-
AI 时代下关于测开的成长之路 at November 05, 2024
OA 打错字了?
-
大家开发测试平台时,前端代码是现写还是找个现有项目模板套? at November 05, 2024
可以用前端组件库呀,比如 vue-admin-template。
有别人封装好的,用就是,开发效率会高不少,代码也更容易维护。
-
ios 自动化,启动 wda 后频繁报: request error: ('Connection aborted.', MuxReplyError(<UsbmuxReplyCode.ConnectionRefused: 3>)),如何解决? at October 29, 2024
推荐 gidevice,稳定性比 tidevice 高,可以 github 搜一下
我们之前云真机要保持 7*24 小时连接,用 tidevice 基本 1 天左右就要重启一次,gidevice 可坚持的时间长不少(具体多久忘了,应该超过 3 天)。
-
为什么测试之家点击新话题不弄成新增一个标签页呢? at September 02, 2024
看个人习惯吧,我自己更习惯通过手势操作进行后退。
如果想新增标签页,可以按住 ctrl/command 键来点击新话题,这样会新标签页打开
-
vue 代码覆盖率怎么实现? at September 02, 2024
我之前文章里有提到,通过 nyc 命令可以插桩:
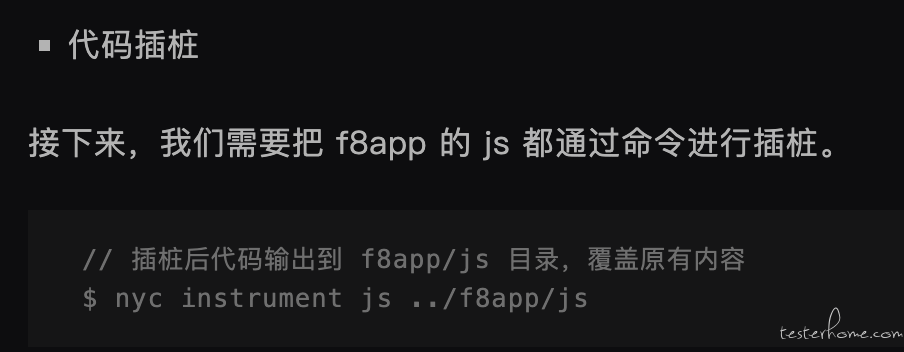
你试下对编译后的 js,用类似的命令插桩下,看看效果?
PS:我这个文章已经是 17 年的了,不确定现在是否还可以用,建议你到 vue 社区里问下,可能会有更好的答案。
-
jenkins 的构建历史是否可以进行重复构建 at August 03, 2024
有插件可以做到类似效果:https://plugins.jenkins.io/rebuild/(只是网上搜到,实际建议自己试验下)
另外,这个场景听起来,是暴露的参数过多,而实际构建其实只有少数几个典型参数组合场景?
如果是,建议改为两端式的 job。用历史构建的话,如果找不到对应的历史构建,还是解决不了这个问题。
job1:对应少数典型参数组合场景,只需要选少量参数即可满足大部分需求。job1 的实际逻辑是根据参数选择情况,对应推断出 job2 所需的参数,并触发 job2 运行。
job2:就是现在的 job,暴露所有参数,按需自定义。 -
怎么才算是测开? at July 29, 2024
这里特指的是不碰业务测试的测试开发部门吧。不是所有测开都在这种部门,所以也不是所有测开都干这个事。
-
怎么才算是测开? at July 29, 2024
这个看你未来发展规划吧。
可以先看下有没有机会,去业务测试团队轮下岗,测 1-2 个项目体验一下,看自己想不想往业务方向走。
如果想,那就逐步增进这块的能力,熟悉业务并通过有效的技术手段控制住业务的质量,以最终业务质量有没有提升为结果。
如果觉得不合适,那就往开发方向转。开发里面也有基础架构平台或者研发效能平台这类开发岗的,你在测试平台的一些经验可以迁移过去,比完全从零到一重新开始好一些。还有一种,就是考虑弄个开源项目并运营起来,在行业内获得一席之地,这样可以获得更多机会,不完全绑死在你现在的公司、现在的岗位。
PS:我听你的描述,连测试流程都不大涉及,感觉像是纯实现需求的开发,对于需求这块的了解还比较少?如果是,可以先在这方面提升一下吧。多和业务测试团队同学交流,了解整体测试流程体系,也培养下自己的思考能力,能从业务诉求里面提取出有效的需求,并设计对应的高性价比解决方案。
-
怎么才算是测开? at July 27, 2024
从之前面试经验,现在会自动化测试(含框架封装)的测试非常多,有的 title 会是纯业务测试,有的会是测开。这个没有绝对,取决于公司定位。
但一般来说,测开至少在开发水平上,搞个自动化框架、自动化平台是没啥问题的。不知道楼主这里的测试框架和工具是复杂到什么程度,不大好评估算不算测开。
以下纯个人理解,仅供参考:
在之前,测开有两个大的类别,一类是业务中的测开,一类是纯工具平台的测开。
业务中的测开,主要就是稀饭说的 能通过技术手段解决业务质量问题的人群 。这部分一般属于业务测试团队里技术水平比较高的,技术视野也广,能想到和落地一些技术手段来切实解决业务质量问题。常用的技术包括但不限于
- 建立自动化测试(包括流量录制回放等)解决回归成本高问题
- 建立造数据工具,解决部分特殊场景模拟成本高问题
- 引入 mock 等技术解决系统间异常难以模拟问题
- 引入代码覆盖率 + 代码与用例关联解决难以准确评估代码改动影响面问题等
- 会阅读研发代码逻辑,有能力参与技术评审及 CR 并发现问题
纯工具平台的测开,主要偏开发,主要是完成一些技术复杂度高的测试平台的设计、研发。这类在很多公司里也称为 “工具组”,一般只有比较大的测试团队才会存在,主要解决业务中测开日常需要兼顾业务测试,工具平台产出相对慢的问题。
不过随着时代变迁,现在剩下的主要是第一类测开,大厂现在招的基本也是这类型的,既能负责业务测试,也能兼顾通过技术手段保障质量。第二类随着大的测试团队减少,以及开源平台工具越来越丰富,从零到一研发必要性降低,会越来越少。
-
周六没人上班吗,论坛如此冷清 at July 06, 2024
加班中
-
大家所在公司,针对线上系统用户反馈的工单,是研发还是测试直接对接呢,恳请大家留言,注明您所在的公司 at July 04, 2024
之前在 toC 业务,基本是客服对接,然后客服过一道后再给产品,产品处理不了再对接测试 + 研发
目前在 toB 业务,之前是有个单独的运营统一对接,现在没有这个岗位了,变为值班研发对接怎么说呢,道理上测试对接是有一定道理,但实际上测试人数少,负荷大,基本很难及时响应,所以实际操作上不大会测试直接对接。
-
退出全部的技术群后,我感受到了清静的美好 at July 03, 2024
微信群、qq 群个人觉得都不大适合聊技术,主要是很难给很长的回复,多次回复又没那么多时间。
社区里好的技术贴回复,基本都到了格式上要做些分点的水平,微信和 qq 里很难做到这个。
-
长期迭代的系统如何管理维护测试用例? at June 24, 2024
我觉得两种不冲突。
1、新需求每个需求一个 xmind,这时候可以写细一些,按重要程度分 P0P1P2
2、新需求上线后,抽半天把 P0 用例合并到核心用例集里。后续每次迭代回归就跑这个核心用例集的内容。 -
兼职,求教 at June 24, 2024
找做产品经理的朋友问下,看有没有啥社区或者资料库。
不过像恒温说的,正式的需求都是内部材料,不大可能会让你收集得到。
-
关于测试怎么交到女朋友的问题 at June 24, 2024
高中同学
-
明天体检,希望身体没啥大问题 at June 24, 2024
祝身体健康。
不知不觉,健身停了大半年了。后面要重拾回来,找回自己的节奏。
-
兄弟们 现在已经是 AI 横行的时代了 有没有什么可以学习辅助测试的 at May 27, 2024
也是差不多,我们主要关注召回率、可用率和对用例编写效率的提升情况。
-
大家买的房子跌了多少了 at May 24, 2024
哈哈,我第一次也是在这本书看到的。后面看《开窍》和别的书,里面也有类似的观点,所以记忆就越来越深刻了。
《穷爸爸富爸爸》是本好书。只是我自己实在控制不住自己,做不到尽量只花收益的钱,少动本金。
-
兄弟们 现在已经是 AI 横行的时代了 有没有什么可以学习辅助测试的 at May 23, 2024
测试用例生成,这块还挺多公司在探索的。
-
阶梯性压测,到时间任务结束不了? at May 23, 2024
从 tps 的图看,3 分钟后已经停止发起请求了,但直到 7 分钟结束,持续有 http fail 出现,说明是一直在等待 http 请求返回,直到全部返回都收到/都达到超时上限自动结束。
你把响应时间的图加上,应该就很清晰了。
-
大家买的房子跌了多少了 at May 22, 2024
嗯嗯,确实是可以换。我想表达的是,不具备投资的赚取收益属性,因为卖的时机取决于自己的刚需,而不是涨了就可以卖。而且自住的,也没法通过收租之类的方式持续获得被动收入,只是在不断地付房贷。
-
大家买的房子跌了多少了 at May 20, 2024
学习算不上,主要看一些理财书里看到的。
-
测试工作在有效推动产品质量提升方面可以做哪些内容 at May 18, 2024
想先了解下,你这里的 产品质量 ,定义包括哪些?
比如一些需求内容不够明确,不满足实际业务需要,没达到预期的业务目标,在你这个范畴中不?
-
接口测试 - 参数测试 at May 18, 2024
1、编程语言里的数据类型要转换为 json,有一个叫 序列化 的过程。这个过程会把变成语言里的数据类型,按照一定规则转为 json 里的数据类型。python 里一般用自带的 json 库进行序列化(具体要看你们研发的代码)。
这个库的 python 转 json 的转换规则如下:https://docs.python.org/3/library/json.html
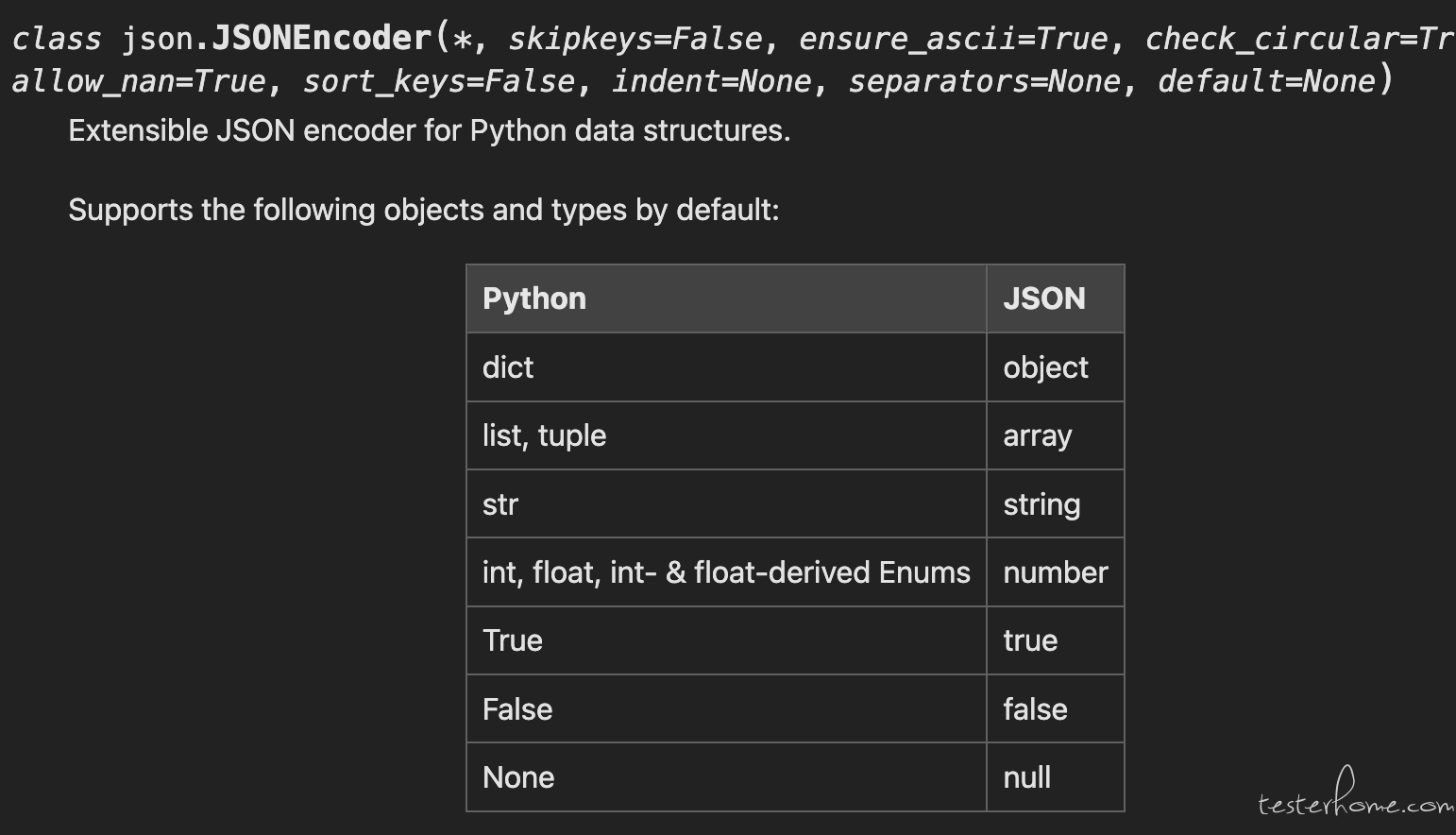
2、按照上面规则,turple 应该转为了 json 的 array,而你的接口规定的参数类型是 string,自然对不上
3、覆盖的时候,覆盖 json 支持的格式就好。甚至有些场景下,没太大必要做这个测试,因为各个语言的反序列化其实是有一定的兼容性的,比如 json 传了 string 类型的"3",语言中对应的类型是 int,会尽量转为 int。这部分转换是各个库自动完成的,开发压根不用写代码,风险也低。所以在做参数覆盖的时候,相比单纯从技术层面去设计,更建议从业务层面去设计。业务层面的才是研发要写代码实现的,也是风险更高的。
-
点工如何学习设计模式和算法 at May 18, 2024
如果不打算做任何和代码沾边的事情(如自动化、提效脚本编写等),也不想和开发交流时让对方觉得你懂行,确实没啥用。