目前在测试部的各个测试人员都开始使用 MCP 了,部门也有了自己的测试 MCP Server,主要集中在常规流程自动化,常用业务信息查询,各种 JIRA 任务查询,日常工作相关查询。
之前我提了自定义脚本 MCP+playwright MCP 合作方式的想法,目前也应用于当前的测试工作中,效果还行。
下一步呢,想通过 MCP 实现 BUG 自动回归,其实这个可实现性很高:
1、本身 BUG 规范情况下,会有完整的操作步骤,实际问题,期望结果:这个借助 playwright MCP+ 大模型是可以自动化执行的;而实际问题,期望结果也可以进行对应元素比对
2、如果 BUG 有截图,有条件公司的大模型可以读图获取 BUG 框选处情况,能更加精确的判断原 BUG 问题及现在是否修复
3、【前期尝试】可以主动在添加 BUG 时,判断此 BUG 是否可以借助 AI 回归,那就可以进行打标或者标题中有特殊字符。
4、我们使用 JIRA 管理 bug,可以在标题中加入 [AI 回归],在自定义 MCP 中使用过滤器查询出这些待回归的 BUG 的标题、描述;然后规划好任务,让 playwright mcp+ 大模型去一一验证是否回归通过。
5、另外,可以借助 MCP Prompts,直接将整个任务过程编辑为重复使用的 Prompt,可以直接使用
你这比训练一个大模型都难,,,,,,,
这里没有要求 AI 回归具备通用性,而且可以在提交 BUG 时,判断是否 AI 回归,打上标志即可:
- 比如有些极其简单的: BUG 中已经给出某个页面:” 提供了 BUG 的页面 URL,哪个地方(元素)应该是什么值 “这种 AI 肯定可以搞定
- 一些基本的: BUG 中给出登录名、账单,操作元素步骤,指定元素有问题,应该是什么,playwright mcp 也可以搞定的。
- 其他类型,需要查询数据库、前后文有业务规则联系的,这种还是乖乖自己回归
很好奇最终做出来会是什么效果 可以的话建议开源分享一波
当个 kpi 还行
期待最后的效果
1,写 BUG 的时候会提页面链接正常,但是你会提某个元素 XPTH 路径么?
2,很多时候这种页面的 BUG 的元素里面的值我自己都不知道他应该是什么,比如一个酒店或者景点的封面图,他就是一个图的链接,我也是要调外部接口才知道值是什么,但是我人眼看得出来这个图不属于这个酒店或者景点 AI 怎么判断呢
3,大模型怎么理解你的操作步骤和预期结果,因为这里面有你具体的业务知识,给他配一个知识库么?
 哎,登录态,用户影响回归,纯 web 端,配置复杂一下就麻烦,关键 mcp 也是通过指令去驱动想想就不想搞就只能当玩具
哎,登录态,用户影响回归,纯 web 端,配置复杂一下就麻烦,关键 mcp 也是通过指令去驱动想想就不想搞就只能当玩具
可以具体分享一下现有的么?
画蛇添足,回归 bug 才占多少工作量
额...我觉得空闲时间多的话可以玩一下
我这里提一个很普遍且很简单的场景,一个非常经典、简单的小 BUG,应该符合楼主打标的标准
bug 背景:
- 标题:注册页 - 用户名输入框超过 20 字符时,前端未正确截断,导致提交后后端报错
- 步骤:
- 1.进入游客页的注册页(url="https://testerhome.com/addUser")
- 2.在用户名输入框中输入超过 20 个字符
- 3.观察到前端未有长度提示限制、无截断操作、能发起提交
- 预期:输入框应自动限制和提醒用户最多只能输入 20 个字符
如何解决接下来的这些麻烦:
1“进入注册页”
这个注册页如果需要先登录才能访问?AI 如何获取有效的测试账号和密码?是要在 bug 单里写上测试帐号和密码?还是在配置文件里加上通用的测试帐号和密码?
出于安全合规的要求,测试账号都需要区分环境(开发 / 测试 / 预发)、定期轮换密码、处理账号状态(被锁 / 过期 / 权限变更),每次账号变动都要人工同步更新 AI 配置吗?
若进入注册页有其他事件的弹窗干扰,怎么处理?
2” 找到用户名输入框 “
- a 方法: 将整个注册页的 DOM 发送给大模型,让它自己找(产生高昂的 Token 成本,且速度慢)
- b 方法:在创建 BUG 时,人工为 AI 提供定位器 page.getByLabel('Username'))(相当奇怪的做法)
- c 方法:用 "语义 + 视觉" 混合定位识别(类似 airtest 的图像识别,依然是成本不划算)
3” 断言 “
【“前端未有长度提示限制、无截断操作、能发起提交” 这一描述对人类清晰,但对 AI 是模糊的】
-【前端未有长度提示限制】提示是文本(如 "最多 20 字符")还是图标?出现在输入框上方还是下方?是否有特定 role="alert"属性?这些细节若不在 BUG 描述中写明,AI 会陷入猜测;若要写清,本质是让测试人员提前完成 "断言设计",AI 沦为执行工具,却额外支付了 AI 调用成本
【无截断操作】AI 在输入 21 个字符后,是否需要执行 await input.value() 来获取输入框的值,并断言其长度等于 21?,截断逻辑是 "输入时实时截断" 还是"失焦后截断” 这些都要在 bug 单上写明吗?
如果提示有了,但是截断逻辑没有修复,填写了 21 个字符后产生报错提示。AI 是否能验证提交? 检查提交按钮的 disabled 属性是否为 false?还是让 AI 真正点击提交按钮,然后判断是否发出请求?
我让 AI 生成可以让 AI 回归更快捷的 bug 单,它给出以下回复
【AI 回归】注册页 - 用户名输入框超过 20 字符未截断导致后端报错
一、元数据(供 AI 快速识别场景)
- 适用 AI 回归:是
- 依赖环境:测试环境(固定 URL:
https://test.testerhome.com/addUser)
- 前置状态:需游客身份(无需登录,若页面强制跳转登录页,使用预设账号:
{TEST_ACCOUNT},密码:{TEST_PWD},从环境变量读取)
- 干扰项处理:若页面加载后 3 秒内出现 “隐私协议弹窗”,优先点击
//button[text()='同意并继续'](定位器固定)
二、操作步骤(精确到 AI 可执行的原子动作)
| 步骤编号 | 操作类型 | 具体指令(含定位器/参数) | 执行约束条件 |
|---|---|---|---|
| 1 | 页面访问 | 打开 URL:https://test.testerhome.com/addUser,等待页面加载完成(判断标准://form[@id='register-form']可见) |
超时时间:10 秒,失败则标记 “环境异常” |
| 2 | 元素定位 | 定位用户名输入框:page.getByLabel('用户名', {exact: true})(备选定位器://input[@name='username']) |
若主定位器失败,自动尝试备选 |
| 3 | 输入操作 | 向输入框输入固定字符串:"testuser1234567890abcdef"(共 25 字符,纯英文无特殊符号) |
输入速度:每字符间隔 50ms,模拟人工输入 |
| 4 | 提交操作 | 定位提交按钮://button[@type='submit' and text()='注册'],执行点击操作 |
点击前确认按钮disabled属性为false
|
三、断言规则(分解为可量化的验证点)
1. 前端长度提示验证
- 验证对象:错误提示元素(定位器:
//div[@class='error-hint' and @for='username'])
- 断言条件:输入第 21 字符后 300ms 内,该元素可见且文本包含 “最多 20 个字符”(忽略标点/大小写差异)
- 失败判定:超过 1 秒未出现提示,或提示文本不含 “20”
2. 前端截断逻辑验证
- 验证对象:用户名输入框的
value属性
- 断言条件:输入完成后(步骤 3 结束后 1 秒),获取输入框值,长度必须≤20 字符
- 特殊场景:若输入框采用 “失焦后截断” 逻辑(需在 BUG 单补充说明),则需在输入后执行
blur()操作,再断言值长度
3. 提交拦截验证
- 验证方式:拦截提交请求(接口路径:
/api/register)
- 断言条件:
- 若提示和截断均生效:请求不应发出
- 若提示生效但未截断:请求可发出,但请求体中
username字段长度必须≤20(后端截断场景)
- 若均未生效:请求发出且
username长度=25 → 判定 BUG 未修复
- 若提示和截断均生效:请求不应发出
四、异常处理规则(告诉 AI“遇到问题怎么办”)
- 若步骤 2 定位输入框失败:自动截图并标记 “元素定位失败”,终止执行(不判定 BUG 状态)
- 若提交后页面跳转至错误页(
//div[@id='error-page']可见):视为后端报错,判定 BUG 未修复
- 若测试过程中出现未预设弹窗:截图并记录弹窗文本,标记 “未知干扰”,转人工处理
五、验收标准(明确 “通过/失败” 的刚性条件)
- 回归通过:满足以下全部
- 提示验证通过(出现含 “20 字符” 的提示)
- 截断验证通过(输入框值≤20 字符)
- 提交拦截验证通过(无超长数据提交)
- 提示验证通过(出现含 “20 字符” 的提示)
- 回归失败:任意一项验证未通过
就如果按 AI 这个写法,一个三四分钟就能回归的简单 bug,足足在 bug 单上就耗时至少 20 分钟
最后业务测试做多的人都会知道,bug 回归的核心是 “验证动态变化的功能”,就是 UI 可能改、逻辑可能调、异常场景可能新增
毕竟是面向人的验证工作,当然我不是找茬,只是感觉想用 AI 去做回归,真心有点难
统一回复一下,目前有这个想法,是使用了一段时间 browser Use 和 CC+Playwright MCP。
browser Use 他能将你的语义步骤(无需提供 xpath 及 css locator)转换为自动化,虽然成功率视流程及页面元素影响,但针对页面很明确(直接访问到 URL),找到指定元素是可以的。
CC+Playwright MCP:目前在 prompts 调教好的情况,能将你的任务自动拆分执行计划,目前已经在一些业务测试验收:比如自动访问搜索页面,输入关键词或自然语义进行搜索,并将搜索到的商品名称、价格、特殊属性进行获取,并和输入关键词或自然语义通过大模型进行匹配度校验并给出结果报告。那同样针对一些流程简单、异常元素定位明确的 BUG,可以去尝试自动化校验。但这个能否自动执行需要看选择的模型,有的模型会自动,有的每个步骤都需要你去确认。
个人推荐思路,如果想要通畅,可以 MCP+Browser Use,Browser Use 也提供了 MCP 接入,可以考虑整合起来。
上面有小伙伴问是否需要提供定位(xpath),browser Use、【Playwright MCP+ 大模型】目前都是可以语义定位(比如登录名输入框,你直接说 “登录名输入框” 即可;页面中的回复信息的第 1 条,直接这么说即可”),当然你的语义定位要精确些,比如这里
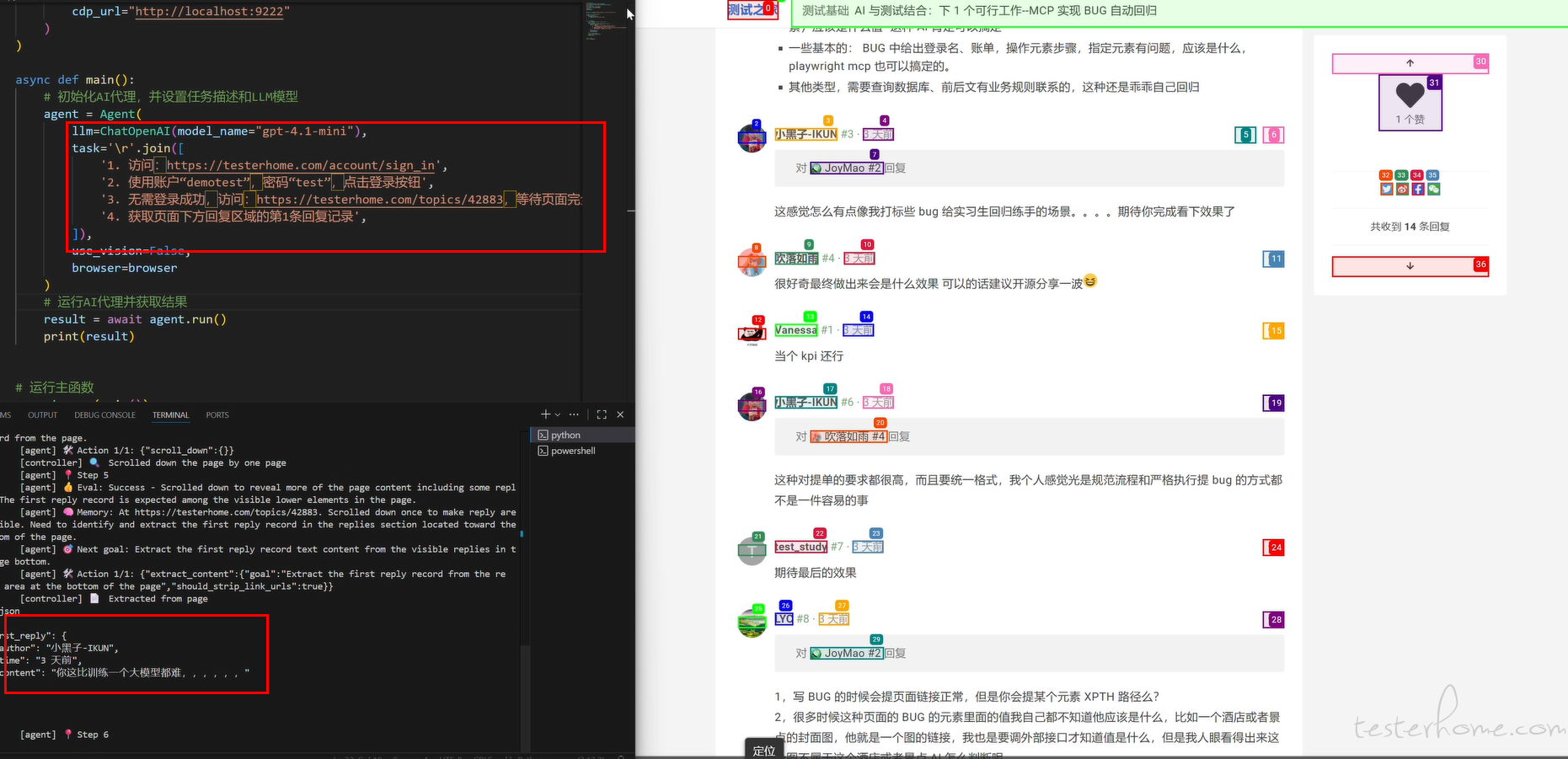
另外,这里只是针对 BUG 回归,回归当前你提出问题本身:期望与实际是否一致,没有要求其发散更多,也没要求去联系业务,这种交给自己去做;
在一个新的、较紧急业务开发中,业务信息不对、不完整类的 BUG 其实占比还是比较多的,这些应该比较合适使用 AI 回归。
回归 bug 占用时间问题,得看 BUG 多不多,什么时候回归。如果任务紧,bug 回归作为最后的系统回归的一部分时,面对堆积的 BUG,可以省去一些时间。
当然,这个也是我使用 CC+Playwright MCP+BrowserUse 应用于 AI 验证搜索结果项目中,产生的可以认为是 KPI 想法;也简单验证了一个 “某某页面,用户审核状态有误,应该是 xx,实际是 yy” 的 BUG demo。
提出来,也是希望抛砖引玉、集思广益。
感谢所有回复的同学
- 做这个的目的是什么,是提效还是降本(裁一些人)
- 使用者的门槛如何,你这个感觉是提高了使用者的门槛
- 投入产出比如何,维护成本如何计算,ROI 如何?
- 想法是不错,就看落地效果了
支持下楼主,在技术领域,先不要看效果,看成本,先探索。最早 appium 刚刚出来的时候也是各种被挑战,现在俨然已经是移动端的测试框架排列前茅的了。
👍,期待博主的持续更新
我觉得通过 AI 来完成一些事情后,怎么判断它做的对不对比较关键,比如你这个落地之后,我怎么保证这个被回归的 bug 是真的修复了?
支持一下。只要做的东西,能确实解决楼主工作部分问题,且有精力做,那就可以先去做,任何东西没有一做就是完美的,碰到问题后面慢慢优化,由点及面,说不定也是一大测试利器 。
。
不方便给完整的,思路是使用 MCP Client 传递 BUG 步骤及问题定位的元素,去调用 Browser User 的包装的 MCP Server,然后将获取的对应 BUG 中元素的当前的值,再交给到模型比对是否和预期一致。
目前只是提出了一些思路和不完善的设计。做出一些小的 demo 也仅限于那种步骤简单明确,问题元素也很容易定位那种,而且大模型的 token 数消耗蛮大的。
验证了一些可行性,至少是这些挑选过的 BUG
这个本地部署吧 不然接口安全好像没办法保证
我想问一下,谁对 AI 回归的 bug 进行负责,也就是回归结果谬误,导致 BUG 遗漏到线上后,谁负责。
AI 这东西,我就怕不够 token 来跑。
简单场景的回归感觉不如 midscene,复杂场景还是得靠人