杂
-
81 个赞 / 56 条回复
-
13 个赞 / 7 条回复
-
13 个赞 / 3 条回复
-
12 个赞 / 4 条回复
-
11 个赞 / 2 条回复
-
6 个赞 / 25 条回复
-
6 个赞 / 9 条回复
-
5 个赞 / 5 条回复
-
5 个赞 / 1 条回复
-
3 个赞 / 19 条回复
-
3 个赞 / 0 条回复
-
2 个赞 / 1 条回复
-
2 个赞 / 4 条回复
-
2 个赞 / 0 条回复
-
2 个赞 / 1 条回复
-
2 个赞 / 0 条回复
-
2 个赞 / 14 条回复
-
2 个赞 / 0 条回复
-
1 个赞 / 0 条回复
-
1 个赞 / 0 条回复
-
1 个赞 / 1 条回复
-
1 个赞 / 4 条回复
-
1 个赞 / 2 条回复
-
0 个赞 / 0 条回复
-
0 个赞 / 2 条回复
-
改写一个简单的 MCP Chat Client at 2026年04月09日
懒得再写新文章了,以此回帖代替。
今年的 MCP 已经被冷落了,为了继续有价值,针对 MCP 一次性扁平化塞入大模型的系统提示词,接入很多 MCPserver 造成上下文臃肿,tool 命中率变低情况。做了类似 skill 式或者意图识别类的改造:
1、mcp-server 中每个 server 配置中增加"when-to-use",告知大模型此 sever 能干啥
2、现有大模型先读取 servers 的"when-to-use",找到需要的 server 和需要做的步骤操作
3、获取此 sever 下的 tools 动态插入系统提示词,让大模型去找到对 tool 然后执行用户提问->大模型 server 路由->加载单个 server 的 tools->大模型找到 tool 并执行->大模型识别结果
-
AI 与测试结合:下 1 个可行工作--MCP 实现 BUG 自动回归 at 2025年09月17日
不方便给完整的,思路是使用 MCP Client 传递 BUG 步骤及问题定位的元素,去调用 Browser User 的包装的 MCP Server,然后将获取的对应 BUG 中元素的当前的值,再交给到模型比对是否和预期一致。
目前只是提出了一些思路和不完善的设计。做出一些小的 demo 也仅限于那种步骤简单明确,问题元素也很容易定位那种,而且大模型的 token 数消耗蛮大的。
验证了一些可行性,至少是这些挑选过的 BUG -
AI 与测试结合:下 1 个可行工作--MCP 实现 BUG 自动回归 at 2025年09月14日
统一回复一下,目前有这个想法,是使用了一段时间 browser Use 和 CC+Playwright MCP。
browser Use 他能将你的语义步骤(无需提供 xpath 及 css locator)转换为自动化,虽然成功率视流程及页面元素影响,但针对页面很明确(直接访问到 URL),找到指定元素是可以的。
CC+Playwright MCP:目前在 prompts 调教好的情况,能将你的任务自动拆分执行计划,目前已经在一些业务测试验收:比如自动访问搜索页面,输入关键词或自然语义进行搜索,并将搜索到的商品名称、价格、特殊属性进行获取,并和输入关键词或自然语义通过大模型进行匹配度校验并给出结果报告。那同样针对一些流程简单、异常元素定位明确的 BUG,可以去尝试自动化校验。但这个能否自动执行需要看选择的模型,有的模型会自动,有的每个步骤都需要你去确认。
个人推荐思路,如果想要通畅,可以 MCP+Browser Use,Browser Use 也提供了 MCP 接入,可以考虑整合起来。
上面有小伙伴问是否需要提供定位(xpath),browser Use、【Playwright MCP+ 大模型】目前都是可以语义定位(比如登录名输入框,你直接说 “登录名输入框” 即可;页面中的回复信息的第 1 条,直接这么说即可”),当然你的语义定位要精确些,比如这里
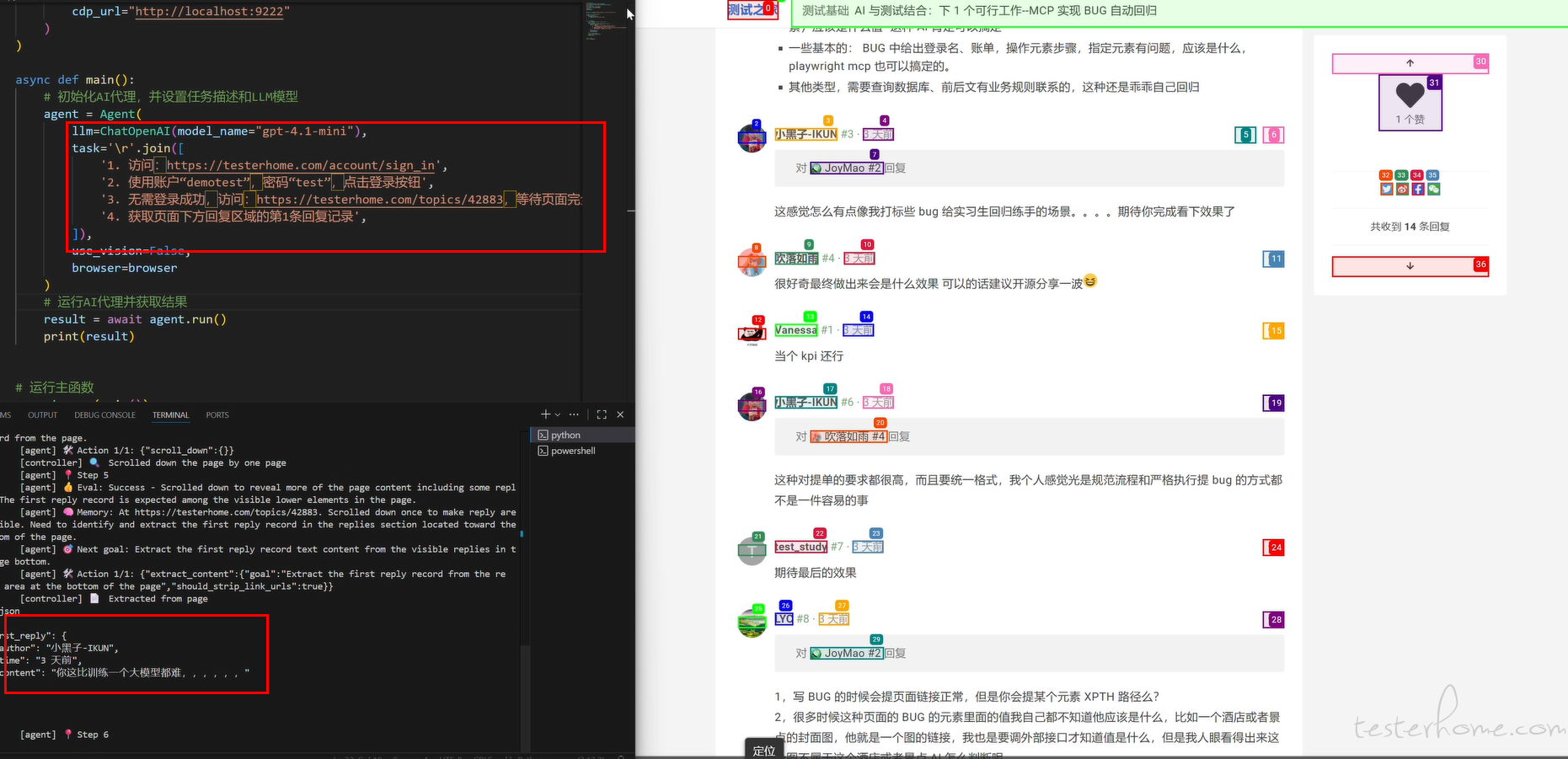
另外,这里只是针对 BUG 回归,回归当前你提出问题本身:期望与实际是否一致,没有要求其发散更多,也没要求去联系业务,这种交给自己去做;
在一个新的、较紧急业务开发中,业务信息不对、不完整类的 BUG 其实占比还是比较多的,这些应该比较合适使用 AI 回归。
回归 bug 占用时间问题,得看 BUG 多不多,什么时候回归。如果任务紧,bug 回归作为最后的系统回归的一部分时,面对堆积的 BUG,可以省去一些时间。当然,这个也是我使用 CC+Playwright MCP+BrowserUse 应用于 AI 验证搜索结果项目中,产生的可以认为是 KPI 想法;也简单验证了一个 “某某页面,用户审核状态有误,应该是 xx,实际是 yy” 的 BUG demo。
提出来,也是希望抛砖引玉、集思广益。
感谢所有回复的同学 -
AI 与测试结合:下 1 个可行工作--MCP 实现 BUG 自动回归 at 2025年09月12日
这里没有要求 AI 回归具备通用性,而且可以在提交 BUG 时,判断是否 AI 回归,打上标志即可:
- 比如有些极其简单的: BUG 中已经给出某个页面:” 提供了 BUG 的页面 URL,哪个地方(元素)应该是什么值 “这种 AI 肯定可以搞定
- 一些基本的: BUG 中给出登录名、账单,操作元素步骤,指定元素有问题,应该是什么,playwright mcp 也可以搞定的。
- 其他类型,需要查询数据库、前后文有业务规则联系的,这种还是乖乖自己回归
-
是否有 AI 在测试方面落地成功方案 at 2025年08月04日
应付 KPI 的话,可以尝试 MCP 方向:写点查询业务数据、调用自动化、辅助工作流方向
-
playwright/mcp 的一种工作实践——和自定义 MCP Server 的 playwright 自动化脚本结合 at 2025年06月09日
1、这里只是举了一个简单表单例子,如果是复杂的长流程过程,是要事先准备好自动化脚本的
2、playwright/mcp 本身只是一个 Tools,如果要很智能的完成输入"帮我完成这个表单"就能自动填写表单,需要你对接的大模型或智能体 “足够智能”,但也会面临一大堆失败/错误,需要你不断对话调整的过程:可以尝试一下或参考之前论坛中的帖子。
而如果使用一般的大模型,你就需要重复的如下进行:
AI:"你是否做 xx1?" - 你:” 是的 “
AI:"你是否做 xx2?" - 你:” 是的 “
AI:"你是否做 xx3?" - 你:” 是的 “
...
这样效率不高的
3、但 playwright/mcp 可以录制你的过程变成脚本,倒是方便不少 -
playwright/mcp 的一种工作实践——和自定义 MCP Server 的 playwright 自动化脚本结合 at 2025年06月05日
其实是把 MCP 作为一个工作智能助手,在浏览器相关测试中,可以通过 prompts
- 操作页面或抓取信息 (playwright/mcp)
- 将页面操作自动生成自动化脚本 (playwright/mcp)
- 调用自动化脚本快速完成一些常用流程操作 (自定义 mcp 调用 playwright 脚本)
- 通过页面字段,快速查询库表中相关信息核对(自定义 mcp 编写模板化 sql 查询库表工具)
- 获取截图 + 问题描述快速提交 BUG 到你们的项目平台(自定义 mcp 调用 API)
- 获取截图 + 描述通过内部通信工具快速发送给相关同事(自定义 mcp 调用 API) 等等
-
以前的笔记,可以参考以下(可能有错误)
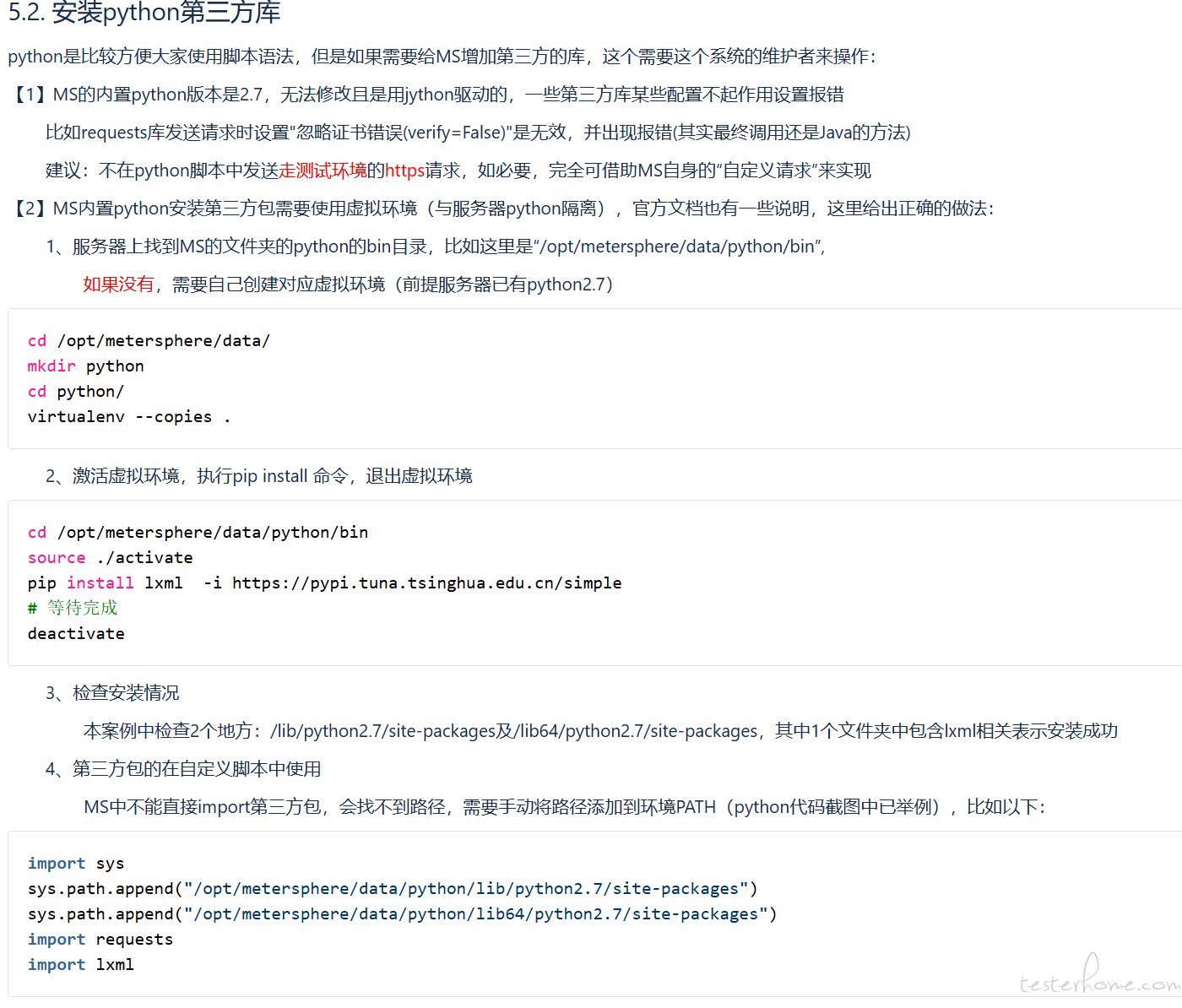
-
看来我是真的不适合华为系的。。。 at 2024年10月25日
同样是 10 多年前,南京华为,很多人一起模拟团队那种面试,不知道这做叫什么
-
公司裁员,一般是根据能力高低,还是性价比高低来裁? at 2024年07月23日
杂