-
改写一个简单的 MCP Chat Client at 2026年04月09日
懒得再写新文章了,以此回帖代替。
今年的 MCP 已经被冷落了,为了继续有价值,针对 MCP 一次性扁平化塞入大模型的系统提示词,接入很多 MCPserver 造成上下文臃肿,tool 命中率变低情况。做了类似 skill 式或者意图识别类的改造:
1、mcp-server 中每个 server 配置中增加"when-to-use",告知大模型此 sever 能干啥
2、现有大模型先读取 servers 的"when-to-use",找到需要的 server 和需要做的步骤操作
3、获取此 sever 下的 tools 动态插入系统提示词,让大模型去找到对 tool 然后执行用户提问->大模型 server 路由->加载单个 server 的 tools->大模型找到 tool 并执行->大模型识别结果
-
AI 与测试结合:下 1 个可行工作--MCP 实现 BUG 自动回归 at 2025年09月17日
不方便给完整的,思路是使用 MCP Client 传递 BUG 步骤及问题定位的元素,去调用 Browser User 的包装的 MCP Server,然后将获取的对应 BUG 中元素的当前的值,再交给到模型比对是否和预期一致。
目前只是提出了一些思路和不完善的设计。做出一些小的 demo 也仅限于那种步骤简单明确,问题元素也很容易定位那种,而且大模型的 token 数消耗蛮大的。
验证了一些可行性,至少是这些挑选过的 BUG -
AI 与测试结合:下 1 个可行工作--MCP 实现 BUG 自动回归 at 2025年09月14日
统一回复一下,目前有这个想法,是使用了一段时间 browser Use 和 CC+Playwright MCP。
browser Use 他能将你的语义步骤(无需提供 xpath 及 css locator)转换为自动化,虽然成功率视流程及页面元素影响,但针对页面很明确(直接访问到 URL),找到指定元素是可以的。
CC+Playwright MCP:目前在 prompts 调教好的情况,能将你的任务自动拆分执行计划,目前已经在一些业务测试验收:比如自动访问搜索页面,输入关键词或自然语义进行搜索,并将搜索到的商品名称、价格、特殊属性进行获取,并和输入关键词或自然语义通过大模型进行匹配度校验并给出结果报告。那同样针对一些流程简单、异常元素定位明确的 BUG,可以去尝试自动化校验。但这个能否自动执行需要看选择的模型,有的模型会自动,有的每个步骤都需要你去确认。
个人推荐思路,如果想要通畅,可以 MCP+Browser Use,Browser Use 也提供了 MCP 接入,可以考虑整合起来。
上面有小伙伴问是否需要提供定位(xpath),browser Use、【Playwright MCP+ 大模型】目前都是可以语义定位(比如登录名输入框,你直接说 “登录名输入框” 即可;页面中的回复信息的第 1 条,直接这么说即可”),当然你的语义定位要精确些,比如这里
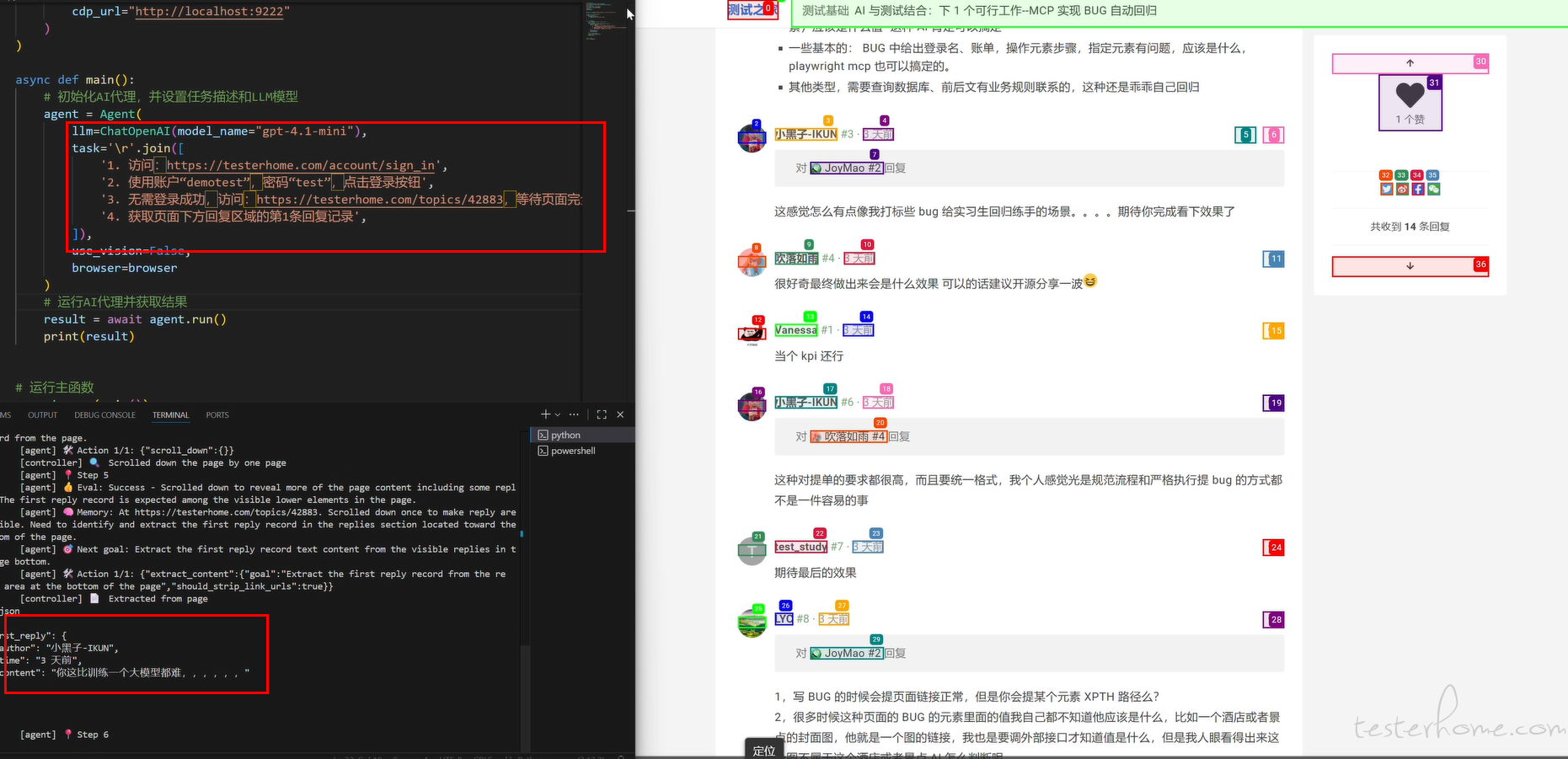
另外,这里只是针对 BUG 回归,回归当前你提出问题本身:期望与实际是否一致,没有要求其发散更多,也没要求去联系业务,这种交给自己去做;
在一个新的、较紧急业务开发中,业务信息不对、不完整类的 BUG 其实占比还是比较多的,这些应该比较合适使用 AI 回归。
回归 bug 占用时间问题,得看 BUG 多不多,什么时候回归。如果任务紧,bug 回归作为最后的系统回归的一部分时,面对堆积的 BUG,可以省去一些时间。当然,这个也是我使用 CC+Playwright MCP+BrowserUse 应用于 AI 验证搜索结果项目中,产生的可以认为是 KPI 想法;也简单验证了一个 “某某页面,用户审核状态有误,应该是 xx,实际是 yy” 的 BUG demo。
提出来,也是希望抛砖引玉、集思广益。
感谢所有回复的同学 -
AI 与测试结合:下 1 个可行工作--MCP 实现 BUG 自动回归 at 2025年09月12日
这里没有要求 AI 回归具备通用性,而且可以在提交 BUG 时,判断是否 AI 回归,打上标志即可:
- 比如有些极其简单的: BUG 中已经给出某个页面:” 提供了 BUG 的页面 URL,哪个地方(元素)应该是什么值 “这种 AI 肯定可以搞定
- 一些基本的: BUG 中给出登录名、账单,操作元素步骤,指定元素有问题,应该是什么,playwright mcp 也可以搞定的。
- 其他类型,需要查询数据库、前后文有业务规则联系的,这种还是乖乖自己回归
-
是否有 AI 在测试方面落地成功方案 at 2025年08月04日
应付 KPI 的话,可以尝试 MCP 方向:写点查询业务数据、调用自动化、辅助工作流方向
-
playwright/mcp 的一种工作实践——和自定义 MCP Server 的 playwright 自动化脚本结合 at 2025年06月09日
1、这里只是举了一个简单表单例子,如果是复杂的长流程过程,是要事先准备好自动化脚本的
2、playwright/mcp 本身只是一个 Tools,如果要很智能的完成输入"帮我完成这个表单"就能自动填写表单,需要你对接的大模型或智能体 “足够智能”,但也会面临一大堆失败/错误,需要你不断对话调整的过程:可以尝试一下或参考之前论坛中的帖子。
而如果使用一般的大模型,你就需要重复的如下进行:
AI:"你是否做 xx1?" - 你:” 是的 “
AI:"你是否做 xx2?" - 你:” 是的 “
AI:"你是否做 xx3?" - 你:” 是的 “
...
这样效率不高的
3、但 playwright/mcp 可以录制你的过程变成脚本,倒是方便不少 -
playwright/mcp 的一种工作实践——和自定义 MCP Server 的 playwright 自动化脚本结合 at 2025年06月05日
其实是把 MCP 作为一个工作智能助手,在浏览器相关测试中,可以通过 prompts
- 操作页面或抓取信息 (playwright/mcp)
- 将页面操作自动生成自动化脚本 (playwright/mcp)
- 调用自动化脚本快速完成一些常用流程操作 (自定义 mcp 调用 playwright 脚本)
- 通过页面字段,快速查询库表中相关信息核对(自定义 mcp 编写模板化 sql 查询库表工具)
- 获取截图 + 问题描述快速提交 BUG 到你们的项目平台(自定义 mcp 调用 API)
- 获取截图 + 描述通过内部通信工具快速发送给相关同事(自定义 mcp 调用 API) 等等
-
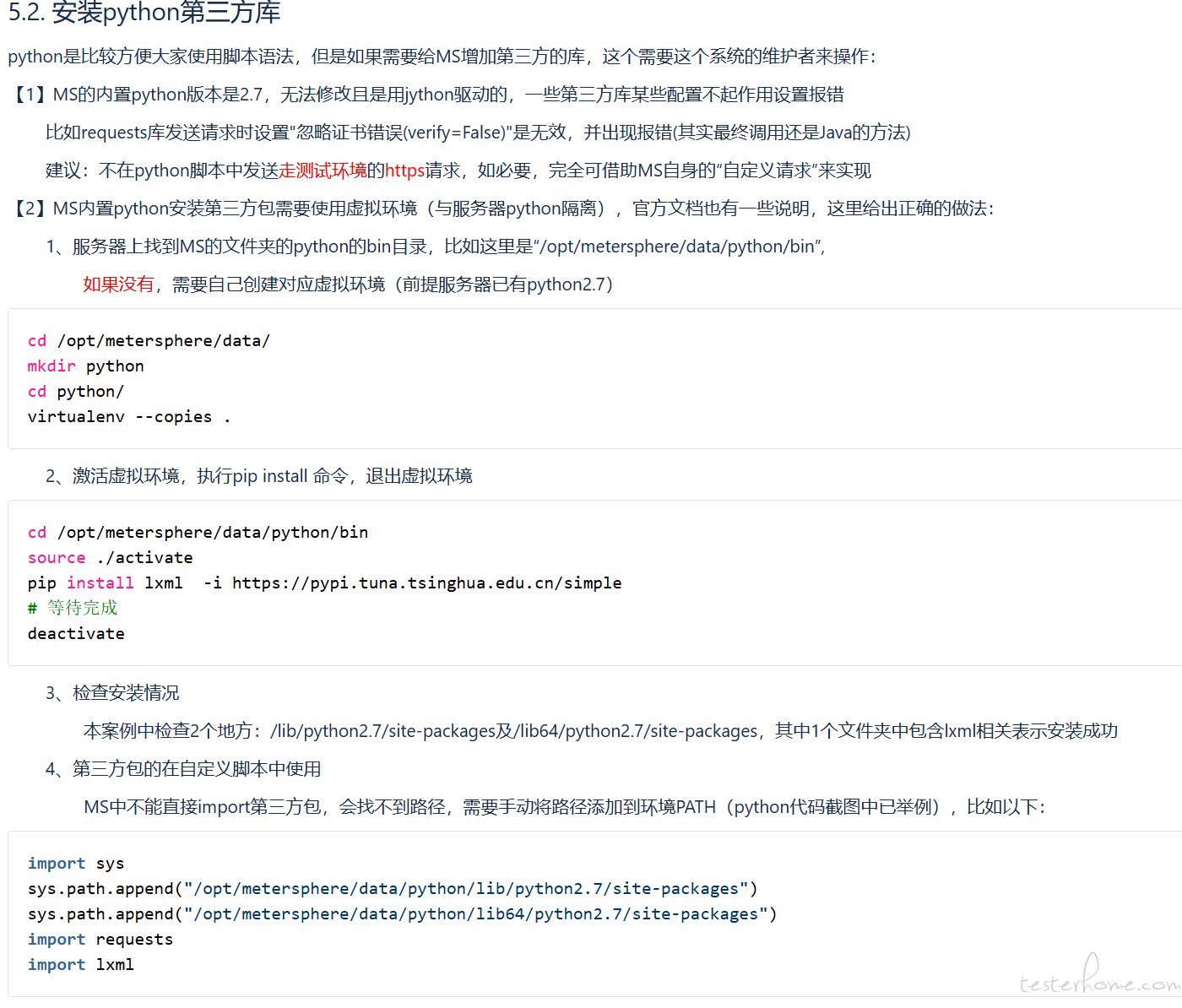
以前的笔记,可以参考以下(可能有错误)
-
看来我是真的不适合华为系的。。。 at 2024年10月25日
同样是 10 多年前,南京华为,很多人一起模拟团队那种面试,不知道这做叫什么
-
公司裁员,一般是根据能力高低,还是性价比高低来裁? at 2024年07月23日
-
震惊!! 路由器与 Robot Framework 七型的爱🙄 at 2024年06月11日
没必要吐槽 RF 和使用 pytest 写脚本证明啥的。
夸张的说 python 现在的支持的库多的几乎没有没不涵盖的,这和什么测试框架没有关系。刚做自动化时自然会接触 RF,本能就 skip 了,因为也搞过个使用 excel+unittest 做类似关键词驱动的东西玩玩,太不灵活了,哪有写脚本灵活。但对于项目关联角度来说,选择框架还是很有用的,pytest 也是目前最好的选择了。
有的项目已经 7、8 年了,用了目前看来已经 “过时” 的框架,如果这块业务还在运营,大裁员环境下,还有人有多的余力去大改造吗,小改小调是不是还得懂些 “过时” 的框架.
至于 “培训” 嘛,只能说挣钱不寒碜
-
关于 Xmind 用例在线管理的探讨 at 2024年04月23日
市面上有不少基于百度脑图开发的思维导图在线用例工具
-
社区定制笔记本套装收到了 at 2024年04月19日
我前年兑换的杯子依然等待发货....

-
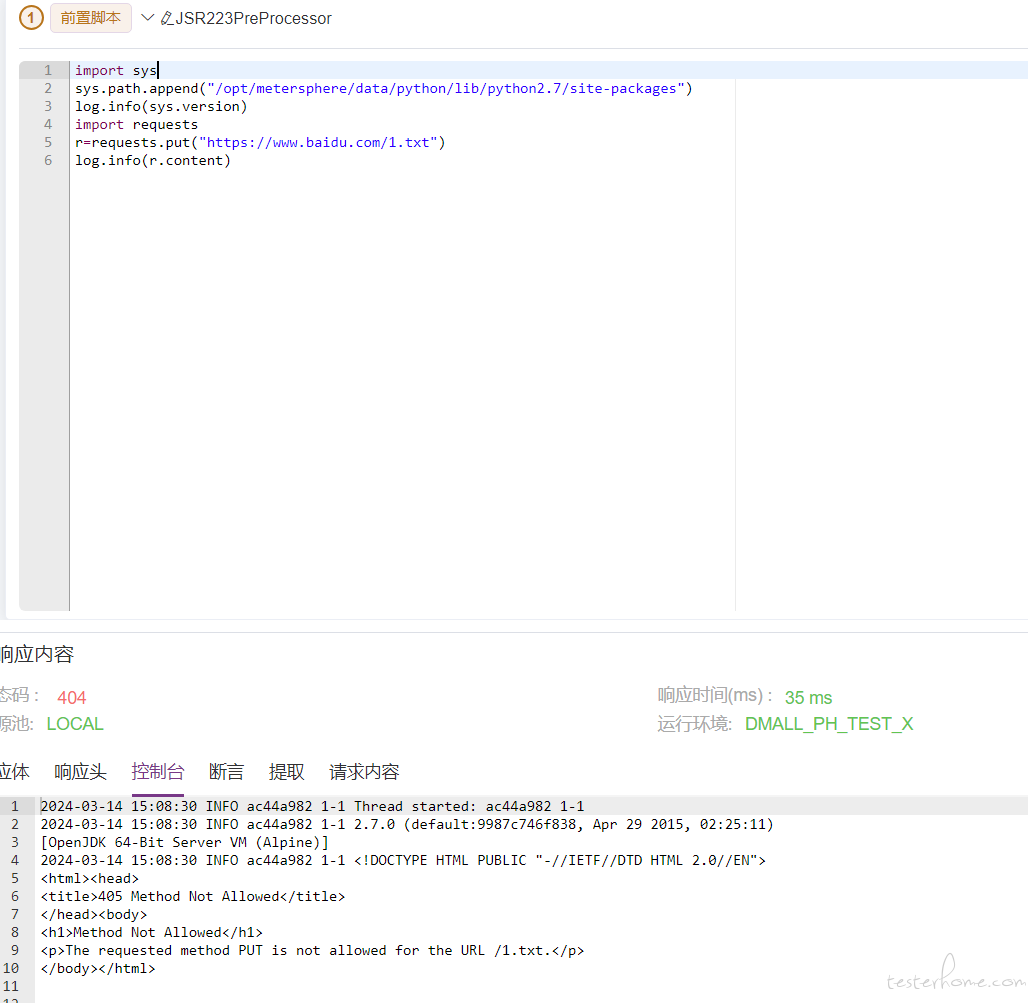
前置 python 脚本:requests 无法请求,报错请问是什么原因 at 2024年03月14日
首先 metersphere 使用 python 的第三方包,先参考:
https://zhuanlan.zhihu.com/p/446668517?utm_id=0
按这里做法,我尝试是可以的
-
UI 自动化 at 2023年12月28日
多年以来,UI 自动化都是虎头蛇尾的多,很少持续 2 年以上的:
除了自动化技术的迭代,更多是因为大环境下,很多业务持续的时间不够长,对应 UI 更不用说了。相对的更有效的是接口自动化测试、甚至流量回放测试,UI 的部分靠人工保证是更有性价比的
-
如何识别算术型验证码? at 2023年11月21日
如果能被自动化【轻易】搞定的验证码,那还搞的目的是什么?
验证码的目的本来就是要区分人和机器,最低目的也是要大大增加自动化验证的成本。
所以如果对自己公司的系统:
测试环境:给自动化测试提供直接跳过的功能,至于验证码本身功能通过人工去测试。
生产环境:先人工完成登录,然后通过 connect 的方式去执行自动化脚本 -
大模型时代下的测试畅想 at 2023年11月09日
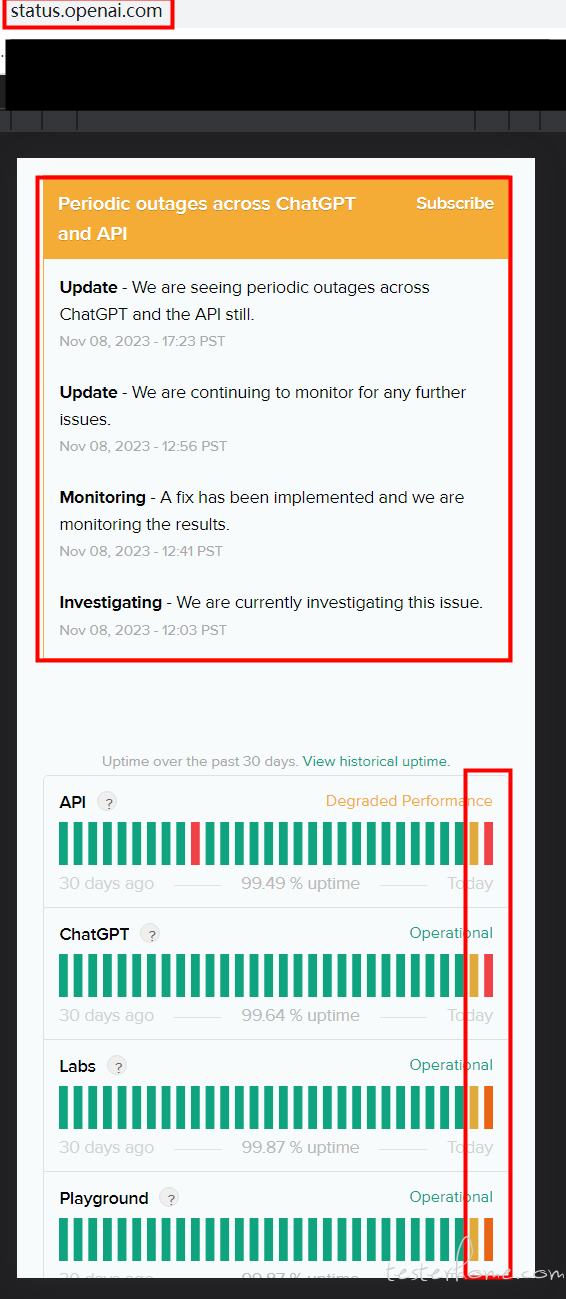
昨晚又出故障了,最近 openAI 升级后各种故障:
-
大模型时代下的测试畅想 at 2023年11月08日
今天服务挂了,现在应该好了
-
playwright 在免登录问题 at 2023年10月19日
content/page.on("request", handler),在 handler 中打印一下你的请求头看看、检查一下。
-
一张图让我破防了 at 2023年10月18日
只是对卷心菜这个说法感觉有意思:在一个都是低水平的地方卷,卷的再好,在外面来看还是低水平。
裂开了则不是我思考的地方
-
大家测试平时是如何传图片的 at 2023年09月04日
最简单的方法其实就是最古老的方法:ASP 的上传下载服务
-
帮忙推荐一个用 Python 写的、开源的测试用例管理平台 at 2023年09月04日
5 年前也有一样的问题,搜刮全网,开源的普遍的是 php,少量 java,而且不好用;最后跟领导说一下,最后决定自给自足了。
-
各位大神,大家都用什么开源测试用例管理平台? at 2023年07月21日
自研的话可以契合本公司/部门的需求。
我们这里是偏业务的公司,测试用例几乎可当需求归档的。
而且用例容量日积月累,层级复杂。一些开源工具的的层级管理就不太满足了,所以要自研。
至于备份,定时任务 dump 就好了。 -
机器的配置倍数增涨,可以认为性能也是成倍数增涨吗???线性关系 at 2023年07月06日
如果性能能这样计算,也

一个应用调用链涉及到多个服务,每个服务都是影响性能的。
代码写的差,再好的硬件也救不了
不能充分利用多核,cpu 再多核心也没用 -
调用 GPT3.5 生成思维导图用例 at 2023年06月21日
没有特别去找过特定的论坛,但 github 上有相关项目是关于 chatgpt prompt 的:https://github.com/f/awesome-chatgpt-prompts
我们这个例子中的提示语是不断完善出来的,把大家日常中遇到的各种异常都存下来,逐渐调试出来的。