-
想问问大家对于外包的看法 at 2023年07月10日
-
你们测试管理的工作是怎样的? at 2023年07月08日
-
TestHome 证书过期了? at 2023年07月07日
遇到了
-
写了个在线小工具,可以提提需求 at 2023年07月07日
每天自己用一用,还能有收入
-
“领导把代码拿走了”
-
机器的配置倍数增涨,可以认为性能也是成倍数增涨吗???线性关系 at 2023年07月06日
v8 发动机,可以快过飞机吗

-
初中高级测试招人,内推 at 2023年07月06日
钱到位,都好说
 ,什么外包不外包
,什么外包不外包 -
一个季度的考核绩效的质量考核合理吗 at 2023年07月05日
明显想降绩效了
-
这么可爱的 BUG,就不修了吧,,算是给各位 TesterHome 家人的小彩蛋。
-
怎么样把 python 的 selenium 自动化脚本,放到 docker 容器 at 2023年06月28日
好的
-
怎么样把 python 的 selenium 自动化脚本,放到 docker 容器 at 2023年06月28日
好,看到了,不错
-
怎么样把 python 的 selenium 自动化脚本,放到 docker 容器 at 2023年06月28日
懂了,,那我的 python 代码,不一定非要放 docker,,可以放 linux,,然后通过接口调用 docker 容器的 selenium 镜像
-
面试被问到自动化测试问题,该怎么回答 at 2023年06月26日
以我自身的项目经验,我的回答如下:
你们公司是怎么开展自动化的,做了哪些自动化?
回答:我们公司,在项目发布上线,稳定运行一段时间后,会开展自动化。首先,我们会根据业务流程,划分哪些功能模块实现自动化。然后安排测试,编写自动化脚本,实现自动化。自动化分为 UI 和接口,像 UI 自动化的话,主要核心是覆盖业务主流程;像接口自动化,我们是达到了 100% 覆盖,并且要实现断言,连接数据库的数据校核断言。做了自动化,有什么效果,多大的提升?
回答:首先,我们需要把自动化的作用定位清楚,自动化的作用,实际上是回归功能,保障功能的稳定性,并不是为了发现 bug。所以,在自动化的收益方面,主要是极大的减轻测试人员的回归功能压力,在每次发布上线后,我们只需要执行一遍自动化脚本,然后等待自动化结束,查看测试报告,可快速定位执行失败的用例,以及失败的原因。相比于没有自动化的,我们项目使用了自动化之后,在每次版本发布上线,能够全方面的回归功能,及时发现因版本迭代发布导致的功能异常;在做自动化过程中,遇到什么痛点,你们是怎么样解决的?
回答:UI 自动化,有几个痛点,是普遍存在的;
第一点:稳定性,有时候网络慢或者页面加载卡顿,容易出现加载超时,元素定位不到的情况,这种情况,我们是优化定位元素的方法,改为隐性等待,即定位到元素再执行下一步操作;
第二点:版本迭代后,元素定位失败,原因是前端改了布局或者修改了代码,导致原本的定位方法失效,这种情况,我们的处理方案是,使用相对定位,并且尽可能的完善定位元素的代码,结合多种定位方式,确保每一次能够准确定位;
第三点:执行速度慢,由于 UI 自动化,耗时比较久,我们有几种解决办法,第一种是尽量减少强制等待的时间,第二种是采用 pytest 的多线程执行,第三种是使用更加简单的进入路径,比如,进入某个页面实现自动化,我们可以直接打开该页面的 url 路径,而不是通过一层一层点击进入;
第四点:用例执行失败,我们会采用 pytest 的用例失败重新运行的方法;
第五点:执行过程,画面回放,有时候,用例执行失败了,我们想去复现,以及查看失败的原因,虽然有充足的日志记录,但是远远不够,所以,我们增加画面录制的回放功能,我们实现的办法,比较简单有效,就是在执行每一个操作步骤后,自动截屏,保存到一个临时文件,最后用例执行完之后,把所有的临时图片合并成 gif 保存起来,这样,我们就可以通过 gif 图片,查看执行过程的画面回放。
-
大家都是怎样提取软件测试点的呢?? at 2023年06月20日
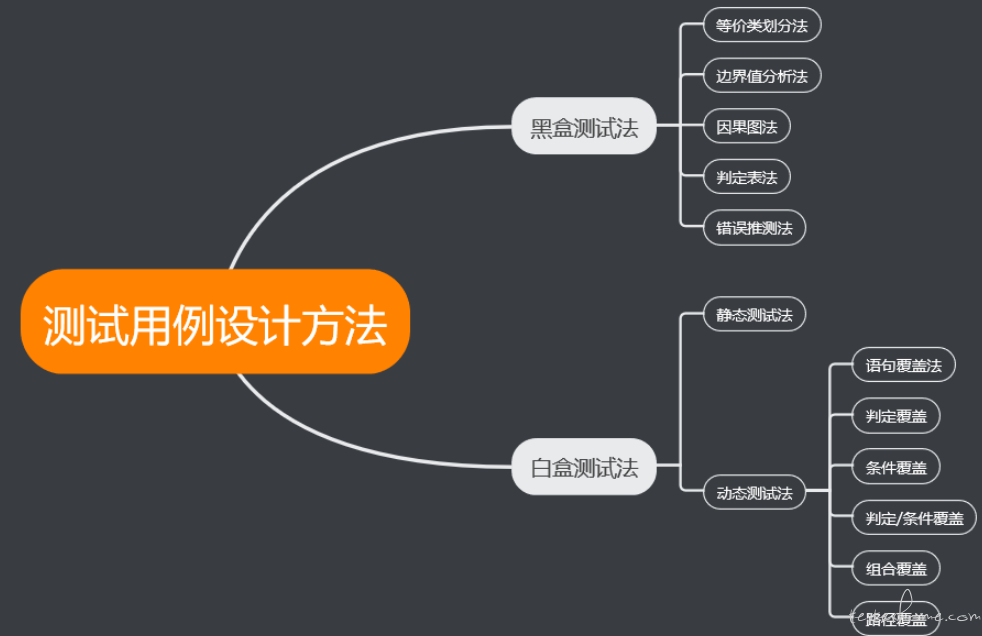
先抓住系统性的方法,再逐个学习。 -
人心浮动的今天我们还能否安心的做个测试! at 2023年06月20日
测试精通这些,性价比太低了,天花板确实不高,并且吃香的测试的岗位并不多。
-
人心浮动的今天我们还能否安心的做个测试! at 2023年06月20日
不妨把时间拉回到 5 年前,那个时候,不也是开始卷自动化,selenium。
现在呢?selenium 反而成为了每个测试人员的 “标配”。卷是迟早的,市场需求决定,不迎合市场需求,注定会被替代或者淘汰。
-
【pytest】请问下为啥每一个用例都执行两次了 at 2023年06月16日
这个是 logging 日志器的问题,应该是重复实例化了两次,需要排查一下,哪些地方实例化了 logging
-
【技术方案】关于 Excel 关键字驱动自动化测试框架的技术架构 at 2023年06月16日 企业效益,你懂得,不可能每个人都懂代码,要不然,也不会有测试开发这种岗位
-
严肃讨论一下测试护城河问题 at 2023年06月16日
省流:题主在很严肃的在讨论护城河的问题
-
测试需要解决问题吗??????? at 2023年06月15日
看情况,有时候,开发就是自己不动脑子,自己不去思考解决方案,反而,要让测试说怎么改,这种情况,当然直接回绝,测试只看结果,结果符合需求就可以,具体怎么实现,开发自己解决。
-
测试需要解决问题吗??????? at 2023年06月15日
协助解决问题
-
【技术方案】关于 Excel 关键字驱动自动化测试框架的技术架构 at 2023年06月15日
这种太灵活的需求,UI 自动化不太适合,UI 自动化本质上是代替人工,自动回归功能,并不是为了测试功能有没有 bug。
所以,不能偏离自动化的初衷,如果要这样搞,UI 自动化的脚本那是要费好大力气维护,得不偿失。
除非这种不得不做,如果是我肯定选择简单的方式实现;
-
【技术方案】关于 Excel 关键字驱动自动化测试框架的技术架构 at 2023年06月14日
这个 not,我还是第一次知道,可以同时判断,None 和 空字符串,,,学到了,,谢谢大佬
-
【技术方案】关于 Excel 关键字驱动自动化测试框架的技术架构 at 2023年06月14日
其实不然,这种 Excel 自动化测试框架,应该用的公司还是蛮多,主要考虑到团队,技术水平不统一,使用 Excel 可以降低学习成本,适合代码能力不强的测试人员,只要稍加培训,怎么使用关键字函数就可以快速上手,编写自动化测试用例。
当然,最好的方式,就是用自动化测试平台。。
-
聊聊如何怎编写好一个用户使用手册 at 2023年06月14日
借鉴