5. 模型算法监控体系
绝大多数测试同学可能接触不到这方面的测试,只是为了记录下团队一年的成果,感谢小伙伴们的奋力拼搏!
发现已经写了 1 万多字了,新起一篇,方便大家阅读
提到模型算法方面的测试,往事浮现,历历在目。
记得商业化大老板跟我们说:“测试的同学能不能把测试工作再做的深入一些?不要局限于广告投放平台 UI 上面的点点点,而是把模型效果给测一测,因为平台交互的问题只会影响到一部分商户的体验,而模型效果的影响可能是数十万、几百万的用户,我更关心这方面的质量”,大老板非常委婉的 Diss 了测试,如芒在背。
我们去找模型算法的研发负责人沟通,测试人员有没有能介入的地方,我现在还记得他坐在对面歪着嘴笑(不是贬义,他平时笑起来也是嘴巴歪向一边),看着我们缓缓地摇头,当时的情景下深深的感觉测试被鄙视了,只不过我们没有放弃测试深入化这件事,方法总比困难多。
5.1 业界调研
通过跟研发同学沟通,我们发现研发同学评估新模型的效果会有两种办法,第一种是本地环境离线实验,第二种是线上小流量灰度测试,这两种方法都不需要测试太多的干预。我们在想如果不直接干预测试,还有其他事情能做吗?
老规矩,先去外面看看业界前辈是如何做的,找了一圈我们发现基于模型和算法的测试案例真的寥寥无几。正在我们苦思冥想的时候,我们发现研发每天都会把实验数据录入到 wiki 中,当作实验日志来记录。突然萌生了一个念头,这种碎片化的数据是不是可以连续跟踪呢?经过跟小伙伴们讨论后发现,我们有一个很重要的事情可以做,那就是“模型监控”!
5.2 场景分析
广告引擎系统非常的复杂,不知道是否会涉密,所以我从网上找了个类似的架构图帮助大家理解,实际架构要复杂许多,可以参考刘鹏博士写的《计算广告》中提到的在线广告架构图:
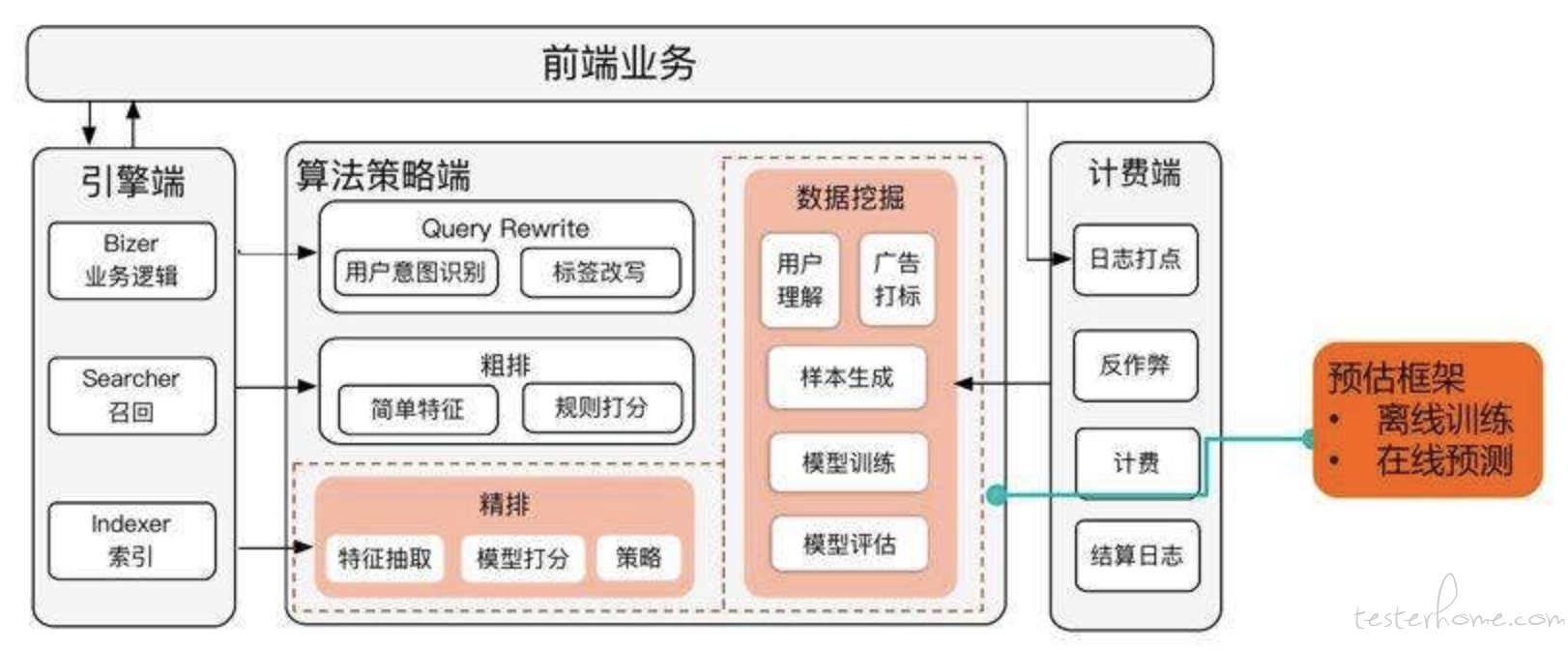
(图片来源于百度)
5.2.1 基本概念分割线
这里稍微科普一下,在线商业广告有很多种类型:
- 合约广告
- 竞价广告
- 程序化交易广告
- 原生广告
一条广告从创建到召回,再到展示用户面前,会经历一系列复杂的处理,整个过程中都需要测试同学来参与验证,而目前我们对模型算法的测试还是空白,我们来看一下示意图:
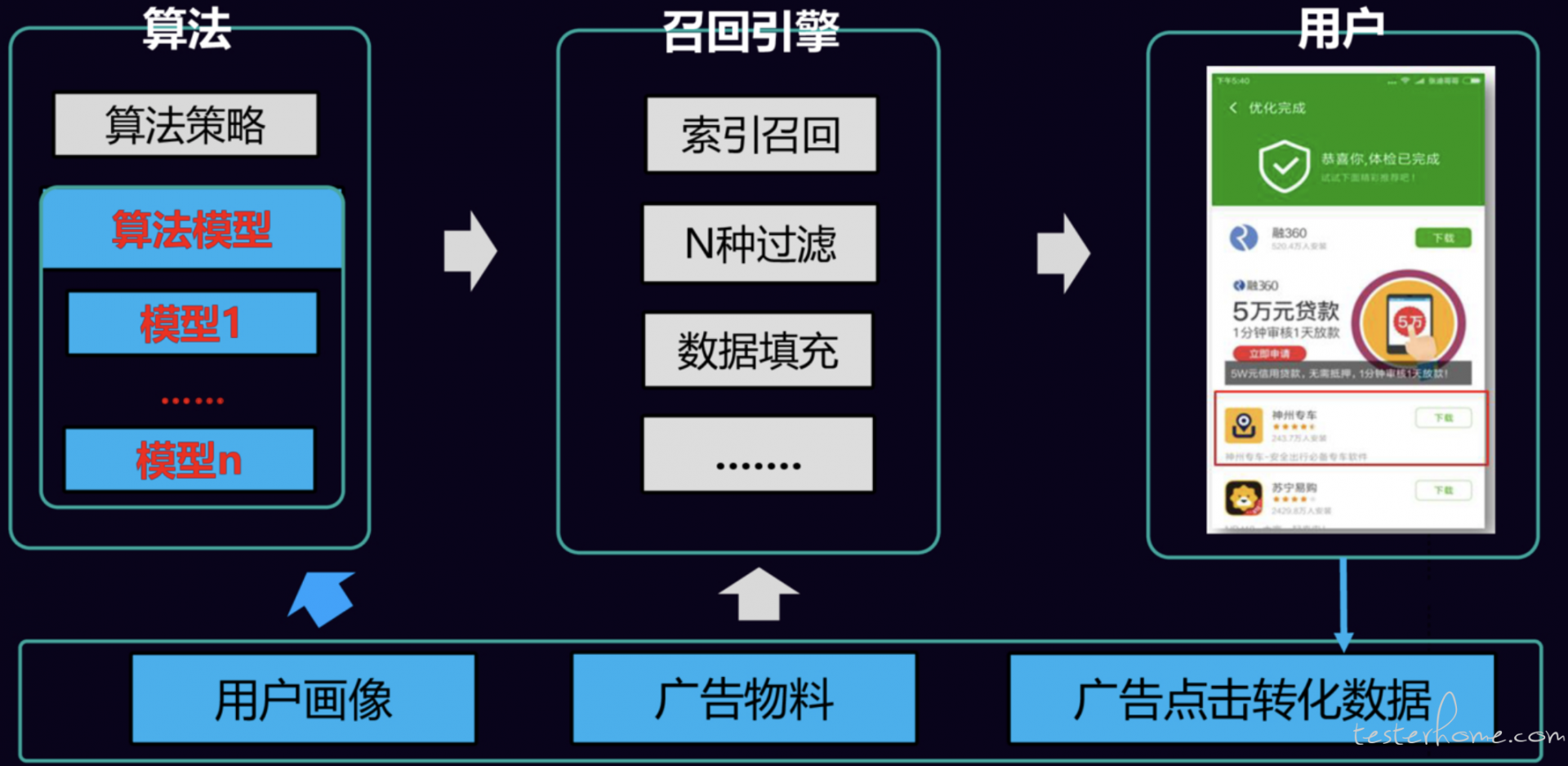
召回引擎主要负责广告被召回的逻辑,比如在什么场景下,在什么广告位上,提供什么样的广告类型,并提供广告物料。
算法侧是根据当前的用户画像,计算广告展示策略,比如什么样的广告优先展示,广告的排序队列是怎样的。
广告涉及到的一部分算法类型:
- 分类算法:决策树、贝叶斯、神经网络……
- 聚类算法:K-means、K-mediods……
涉及到的部分模型分类:分类模型、聚类模型、回归模型、预测模型……
我们每天要接触的素材是:算法、模型、样本、特征、指标……
言归正传,通过一段时间的沟通和分析,我们对模型训练周期进行了摸排和分解,并对每个环节曾经或可能出现的风险进行分析:
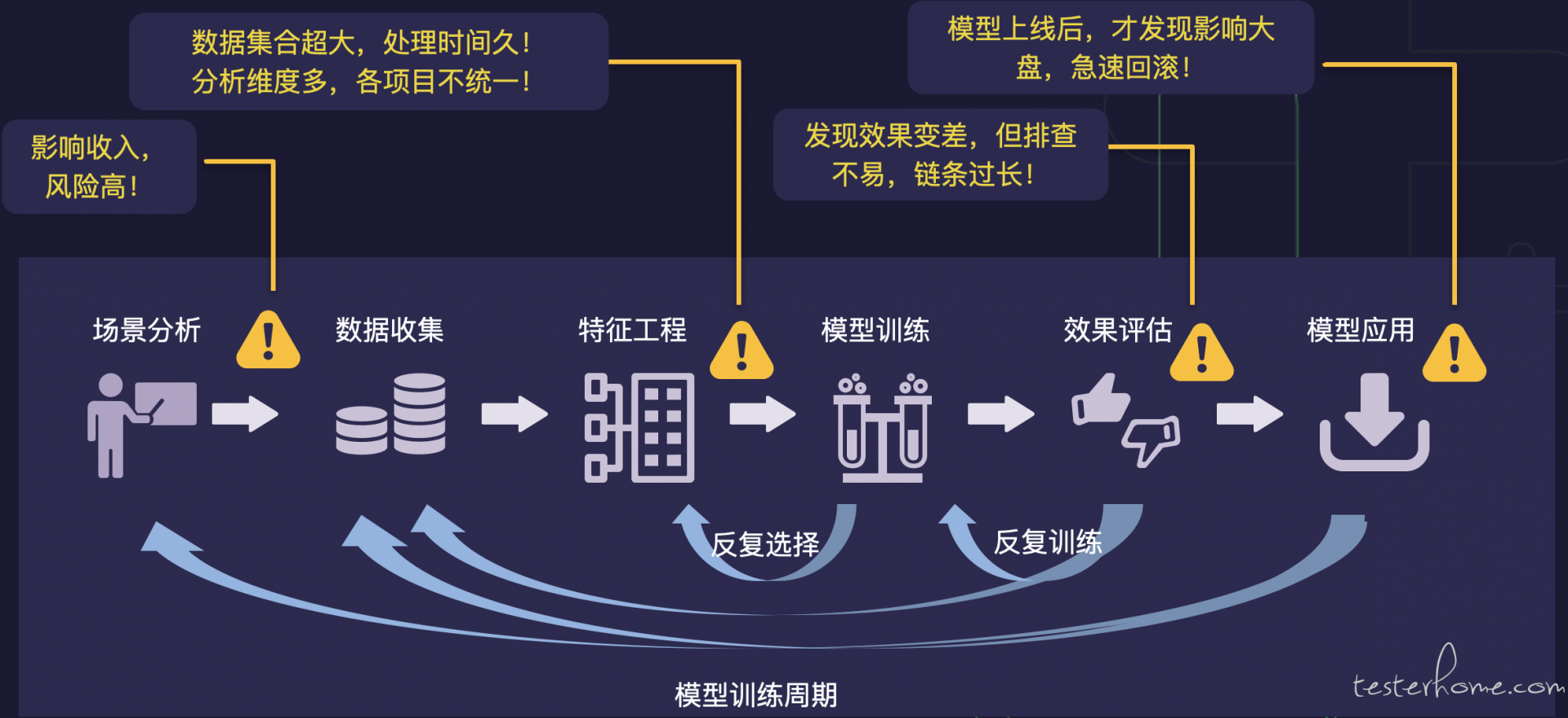
在真正了解到模型算法这块的流程后,我们一度想要放弃,因为难度确实超乎我们的想象,场景比我们想的要复杂。
由于算法模型的黑盒性、难解释性,不再是我们过去测试的 true 或 false 的情况,业界能借鉴的案例也极少。除此之外,还有一些坑等着我们跳:
- 超大规模的样本和特征(某个模型的样本量约 5 亿)
- 问题定位不确定性太多,研发自己做也非常耗时
- 离线训练需要大数据计算的背景知识和技能
- 不同的场景有不同的算法模型,应用场景多样化决定了数据表现的多样性
5.3 测试体系
附上我们整体的测试体系和过程。
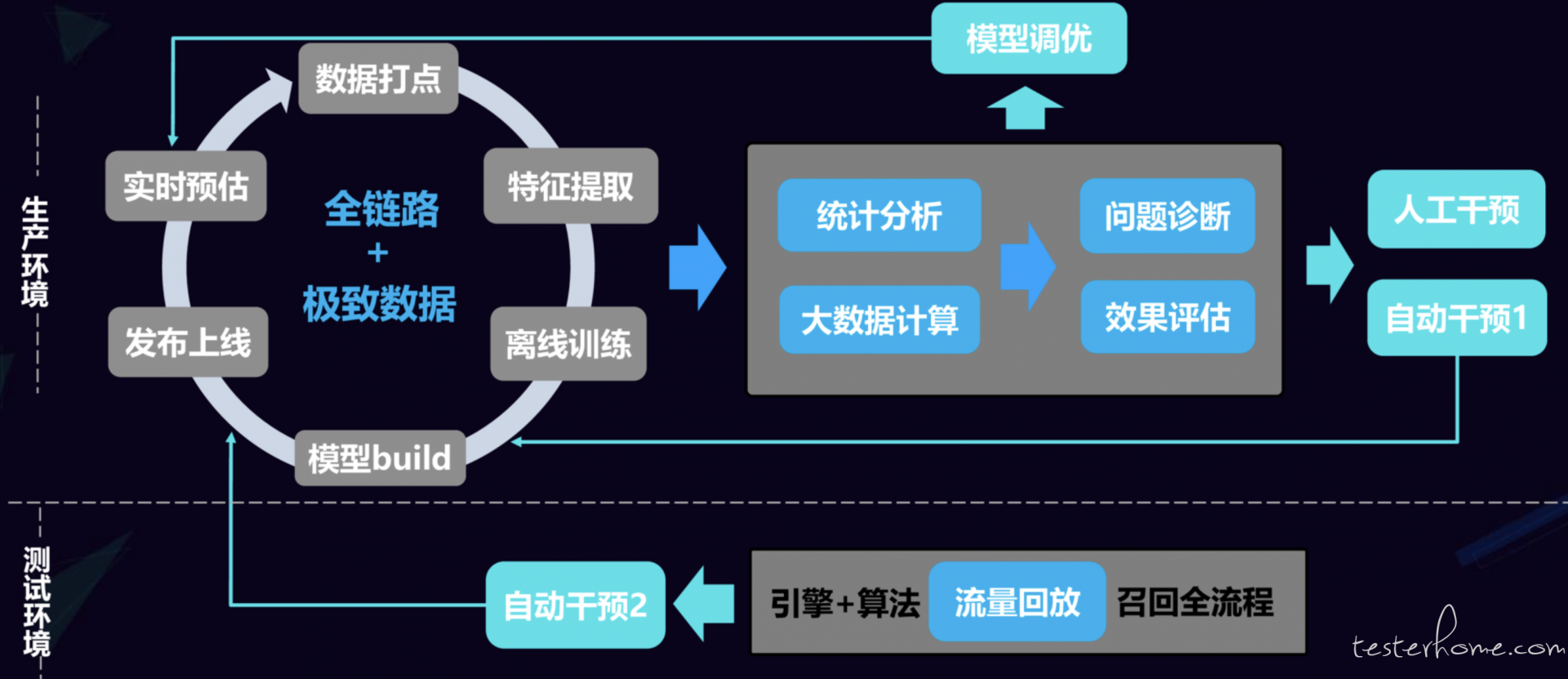
模型算法方面的测试我们划分为“生产环境”和“测试环境”两套。针对生产环境,模型从生产到上线大抵可以划分为六个环节:
- 数据来源
- 特征提取
- 离线训练
- 模型 Build
- 发布上线
- 实时预估
生产环境中,我们在这上面六大环节中分别做了各种定制化的监控,从而实现 “全链路” 的数据跟踪,同时也把所有能获取到的过程指标数据全部拿到,然后根据大数据的计算进行统计,把数据结果通过平台化的方式展现出来,提供研发人员进行问题追踪排查,同时也可以辅助算法工程师进行模型调优,最令人兴奋的是,我们的做法吸引了很多算法工程师前来,提出了大量的定制化数据需求,从而商定了很多监控报警和流程卡点机制。
测试环境上,我们搭建了一套完全模拟线上的仿真测试环境,通过流量回放技术,把线上数据引流到线下,对即将上线的新模型进行检测,查看各项指标的表现,从而预判能否发布到线上,在这个环节我们也增加了自动干预的卡点,如果出现较大的指标波动,我们就自动拦截上线。
5.4 数据监控
数据监控机制形成了四种分类:
- 样本特征类
- 全样本量和大小
- 正样本量和比例
- 新增缺失率
- Q 百分比
- 模型内容类
- Feature 总量
- Feature 缺失率
- Feature 新增率
- 效果评估类
- 机器学习
- 变现能力
- 特征效用
- 基础质量类
- 上游数据
- Build 过程
- 发布流程
- 物理环境
上述四类,前面两类是跟模型算法内容相关的监控,而后面两类属于出于质量设计而扩展出来的能力。我们以样本特征和模型内容为例,在我们的监控环节里,需要采集到的指标有:

上图中,左侧是我们梳理和要监控的指标内容,右侧是我们需要根据这些数据提供查询的维度,其实是平台化后衍生出来的用户需求。实际上我们前后针对 13 个模型整理出来了 44 种监控指标,并且算法工程师们还在不断的增加新的指标,紧接着我们就面临了第二个挑战:大数据计算。
前面有提到,某个模型的样本数据大约是 5 亿条,每个样本的特征项可能会有近百种。举个例子:某个用户的手机 IMEI 号作为其唯一的样本,对应的特征数据会有 100 多种,那么测试在做样本训练的时候,会遇到计算的性能问题,我们最初进行一次样本训练需要 8 个小时,而研发人员对样本训练的时效性要求又非常高,迫使我们不得不去解决这个问题。比如说:
- 如何解决数据倾斜的问题?
- 如何解决 Spark 任务 GC 时间过长的问题?
诸如此类的问题还有很多,都是需要我们去排查和解决的,通过小伙伴们不懈的努力,我们把样本训练的时间从 8 小时减少到 1 小时,最终目前可以压缩到 20 分钟内完成。
另外尽管我们对样本数据进行了 top N 的筛选,但是结果数据依然非常复杂,因为我们需要用堆叠图来展示,对前端性能要求很高,见下图:
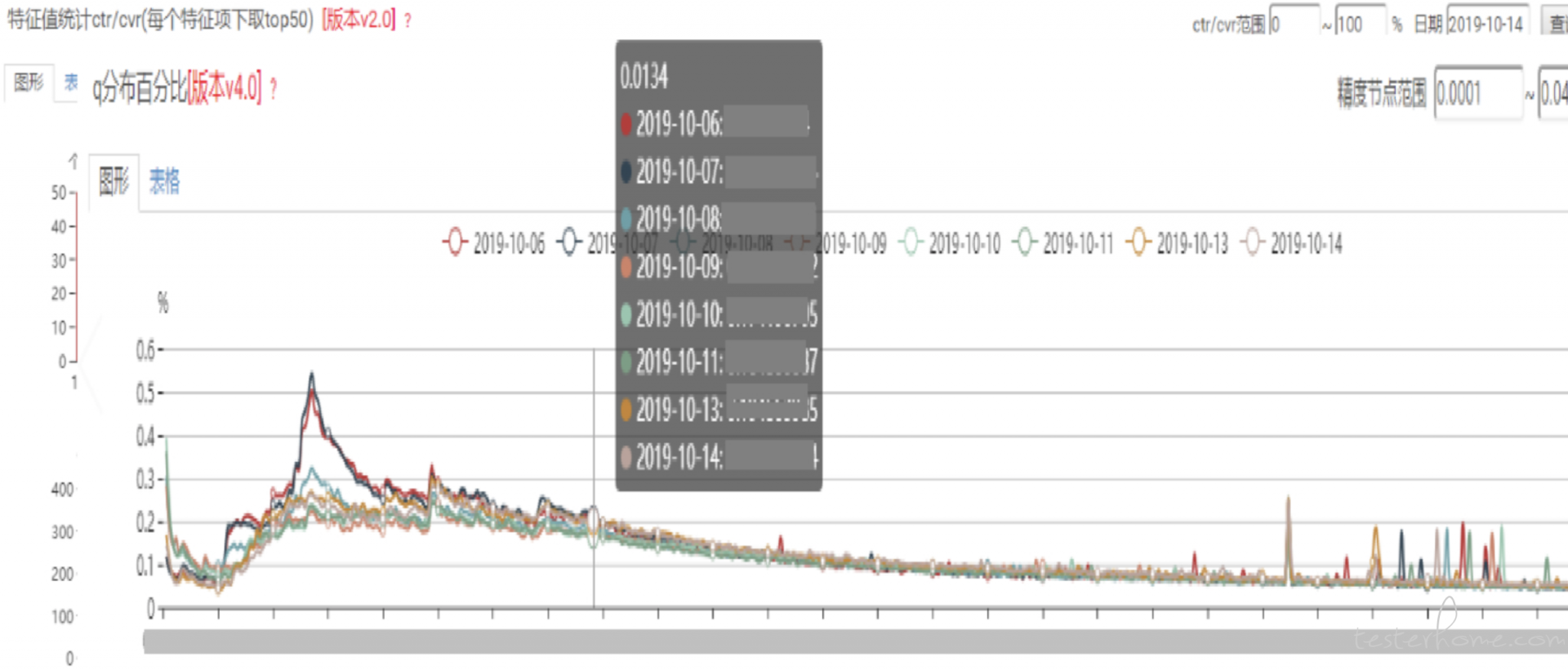
5.5 效果评估
在上面流程里,我们不止是对模型的过程进行监控,还需要兼顾效果评估类的工作,目前我们完成的事务可分为下面几大类:
- 机器学习相关
- AUC
- COPC
- LOGLOSS
- PCTR
- 准确率
- 召回率
- ROC 曲线
- 业务相关
- 实时收入
- CTR
- CVR
- CPM
- 特征效果相关
- IV
- WOE
- 特征变现变化
基于需求,我们需要支持几个维度的数据对比,将平台能力提升到了一个新的复杂程度:
- 不同阶段对比
- 阶段一致性
- 时间维度
- 版本对比
- 分桶
- 分 ADX
5.6 基础质量
关于基础质量,前面有提到,是我们围绕着模型算法测试干预的探索过程中,衍生出来的基于质量的行为。
这个是有惨痛的教训的,曾经发生过一个线上事故,因为上游某个特征数据推送出现问题,采用了默认的内容,从而导致了线上大面积的计算错误,虽然在数分钟内就发现了该问题,但是也产生了巨量的收入损失。
因此我们针对这种情况补充了几件事:

对于上游依赖的数据,我们会做全流程的监控,主要监控其变化异常,比如某个模型在进行训练的时候需要依赖的样本集大小,不能跟上个版本发生较大偏差,对于偏差量我们会配置一个阈值来进行监控,另外会根据样本文件的更新时间进行记录,从而避免使用默认文件的情况发生。模型生产过程也是同样的道理,只是监控的范围更大,维度更多,譬如下图中当文件出现不一致的时候发生的监控报警:
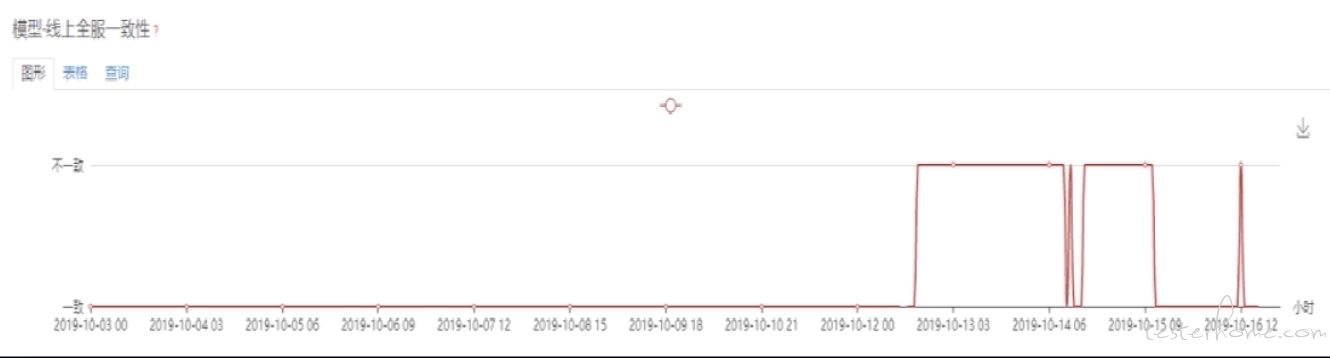

5.7 平台化
关于平台化的需求,其实是用户提出来的,也就是我们的算法工程师们,他们期望平台能够提供几个方面的支持:
- 查询
- 自定义场景查询
- 配套表格数据
- 线上部署记录查询
- 对比
- 同环比数据
- 不同模型对比
- 不同版本对比
- 在线配置
- 基础属性配置
- 特征项管理
- 报警阈值配置
- 监控信号阈值配置
- 交互友好
- 更新记录可查
- 前端性能
目前系统功能已经越来越多,不能一一截图,下图是系统的一小部分截图:
5.8 模型监控带来的收益
这部分内容相信是大家最为关心的,就是做了那么多事情,到底有哪些可预期的收益?我们从监控平台上线以来,做了一次线上事故的对比:

在回顾全年的效果时,我们发现这种做法是非常有效果的,得到了业务方的高度认可。以至于后来我们支持的算法工程师调到别的项目去的时候,第一时间就把这套监控方案引入到项目中去。最值得高兴的是我们不但得到了业务方的认可,还给其他业务线带来了帮助,甚至有个业务线上线第一天就发现了 2 个有效问题,直接影响了收入的提升。
6. 团队取得的落地效果
最后,请允许我用团队述职报告里面的一部分内容来总结一下我们团队 2019 年的组织产出(求大佬们轻喷  ):
):
-
移动广告业务从优化 CI、CT、CD 流程,到精准测试的研发,再到线上监控一整套解决方案的落地,把移动广告整体事故损失从去年的 XXX 多万降至 XXX 万,减少 54%。
- 打造了完整的引擎算法线上监控体系:
- 完成算法模型深入化测试目标。监控覆盖模型全链路,44 个指标,8 个上线卡点,实现了测试干预模型上线的能力。有效报警和上线拦截分别 20+、47 次,无反馈漏报。自 5.28 后再无相关事故发生 (除 1 起已告警未采纳的事故)
- 配置文件的梳理,覆盖 95% 的词典文件监控,5 个监控维度。有效报警 15+ 次,发现问题种类 7 个。
- 整体监控体系也辅助联盟和搜索算法的质量保证,发现了直接影响收入的问题。
- 模型调优效率化工具已上线,预期可以将模型调优环节,由原来的零散数据分析变得更加全面体系化,且一个包含完整指标一个任务最快 10 分钟完成
- 协助其他兄弟团队的 3 个业务线完成了引擎的相关模型算法监控方案落地
- 精准测试探索:
- 完成引擎算法 C++ 准实时代码染色系统、自动化用例执行推荐、流量回放场景的 diff 及冗余代码标记一系列工具。
- 辅助 rd 删除冗余代码 1w+ 行,项目体积减少 20%。有效辅助手工和自动化测试覆盖率的提升,自动化回归 case 增加 218 条,累计 551 条,核心模块 ileaf 自动化覆盖率由 58.8% 提升至 72%,dspserver 由 53.9% 提升至 57.2%
- Java 覆盖率
- 针对覆盖率数据,行覆盖达到 75.34%,diff 新增覆盖率 90% 以上
- 结合实时染色功能,增加难覆盖到场景用例 3 条,删除 1 个无用文件
- 推广到兄弟团队使用,目前已经集成使用的有 1 个业务,正在沟通中的有 2 个业务
- PHP 覆盖率
- 完成 PHP 代码增量覆盖率并应用于日常项目,测试中应用系统:channel、sales、mkt、job、ka 等,辅助测试查看覆盖的完整度,补充异常 case,平均增量覆盖率 80%;督促开发剔除本次的无效代码 620 多行;
- CI、CT、CD 优化:
- 增加系统级 diff,覆盖 36 个广告场景; 增加了动态性能报警阈值机制; 以及小流量配置机制、模块机器分配等一系列优化。
- 全年完成 2118 次构建和测试。有效拦截崩溃 6+ 次,性能下降严重或功能问题 3+ 次,辅助 rd 将核心模块平均延迟从 65ms 优化到 30ms。
- 打造了完整的引擎算法线上监控体系:
之前规划的完成情况
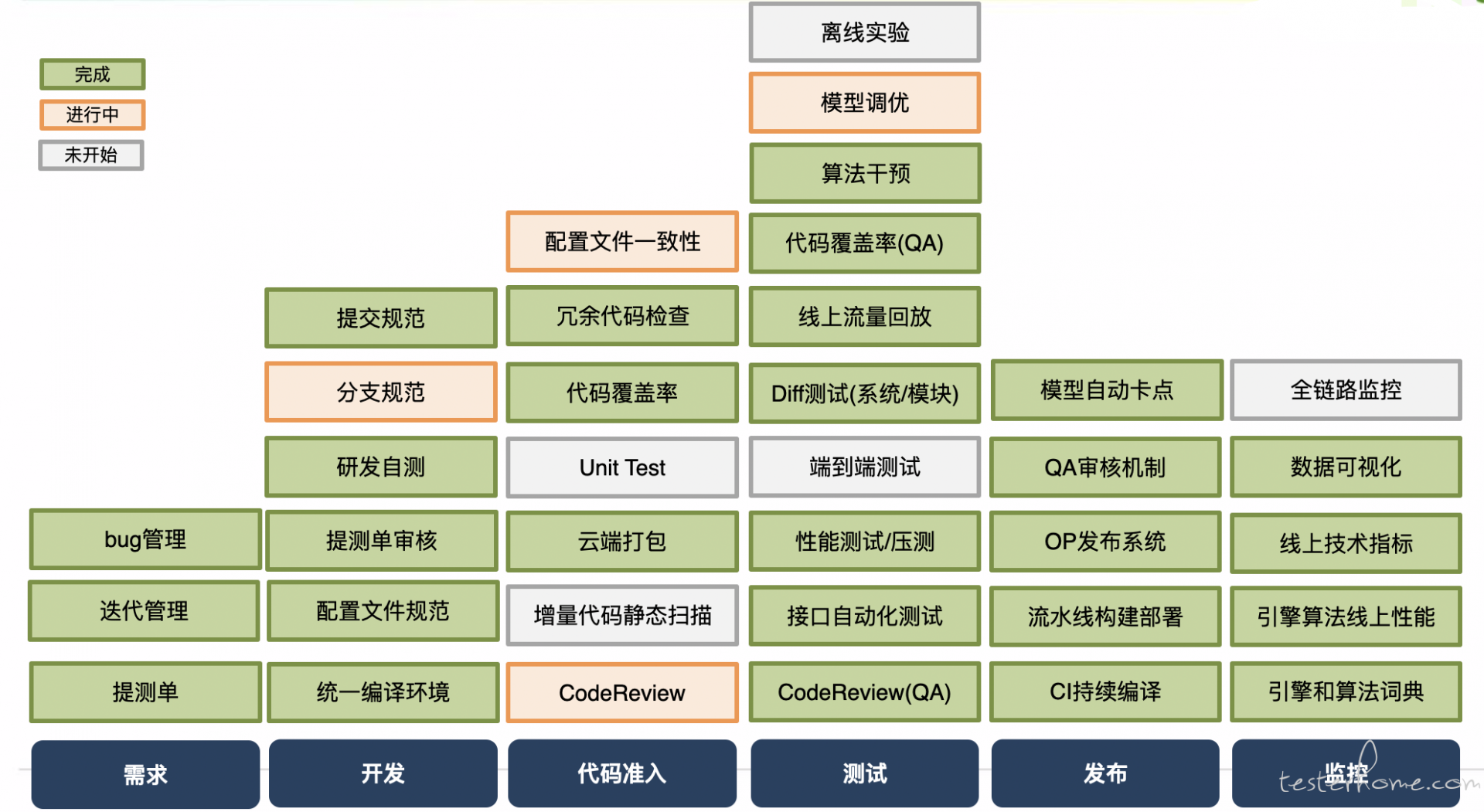
7. 未来规划
新的一年,团队遭遇了重大的组织结构调整,之前规划的事情可能会面临很大的修改,这里暂时就贴一张图。
不论怎么样,我们都会秉承“专业、支撑、开放”的精神持续的奋斗下去,打造一支持续创新,锐意进取,努力拼搏的团队。

 感谢支持~
感谢支持~

