-
暗黑模式下审核区 UI 显示 bug at 2022年04月30日
css 用得不对,导致没适配。已修正。
顺便也关贴了。
-
HttpRunner v4.0 正式发布:一文了解 v4.0 的前世、今生与未来 at 2022年04月29日
越来越强大了,特别支持多协议这个,点赞!
-
测试左移 - 测试过程左移 at 2022年04月29日
TCDD(测试用例驱动开发)这个新概念,可以扩展说下具体是什么意思么?和 TDD、ATDD 这些有什么不同?学习学习下
然后你这两个部分,感觉相比前面的 12 个步骤,会不会有点过了?。需求质量、代码质量在你抽象后都没了,这个我理解应该是你标题说到的 测试过程左移 的核心之一。
-
记一次测试开发面试题 at 2022年04月29日
第一轮估计我就过不了了,有些东西不常用记不住,只能说个大概。。。
-
说好的金三银四呢,今年怎么这么难 at 2022年04月29日
不错,
怎么用技术解决问题和提效这方向是对的,继续加油吧!PS:如果觉得自己这么久都没拿得出手的成果,有可能是你日常任务波澜比较小,挑战性不高。可以试下后面遇到挑战性任务(简单点说,就是你第一反应会是个深坑或者很难的任务)时,自己主动去争取做一下。这类任务一般数量不多,但完成后给到你的成长会比普通任务要明显的多,而且成果相对亮眼,也容易让领导看到你,后面给你更多的机会。
-
如何保障需求质量(上):你应该知道的 at 2022年04月29日
管理不好这个,有啥好工具建议么?
现在测试用例通过平台编辑历史可以跟踪、代码通过 git 可以跟踪,唯独需求啥时候变、变了啥没有合适工具去跟踪。经常需求评审的时候需求质量还不错,后面实际开发时有些需求会进一步补充或者微调,就会因为管理不好出各种问题。
-
【已解决】急!遇到一个元素定位问题,没找到成功的解决方案 at 2022年04月29日
找不到元素的时候,打印 page source 看看先?
有时候 page source 看到的,和你浏览器 elments 看到的会有一些出入。也可能是这个是延迟加载的,你找元素的时候还没加载出来。
先打印 page source 确认有控件,再 find ,会比较稳。
-
说好的金三银四呢,今年怎么这么难 at 2022年04月29日
如果你是想找测试技术积累比较不错的中大厂,建议想办法找内推,不要想着靠海投。海投的话一般第一关是 hr 筛,学历一个过滤条件可能你的简历就没在列表里了,而且现在 HC 少的情况下,对人员的要求会更高一个档次。
另外,7 年经验,总归要有点拿得出手的成果吧(不一定是技术的,业务方面的也可以,测试也不仅仅是技术),可以写一下这些成果?
-
说好的金三银四呢,今年怎么这么难 at 2022年04月29日
可以粗细结合,但不能都是细节。
筛简历的人一般是 leader ,习惯性会优先关注成果,其次才是过程细节(毕竟有些总监其实过程细节已经很久没怎么接触了)。细节不用写全,毕竟内容比较多,一般都是面试才会把细节聊透。
你这里没有写任何成果,写的过程细节也没啥亮点(都是网上很容易就能找到且使用很普遍的技术),所以在茫茫简历中,吸引度远不如那些写着 “测试时间缩短 xx%/线上故障率降低 xx%” 这类带有量化成果说明的简历。
-
测试左移 - 测试过程左移 at 2022年04月29日
TCDD 是啥?第一次听。
...产品参与;从上面的 12 步骤里,抽象出三部分
1、测试用例开发;-基本能力
2、测试脚本开发;-升级能力
3、QA 质量体系监控;--数据可视化
这两部分才是测试重点关注的地方,但要把 12 部分内容释放出来:分两部分实践:是有错别字么?一会两部分,一会三部分,表示没看懂。然后这个抽象也没懂,12 个步骤怎么能抽象成这 3 个部分。
-
wsl 环境 appium 报错,github、官网搜索未果,恳请社区大佬帮忙解决~ at 2022年04月29日
如何通过 adb 命令检测 server 进程是否存活
你之前贴的 appium 日志里就有:
2022-04-27 03:17:51:407 [ADB] Running '/lib/android-sdk/platform-tools/adb -P 5037 -s emulator-5554 shell pm list instrumentation'E wifi_forwarder: RemoteConnection failed to initialize: RemoteConnection failed to open pipe
查了下,你这个的进程号和 UIAutomator 无关,而且出现了 N 次,不过既然涉及 port ,确实有一定概率是有关的。要排除也很简单,在关闭 Uiautomator2 server 后,继续捕获 logcat 日志,看会不会出现。会的话说明没关系。
关闭 UIAutomator2 server 的方式,可以参照 appium 日志
2022-04-27 03:17:52:252 [ADB] Running '/lib/android-sdk/platform-tools/adb -P 5037 -s emulator-5554 shell am force-stop io.appium.uiautomator2.server.test'我调大 server 检测的超时时间,'uiautomator2ServerLaunchTimeout':'500000', 还是无法启动 UiAutomator2 server
从快速解决问题的角度,建议你直接换台别的测试机试试。如果要继续定位,可以参照我上面写的来看,日志实在没线索的话,需要继续追到 UIAutomator2 server 源码。
-
有个技术需求 - 请教下社区大佬们 at 2022年04月29日
不客气
PS:少发这类大表情图吧,毕竟这里不是微信群,有点闪瞎眼。。。
-
大佬们了解招行信用卡的测开嘛 at 2022年04月29日
都是比较大的公司,没说具体业务和团队不好比。
只能说整体印象上,招行的测试技术在银行里还是算很不错的,可能相对来说没有互联网那么极致(主要是业务体量差异引起),但比其他银行应该是好不少的。联想就不大清楚了,接触比较少。
-
说好的金三银四呢,今年怎么这么难 at 2022年04月29日
只看这部分内容,感觉写得太细节了,也缺少成果说明,在现在 hc 紧张的大环境下没什么吸引力。写项目经历还是用下 star 法则吧。
-
locust 压测脚本如何进行合理的参数化? at 2022年04月28日
不熟悉 locust , @debugtalk 帮忙看下是不是参数化姿势问题?
-
给大家分享点鸿蒙小知识 at 2022年04月28日
收藏了,后面如果需要弄鸿蒙原生包的时候用得上。
-
“私人社团” 本意是用来做什么的吗? at 2022年04月28日
get 到大家的意思了,就是帖子列表页屏蔽掉私人社团的帖子,避免出现看到帖子点进去却没权限看内容。
这个应该是之前遗漏的一个功能点,我加到我的 todo 里,五一抽空弄一下
-
wsl 环境 appium 报错,github、官网搜索未果,恳请社区大佬帮忙解决~ at 2022年04月27日
这个是 android 平台,和 ios 的 WDA 没太大关系。 WD = Web Driver 。
-
wsl 环境 appium 报错,github、官网搜索未果,恳请社区大佬帮忙解决~ at 2022年04月27日
日志挺齐全,先赞一个
先分享下解析日志的思路,便于你看懂下面说的东西:
1、首先,得先大概了解 appium 这个场景下的大致架构原理。以下这个是 appium 在使用 uiautomator2 模式下的最新架构图(出自官方 https://github.com/appium/appium-uiautomator2-server/wiki ,百度搜关键字
appium uiautomator2,也能找到相关文章说明):
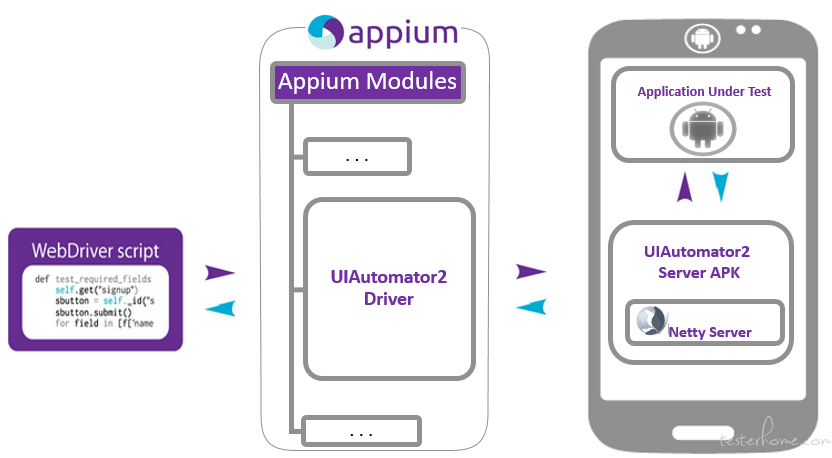
2、了解架构后,从 appium 日志开始出错的位置开始分析,了解出错的直接原因
3、从直接原因的日志继续往前看,看前面做了什么,和架构图里的这些组件模块的关系是什么。辅助看 logcat 日志找到一些 appium log 里找不到的安卓系统内部错误信息
然后我从第二步开始详细说下怎么分析:
- 日志出错位置
2022-04-27 03:18:24:008 [UiAutomator2] The instrumentation process cannot be initialized within 30000ms timeout. Make sure the application under test does not crash and investigate the logcat output. You could also try to increase the value of 'uiautomator2ServerLaunchTimeout' capability.直接原因翻译过来就是:instrumentation 进程在 30 秒超时时限内未能完成初始化。请确认被测应用没有崩溃(这里有点误导,应该看 instrumentation 进程有没有崩溃)并查看 logcat 输出。你也可以通过 uiautomator2ServerLaunchTimeout 调大超时时间
- 往前看,看前面在做什么
2022-04-27 03:17:53:549 [WD Proxy] Matched '/status' to command name 'getStatus' 2022-04-27 03:17:53:554 [WD Proxy] Proxying [GET /status] to [GET http://127.0.0.1:8200/wd/hub/status] with no body ... 2022-04-27 03:18:23:998 [WD Proxy] Matched '/status' to command name 'getStatus' 2022-04-27 03:18:23:999 [WD Proxy] Proxying [GET /status] to [GET http://127.0.0.1:8200/wd/hub/status] with no body 2022-04-27 03:18:24:006 [WD Proxy] Got response with unknown status: {"errno":-111,"code":"ECONNREFUSED","syscall":"connect","address":"127.0.0.1","port":8200}这段是在不断重试连接 http://127.0.0.1:8200/wd/hub/status 这个地址,为啥要连接这个地址呢?从架构图可以看到,有个 netty server ,实际就是在尝试连接这个 server 。因为只有这个 server 能连上,才有办法从 appium 服务端通过发信息给这个 server ,操作手机里的 app 。
2022-04-27 03:17:52:536 [UiAutomator2] Starting UIAutomator2 server 4.5.5 2022-04-27 03:17:52:537 [UiAutomator2] Using UIAutomator2 server from '/usr/local/lib/node_modules/appium/node_modules/appium-uiautomator2-server/apks/appium-uiautomator2-server-v4.5.5.apk' and test from '/usr/local/lib/node_modules/appium/node_modules/appium-uiautomator2-server/apks/appium-uiautomator2-server-debug-androidTest.apk' 2022-04-27 03:17:52:537 [UiAutomator2] Waiting up to 30000ms for UiAutomator2 to be online... 2022-04-27 03:17:52:538 [ADB] Creating ADB subprocess with args: ["-P",5037,"-s","emulator-5554","shell","am","instrument","-w","io.appium.uiautomator2.server.test/androidx.test.runner.AndroidJUnitRunner"] 2022-04-27 03:17:52:966 [Instrumentation] io.appium.uiautomator2.server.test.AppiumUiAutomator2Server:这段挺清晰了,在启动 UIAutomator2 server ,并在启动完后等待 30 秒直到它在线。和上一段持续尝试连接能对上了。然后启动用的 adb 命令参数是 "-P",5037,"-s","emulator-5554","shell","am","instrument","-w","io.appium.uiautomator2.server.test/androidx.test.runner.AndroidJUnitRunner"
2022-04-27 03:17:52:238 [UiAutomator2] Performing shallow cleanup of automation leftovers 2022-04-27 03:17:52:251 [UiAutomator2] No obsolete sessions have been detected (Error: connect ECONNREFUSED 127.0.0.1:8200) 2022-04-27 03:17:52:252 [ADB] Running '/lib/android-sdk/platform-tools/adb -P 5037 -s emulator-5554 shell am force-stop io.appium.uiautomator2.server.test'这段的关键语句是第一行的
Performing shallow cleanup of automation leftovers,翻译过来就是清理上一次自动化测试可能存在的遗留内容(有可能上一次是被手动中断的,所以开始前需要检测并恢复到下一步需要的初始状态,和我们自动化测试 setup 做的事情差不多)。实际做了啥?两个事情,一个是尝试连接 127.0.0.1:8200(结果是 ECONNREFUSED ,连不上),另一个是通过 am force-stop 杀掉 io.appium.uiautomator2.server.test 对应进程(这也是后面 logcat 里会存在 crash 这样的字眼的原因,在 crash 位置往上看就会看到是被 kill 掉了)同时通过这段分析其实可以发现,带有
[ADB]的是实际执行命令的信息,我们排查日志关键不是看命令细节,而是看意图,所以后续分析主要看带有[UiAutomator2]的2022-04-27 03:17:48:173 [UiAutomator2] Checking whether app is actually present ... 2022-04-27 03:17:50:329 [UiAutomator2] Forwarding UiAutomator2 Server port 6790 to 8200 ... 2022-04-27 03:17:50:551 [UiAutomator2] io.appium.uiautomator2.server installation state: sameVersionInstalled ... 2022-04-27 03:17:51:403 [UiAutomator2] Server packages are not going to be (re) installed 2022-04-27 03:17:51:406 [UiAutomator2] Waiting up to 30000ms for services to be available ... 2022-04-27 03:17:51:680 [UiAutomator2] Instrumentation target 'io.appium.uiautomator2.server.test/androidx.test.runner.AndroidJUnitRunner' is available只看
[UiAutomator2],相当清爽,我在末尾补上中文翻译方便查看2022-04-27 03:17:48:173 [UiAutomator2] Checking whether app is actually present ——判断 app 是否存在 ... 2022-04-27 03:17:50:329 [UiAutomator2] Forwarding UiAutomator2 Server port 6790 to 8200 ——把 server 的端口从6790转发8200(和网络请求地址端口号是 8200 对上了) ... 2022-04-27 03:17:50:551 [UiAutomator2] io.appium.uiautomator2.server installation state: sameVersionInstalled ——确认 io.appium.uiautomator2.server 的安装状态为:已安装同版本的应用 ... 2022-04-27 03:17:51:403 [UiAutomator2] Server packages are not going to be (re) installed——得出结论:Server安装包不需要再安装 2022-04-27 03:17:51:406 [UiAutomator2] Waiting up to 30000ms for services to be available——等待30秒知道服务初始化完毕(因为之前有可能由于某些原因已经启动了应用,所以这里等上30秒保障之前启动的已经启动完毕) ... 2022-04-27 03:17:51:680 [UiAutomator2] Instrumentation target 'io.appium.uiautomator2.server.test/androidx.test.runner.AndroidJUnitRunner' is available——查到有 io.appium.uiautomator2.server.test/androidx.test.runner.AndroidJUnitRunner 的可用服务,和后面强制停掉服务对上号- 看完 appium log ,结合看 logcat
logcat 因为混杂了所有系统信息,所以需要自己想办法捞和自己要查的东西有关的信息。这个过滤方法的核心就是:进程号。要找到进程号,先得找到进程名,搜索
io.appium.uiautomator2.server.test,找到和它有关的启动信息04-27 03:17:52.063 5053 5068 I TestRunner: started: startServer(io.appium.uiautomator2.server.test.AppiumUiAutomator2Server)然后通过这个信息,找到进程号是 5053 ,线程号是 5068(不是高并发,线程号在这里用处不大,可以忽略)。然后找到所有 logcat 里的 5053 内容(推荐保存到文件后,cat + grep 快速过滤)
04-27 03:17:51.933 5053 5053 I art : Late-enabling -Xcheck:jni 04-27 03:17:51.934 5053 5053 W art : Unexpected CPU variant for X86 using defaults: x86 04-27 03:17:51.936 1698 1710 I ActivityManager: Start proc 5053:io.appium.uiautomator2.server/u0a81 for added application io.appium.uiautomator2.server 04-27 03:17:51.952 5053 5060 E art : Failed sending reply to debugger: Broken pipe 04-27 03:17:51.953 5053 5060 I art : Debugger is no longer active 04-27 03:17:51.953 5053 5060 I art : Starting a blocking GC Instrumentation 04-27 03:17:51.958 5053 5053 W System : ClassLoader referenced unknown path: /data/app/io.appium.uiautomator2.server.test-1/lib/x86 04-27 03:17:51.958 5053 5053 W System : ClassLoader referenced unknown path: /data/app/io.appium.uiautomator2.server-1/lib/x86 04-27 03:17:51.961 5053 5053 W System : ClassLoader referenced unknown path: 04-27 03:17:51.971 5053 5053 I MonitoringInstr: Instrumentation started! 04-27 03:17:51.971 5053 5053 I MonitoringInstr: Setting context classloader to 'dalvik.system.PathClassLoader[DexPathList[[zip file "/system/framework/android.test.runner.jar", zip file "/data/app/io.appium.uiautomator2.server.test-1/base.apk", zip file "/data/app/io.appium.uiautomator2.server-1/base.apk"],nativeLibraryDirectories=[/data/app/io.appium.uiautomator2.server.test-1/lib/x86, /data/app/io.appium.uiautomator2.server-1/lib/x86, /system/lib, /vendor/lib]]]', Original: 'dalvik.system.PathClassLoader[DexPathList[[zip file "/system/framework/android.test.runner.jar", zip file "/data/app/io.appium.uiautomator2.server.test-1/base.apk", zip file "/data/app/io.appium.uiautomator2.server-1/base.apk"],nativeLibraryDirectories=[/data/app/io.appium.uiautomator2.server.test-1/lib/x86, /data/app/io.appium.uiautomator2.server-1/lib/x86, /system/lib, /vendor/lib]]]' 04-27 03:17:51.973 5053 5053 I MonitoringInstr: No JSBridge. 04-27 03:17:51.975 5053 5068 I MonitoringInstr: Setting context classloader to 'dalvik.system.PathClassLoader[DexPathList[[zip file "/system/framework/android.test.runner.jar", zip file "/data/app/io.appium.uiautomator2.server.test-1/base.apk", zip file "/data/app/io.appium.uiautomator2.server-1/base.apk"],nativeLibraryDirectories=[/data/app/io.appium.uiautomator2.server.test-1/lib/x86, /data/app/io.appium.uiautomator2.server-1/lib/x86, /system/lib, /vendor/lib]]]', Original: 'dalvik.system.PathClassLoader[DexPathList[[zip file "/system/framework/android.test.runner.jar", zip file "/data/app/io.appium.uiautomator2.server.test-1/base.apk", zip file "/data/app/io.appium.uiautomator2.server-1/base.apk"],nativeLibraryDirectories=[/data/app/io.appium.uiautomator2.server.test-1/lib/x86, /data/app/io.appium.uiautomator2.server-1/lib/x86, /system/lib, /vendor/lib]]]' 04-27 03:17:51.979 5053 5068 I UsageTrackerFacilitator: Usage tracking enabled 04-27 03:17:51.979 5053 5068 I TestRequestBuilder: Scanning classpath to find tests in paths [/data/app/io.appium.uiautomator2.server.test-1/base.apk] 04-27 03:17:52.060 5053 5068 D TestExecutor: Adding listener androidx.test.internal.runner.listener.LogRunListener 04-27 03:17:52.060 5053 5068 D TestExecutor: Adding listener androidx.test.internal.runner.listener.InstrumentationResultPrinter 04-27 03:17:52.060 5053 5068 D TestExecutor: Adding listener androidx.test.internal.runner.listener.ActivityFinisherRunListener 04-27 03:17:52.061 5053 5068 I TestRunner: run started: 1 tests 04-27 03:17:52.063 5053 5068 I TestRunner: started: startServer(io.appium.uiautomator2.server.test.AppiumUiAutomator2Server) 04-27 03:17:52.065 5053 5053 I MonitoringInstr: Activities that are still in CREATED to STOPPED: 0 04-27 03:17:52.067 5053 5068 I appium : [AppiumUiAutomator2Server] Starting Server 04-27 03:17:53.072 5053 5068 I appium : AndroidServer created on port 6790 04-27 03:17:53.073 5053 5068 I appium : io.appium.uiautomator2.server started: 04-27 03:17:53.084 5053 5070 I appium : Started UiAutomator2从最末尾的几条信息看,服务是正常启动了的,没有任何崩溃或者报错相关信息。注意这里有个暗坑,可能手机和电脑时间没达到秒级对齐,所以两边的启动时间稍微有点对不上。
结论
从 logcat 日志看,虽然 appium server 30 秒内都没有能访问通 /status 接口,但也没有明显的崩溃或者退出的错误信息。说明可能两种原因:
1、启动太慢了,30 秒内启动不完。
2、其实已经崩溃了,只是 logcat 没采集到排查方法也不难,按照 appium 前面指引调大 server 检测的超时时间,同时弄个简单的脚本每秒通过 adb 命令(注意不是网络接口)检测 server 进程是否存活(排除可能性 2)。如果改大后,直到超时进程还存活的话,那继续改大超时;如果已经不存活,从 logcat 里尝试捞崩溃日志再分析。
-
“私人社团” 本意是用来做什么的吗? at 2022年04月27日
我解答一下吧:
私人社团的本意,是用于给一些组织借助社区作为自己的内部资料记录、交流,同时内容不大想公开给所有人用。比如我们管理员有个内部站务的私人社团,用于记录一些不大适合公开的内部事务。(其实主要是这个是 rubychina 加的功能,我们拿过来成本不高,且又确实有使用场景,所以就拿过来了,哈哈)
至于你提的几个问题:
为什么在私人社团里发的问题,我一个社团外部的人能看到?
能否发下具体的地址及看到入口的截图?这应该是个 bug 。去年年底关站期间,权限系统做了比较大变更,可能引起了这方面的问题。
在什么情况下才需要往私人社团里发问题求解答?
这个属于发帖人自己想法,我也给不了答案。。。
一个私人社团大几百号上千人,“私人” 的意义在哪里?跟整个社区有区别吗?
私人社团的入团是需要社团自己的管理员审核的,内容查看也只有社团内的人可见,这个是 “私人” 所在。至于社团规模,这个我们交由社团管理员自己来控制,从社区管理的角度,现阶段没有太大的控制单个社团人数规模的必要性。而且相比社区 6w 多用户,一个社团几百上千人并不算多。
-
linux+appium+ 安卓系统-sdk-(移动端自动化) 找了一圈也没有答案 at 2022年04月27日
不知道。。。等楼主本人来说清楚吧。
-
公司需要从 0 到 1 搭建测试团队,咨询一下各位大哥,如果从收益上来考虑,优先做哪些事呀? at 2022年04月27日
这个上下文实在太少,团队现状也不知道,不知道怎么回答好。。。可以提供更多信息么?
-
linux+appium+ 安卓系统-sdk-(移动端自动化) 找了一圈也没有答案 at 2022年04月27日
目前就是卡在,linux 服务器里安装安卓系统,linux 中 adb 连接安卓设备,然后执行 python 脚本,运行 app 自动化,后续结合 Jenkins 集成
额,我语文不大好,你意思是说这么多地方卡住?可以分享下你自己通过什么方式找,找到了什么文章,然后你现在有什么问题是这些文章都解答不了的?
- linux 服务器里安装安卓系统
这个只能弄虚拟机吧,毕竟两个都是完整的操作系统。不过 x86 平台上高性能的 android 系统基本都是 x86 指令集的,用 arm 指令集的因为要额外转译性能都一般,而且目前手机上的系统都有各种自家的二次开发,和原版的有一定差异,所以这么跑出来的结果可信度有限,比较少人这么做。
-
有个技术需求 - 请教下社区大佬们 at 2022年04月27日
看起来是个技术优化需求,从需求看应该是 redis 和数据库数据结构不变的情况下,优化中间的定时任务性能。所以还是最好去看下代码确认下逻辑是否一致,纯黑盒难保会有遗漏。
如果是我测,我会这么做:
1、先了解清楚原来老的定时任务,具体做了什么转换。这个了解相比问开发,更需要自己也去看看相关代码,代码里才有最充分的细节
2、然后 review 新的定时任务,转换逻辑和老代码是否一致
3、逻辑 review OK 后,找一些 redis 数据,分别交给新老定时任务去处理, diff 对比下输出值有没有差异,同时可以看看性能是否有提升
4、最后结合整个业务去过一下代驾功能里和这个定时任务有关的用例,确认整体功能正常
5、最后确认下预计的上线切换方案(最稳的是新的任务先不要写到正式表,先写到一个临时表,然后观察一段时间确认写入的内容和老任务一样,再关掉老任务,新任务切换到正式表),做一下演练。 -
聊聊 leader 的向上管理和向下管理 at 2022年04月25日
除了找 bug,测试团队是不是能给公司的业务带来更多贡献?比如帮助整个团队的品质得到进一步的提升:“品质 “要比” 缺陷 “的范围大很多。
这点很认可,要扩大上级对测试价值的认知,如果总是觉得测试只是手工活点点点,那后面会处处受限。