-
用终端执行 module not found xxx,但是用终端执行 python 时 import xxx 可导入 at 2022年01月19日
我重新看了下你前面 pip freeze 命令运行环境,命令行最前面没有 (venv) ,说明并不是在 venv 环境中执行。
你按上一层的步骤,在运行
source venv/bin/activate进入 venv 环境后,再执行pip freeze命令看到底有没有装到依赖?没有的话在这个环境内用 pip 命令安装你所需要的依赖就好 -
TouchAction 做滑动解锁 为什么会失败 at 2022年01月19日
那你得看看这个 app 的滑动解锁识别原理是啥,看是不是有什么特殊配置(比如要求每个点要停留一定时间之类的)。
-
用终端执行 module not found xxx,但是用终端执行 python 时 import xxx 可导入 at 2022年01月19日
那看来确实有依赖。把你完整的怎么启动 pytest 的方式发一下?详细到手把手级别,看是不是实际执行环境用的不大一样。
-
TouchAction 做滑动解锁 为什么会失败 at 2022年01月19日
这个应该和新写法没太大关系。你这个滑动解锁人工滑动是要怎么滑的,正常滑完是什么样?你的坐标确认都有对到每个点上了么?
-
TouchAction 做滑动解锁 为什么会失败 at 2022年01月18日
没看出哪里失败了?日志没有报错,左边截图也没提示解锁成功/失败什么的。
麻烦附上一个正确的结果,有对比才能看出哪里不对。
-
使用 tidevice 抓 iOS 日志过程中,想停止抓日志除了按 Ctrl+c 停止还有其他办法吗 at 2022年01月18日
你是怎么调用 tidevice 的呢,一般这种情况发个
kill <进程id>命令发送中断信号给进程,就可以关闭了。电脑 ctrl+c、ctrl+d 这些本质上也是发送信号给进程。关于信号的详细信息,可以参考 https://www.jianshu.com/p/d7b96562d6ed
-
内外网通过隧道反向连接 at 2022年01月18日
这个场景用 V*i 是不是更正规一些?看起来有点像是一些暴露内网端口给公网访问的招,容易有安全风险。
-
专项测试怎样才 “好玩” at 2022年01月18日
有没有结合项目实际实践的分享?
纯这么讲有点虚,而且这些概念也挺多地方有介绍了,不算新,仅仅讲概念没什么感觉。
-
appium 执行抖动的动作 没有反应 at 2022年01月18日
从官方文档介绍,这个 shake 方法只支持 iOS :
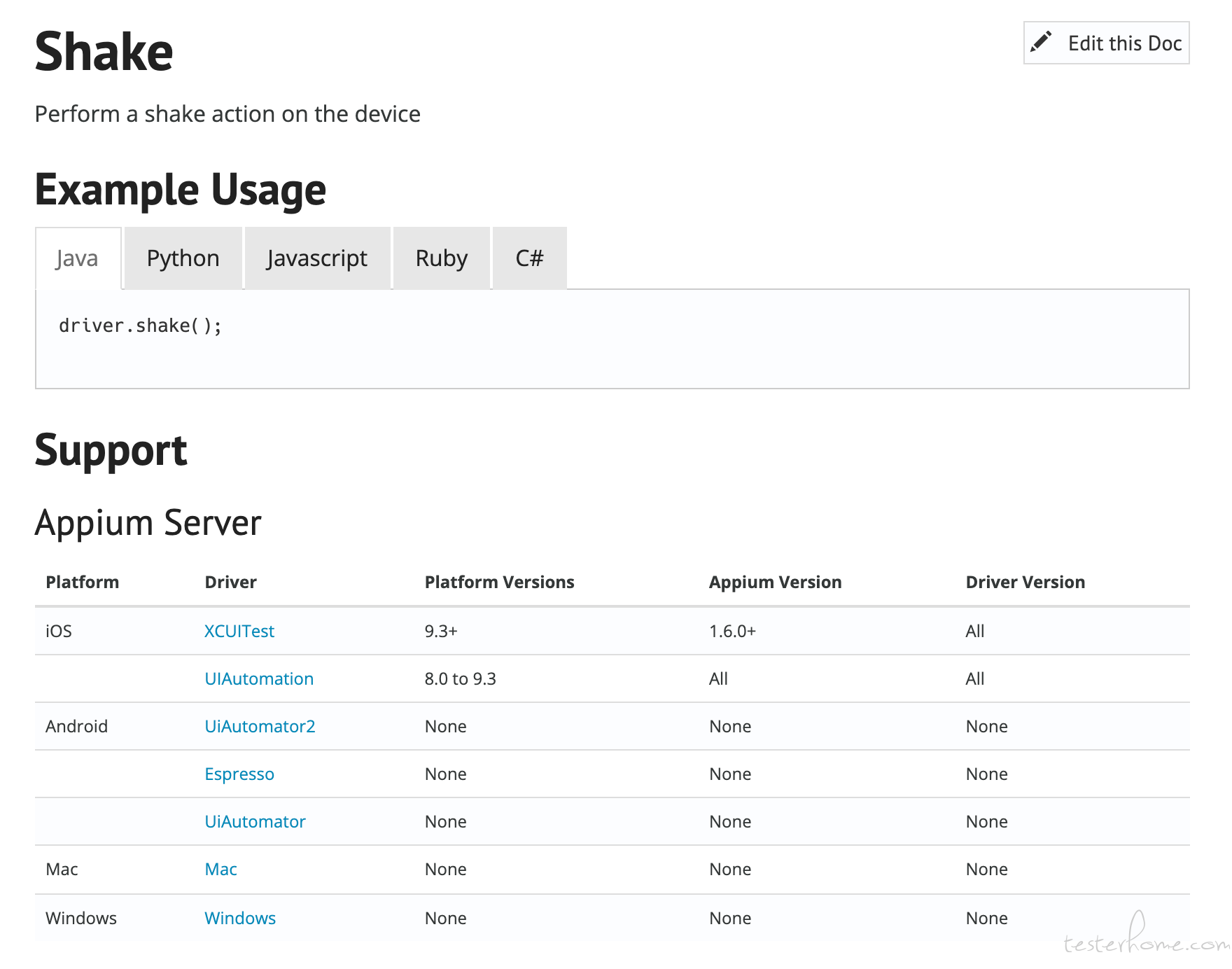
https://appium.io/docs/en/commands/device/interactions/shake/不知道你是什么场景需要用到抖动这样的动作,建议让开发把这个通过抖动触发的功能,加个通过别的方式调用的入口供你调用吧。
-
用终端执行 module not found xxx,但是用终端执行 python 时 import xxx 可导入 at 2022年01月18日
你这个路径确认是你用的 venv 安装依赖库的路径么?建议你在你对应的 venv 环境里用
pip freeze之类的命令确认。虚拟环境是一个 Python 环境,安装到其中的 Python 解释器、库和脚本与其他虚拟环境中的内容是隔离的,且(默认)与 “系统级” Python(操作系统的一部分)中安装的库是隔离的
出自官方文档:https://docs.python.org/zh-cn/3/library/venv.html#venv-def
-
用终端执行 module not found xxx,但是用终端执行 python 时 import xxx 可导入 at 2022年01月18日
venv 里面确认配置和安装了 panda 这个库么?这个虚拟环境的依赖库配置和普通 shell 这些是隔离的,相当于每次都是从一个什么依赖库都没有的干净环境启动。
-
记一个 jenkins 的 slave 连不上 master 的错误 at 2022年01月18日
疑难杂症的原因,总是出现在你想象不到的地方。
-
有图,江湖救急,网站上有对 jmeter 特别熟悉的人吗 at 2022年01月18日
验证过 vars.putObject() 支持写入 byte[] 类型数据么?
-
有图,江湖救急,网站上有对 jmeter 特别熟悉的人吗 at 2022年01月18日
1、可以看看这个回答,也写个最简化代码验证一下?
2、正文提到有报错,具体报错信息也贴上来吧? -
用终端执行 module not found xxx,但是用终端执行 python 时 import xxx 可导入 at 2022年01月18日
无论你有多少个 python ,
which python3都只会有一个的(它显示的是当前环境变量下 python3 命令的实际路径,这个路径是按照 path 的顺序找的,首次匹配就返回,所以不可能有多个),这个校验方法并不正确。具体找法可以参考:https://www.zhihu.com/question/270799956
然后这个问题大概率就是楼上所说的你有不止一个 python ,且不同执行环境用的并不是同一个。卸载掉其中一个,或者确保把环境变量都设置为指向同一个就好。
-
【花菜】我的 2021 年终总结 at 2022年01月18日
恭喜,预祝新婚快乐!求婚这个好有气氛呀~
-
Jenkins 做 docker 集群架构的持续集成,怎样控制镜像的构建? at 2022年01月17日
额,前面说的这个思路可以么?可以的话,写脚本实现然后供 jenkins 调用是否可以?
这个属于项目强相关的逻辑,自行写脚本去实现是最合适的。
-
Jenkins 做 docker 集群架构的持续集成,怎样控制镜像的构建? at 2022年01月15日
控制准确构建,核心是要识别到变更涉及的 service 是什么。
如上面槽神说的,既然区分了 service ,那这几个 service 大部分情况下应该是放在不同文件夹的,然后通过 module 或者 git submodule 之类的形式组合成这个大仓库。那么你通过 git diff 看下改动的代码文件路径包含哪些 service 的文件夹,然后就只运行这个 service 对应的 docker build 命令,是否可以?
-
接口自动化如何获取第三方 token at 2022年01月15日
这个文档没有说 token 哪里来,表示爱莫能助。建议问下开发,程序里这个 token 怎么来的,然后看怎么用程序模拟?
-
「我的 2021 年终总结」2021 年的年度总结 at 2022年01月15日
输出很多,自愧不如。点赞~
PS:一些好的文章也可以分享来社区呀,大家一起交流学习。
-
【MTSC 中国互联网测试开发大会】荣获 2021 中国最受开发者欢迎技术活动 at 2022年01月15日
哇,原来有这么多大会的呀。
-
有图,江湖救急,网站上有对 jmeter 特别熟悉的人吗 at 2022年01月14日
在最后一步将入参加密以后的 byte 类型经过 vars.putObject() 到 http 请求中错误。
具体啥报错?另外,你加密后的 byte 类型具体到底是啥类型,用 java 语言把类型名明确给出来?var.putObject() 并不是所有类型都支持的。如果是 byte[] 类型,这个属于基本数据类型,不属于对象,不一定支持。
-
求近几年 MTSC 大会的视频资源 at 2022年01月14日
关注社区公众号后,底部菜单的 MTSC 大会点击就可以看到最近几届大会视频的入口。

-
请问不懂机器学习的测试开发如何将 AI 应用到测试领域中呢 at 2022年01月13日
你说的这些,本身就是价值。有一部分也有开源自己的模型出来给大家用的吧。
但现阶段 AI 各个模型还是针对性非常强的,建议可以了解下现在 AI 的一些主流算法和应用领域。对于成熟领域(如车牌号识别、OCR 识别、音转文这类)确实不少成熟的基于 AI 实现的方案可用,甚至也有抽离成了简单的 API 便于集成到任意应用中。但对于新领域(比如楼主提到的在游戏测试领域的引用)并没有这样的直接可用的方案,还处于探索阶段。
不过之前 MTSC 大会游戏专场,网易有分享过一个基于 AI 做得自动按指引做任务的实践,楼主可以看看历年游戏专场的议题了解一下。
-
写单元测试的公司多吗? at 2022年01月11日
经历过的公司,一般基础组件类的(比如一些组件)会对单测有要求,因为你单测覆盖率都给不出来别人不敢用,而且这类无界面的组件不写单测更难测试。
而业务系统的比较少,因为比较难写(大部分业务系统因为历史原因欠债严重,核心逻辑很可能在一个一堆 if else 的上帝类里,写功能都难,单元测试就更难了),而且业务变化太快、有测试人员校验,从质量角度也没有非常强的必要写。