-
测开需要具备良好测试用例设计能力吗 at 2022年03月25日
个人观点:需要,但要求不会很高,能做就行,核心是要满足自己能设计自己开发的功能的测试用例这个场景的需要。
但又不一定每个测开都是从传统业务测试成长上来,不少一开始就直接是做工具的了。
这类测开一般也需要学习测试知识,甚至有需要的话到业务组轮岗做一下测试。只是技能点偏向于做工具开发,并不代表不需要具备测试用例设计能力。不真实了解和做过测试的测开,体会不到测试的痛,很容易跑偏。
-
APP Crash 大家都是怎么在通过测试去发现的? at 2022年03月25日
额,个人觉得,你这个分类层级太高,场景太多,会导致测的成本很高。有好几种其实背后都是一个原因(比如带宽限制、网络变化、用户过多,本质上都是网络库处理相关的逻辑处理不够完善,导致极端情况下会出现未被捕获的异常引起 crash )
一般比较少专门测 crash ,真的测更多是针对第一点,用云真机平台的 monkey 或遍历这方面的能力去跑。其他的更多通过日常功能测试中的异常路径测试 + 部分特定场景专项测试(如弱网)+ 线上崩溃监控预警 来发现。
-
jenkins 如何防止多个 job 同时执行呢? at 2022年03月24日
你这种属于指定 job 之间不允许并行,目前 jenkins 好像没见到有类似这样的功能可供配置。
可以考虑下面几个方向:
1、状态合并。三个 job 合一,用参数区分。这样借助 Job 本身的不允许并行构建可以做到。缺点是相关的定时任务什么的也都被合并了,会增加维护成本。
2、状态共享。建立一个临时文件,用于记录这个手机上是否已经有别的 job 在用(比如 job 开始跑时创建这个文件,跑完后删掉这个文件)。每次 job 运行时先查这个文件内容,如果有,那 job 就直接结束不跑或者轮询等待直到可以跑。基本上云真机平台共享设备资源也是类似这样的做法,只是为了避免意外退出设备持续被占用,一般会额外加个使用时必须保活 + 没有保活则超时自动释放的机制。
3、执行器限制。三个 job 的执行器都分配到一个最多只能同时跑一个任务的执行器上,这样执行器自动会保障 3 个 job 同一时间只有一个在跑,剩余的排队。缺点是为了这个需求额外弄一个执行器,有点不值当。
-
1 at 2022年03月24日
@ 那颗炽热的心啊 @A. @ 枫叶 -
wda 安装完成后,使用 tidevice 打开 wda,会退出 at 2022年03月23日
日志信息不足,无法定位。
你用类似下面的命令来跑,获取更多信息吧。
tidevice -u <替换成你的设备uuid> xctest --bundle_id "*WebDriverAgent*" --debug -
迟来的总结与回顾 at 2022年03月23日
写书不易,飞哥加油!
所以也导致我还是会焦虑,我总是想去挣更多的钱。 老婆大人总会劝我,钱是永远挣不完的,够用就行了,穷也有穷的活法,一家人健健康康的才最重要。所以我也在开始慢慢的调整自己的状态。
我老婆也总是这么说我的。。。
-
测试开发到底应该干点啥 at 2022年03月22日
PS:如果发现找不到团队痛点,问业务、问领导都问不到(很常见,习惯了就会成为盲点),你自己直接跑去业务,和业务一起当一个月业务测试,一起测需求,哪些地方低效且容易提升效率,就立马可以发现了。
-
测试开发到底应该干点啥 at 2022年03月22日
你的关注点有点不对,关注点不是写脚本还是写平台,这个只是实现形式。关注点应该是做什么能帮助团队的质量保障做得更好。包括效率上的提升,以及一些深度上的扩展。
你领导认为不只是做自动化,我个人其实也认同,毕竟自动化用例这个大多是强耦合业务的,测开人力比业务测试少很多,测开干这个,投入产出比不匹配,而且写出来的自动化业务测试同学不一定信任,还是手动再测一遍才心安,那就是白写。
举几个以前带的团队做过提效的例子:
1、测试环境数据库 ddl 的维护提效。为了便于有需要时并行测试需求,一共有维护 4 套测试环境(此处先不追究是否合理,这个是当时现状)。经常遇到由于 DDL 维护不及时导致需求部署上去后,由于 DDL 过时导致部分核心流程不可用。前期是做了一个 Python 脚本能一键应用上线时的 DDL 到 4 个环境的数据库中,保障和线上 DDL 一致。后期是引入了 flyway ,能让服务自维护 DDL 的框架。
2、定时任务触发提效。开发的定时任务用的是 spring boot 自带的 @Schedule ,缺少手动触发机制,每次测都得等到时间才能触发。后续基于做了扩展方法,测试可以通过调用接口传入定时任务相关参数,就立即启动定时任务,不用干等。
这些都不涉及平台开发,也不是写自动化脚本,但都是能有效解决当时团队痛点的手段。视野拓宽点,不要只看到自动化。当然楼主说的开源有好工具直接用这个是认可的,只是开源工具平台很容易在接入业务的最后一公里不方便(最常见的是和公司账号体系的打通,开源工具不大可能适配每个公司自己的账号体系),所以一般还是要做点二次开发才更适合使用。
长期也要考虑后面怎么 show 的问题,从这个角度,搞个前端界面包一下, show 起来容易很多,所以领导一般也喜欢做成平台形式,ppt 展示起来,总归比配一个报告或者代码的图看起来好很多。
-
Selenium 用例如何在报错后可以继续执行? at 2022年03月21日
。。。你这个不叫 10 条用例,只是 10 个函数而已。大家被你的术语误导了,默认你应该用了框架并用上了 @Test 这类注解将函数注明为用例。
后续建议在提问题的同时,把你的代码、日志也贴上来吧,这样更全面,也能尽量避免理解偏差。
-
Selenium 用例如何在报错后可以继续执行? at 2022年03月21日
好奇你用例是怎么写的,可以把具体写法贴一下么?还有具体的报错信息。
用例 fail 后继续执行后续用例,直到全部用例执行完毕,我理解应该是一个测试执行管理框架的标配,unittest 就有这样的设定。
-
想请教一下目前的自己的 App UI 自动化平台比如 monkey 自动化里面都是怎么处理应用安装弹窗和登录问题的,都是通过前置脚本去处理的吗?有没有什么办法是可以直接安装的? at 2022年03月21日
这个是个新思路,可以开个帖子详细说下?
-
如何注册?如何绑定微信?如何激活账号? at 2022年03月21日
发你要解绑那个账号的邮箱地址,没有邮箱地址没法解绑。
-
用例即艺术,那么如何将用例艺术化 at 2022年03月17日
你们的标准化是标准化用例的哪个部分,格式、分类还是啥?
-
求助,启动 lyrebird 时,提示这个报错 at 2022年03月17日
idevice_id error: /bin/sh: idevice_id: command not found这个报错很明显了,找不到 idevice_id 命令。idevice_id 命令所属的 libmobiledevice 这个库装了么?你直接命令行调用,可以成功调起 idevice_id 命令么?
ERROR [device_service] Environment variable ANDROID_HOME not found!这个 ANDROID_HOME 环境变量配了么?
顺道搜了下官网文档,确实没写装 libmobiledevice 这方面的信息,只有插件的 github 主页有写:https://github.com/Meituan-Dianping/lyrebird-ios。可以给官方反馈个 issue ,让他们补全这部分信息到官网上。

-
用例即艺术,那么如何将用例艺术化 at 2022年03月17日
优雅是个很主观的词,我也不知道怎么样的用例算优雅。。。
-
想请教一下目前的自己的 App UI 自动化平台比如 monkey 自动化里面都是怎么处理应用安装弹窗和登录问题的,都是通过前置脚本去处理的吗?有没有什么办法是可以直接安装的? at 2022年03月17日
对于 ov 的安装弹窗,目前貌似除了用自动化脚本针对性去点掉外,没啥特别好的办法,除非能搞到内部版系统之类的。不过这个只是安装时用到,而且相对比较通用,写一个性价比还可以。
至于登录,我们是复用 UI 自动化里的登录用例的,不过在原来登录基础上加上了多账号管理机制,多设备同时跑的时候,会额外传一个机器序号的字段(比如跑 2 台机器,1 台传 1,另一台传 2),避免账号互踢导致实际并没有登录。登录完再开始跑遍历程序(可以理解为是前置脚本)。
而针对内部随时冒出来的权限弹窗,这个应该要在遍历程序内处理的,这个是自动遍历类工具的标配吧。
-
【求助】智能家居测试中,控制设备后,设备状态变化,没办法能获取到状态变化的关联属性值 at 2022年03月16日
如果是自家 app ,可以找开发加 contentDescription 属性以及根据开关状态切换这个 id 值的逻辑。
可以参照:https://developer.android.com/guide/topics/ui/accessibility/apps
-
请教 python 脚本执行会报磁盘空间不足 at 2022年03月15日
客气了。
每个奇葩问题的背后,其实都是一系列运行原理的组合。搞懂这个能让你更清晰真切地了解 python 的外部库加载机制,建议你可以继续追查下,相信会有所收获的。
至于为啥会自动加载,我从你的文件名大概知道原因了,你可以自己试着查下,了解后能有效帮助你避免以后出现同类问题(这个问题其实并不奇葩,属于新手常见问题之一,只是你的脚本刚好输出内容有点特别而你又没提及,所以大家都被你给出的 “磁盘空间不足” 误导了方向)
PS:下次提问建议最好是把你项目有关的全部信息附上,最好是把代码放到 github 仓库方便其他人复现,否则缺少有效线索,大家只能靠你选择性给出的信息去猜,很容易方向错误。
-
数据为什么会走丢了呢? at 2022年03月15日
很不错的文章,先增加一些场景细化复现场景,然后查资料了解黑盒子背后的原理,提出假设 + 验证确认,点赞!
话说,这种为了高性能服务,并且发了后不用管的,用 UDP 应该比 TCP 更合适,当时开发为啥不考虑直接用 UDP ,这个有和开发探讨过么?
-
大家测试环境加日志监控了吗?有哪些弊端,有哪些收益? at 2022年03月15日
这个要看你这报警的阈值是怎么设置的。
如果是抛个异常就预警,估计会很多(很可能出个 bug 就异常了,或者是历史原因系统存在很多其实不用关注的异常)很快就疲了,加了等于没加
如果是能限制为影响环境主流程才预警,那会比较有效,但会比较难,因为从日志其实很难区分,比较有效的是 4 楼所说的,在测试环境里跑已有的自动化用例(特别是流程类的),不通过的时候预警。我们之前是加了主流程自动化的失败监控,30 分钟跑一次并且自带重试机制(有可能刚好某个服务在部署,引起失败),如果重试还是失败就预警。
-
开源了一个基于 K8s 的微服务本地联调测试工具 KubeOrbit at 2022年03月15日
已 star,能把环境里的流量转到本地方便联调,挺不错的。
话说,你是转行做运维开发了?
-
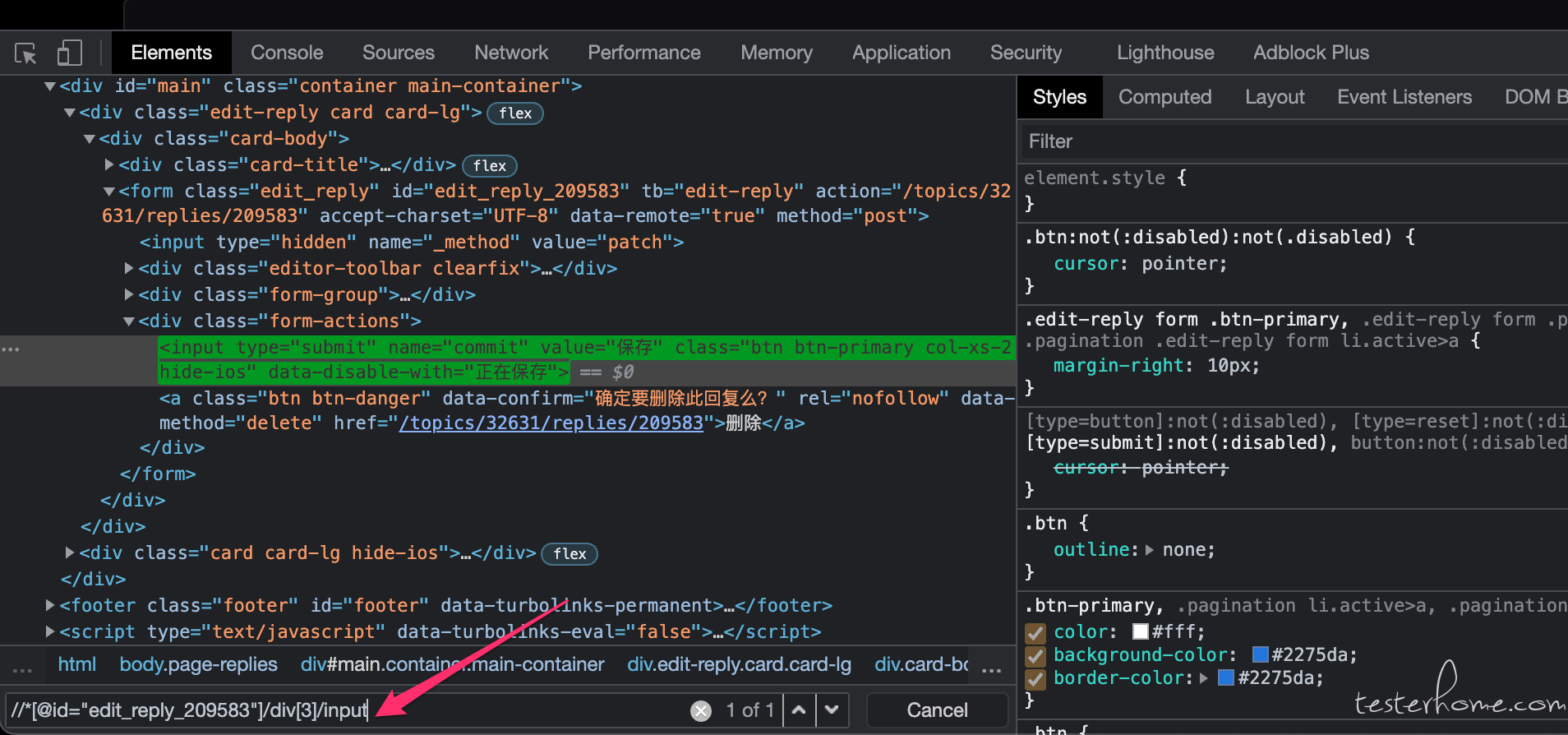
selenium 自动化时,怎么选中动态加载,封装在接口里面的下拉框数据 at 2022年03月15日
你的户籍人口这个控件的 xpath 是怎么来的,有确认过这个 xpath 的正确性吗?这个控件查找的时候加个显式等待试试(因为从你描述看,应该是请求网络成功过后才会出现这个元素,所以点击后立即找有可能网络还没返回,所以找不到)
可以在 chrome 浏览器的 审查元素 - 元素 tab 用 xpath 搜索,看看在你点击了下拉框加载到数据后进行搜索,是否有搜索到结果。
-
请教 python 脚本执行会报磁盘空间不足 at 2022年03月15日
挺好,问题范围缩小了。不过我自己没遇到过这个问题,所以也只能给些建议:
可以试试:
1、确认下是所有 import 都有问题,还是只有 request 库?如果是后者,可以试试重装 requests 库,看是不是装的时候有问题。
2、项目目录不要放 C 盘桌面,改放别的盘或别的位置(因为一般系统也在 C 盘,桌面属于 C 盘用户文件夹下目录,所以 C 盘特别容易遇到有权限限制的文件夹) -
如何注册?如何绑定微信?如何激活账号? at 2022年03月14日
请把你微信误绑定的邮箱地址发出来。管理员可以根据这个地址找到绑定信息,帮你进行解绑。
-
如何注册?如何绑定微信?如何激活账号? at 2022年03月14日
请把你微信误绑定的邮箱地址给出。管理员可以根据这个地址找到绑定信息,帮你进行解绑。