-
请教大佬们一个 xpath 的问题 at January 26, 2022
(//td)[1] 表示全部 td 中的第 1 个
-
碰到个很恶心的问题,使用 selenium 打开的 chrome 不能登录 12306 at January 12, 2022
得看你的需求了,
1-如果你想定时自动化登录去做一些事,那就得想法子绕开校验( ,如上楼所说,请慎重)
,如上楼所说,请慎重)
还有如果是通过 webdriver 自带 click 无法点击,那就试着 webdriver 打开页面后手动点击试试,如果可以,那就尝试用 webdriver 执行 js 代码 ($("input[xx]").click())
2-如果只是一次性的,那你就手动登录后,将 cookie 拷贝出来,在 webdriver 中设置好 cookie 绕开登录 -
关于功能测试人的价值 at December 10, 2021
过不了 “造火箭” 的面试(很强能力),是去不了字节点点点的
-
关于功能测试人的价值 at December 09, 2021
无意中,看到了这个帖子:https://testerhome.com/topics/30396
贴子内容很极端,口气像是一个测开对测试推广自己的平台无效后的泄愤,也充斥着对测试的片面的理解。不知道原贴人看到这个帖子后,回答能不能想上面的 15 楼和 21 楼一样好,还是单纯的认为点点就好。嗯...自己有些想法不吐不快,也算总结吧。
测试除了业务,也要懂技术,除了测试技术、自动化技术,开发技术也要会点:
代码不一定写,但至少要会数据库、了解架构及中间件的作用,各个应用服务的作用以及被测功能实现逻辑及处理流程。对于开发平台,我也反对重复再重复造轮子做同样的自动化类的平台,因为实在已经太多了,实在是卷的不行。
但不是说测试不要去学技术,学技术写小工具、写自动化可以让测试便捷、测试的边界更大,更能与开发做沟通。
另外测试平台也是需要的,但得结合部门实际的测试工作规范、工作习惯来设计,而不是对测试片面了解的测开自认为 “高屋建瓴” 的搞个出来。大家不用就是说 “我这个很好用,你们不要浪费时间学技术了,你们学不好的,乖乖的用我这个”。
这边也在维护部门的日常测试工具以及一个测试用例平台(2 个功能测试开发的),但我们都是兼顾着在做功能测试的。我们了解功能测试、部门的测试规范及流程,而且需求方就是我们的其他测试人员。这样这个平台我们部门自己用的很舒畅,以致其他部门也一起用了,甚至产品部都想拿来做需求归档了测试,不是看到需求明面上东西点点就好。这个帖子以微信支付为例,那是微信大家都用,但设想的测试场景就层次不一样,可以预见之和的用例设计、上下游的沟通协作、执行效率也不一样。另外学技术也是必要的,可以提高工作效率,可以测试更内层的内容。
这一行入行简单,但不代表这行的上限低,积累、学习,共勉。
-
关于功能测试人的价值 at December 07, 2021
厉害

-
关于功能测试人的价值 at December 07, 2021
因为是面试题,不会给你长篇的规则限制的,所以可以说没有真正的答案的。看的就是你能发散考虑的范围,考虑问题的能力。
所以你的补充也是 OK 的。
其实你的问题再仔细思考需求时,能推测可能的答案:余额为啥要给折扣?
是不是想鼓励人去把钱放到余额吧?
是不是余额是平台自己的,不像信用卡一样需要额外的手续费,或者风控上的风险(信用、拒付等等呢)?
这些受益人是平台,所以折扣由平台出(而不是商户)是不是更合理?那应不应该有上限? -
关于功能测试人的价值 at December 07, 2021
其实真正的目的就是 15 楼所说的。
功能测试可不是点点点,不是要求别人尽善尽美,不是学个测试基础理论就能干好,不是预设自己处于理想化的工作环境中。
这个需求看上去很简单,但不同层次的测试人员看到的东西就是不一样:有的只是流于表面的字里行间,有的已经将整个资金体系都纳入考虑范围:这个就是功能测试人的价值——有的已经超越了产品经理的业务广度。现在很多刚入行的面试时一来就各种技术说的贼溜,但问及点功能测试的内容就支支吾吾,解释说自己是不做功能测试的只做自动化......说的好像功能测试是很受鄙视的(还是太年轻......)
-
关于功能测试人的价值 at December 06, 2021
傲气
-
关于功能测试人的价值 at December 06, 2021
这个要是测试能直接打回就好了。。。。。。人家产品才是说了算的人。
这个其实是 1 个现实场景中的缩影,就算那个产品经理已经考虑了这种那种场景,但还是有各种场景坑在里面。
需求如果完善的整理好,就该 1 篇 10 页以上的需求文档了,但目前现实是需求工程师这个岗位已经没有了,只有产品岗:只有我要什么就得做什么,负责的还会给你考虑各种情况,不负责的真得测试或者开发深入后,反向推动产品去完善各种场景。好了,牢骚发完了,说下正题,这个是个面试题(所以需求比较短,而且背景就是针对就微信扫码支付场景)
一是看看测试人员考虑问题的全面性,是发散式的。这里面涉及等价类、边界值,也涉及页面与后端二次校验、幂等校验等等:直接反映出测试基本能力:你能保证自己的测试足够充分吗(这个可是支付,容错性要求可是极低的)
二是看看测试人员做事方式,是找到一个问题直接撂挑子,还是罗列尽可能多的方式找产品沟通并一一确认。 -
关于功能测试人的价值 at December 06, 2021
可以质疑啊
但看这个主题的标题啊。 -
关于功能测试人的价值 at December 06, 2021
上面是产品的定义。
至于你的考虑,只是一种测试需要考虑的场景。 -
flask 中的静态文件到底应该怎么使用 at November 22, 2021
appt= Flask(__name__, template_folder='templates', static_folder='static', static_url_path='/static' )检查下 static 的路径及 url 配置,其他的不知道了
-
关于 locust 并发数量的疑问(Number of Users 设置成 20 竟然和 1 时的 RPS 相同?) at November 16, 2021
locust 本地也可以多起 1 个或多个实例来提高负载利用
-
关于 locust 并发数量的疑问(Number of Users 设置成 20 竟然和 1 时的 RPS 相同?) at November 15, 2021
如果以下问题需要先排除:
【1】环境特殊的配置
【2】locust 的 bug
【3】压测机资源负载情况
【4】脚本中做了延长事务时间的处理(比如构造协议、复杂的断言、解析)另外 locust 本身的压测能力是有一些不足的,这点 locust 和 jmeter 做比较的文章网上已经很多了:
因为 python 的语言特性还有默认的 requests 包都是影响 locust 压测能力的,官方也推荐大家使用 FastHttpLocust(据说提高 5-6 倍)。
但你说你的非 http 的,那你还想使用 locust 的话,建议换其他语言的 locust 的压测端,比如 boomer。 -
基于 locust/boomer 为核心的简单 http 接口分布式性能测试工具 at November 12, 2021
-
测试转研发的一年总结 at November 09, 2021
佩服啊,年纪差不多,看看我自己只能一声叹。
工作已经变成了大杂烩:除功能测试、工具、自动化;还兼数据爬取、帆软、安全测试...
感觉自己啥都做,但都不透,迷茫.... -
Locust1.x 的监控平台——boomer at November 09, 2021
我手头没有导入 csv 的例子,但应该很简单的,使用 golang 的 csv 包读取 csv 然后进行自己规则化的脚本编写。
boomer 我只有改版的例子:https://testerhome.com/topics/31192 -
Locust1.x 的监控平台——boomer at November 08, 2021
不知道是是否我理解偏差,文章作者的标题的 boomer 是这个平台的名字吗,还是在 locust 的开源的 go 实现的压测端。
如果是 go 实现的压测端那个 boomer,本身不带导入 csv 功能,需要你在编写的 boomer 脚本中编写 csv 导入的处理 -
大家有没有使用 mitmproxy 的,我想做个拦截下业务流程过程中的接口,然后对接口参数做一下校验 at November 05, 2021
可以采用配置文件的方式,将一条条 path 规则写入规则文件。
这里代码写遍历规则即可 -
Locust1.x 的监控平台——boomer at October 25, 2021
boomer 是个 go 写的 locust 的压测端,本身是编译后命令执行的。
不知道你的 csv 为什么要导入 boomer?
你的意思是不是指标 csv 导入普罗米修斯吧? -
pytesseract 的辨识度极低怎么办? at October 18, 2021
可以试试 muggle-ocr
-
统一测试用例的写法,公司目前有两种意见,投票结果差不多,大家能补充下这两种的优缺点吗 at September 15, 2021
内部的,不过市面上的用例平台包括开源也不少了,还是要匹配自己公司及部门的规范习惯才是合适的。
我们这个不复杂,主要是 antd pro+flask,那个思维导图及流程图组件则是 gg-editor 改造的
-
测试架构师如何解读测试平台的各种争议 at September 14, 2021
目前 github 上各种接口自动化测试平台层出不穷,各说各的好,实在无从下手。
随着项目开发模式、架构的不断演变,测试平台也会更新换代,谁又能保证这个平台的生命力有多久呢 -
统一测试用例的写法,公司目前有两种意见,投票结果差不多,大家能补充下这两种的优缺点吗 at September 14, 2021
主要看新的需求是否以后是否需要维护及当前的 xmind 用例是否有保留价值呢?
如果有的话,xmind 的数据可以像其他楼层提议转化 excel 保存下来,或者就使用适合的测试用例平台是比较合适的。对于一个持续进行的业务,除了考虑当前是否方便,也得考虑后续的维护、参考及协做了。
-
统一测试用例的写法,公司目前有两种意见,投票结果差不多,大家能补充下这两种的优缺点吗 at September 14, 2021
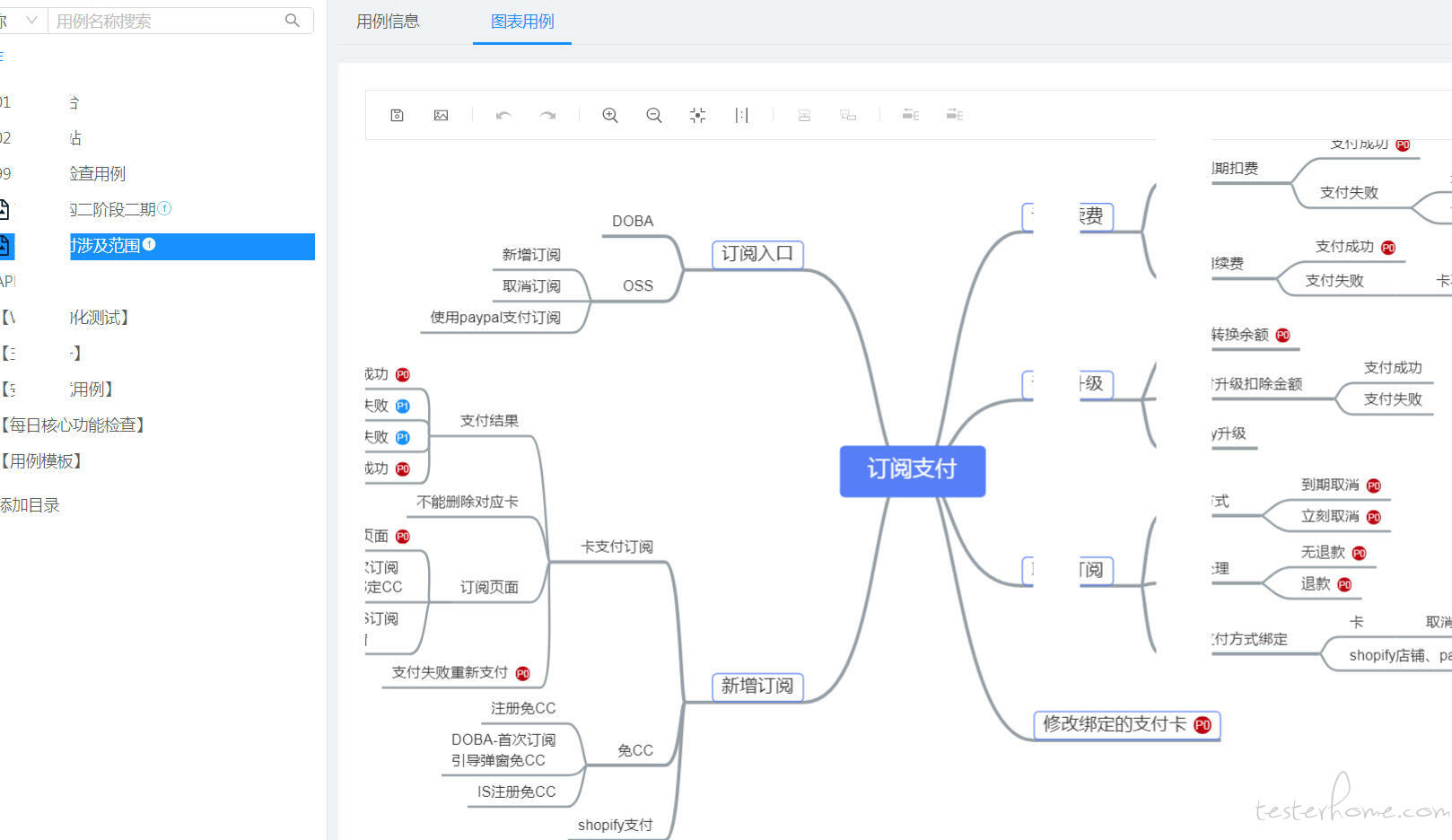
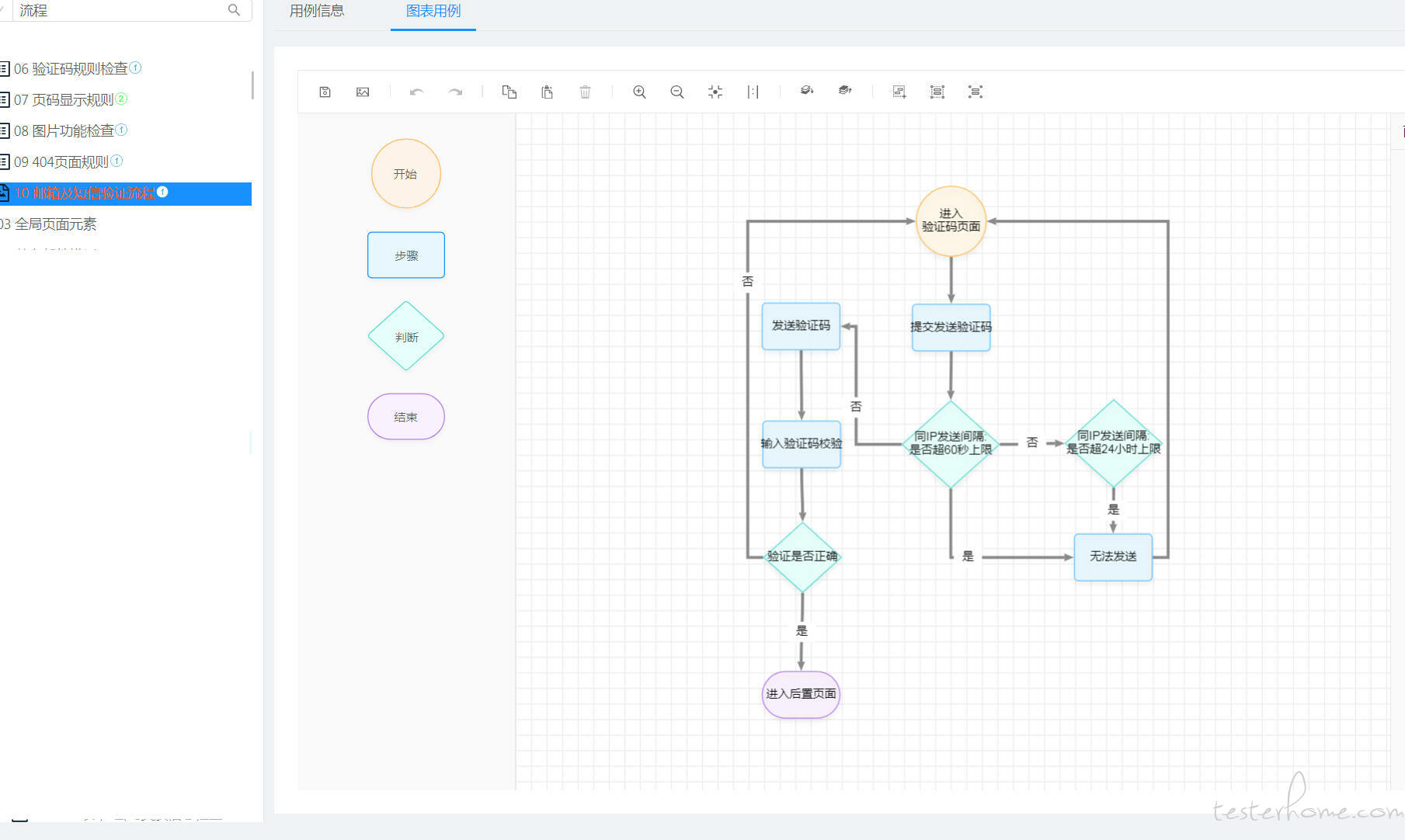
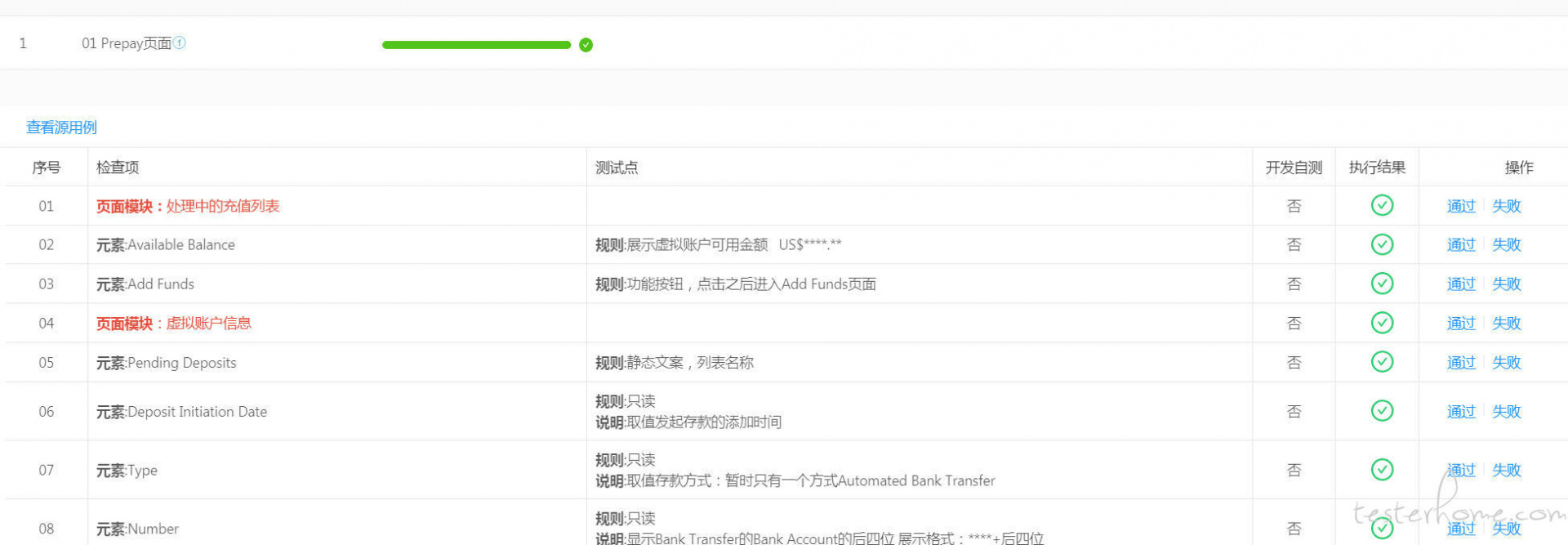
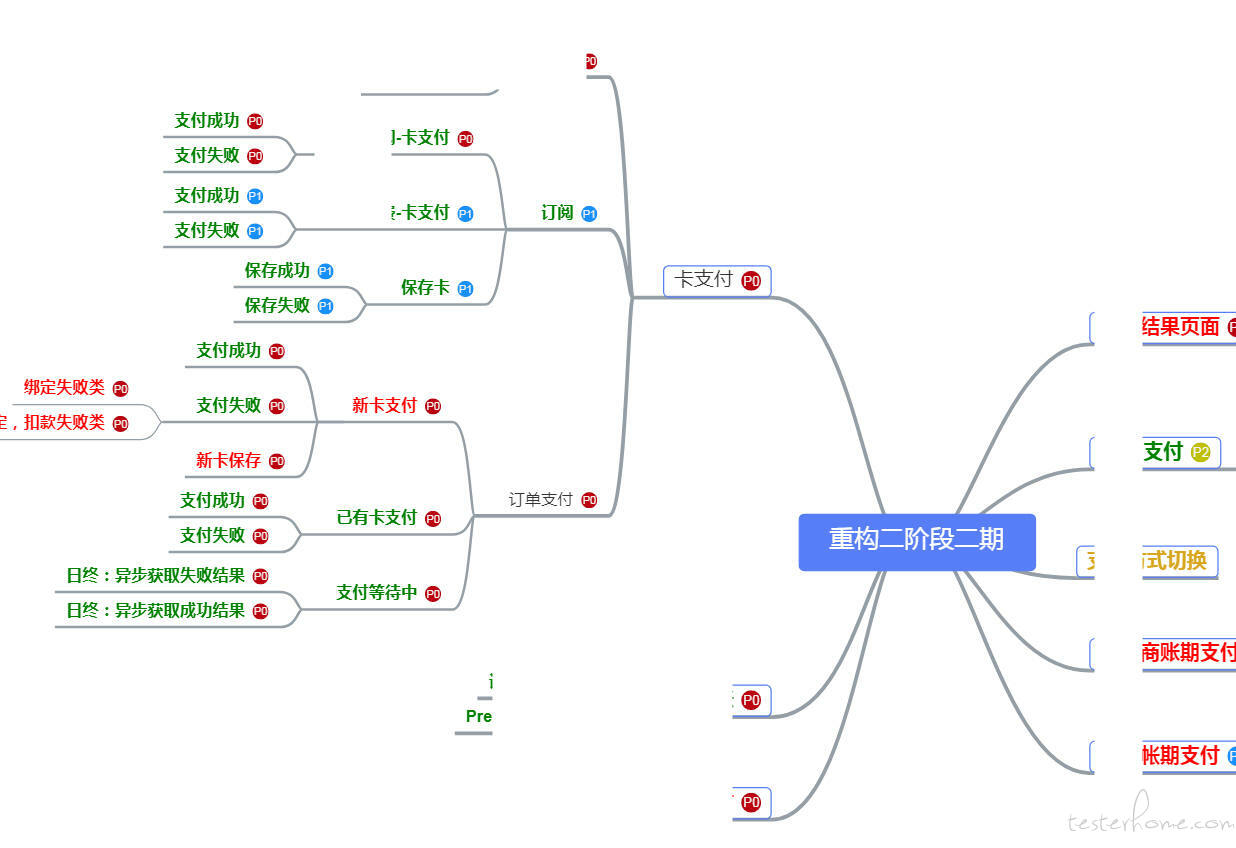
就我来说,类似 excel 表格方式及思维导图的方式、甚至流程图方式的用例都存在,毕竟各有各的场景及方便之处。
表格类型适合执行时一条条过,思维导图适合设计时发散思考,流程图更是适合便于理解业务及执行时清晰了解执行的分支覆盖情况。
不必纠正统一那种格式。
如果是要有 1 个平台或者工具统一管理及方便执行,那肯定是比较好的