-
docker 搭建 gitlab 环境后打开浏览器进入 http://ip:port 提示 ERR_EMPTY_RESPONSE at February 24, 2022
docker 日志里有一项:Up About a minute (health: starting)
你确认你访问的时候 gitlab 启动完了么?
-
测试左移,该怎么个移法? at February 22, 2022
额,没必要背。我也只是想到哪写到哪。
对这些名词有个大致概念就行,一般是发现提测质量不好或者测试阶段经常返工,才需要开始关注和实施左移的。左移的核心个人理解是尽早发现甚至预防缺陷,避免都积压在测试阶段。
-
关于自己的 2021 总结 at February 22, 2022
你接触的东西好多,好处是你的广度会很不错,缺点是因为没有持续运用,如果没沉淀好估计过个一年半载你就基本都忘掉了。建议可以多写些文章总结下你做的东西,沉淀一下,也欢迎分享到社区一起交流。
前路还很长,继续加油~
-
接口自动化测试发展的几个阶段(个人向) at February 22, 2022
这 5 个阶段感觉有点把平台弄得太末尾了,实际上开始引入时就需要进行弄成平台还是框架形式的选型了。加上现在也有不少开源平台可用,其实平台可以直接作为第一阶段直接用。
另外,你这个只是接口测试工具的发展阶段,接口测试虽然依赖工具但不只是工具吧,还包括测试设计、测试范围等,个人觉得有点不那么严谨?
-
测试左移,该怎么个移法? at February 22, 2022
提测前做的、和质量保障相关的事情,个人理解都是左移。左移是相对于传统的测试主要在测试阶段才开始介入而提的概念。
比如需求评审时能提出更多提高需求质量的意见并推进让产品采纳;技术方案评审时能及时提出一些方案存在的风险缺陷(比如和第三方交互是否有充分可靠的补偿重试机制)并进行修正;代码提交时能通过一些自动检测工具自动发现那些低级的空指针错误;开发提测时可以通过 code review 来了解整体实现细节以及评估是否有风险(比如同时更新两个表有没有用事务避免脏数据等)等等。包括 TDD 、ATDD 这类测试驱动开发的方式个人理解也算是测试左移(比正常测试阶段提前了很多开始进行测试)
每次 build 就触发自动化测试这个是持续集成的概念,目的是及早集成和测试,确认每次提交代码后,软件达到最低限度的质量要求(能编译通过、最基本的测试可以通过)。也算是左移的一部分(正常迭代软件,在建立新分支的时候就开始做持续集成了)
左移其实挺难的,主要相关实践基本都离不开技术实践,对人员要求比较高。团队内有这样能力的人不多的话,安排做测试提效工具可能产出比弄左移要明显不少(而且一般开发水平不是太差的话,前期阶段能发现明显缺陷的概率并不高)。个人建议与其研究这些概念性的东西,还不如去审视下自己现在业务还存在什么问题,有什么合适东西可以去实践解决问题。现在已经是一个精细化的年代,很多实践并不见得都适合自己,按自己需要选择即可。
-
有大佬可以推荐下服务端测试方法的书籍或课程吗 at February 22, 2022
服务端性能的书比较多,讲服务端测试的好像也有一些,但只是顺带讲,比较少专门讲。
至于故障演练、安全问题、回滚机制这些,暂时没见到有讲这类的书,更建议你去找一些公司的实践案例参考,比如各个公司的技术公众号、MTSC 大会的分享材料等。
-
请问一下 selenium 报错:selenium.common.exceptions.InvalidArgumentException: Message: invalid argument: 'value' must be a string 该怎么解决 at February 21, 2022
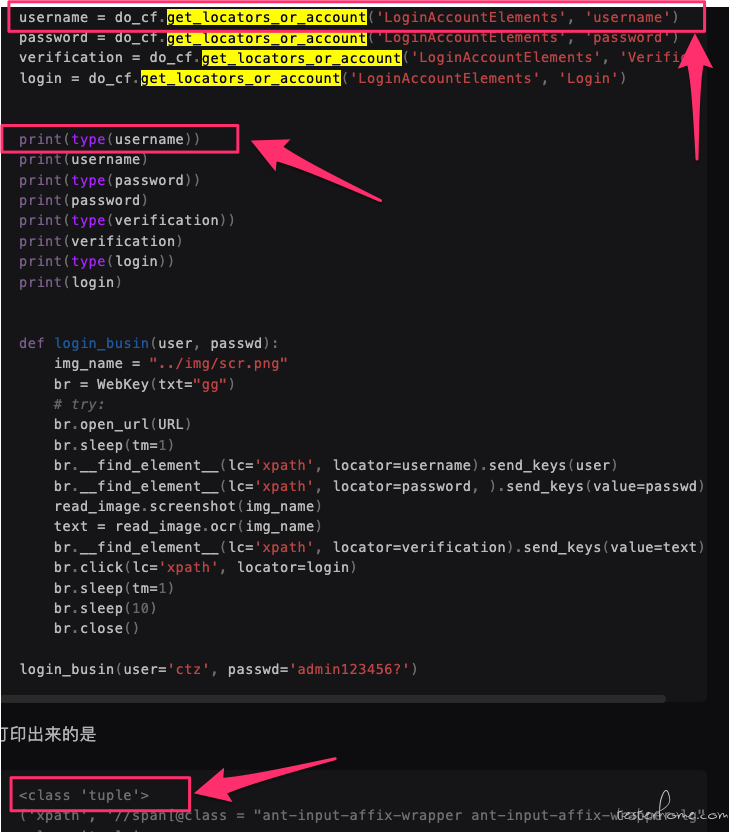
有点奇怪,你上面贴的打印日志里,get_locators_or_account 返回的值类型是 tuple 哦?你看下是不是你那时候的代码有问题导致返回的是 tuple 类型?
-
请问一下 selenium 报错:selenium.common.exceptions.InvalidArgumentException: Message: invalid argument: 'value' must be a string 该怎么解决 at February 21, 2022
1、从两次的堆栈看,都不是执行 sendKeys 报的错(),而是
br.__find_element__。你一直去看 send_keys 方向不对。
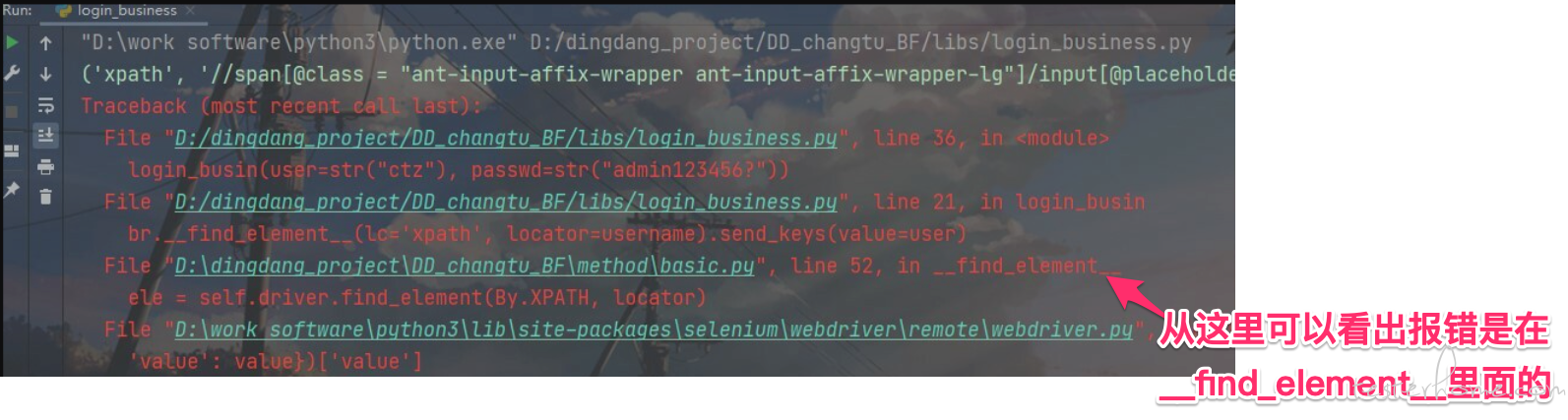
2、你提供的代码里没有
__find_element__的完整实现,无法继续追查定位。如果需要进一步协助,麻烦把这部分源码以及涉及的其他相关函数源码也一并附上来吧。PS:从你贴上来的代码里,username 这个传给
__find_element__的 locator 的值类型是 tuple 而非 string ,而从错误堆栈看这个 locator 是直接传给self.driver.findElement(By.XPATH, locator)的。正常self.driver.findElement(By.XPATH, locator)这里面的 locator 应该是 string 类型的,值内容就是 xpath 的具体定位路径,你也可以从这个角度去排查下。 -
测试朋友们,UDP 接收数据数据包乱序问题有解决方法吗? at February 21, 2022
好吧,我终于大概理解你这里的顺序意思了。你这个 “排序” 有点混淆,实际你需要的是获取到一对基于同一个 pb 协议的请求包和响应包,然后响应包收到后根据里面自带的序号 + 你本地缓存的发送编号,反推出使用的是哪个 pb 协议,再反序列化出对应的 key value 数据,对吧?
有几个新的疑问:
1、这个和 UDP 有什么关系?你们的网络协议是一个请求包或响应包,只需要用一个 UDP 数据包表示?数据量大的情况不会涉及拆分包?
2、是否有看过开发的网络库是怎么做的,是否可以考虑使用开发已经封装好的网络库来做?pb 我理解只是序列化和反序列化,并且由于本身 pb 的序列化方式是去掉 key 只存 value 的,因此反序列化时如果不知道序列化时用的具体协议,是无法保障正确性的(比如两个协议里都是 3 个字段,且都是 int+str+int 类型,那这同一个数据在这两个协议下进行解析都是不会出错的),一般底层网络库实现时会通过一些自定义序号或者数据位来记录这个包对应的是哪个协议,方便做自动解析,不大可能会采用你现在的这种缓存所有请求数据并按序号倒推这种方式。 -
测试朋友们,UDP 接收数据数据包乱序问题有解决方法吗? at February 21, 2022
几个点没看明白:
1、你需要做的是排序还是什么工作?第一段写的是需要排序,第二段变成了执行回调,没明白之间关联是?
2、你排序的目的是做什么,是为了报告展示好看点还是为了正确整合被拆分的 udp 包?从思路上,可以考虑在收到全部返回包后再根据服务端返回内容里发送顺序字段进行排序,这样不会额外增加性能测试中的压测机负荷,也不用担心顺序会有错。但如果是有别的需求所以要实时排序,那就要根据具体情况来设计了。
-
有没有可能在 suite 上进行数据驱动 at February 21, 2022
我确认下我的理解,假设 DataProvider 产生 A、B、C 三个账号数据,你是想把执行顺序从:
用例1:A 用例1:B 用例1:C 用例2:A ...改为
用例1:A 用例2:A 用例3:A ... 用例100: A 用例1:B 用例2:B ...对吗?
如果是,那其实你要做的并不是数据驱动,而是执行顺序编排。这个可以用 testng.xml 来做。建立 10 个 testsuite,每个 suite 里面都是你那 100 条用例,然后每个 testsuite 里面设定不同的 parameter 对应不同用户,testcase 里面通过 @Parameter 来获取当前 suite 对应的用户信息即可。
如果不是,可以类似上面示例这样说清楚你想要达到的效果?
-
基于百度脑图的用例增量保存 + diff 展示整体设计 at February 21, 2022
哈哈,感谢支持!当时还是写了不少单测去测试这个工具类的,因为人工测试太费劲而且也慢。印象中这个类单测的行覆盖率应该有 90% 以上。
-
一些网络协议相关的问题 at February 16, 2022
没深入了解过这块逻辑,结合个人日常刷新 dns 缓存相关理解:
1、服务器无域名信息则向 DNS 请求获取域名对应 IP。 获取到的 IP 和域名是否保存?保存的话是在内存还是落地?内存的话是多久?
——保存是肯定有保存的,否则不会出现各种刷新本地 dns 缓存的操作。至于是内存还是磁盘里面这个真的不大了解。用 “DNS 缓存” 找到了一篇说得很详细的文章,可以参考下:https://bbs.huaweicloud.com/blogs/1093782、服务器与被请求域名服务器建立 TCP 链接后,后 TCP 断开。在什么情况下可以让服务器再次向 DNS 请求后再与被请求域名服务器建立 TCP 链接?;
——感觉你是把域名解析和 tcp 连接混在一起了,实际流程是:找到域名关联的 ip 信息(先本地缓存,后找 dns 服务),然后和这个 ip 及端口(http 默认 80,https 默认 443)建立 tcp 连接。所以你这个问题的答案和第一个其实是一样的,只有 dns 本地缓存失效才会去问 dns 服务器3、问题 2UDP 的情况;
——个人理解和 tcp 也是一样的4、有没有什么方法可以让每次访问都走 DNS 解析后在发送请求;
——每次都强制清除本地 DNS 缓存即可。不过 DNS 除了本地缓存,还有路由中途各个节点的缓存、地区 DNS 缓存的等很多级缓存的,全部缓存刷新一般需要好几个小时。如果你想要快速更改,要不自己在连接的路由器手动加 DNS 映射关系(一般路由器是最近的节点,而 DNS 查询是只要有一个节点返回了映射关系,就不会继续问下一级节点了),要不直接通过本地 host 文件手动配置固定的映射关系(这个连缓存都不用清,立即生效)。 -
兄弟萌,这个名称怎么修改啊? at February 16, 2022
改头像是会需要重新审核的,我查了下后台审核列表,没有你,应该是已经有其他管理员审核通过了。而且我看论坛须知你也发了个 已阅 回复信息。
你现在是还没法发帖么?
-
各位公司的研发任务工作流是咋样的呢 可以分享一下吗 at February 16, 2022
变流程这个,我理解是一个管理问题了,怎么限制大家随意改变系统的流程。自研的话灵活度更高,其实也更容易被提这类需求。不过自研成本也不低,团队没有一定规模,用外部已有的工具可能性价比更高。
-
TestDeploy at February 16, 2022
还是没太看懂,我说下我的疑惑点:
1、github 官网上给的这个演示 demo ,登录后只看到了 hrundemo_nginx、hrundemo_nomal 两个 job ,从控制台输出看起来就是删掉并重启一个 docker container ,然后跑了一下 httprunner 的某个脚本,因为没权限看到配置所以也不知道 shell 脚本咋写的。不过坦白说,这些东西用 docker pipeline 实现也并不复杂,而且还能收获更清晰的 pipeline 视图清晰看出流水线里面包含啥节点,所以没太看出亮点所在。
2、作者既然开源了,我理解应该是考虑过一些通用化的,意味着每个项目应用应该需要自行配置一些个性化配置(比如哪里配置 httprunner 用例的仓库等)吧?这篇文章和 github 的 readme 都没看出来这些怎么配置,并且配置项里有些不知道应该配啥值的内容(比如
${ShellDir},没见到任何说明这个是啥变量,据我了解应该不是类似 ${PATH} 这类有预配置的变量吧?),所以也没法从部署环节上感受到文章里提到的 “只需简单配置就可以 xxx ” 。目前开源领域确实缺少一个融合了 编译打包、部署、执行自动化测试 的开箱即用的平台(jenkins 很接近,但初始配置比较繁琐,离开箱即用还有段距离),这类平台其实很多公司内部都有自研,只是由于融合了非常多内部别的平台工具提供能力(比如最常见的通过 k8s 提供容器部署能力,通过接口测试平台提供接口测试能力)导致很难独立开源。
建议楼主可以把文档完善一下,明确说明一台机器从零开始部署到底需要哪些步骤并尽可能简化为少量命令,并补充说明一下怎么在里面建立一个新项目(比如典型的 java spring 项目)的构建部署测试流程,这样可能效果更好?
PS:目前 Jenkins pipeline 生态已经比较完善,groovy 语言比 shell 语言语法上更接近大家常用的语言,且也支持自行扩展为独立的外部函数库形成功能组件(比如一个函数就完成执行 httprunner 用例并自动存档对应 html 报告结果的工作)。相比之下 "采用 shell 作为主要开发语言,功能组件化" 目前没太感觉到是一个亮点?
-
兄弟萌,这个名称怎么修改啊? at February 16, 2022
这个是你的登录用户名,意味着改了后你登录时用的用户名也得改过来,否则就登录不了的。大部分地方显示的是 姓名 ,这个是你自己可以自由设定的。
确定要改么?
-
涨薪 30% 的测试工程师面试中这样谈项目 at February 15, 2022
数据流/架构图 这个点个赞。我面试问业务项目的时候,会让面试的同学选一个最熟悉的项目,把这个图画一下。从中可以看出他对这个需求背后技术实现的熟悉度,也便于快速了解这个业务项目进而更好地做后续的提问。
-
接口自动化框架搭建 at February 15, 2022
可以上社区的开源项目版块,或者直接 github 找找?不见得每个框架都会对外宣传的
另外,站内的 hrun4j 有调研过么,是否满足?
PS:不知道你的接口覆盖率统计是啥定义,不过目前很少见到有接口自动化框架会弄这个玩意的。如果定义是已有测试用例的接口数量/所有接口数量,那必须得有全部接口信息,这个属于接口定义或者接口文档范畴了;如果定义是代码行覆盖率之类的,那必须接入覆盖率工具,这个和接口自动化关系就更弱了。
-
【接口自动化】异步接口如何做断言? at February 15, 2022
个人理解,异步接口一般是由于执行耗时长,所以调用方不用等待执行完毕,而是发送完即可。
根据业务场景,有可能发完就啥都不管,也可能会配套有被调用方回调调用方返回数据,以及调用方定时轮询查询数据最新状态避免被调用方回调失败这类操作形成闭环。类似下图(图里是带回调但不带主动查询补偿的场景):
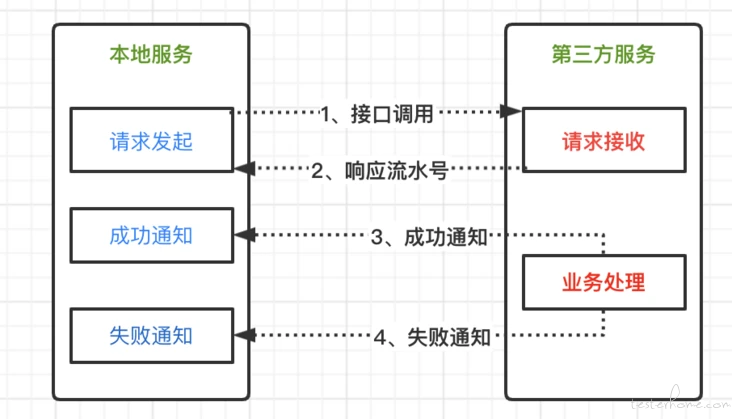
所以怎么做断言,取决于你要校验的是这里面的什么。
- 要校验异步请求本身是否成功——就直接看发送请求后被调用方有没有响应、响应有没有报错(比如格式校验这类耗时很短的可能会直接返回失败响应)、响应时内部处理(如格式校验、记录到内部任务队列中)是否正确。
- 要校验异步请求后被调用方内部处理是否成功——查被调用方的内部数据状态(如查数据库)
- 要校验异步请求后被调用方是否正常回调——在调用方这边查内部数据状态
- 要校验主动补偿是否正常——断言看被调用方的查询接口查询结果,是否和库内最新结果一致;同时关掉被调用方的回调能力,看调用方是否能自己触发主动查询。
-
python *args 和 **kwargs at February 14, 2022
感觉有些文字说得不大清晰,“把参数打包为 xx” 这个有点怪怪的?
我的理解是:本身函数可以接收未命名参数和命名参数。而有些时候函数会需要支持可变参数(比如某些整合类函数,参数可能是直接透传的或者自身逻辑只需要用到其中少量参数),所以才有这样一个方案便于传递和识别函数的所有参数。
未命名参数会按位置顺序传入 *args ,由于本身只有位置没有名字,且不可变,所以用的是 tuple 来封装。
命名参数会传入 **kwargs(kw 是 key word 的缩写),由于本身参数定义是名字 + 值的组合,所以用 dict 来封装。 -
TestDeploy at February 14, 2022
没太看懂,这个是一个环境部署平台,还是一套部署脚本,还是?
跑去 github 看了下 readme ,也点开看了下 demo 地址(打开看就是个 jenkins ),没太看出架构图里提到的各种东西在哪里。而且要实现类似架构图的效果,Jenkins pipeline 貌似也可以实现(加 stage 调用这两个工具即可)。
也可能是我没理解到亮点所在,建议可以举一个典型使用场景,说明下怎么用这个项目,以及用了后带来什么好处?
-
已有接口自动化平台,想引进 UI 自动化,请问是合并一起还是分开两个工程好 at February 14, 2022
没有绝对,看你们实际情况。
从你们接口自动化的技术栈来看,只要 request 改为 appium 就是一个 UI 自动化框架的技术栈了,从这些共性内容方便维护的角度来看,合起来比较好,也便于你们有时候写一些结合接口自动化造数据的 UI 自动化用例。
但如果你们框架内部除了这些基础技术栈,还有比较多针对接口自动化定制的功能,而且这些功能在 UI 自动化上是无法直接复用的,意味着可能会有一定的兼容成本,那 UI 自动化单独弄可能更好。
-
请问一下 jmeter 的用户并发图的,点点点是代表什么意思。 at February 14, 2022
个人理解,圆点代表采样数据。这个图不是每一刻都有新数据采集的,每次采集就会多一个点。然后前后的点连线就成为了看到的曲线了。
至于为啥后面会没有,看你的图像是活动线程数,你结合看看后面这段时间是不是有类似 sleep 或者服务器响应比较慢之类的操作?
-
【专利方向】软件测试专利思考方向 at February 14, 2022
一般著作权好弄点,一个平台甚至一个模块就可以搞一个。专利的话看看有没有什么比较特殊的测试方法或者技术方案,然后查下有没有已有专利,没有的话可以申请下?