-
大家能帮忙看下我这种情况要如何发展吗?(有附上简历) at May 26, 2023
同意
不是人人都有大厂中各种先进技术栈锻炼的机会的,就算自学也只是了解而无真正实践经验的。
他能一个人完成各项目的测试工作,如果能完成的好且有系统化总结的话,肯定也不是 1-3 年的能比的。虽然经历看着平平,倒也反应了真实的日常工作。
测试生涯不是什么都追求技术,往测开方向的——测试的本职还是测试,成为测试专家、测试管理也是路
-
【2022 年度】最佳活跃用户、精华贴用户、年终总结征文获奖名单,小伙伴们请扫码进群领取~~~ at April 03, 2023
过期了
-
想了解下安全测试,有大佬指导指导吗? at January 30, 2023
工具扫描不能代表安全的全部:
1-工具的指纹库是否持续更新:比如缺少新的漏洞信息,或者无法识别使用的中间件或工具
2-工具扫描的路径是否全面:有些 url 路径需要通过一定操作才能访问到
3-一些漏洞可能需要通过多次转换才能判断,这个一般工具不具备(自动化的内容一般都是简单遍历 payload),尤其 sql 注入
4-功能权限校验类需要人去做,工具可不知道业务上那些功能有权限区分
5-需要多步校验中逻辑漏洞、敏感信息、短信类滥用则需要人工和工具结合...
...tips:安全测试水很深
-
UI 自动化测试模块与环境管理全面打通,MeterSphere 开源持续测试平台 v2.6.0 发布 at January 17, 2023
啥时候增加 http 代理服务功能
-
能否说说你作为测试的原则和底线 at December 02, 2022
底线就是:是 BUG 就提了!
该处理就回归,不处理写好谁同意不处理的。 -
报错,找不到 conftest 里面的 fixture 'db_alias' not found at November 16, 2022
@pytest.fixture(scope="session",autouse=False)
def connect_sql(db_alias):你这里 connect_sql 是个 fixture,它调用的 db_alias 也应该是 fixture
所以你得
@pytest.fixture(scope="session",autouse=True)
def db_alias:
return ... -
急,我们的系统的日期控件,在做 webUI 自动化时,输入日期,但是日期弹框一直显示,遮挡其他元素,导致其他元素无法定位 at October 20, 2022
这种是使用某类前端框架的表单和字段组件,校验可能不使用原生的 value,而是组件本身存储机制。
所以除了改 input 的 value,可能还要改对应框架存储的值比如这种 vue-element 的框架,日期组件的值和是否显示在这个组件字段的vue._data 中。
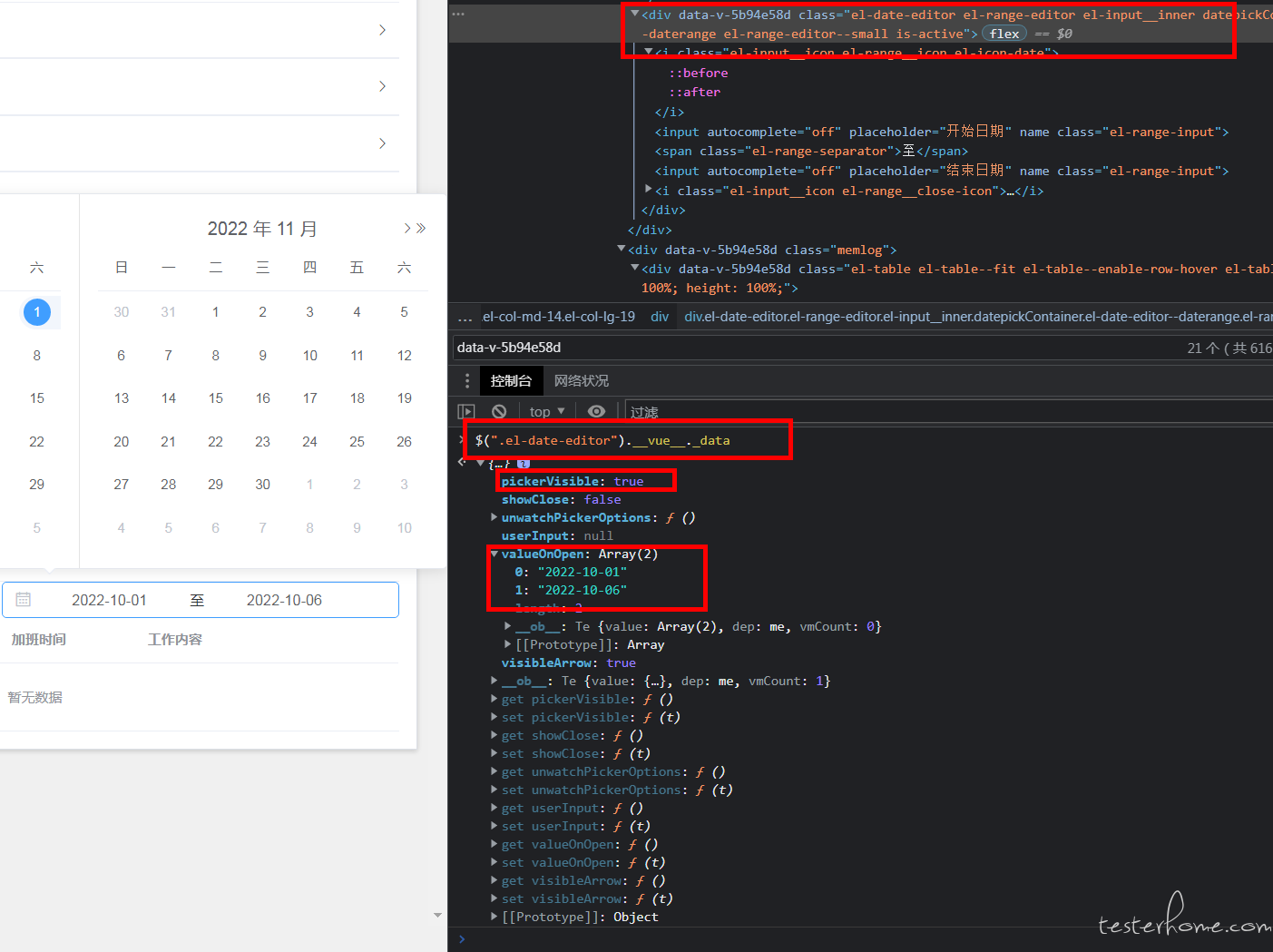
比如关闭日期选择器:$(".el-date-editor").__vue__._data.pickerVisible=false -
关于自动化测试中,hook 掉 web 类项目的前端 js 文件中某个函数的疑问 at October 10, 2022
有个未尝试的想法,可以替换 selenium-wire 试试:
用 interceptor 来替换对应 js 的内容:
api 的文档中有个例子,这里是 html 文件,可以尝试改成 js 文件试试:def interceptor(request): if request.url == 'https://server.com/some/path': request.create_response( status_code=200, headers={'Content-Type': 'text/html'}, # Optional headers dictionary body='<html>Hello World!</html>' # Optional body ) driver.request_interceptor = interceptor -
FunLine 数据工厂开源 at October 09, 2022
一开始看下来,也是这么认为的。
-
简单的反向代理来解决动态修改转发地址和请求头 at October 05, 2022
不沿用的原因是 nginx 的那个动态插件是不支持通过 http 接口动态设置请求头的,所以有临时方案在每套环境之前放 1 个 nginx 来设置对应环境的特殊请求头。
确实找过一些 “Gateway” 类的工具,但大都比较 “大而全”,放在这里有些小题大做。而且不少工具不支持通过 api 动态修改配置,需要改造,就放弃了。
这里只是一个小工具,功能精简且好移植(go 语言)
-
你们公司 bug 的衡量标准是什么 at September 15, 2022
我们不做定期报告,直接将 jira 上 bug 和线上 bug 按级别、bug 产生类型及线上 bug 遗漏类型数据同步到 seatable。
seatable 上做统计图表及明细,领导想看自己去看。 -
前沿大会给我带来了什么 at September 08, 2022
去过 qcon、qecon 一类的,看到各类大厂说自己的 devops、全链路、智能自动化等等高大上的分享,一开始会很羡慕,但细细一想,这些东西都是有局限性的:业务运营的支撑、技术水平、人力物力...都限制了在其他公司的落地,盲目尝试最后落了个鸡飞蛋打的下场。
但我们能做的是从大会的分享中汲取各类创新的思维和技巧,结合自身部门的问题或瓶颈来寻找方法来解决。
从个人来讲,在我们这种不大不小的公司中,尤其是业务线的测试,对大平台的建设没有兴趣。而比较推崇楼主所言的 “小而美的工具或小平台”,准确的说是 “实用工具链”,各种工具能灵活运用各种类型的测试,这并不会比大平台效率降低。
反而把一些列工具强行整合的大平台,前期开发量大(整合时考虑的情况会很多,规则会很复杂),后续如果研发模式改变,子工具、中间件、插件的升级带来的整个平台的维护量也很大,对以发展业务为主的公司来说,这些都是极大的成本。
-
大家学习 go,都用来做什么测试呢? at August 30, 2022
go 写 http/http2 相关的服务比较方便
-
pytest 中如果解决数据依赖问题? at August 19, 2022
pytest 执行依赖及 test 之间传值一种处理方式:
-
pytest 框架的 test 之间的传值:利用 fixture 即可
conftest.py 中定义全局参数:@pytest.fixture(scope='session') # session是大家全局共享变量,其他仅限于各自范围内有影响 def xGlobalArgs(): return {} -
pytest 的 test 依赖及传值,这里 testCASE2 会等待 testCASE1 测试通过再执行
@pytest.mark.dependency(name="test1") def testCASE1(xGlobalArgs): xGlobalArgs["token"]="123123123123123" pass @pytest.mark.dependency(depends=["test1"]) def testCASE2(xGlobalArgs): print(xGlobalArgs.get("token")) pass
-
-
聊聊团队对用例的想法 at August 19, 2022
同意@Ouroboros
用例要看覆盖的是否全面,至于深度?????当然如果能覆盖全面的基础上,让用例的可阅读理解及执行效率上做点文章,才是更优的用例。
至于为了敏捷选择脑图作为用例方式,那更考验设计者是否写的清晰了,
业务后续维护转移其他人测试时,好不好其他人理解呢? -
代码覆盖率这个东西我一直很好奇它的真实的作用是很什么? at August 17, 2022
感谢大佬的补充。
但目前的现实是:道理都懂,但实践上无所适从。
所以想先听听大家的想法和经验,先从一些好实践的地方入手来看看。 -
代码覆盖率这个东西我一直很好奇它的真实的作用是很什么? at August 16, 2022
谢谢大家的分享:
我看下,代码覆盖率使用的可操作确实不是很强,但以下部分可以尝试:1-各个版本增(变)量的的代码可以尝试代码覆盖率,测试可以进行用例的对应逻辑的查漏
2-染色代码和对应接口进行关联(需要找到可用工具或方案),可以进行后续代码变动自动关联测试接口脚本测试 -
代码覆盖率这个东西我一直很好奇它的真实的作用是很什么? at August 16, 2022
“变更部分”:这个有什么工具可以自动获知吗,还是可以有配套的 diff 工具来做
-
代码覆盖率这个东西我一直很好奇它的真实的作用是很什么? at August 16, 2022
对 “每个自动化所覆盖的代码片段进行了关联” 这个比较感兴趣,关联是怎样具体实现的呢?
-
web 端 ui 自动化的疑问 at August 12, 2022
既然要从界面上操作,那还是不要用无头模式。
至于 jenkin 去运行不能打开浏览器页面,可能的原因是 jenkin 以后台服务的方式去启动的
我都是用命令去启动 jenkins 的
但是可以试试 google 到的一个回答(我没试过)
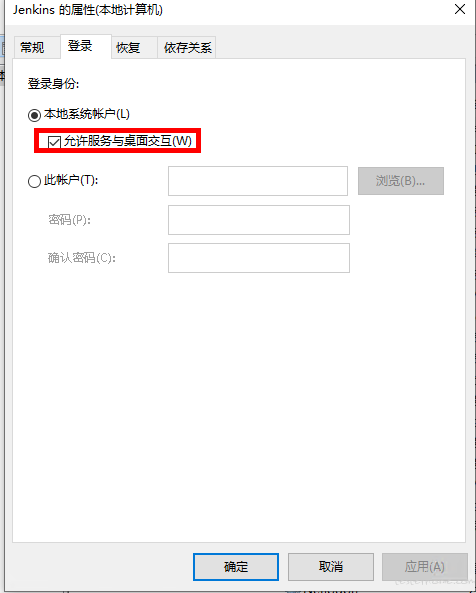
-
无意中发现的一个线上 BUG 说起 at August 12, 2022
我写本文的初衷是讨论怎样避免一些测试遗漏,比如这里:
- 是不是用例设计的时候可以就避免了
- 或者能不能先去了解开发写的代码设计、sql 一类 等等
歪楼了...
-
无意中发现的一个线上 BUG 说起 at August 12, 2022
这个是本职工作呀
-
无意中发现的一个线上 BUG 说起 at August 12, 2022
我在原文加上了补充说明,这样就能明白了。
另外,价格是从第 3 方获取的,但有二次校验(UPC、产品名...校验),校验不通过会被删除。
为啥要保留历史数据?这个是为了 BI 分析用的,看价格的历史变动用的。至于增加一个生效标志,这个设计完全看开发的个人设计喜好了:
- 加这个标志需要在插入时多做一些步骤
- 不加的话则需要查询的时候麻烦些
对于测试来说,符合需求就 OK 了,只不过这里开发耍了一个 “技巧” 耍撇了...
至于责任,那是因为我也是测试,遗漏 bug 时首先会考虑自己的问题,而把责任推给测试那就言重了,毕竟 BUG 是开发写的。
-
web 端 ui 自动化的疑问 at August 12, 2022
如果是想绕过这些步骤,倒是有个建议:
1、上传:可以通过 js 操作元素/利用 requests+ 当前 driver 的 cookie 发送上传请求
2、拖拽:这个通过 js 实现元素的 dom 操作 -
无意中发现的一个线上 BUG 说起 at August 11, 2022
可能我没说明白或你没细看:
那个开发给我的参考 sql 就是他开发的列表用的,那个 sql 会造成上文举例的那个 SKU 无法显示,这样不是 BUG?