
夜深人静伸手不见五指一盏台灯下默默码字的地方 2019 年 我们打了几场硬仗 (上)
前言
这段时间在 OKR 的驱使下,我们团队在业务测试和目标达成的路上专注的奔跑,战线拉的越来越长,担心积压的内容太多,走得太远而忽略了前进路上遇到的经验教训的归纳和沉淀。恰逢团队再次调整,借此机会来回顾一下从 2018 年团队下半年到 2019 年底,第一次调整后我们团队总共做了哪些事情,取得了什么样的进展,遇到了哪些坑。
专栏文章,写的比较随意。
导读
- 业务线梳理
- 目标设定
- 任务拆解
- 最有效果的任务 1:代码覆盖率体系
- 增量代码覆盖率方案
- 代码伪实时染色系统
- 最有效果的任务 2:模型算法监控体系
- 团队取得的落地效果
- 未来的规划
业务线梳理
2018 年下半年,团队从 6 个人增加到 21 个人,支持的业务类型也从单一的移动端方向,扩展了模型算法、Web 端、服务端产品线,业务线方向跨度很大。盘点下来,我们团队的业务主要分四个方向:
- 移动广告 SDK
- 移动广告 DSP 引擎
- CRM 系统
- 效能研发平台
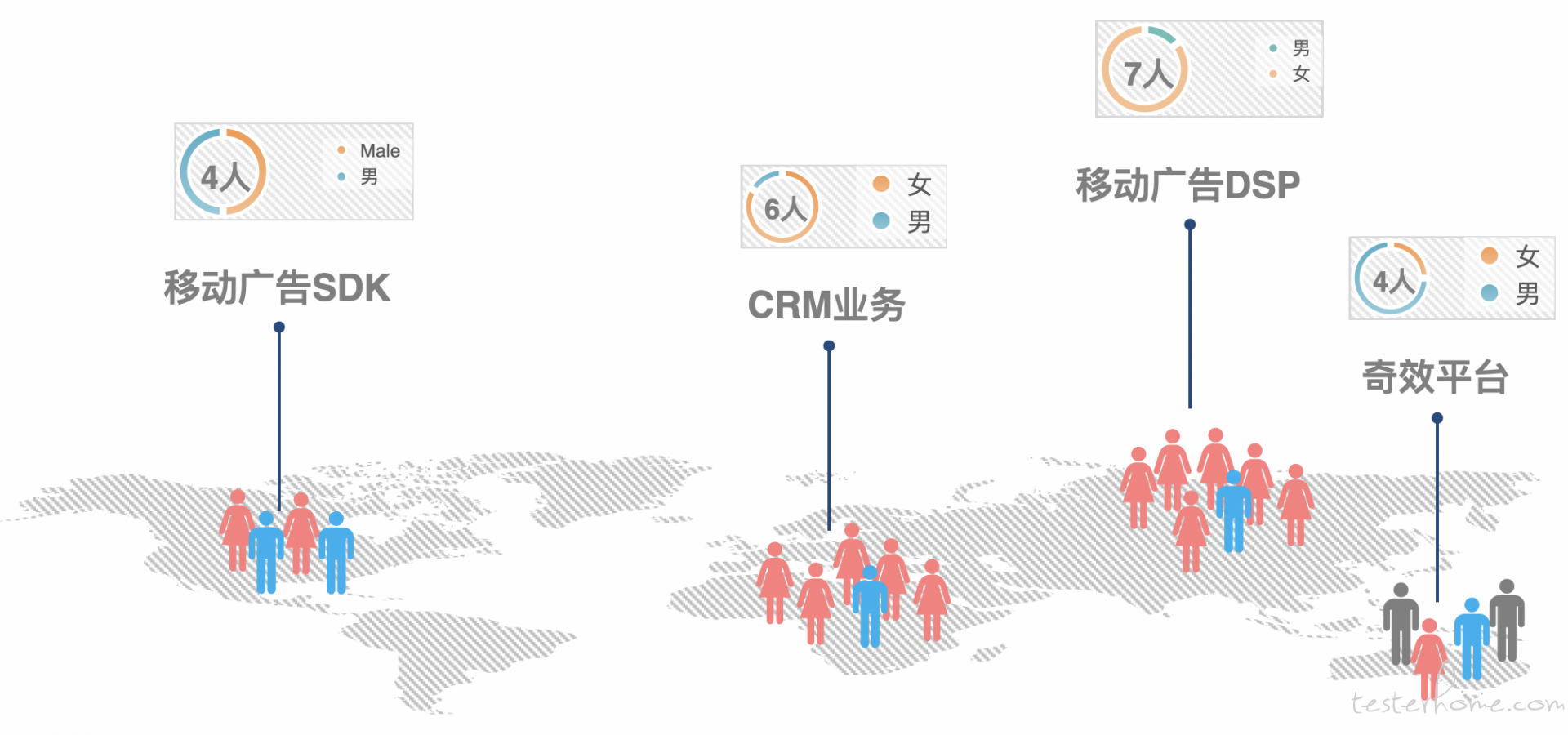
三条不同的业务线,面临的情况各不相同,基本上涵盖了测试行业各种业务的通病。(效能平台本文先不做介绍)
SDK 业务的特点:
- 并行版本多,对接了多个媒体端
- 提测周期短,经常会有定制化需求紧急发版上线
- 项目是模块化结构
- 需要定制测试 Demo APP,本身无界面
- 回归测试周期短,小改动频繁,整体回归测试代价高昂
- 广告打点的特殊性,包括时序、计数、触发时机等,直接影响计费
移动广告 DSP 引擎
- 收入线,风险高,压力大
- 测试难度大,模型算法相关
- 底层 C++,测试走读代码成本高
- 关联上下游较多,排查困难
- 广告类型多,数据量巨大
CRM 业务线
- 业务逻辑极其复杂,十几个系统关联
- 业务链路长
- 财务、法务、合同类多测试多,风险高
- 多个系统并行提测,相互耦合,测试逻辑和构造数据复杂
- 流程管理比较乱,人员流动大
- 测试效率化难
设定目标
托尔斯泰说:“幸福的家庭都是相似的,不幸的家庭各有各的不幸”。看了上面的问题,是不是多少能找到自己项目的影子?团队整合后,面临的问题形形色色,没办法挨个细说,我们团队对现有问题进行了拆解和讨论,并形成了三个大的目标来达成。
- 目标 1: 整体规范项目流程规范,所有业务线自有 Jenkins 全部迁移到统一的流水线上,打造 CI、CT、CD 一体化,集中治理
- 目标 2: 建立精准测试体系,完成 C++、Java、PHP 三个语言的代码覆盖率建设,辅助业务测试、自动化测试、流量回放等手段提升效果
- 目标 3: 推进测试深入化,从广告投放平台深入到引擎的模型算法层面,对广告的模型和词典进行全方位监控及行为分析,降低人为失误造成的事故损失
团队推行 OKR 后有很多好处,具体参看团队之前写的文章:https://testerhome.com/articles/17888
围绕着上面提到的目标,我们拆解为四个季度要完成的 OKR,可以给大家看一下部分的 OKR 系统的截图:
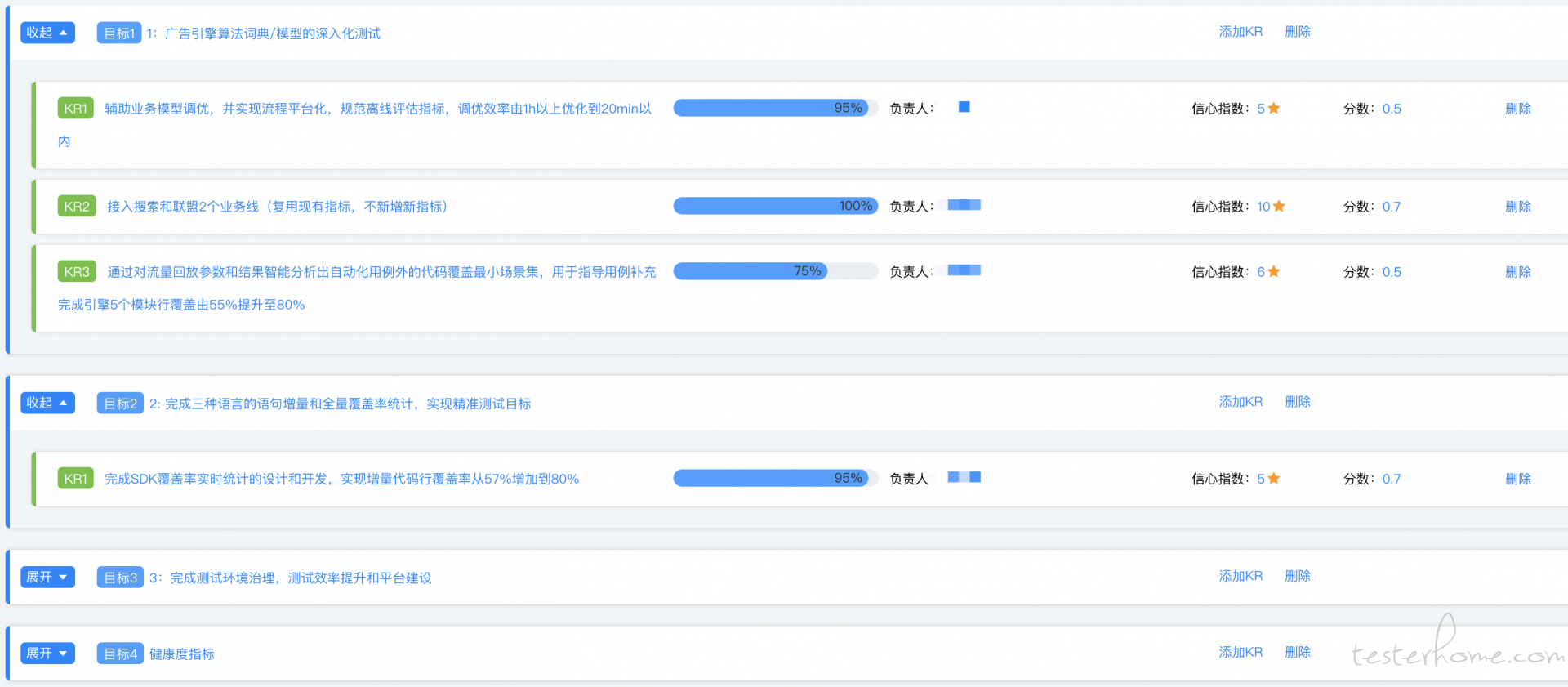
补充一下:这个 okr 系统是奇效平台花一周时间做出来的,之前都是管理在 Excel 中
拆解任务
围绕着总体的三个目标,我们对项目流程进行了分解,分而治之,每个阶段要完成的事情都罗列了出来,大致如下:
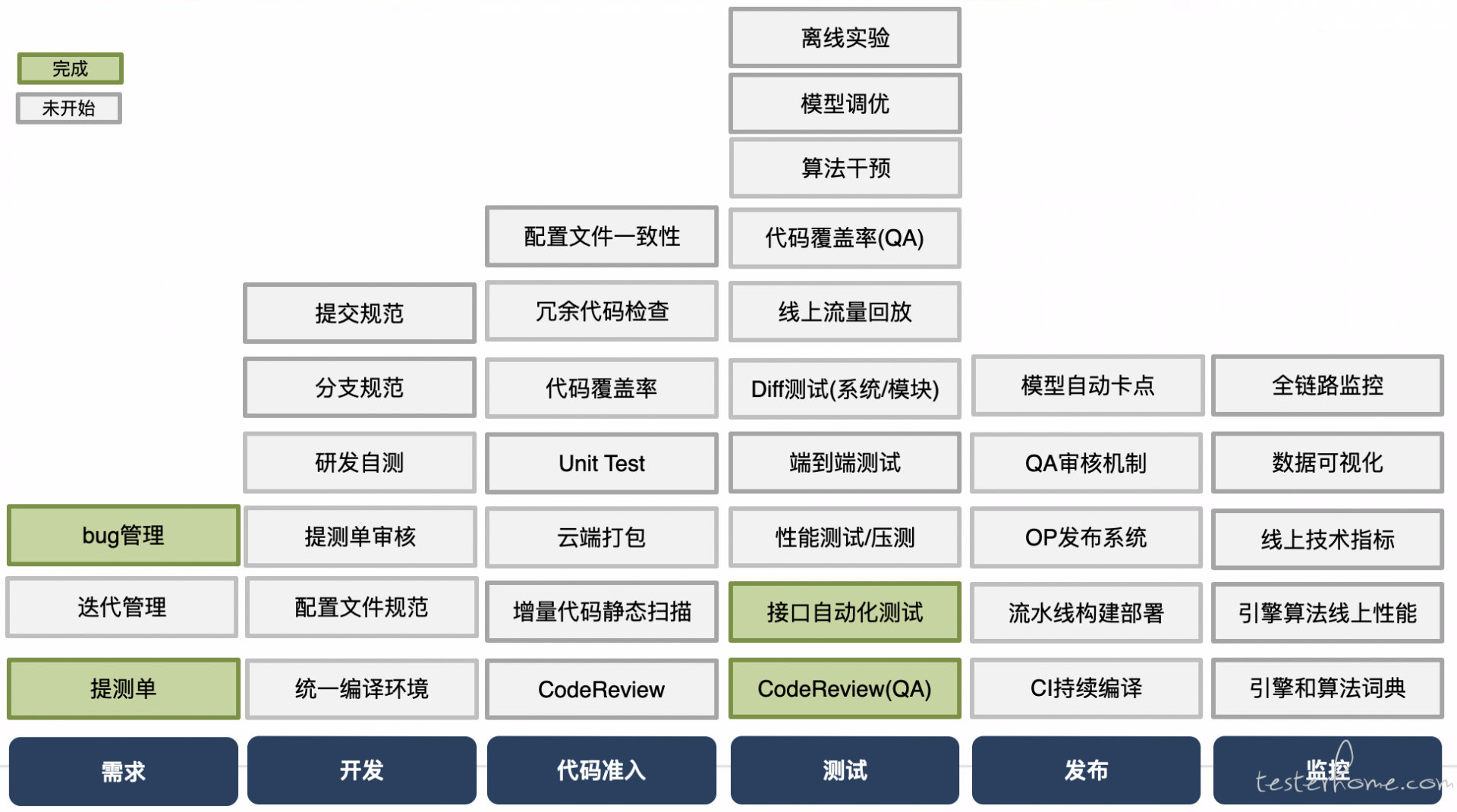
从项目立项到发布上线,总共可以划分为五个阶段:
- 需求阶段
- 研发阶段(代码准入)
- 测试阶段
- 发布阶段
- 监控阶段
我们推动开展测试的左移和右移工作,除了技术方案外,我们与研发团队一起协商了许多规范和检查机制,其中让我们受益颇多的有几个值得提一下(大厂同学可能觉得很诧异,不是本来就该这样么?):
- 建立提测单机制,区分优先级,配置了提测看板,让一周的工作一目了然
- 设定研发自测演示环节,研发会在测试环境进行主要功能演示,被测试同学围观后,提测质量逐渐高了起来
- 统一 Jenkins 流水线后,通过 Docker 解决编译环境一致性问题,减少了提测后环境问题导致排查耗时
- 配置文件规范。以前遇到很多次问题是因为研发本地自测的配置环境跟测试环境不一致造成的
在扫平了项目前期的人为障碍后,我们强化了测试能力建设,其中收效最大的主要是两件事:
- 代码覆盖率检查
- 模型算法监控
可能有人要问了,代码覆盖率检查已经是很多年前提到的概念了,并且在 2018 年已经很多公司已经建立了这样的测试手段,这里我想重点介绍一下我们是怎么用的。
代码覆盖率检查
提到代码覆盖率,社区里面大大小小可以找到几十篇类似的原理、搭建、使用等介绍的帖子,在这里我重点说一下我们团队的技术历程和思考。
前面提到的,我们团队三个业务线,用的语言分别是Java、C++、PHP。也就是说从一开始我们就不能集中技术力量去解决某个语言的覆盖率方案。好在现在互联网信息的便利,有 TesterHome 社区和 MTSC 大会这样的平台,让我们可以获取到很多优秀团队和公司的做法,这里简单罗列一下我们参考到的方案:
-
2018 年 MTSC 大会:
- 《双精准测试实践 - 陆金所》
- 《汽车之家新车电商精准测试解决方案 - 闻小龙》
- 《有赞测试 增量代码覆盖率工具》
- 《基于 codediff 的差异代码覆盖率统计实现 - 转转》
-
2019 年 MTSC 大会:
- 《进化的覆盖率 -- 实时代码染色 - 蚂蚁金服》
- 《恰如其分的自动化测试 - 淘宝》
我们的业务并没有比其他公司的业务独特到哪里去,只不过我们团队要同时解决三个语言的代码覆盖率设计,仅此特殊而已。
代码覆盖率的原则
在投入去做代码覆盖率的时候,我们明确了一个原则和几个期望:
- 原则:代码覆盖率只是一种度量工具,辅助测试的手段,而非评判标准。
为什么这么说呢?我这里简单举几个例子:
function test(int a, int b){
return a/b;
}
输入:a=3,b=6;
// 行覆盖率:100%
// 漏测b=0
function test(int a, int b){
if(a < 5 || b < 10) {
return a/b
} else {
return 0
}
}
//输入1:a=3,b=6;
//覆盖率:50%
//输入2:a=10,b=11;
//覆盖率:50%
// 漏测b=0
这里不论是行覆盖率还是 branch 覆盖率为 100% 都说明不了任何问题,这个我们内部进行过认真的讨论,实际上我们在做代码覆盖率的时候,希望能把目光锁定到那些本次新增的代码、方法、类,但是覆盖率为 0 的情况,是什么情况导致我们覆盖为 0?冗余代码?预埋逻辑?覆盖不到?还是漏测了?
- 期望:
- 在项目快速迭代节奏下从容评估回归测试范围
- 在海量回归 case 中快速提取测试 case
- 在复杂业务场景中针对性设计用例
- 对存量 case 进行梳理和删减
- 对现有的自动手段进行效果跟踪和改进
- 降低漏测场景的复现成本
- 通过可视化度量的方式,促进测试质量的提升
- 在项目流程中,形成质量卡点,强化质量意识
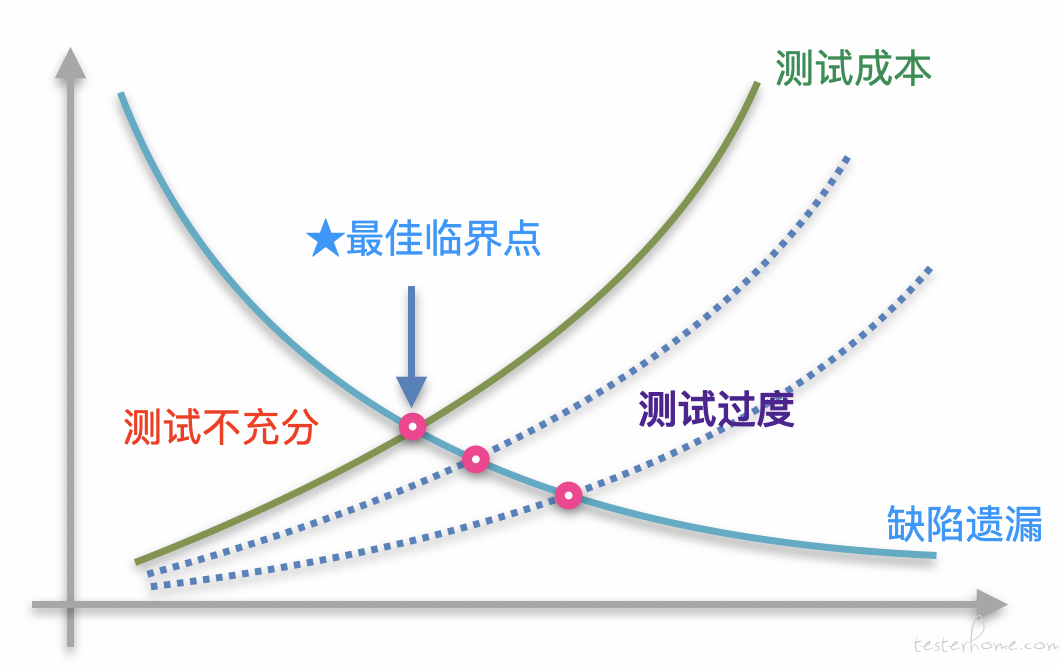
增量代码覆盖率
几种语言的代码覆盖率方案没办法写在一篇文章中,如果感兴趣的话在社区里都可以找到。这里简单介绍一下我们的方案设计:
PHP 代码覆盖率方案
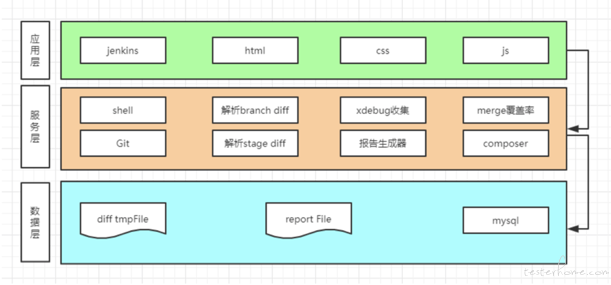
php-code-caverage 并不支持增量报告的展示,如果需要展示的话也比较简单,只需要做如下事情:
- 加入增量 diff 数据(通过解析 git diff 数据得到);
- 在结构化覆盖率数据统计的时候增加增量覆盖率数据的相关字段;
- 覆盖率报告渲染程序中兼容新增的增量覆盖率数据字段;
- 修改对应的报告模板支持增量覆盖率信息;
C++ 代码覆盖率方案
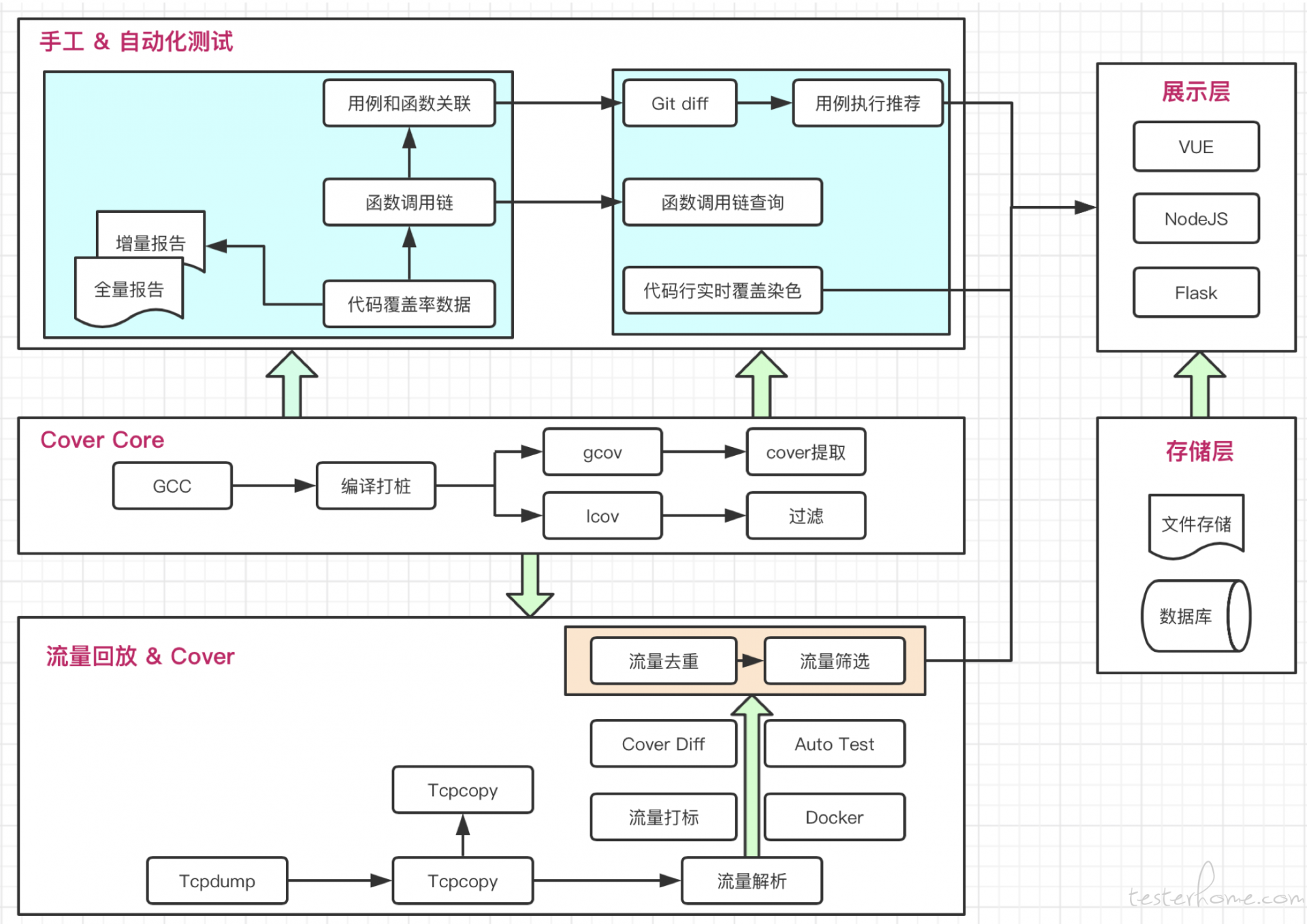
C++ 代码覆盖率是我们另外一个组来实现的,其中的一些细节可以去搜一下 Qtest 测试之道里面的两篇文章《gcov C++ 代码覆盖率测试工具》原理篇和实践篇:
原理篇
实践篇
Java 代码覆盖率方案
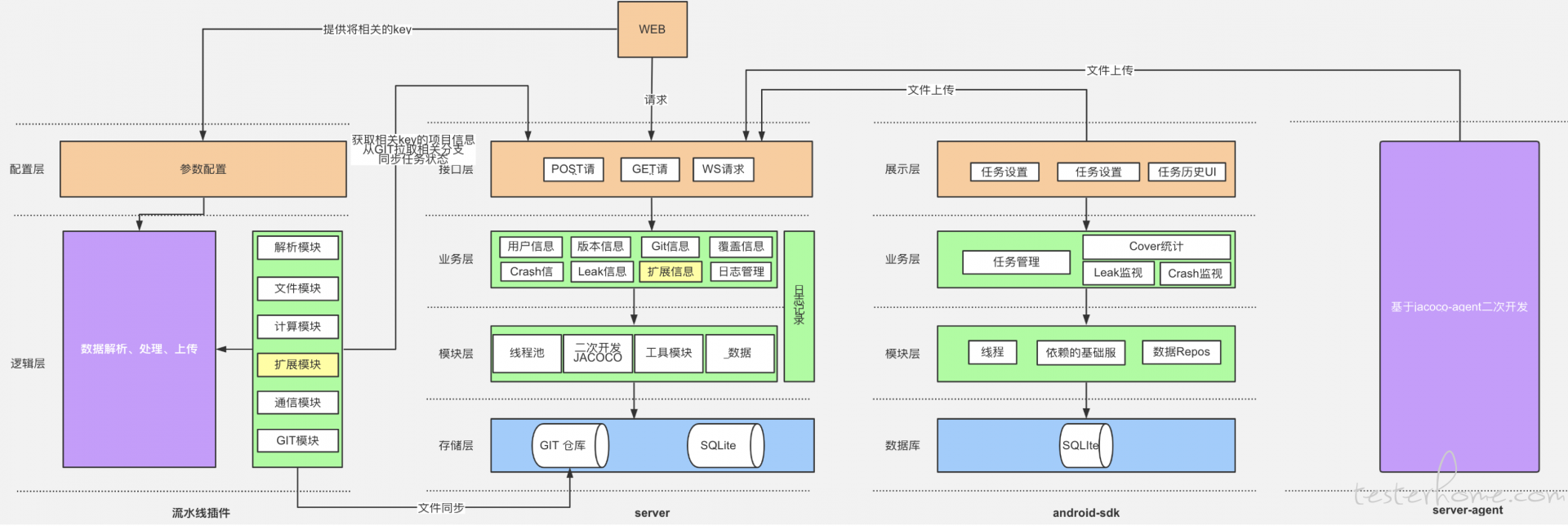
Java 代码覆盖率的文章,社区里不胜枚举,这里就不再介绍了。
代码伪实时染色方案
在完成代码覆盖率统计并集成到 Jenkins 后,我们每周的周会都会追踪一下代码覆盖率对业务测试的帮助,一开始大家对覆盖率还是比较赞同,觉得可以辅助测试,假如发现覆盖率数据偏低会主动去检查是否是设计的用例没有执行到。后来有一些同学反馈说,他们通过覆盖率结果反推 case 非常的困难,流程太长。通过了解,我们发现业务测试在补充用例到时候需要做几件事:
- 清空之前到测试覆盖率数据
- 编译打包、部署环境
- 执行一个 “可能会” 提升覆盖率的测试场景
- 执行完了后,回收覆盖率数据到流水线
- 查看数据结果,是否有提升
在调试一条 case 的时候,整个反馈的链路太长,响应不及时,业务测试同学需要逐条的尝试 case 是否有效,耗费大量的时间。怎么解决这个问题?蚂蚁金服的议题启发了我们!
在跟蚂蚁的讲师沟通后,我们发现要做到他们那样的程度对我们这样的小团队来说不太可能,因为我们不具备这样的技术力量来修改编译器,而且我们还有多语言的需求。于是我们开始尝试了自己的野路子方式,伪实时代码染色系统。
C++ 的染色系统(涉及到核心代码,不得不马赛克):

C++ 代码染色系统具备几个功能点:
环境随时切换和锁定
代码树实时更新,绘制完代码树结构后,再在树节点上追加 diff 信息和覆盖信息
增量代码返回结果只渲染代码树的相关增量文件,高亮显示已覆盖的行

支持精确生成单模块、单目录、单文件的覆盖率信息
支持远程操作覆盖率数据
当然系统功能远不止于此,截图太多会影响阅读体验,这里就不详细的介绍。目前我们在做 case 的录制回放,case 推荐等功能,目前效果还在观察,暂时不提。
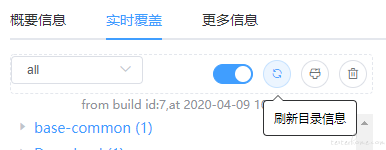
Java 代码染色系统功能:
按测试设备和版本作为 index 来隔离数据
支持全量数据和增量数据切换
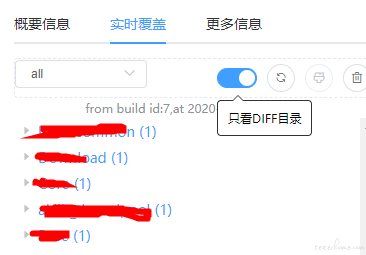
伪实时返回覆盖率数据,从测试完成到覆盖率数据返回,渲染代码树大约需要 0.5~2 秒,所以叫伪实时

功能测试完成后要手动刷新数据
团队代码覆盖率统计系统
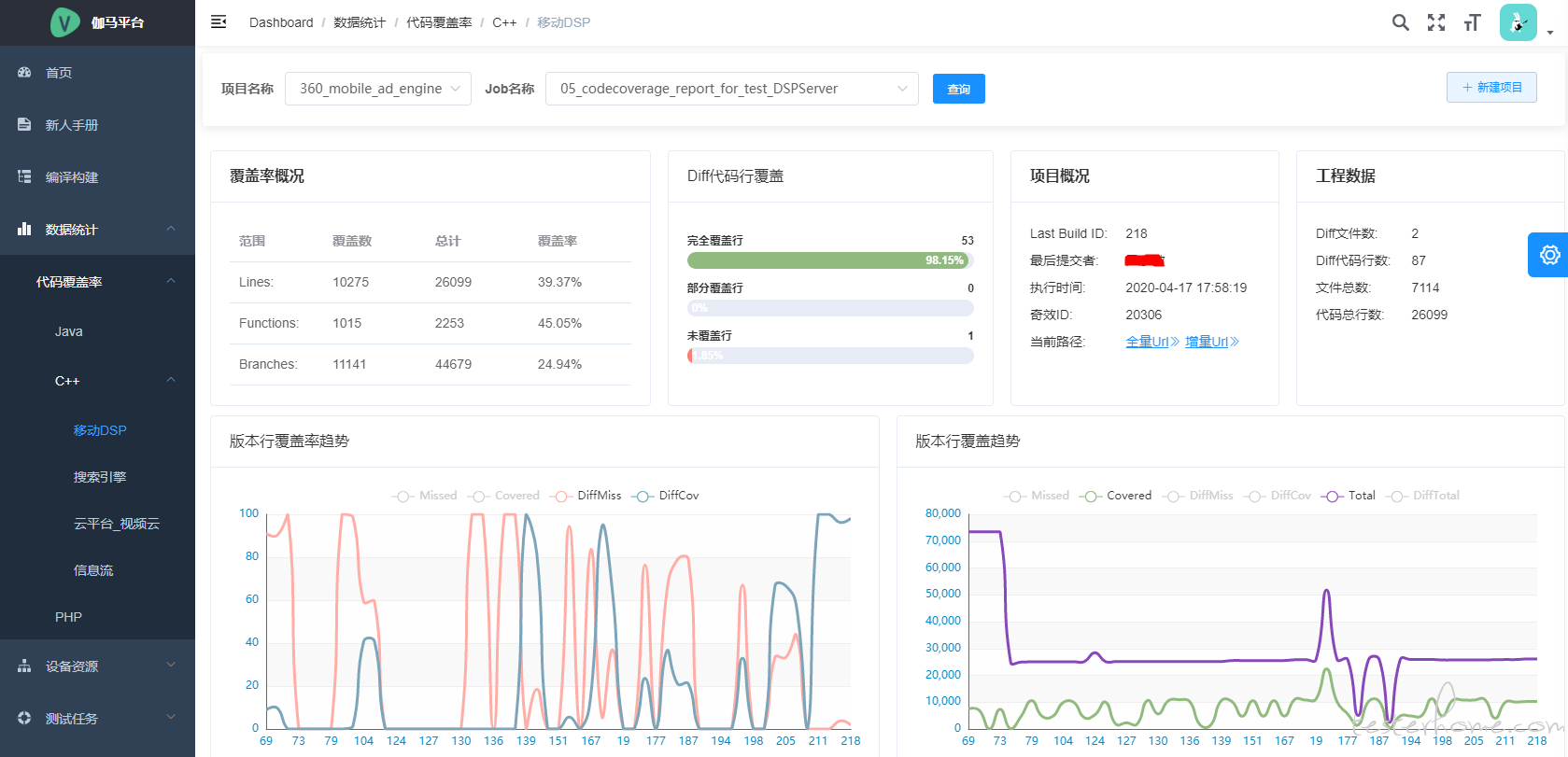
这里做了覆盖率数据和流水线打通,关联到触发人员、BuildID 等信息。我们会关注几个点:
- 重点关注增量覆盖率的变化趋势
- 文件和代码行的剧烈波动会影响代码行覆盖率
- 不追求每一次 build 都是百分百覆盖,只关注累计的测试覆盖率
- leader 会追问为什么是这个覆盖率,组员能明确回答出来
总结
参考了业界的进展,我把精准测试的规划拆成了三个阶段:
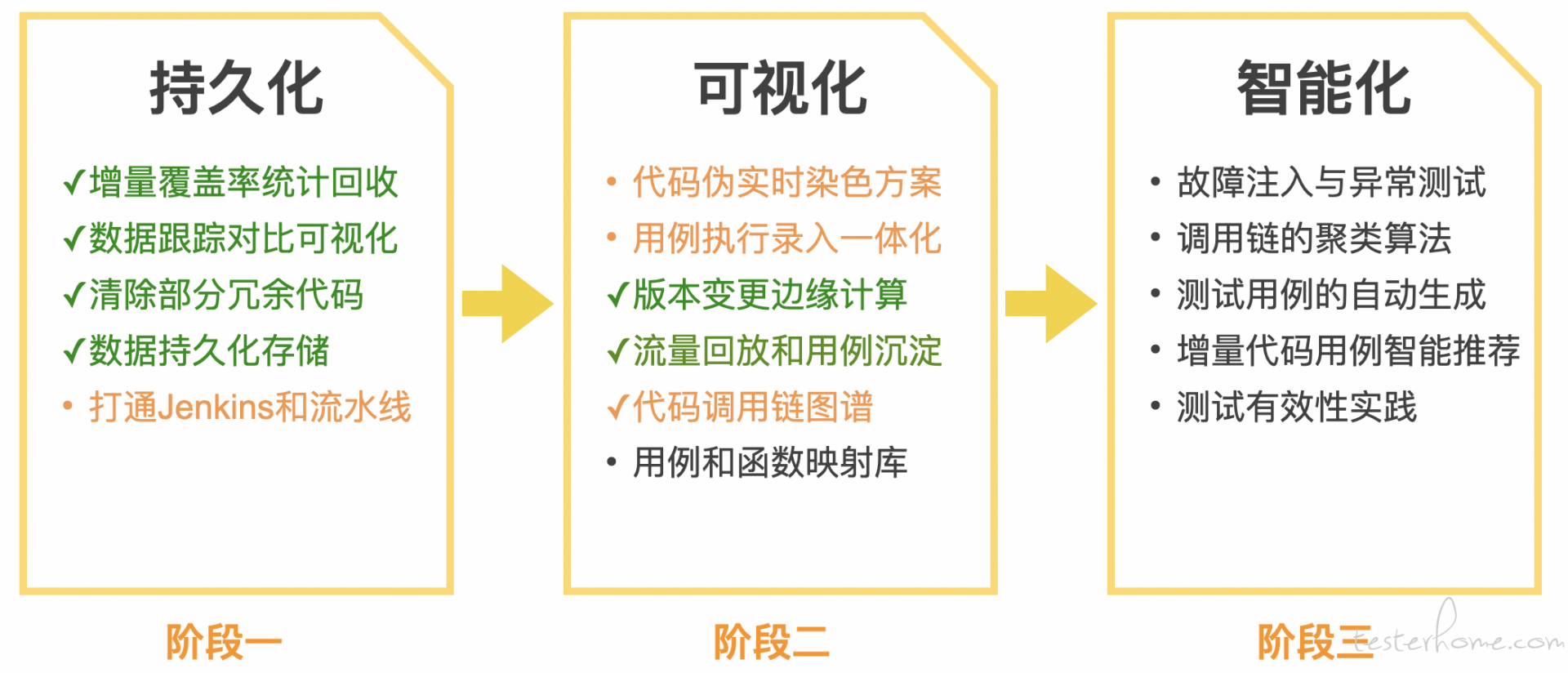
当下我们刚刚把第一阶段的基础能力建设做完,第二阶段很多事情还在进行中,有些已经完成了但是在观察效果,有些还在建设中,很多大厂已经进入到第三个阶段智能化时代,小团队只能仰望和模仿。
模型算法监控体系
待补充




