说明
翻看自己以前的性能测试报告,有一篇比较特别,是关于测试正则表达式的(2018 年),觉得比较特别,在这里分享一下。
(特别说明,我的正则水平不高,“指数型正则”、“嵌套型正则 “是根据现象给的叫法,勿较真)
邮箱格式校验
需求里有个要求:“@ 前后内容不能以点 (.) 开头,但可以数字、字母、下划线连接线 (_-) 开头”
而前端开发写的匹配 email 格式的正则及对应分析图:
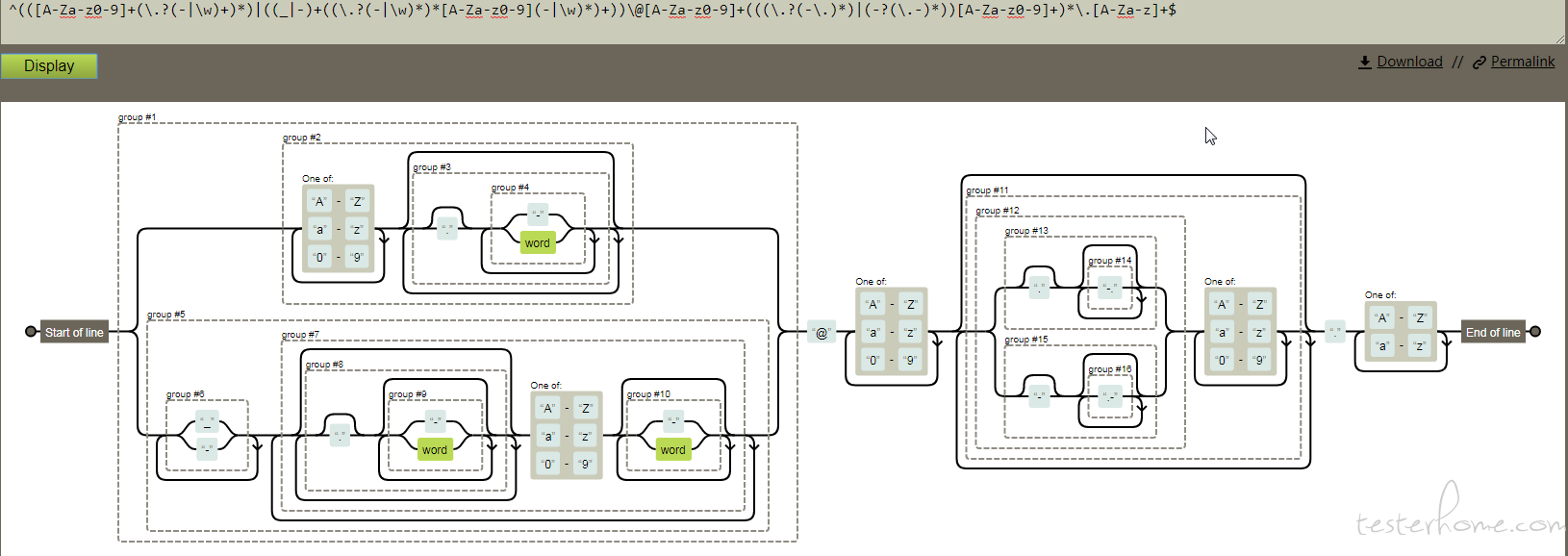
分析:
(\.?(-|\w)+)*)[A-Za-z0-9]这个是明显的指数型正则特征
因为"\w+"是包含"[A-Za-z0-9]"的,如果其后跟的内容不匹配正则,将会不断的进行回溯。
用 a.aaaaaaaaaaaaaaa@a.x-x 测试一下就知道这个错误正则的可怕了 -- 已经溢出测试工具的上限了
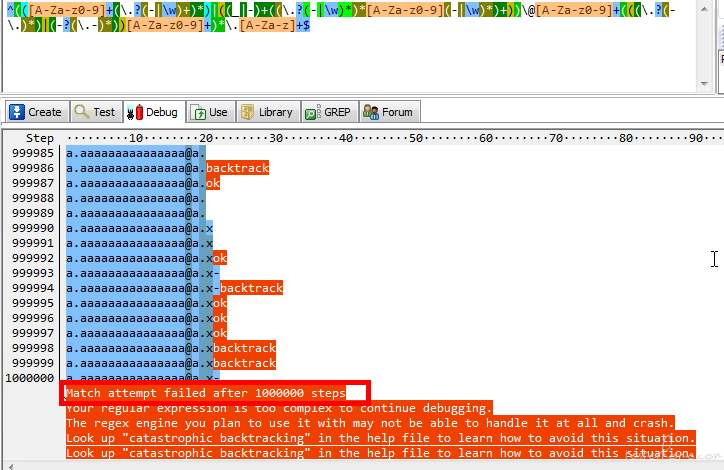
浏览器页面上都不敢尝试,肯定卡死。
这里的测试语句虽然很短,但因为 x-x 无法匹配,前的匹配项过多,造成大量的回溯
补充:
有些看似指数,却不一定是:
比如(\w+=)+$ 、 (\w+=+)+$就可能不是(暂时码不准,没找到合适的测试语句),因为\w不包含=,且=前面\w必须大于1个
但(\w+a)+$是指数型,因为\w包含a,使用aaaaaaaaaaaaaaaaaaaaaaaaa=去测试就溢出了
sql 注入检查正则
没看错,当时为了防止 sql 注入,开发手写正则来拦截可能有 sql 语句的输入,而不是借助其他成熟的工具,但测还得测试。
开发的正则如下:
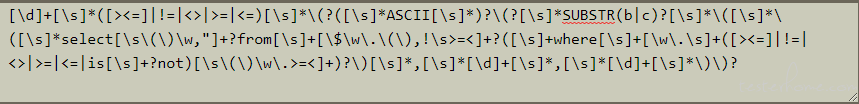
对应超长的正则分析图

分析:
from后面涵盖匹配项包含了where及其后续的内容,即where处即可认为是“数据库表名”又可匹配后面的where处内容。
那么使用如下的输入
1>((substr((select from A where 1= where 1= where 1= where 1= where 1= where 1= where 1= where 1= where 1= where 1= where 1= where 1= where 1= where 1= where 1= where 1= where 1= where 1= where 1= where 1=/),1,1))
当提供如上测试语句时,因为匹配内容不符合时,会不断回溯。嵌套的内容越多,回溯的步骤越多(这里到了 6255 步,当然没有指数型那么夸张)
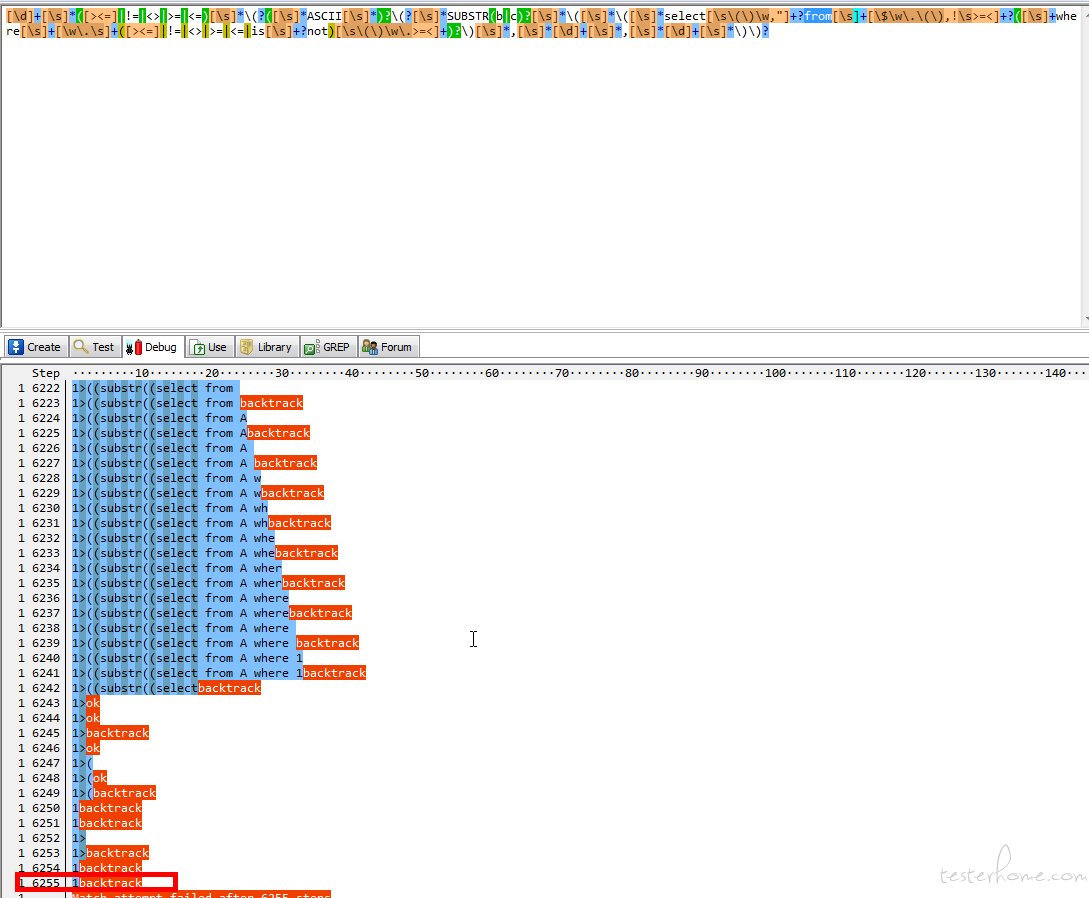
这个语句虽然不能注入,但会极大的影响服务器的性能,造成 其他安全问题
tips: 正则可视化网站:https://regexper.com/
「原创声明:保留所有权利,禁止转载」