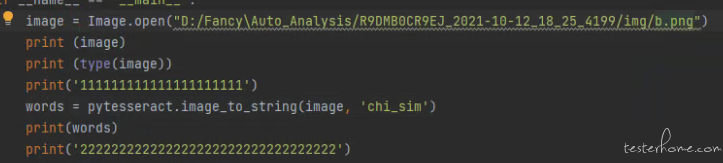
百度一下四个字都识别不出来,识别成 [三] 三
「原创声明:保留所有权利,禁止转载」
能贴一下识别的图么,一般正常字是没什么问题的,识别不了的话可以调调 pytesseract 的配置参数或者对图片做预处理 (二值化、降噪等等)
另外要看具体使用场景,看是否需要使用 OCR,有可能其他的方式也能做
另外还有其他 AI 开放平台的 api 可以用,识别中文应该比 pytesseract 更好一些

对
 Heroman
回复
Heroman
回复
上面的图片简单,识别不了多半是背景太花哨,用二值化就可以搞定。文字是接近纯白,用二值化可以把图片处理成背景纯黑,文字纯白的图片,可以参考下面的文章
https://blog.csdn.net/bosszhao20190517/article/details/105837566开放平台是指百度云、腾讯云等免费的 OCR 识别 api,一样的调接口,传入图片,然后识别结果,因为基于深度学习,数据集比 pytesserct 大,且是国内环境,中文支持更强,效果会更好一点
看你具体是要做什么操作,如果是找控件、点击之类的自动化操作,可以了解下模板匹配、airtest 之类的
我的可以啊
可以试试 muggle-ocr
转用了更好使的百度 OCR