-
k8s 集群监控平台的实现 at 2022年02月26日
测试
-
【匿名讨论】薪酬交流 at 2022年02月24日
我们这里还是不要搞的跟 maimia 一样 吧
 都是匿名的大家说的都不一定是真的, 没有啥参考价值的。
都是匿名的大家说的都不一定是真的, 没有啥参考价值的。 -
普罗米修斯 -- 自定义 exporter at 2022年02月18日
自定义监控的~~~
-
测试不做到管理岗,是不是很难突破 40k? at 2022年01月25日
我理解是的, 毕竟研发那边更卷一些
-
怎么模拟 grpc 的响应?k8s 环境,A 服务和 B 服务在不同的 namespace 中,A 通过 grpc 调用 B 服务的接口,怎么让 B 给 A 返回一个 mock 的响应。 at 2022年01月18日
https://testerhome.com/articles/27001
楼主参考一下我之前在 k8s 里玩 mock server 的帖子。 也是用的 side car 模式。 isto 确实也是这么玩的
-
怎么模拟 grpc 的响应?k8s 环境,A 服务和 B 服务在不同的 namespace 中,A 通过 grpc 调用 B 服务的接口,怎么让 B 给 A 返回一个 mock 的响应。 at 2022年01月18日
我一般的思路都是写个工具,动态的往目标 pod 里注入一个 proxy 容器, 同一个 pod 内的所有容器是用 container 网络模式启动的,共享网络。 如果需要篡改 ip 的话, 一个 iptables 命令就可以了。
-
怎么模拟 grpc 的响应?k8s 环境,A 服务和 B 服务在不同的 namespace 中,A 通过 grpc 调用 B 服务的接口,怎么让 B 给 A 返回一个 mock 的响应。 at 2022年01月17日
你现在碰到的是什么问题? 是不知道怎么写 rpc server 去返回 mock 响应? 还是不知道怎么劫持 A 到 B 的响应?
-
普罗米修斯 -- HTTP API 调用 PromQL at 2022年01月17日
测试
-
普罗米修斯 -- PromQL 进阶 at 2021年12月07日
测试
-
普罗米修斯 -- 初识 PromQL at 2021年11月25日
测试
-
在 UI 自动化中调用浏览器 API 的方法与使用场景 at 2021年11月10日
咨询一下, 你怎么计算的这些指标。 调用的什么 API?
-
普罗米修斯 -- 基本使用 at 2021年11月10日
最近有时间了
-
普罗米修斯 -- 基本使用 at 2021年11月10日
测试
-
大厂面试总结 at 2021年11月10日
每个领域要掌握的知识都不一样 , 别焦虑,我们只是可能不在一个领域里而已。 比如我现在对视频音频类的测试工作就是屁都不懂。
-
在 UI 自动化中调用浏览器 API 的方法与使用场景 at 2021年11月10日
我用的是 chrome 浏览器, 倒是不用加上 window~~
-
当大数据平台在一些配置普通的物理机上时,有必要进行测试吗? at 2021年11月10日
用这个配置 部署 CDH 是搞笑么。。。。。。 咱们 尊重一下大数据吧。。。。。 这个配置跑不起来什么大数据任务的。
-
在 UI 自动化中调用浏览器 API 的方法与使用场景 at 2021年11月10日
performance.getEntries 能获取所有异步的请求的性能信息
-
UI 自动化中的分层设计 at 2021年11月09日
嗯, 新项目用的 python, 没办法, 团队的小伙盘都熟 python, java 不熟。
-
测试开发之路--UI 自动化常用设计模式 at 2021年11月08日
握个抓~ 当初封装这块 UI 自动化的时候, 着实很费劲
-
UI 自动化中的分层设计 at 2021年11月08日
有多种方法解决。 比如可以通过直接在数据库中构造测试数据绕过之前的步骤。 不过我其实还是比较喜欢就是在 UI 上从头开始准备。 模拟真实用户的行为。 开发成本也较低, 有些后台数据过于复杂, 绕过 UI 和 API 直接在数据库中 mock 实在不太现实。
-
UI 自动化中的分层设计 at 2021年11月08日
- 组件层: 跟你说的差不多, 只不过除了定位以外,还有一些基本操作。 比如我举的上传的例子。 有些控件的操作还是很复杂的。
- 页面层和业务逻辑层: 可以这么理解, 页面层是封装单页操作的, 业务逻辑层是调用页面层的多个 class 完成多页面操作以组合成业务逻辑。 比如我们要测试一个订单流程。 这个流程里肯定跳了很多个页面的, 每个页面在页面层里封装自己页面的操作逻辑。 而业务逻辑层就是调用这些页面来完成自己的业务逻辑。 所以理论上, 业务逻辑层才是哪个比较轻的层。
- 用例层: 确实用例层就是调调函数。
-
UI 自动化中的分层设计 at 2021年11月08日
以后多交流~ 我在写 API 测试的时候, 做法也跟你差不多。

-
UI 自动化中的分层设计 at 2021年11月08日
看上面截图哈
-
UI 自动化中的分层设计 at 2021年11月08日
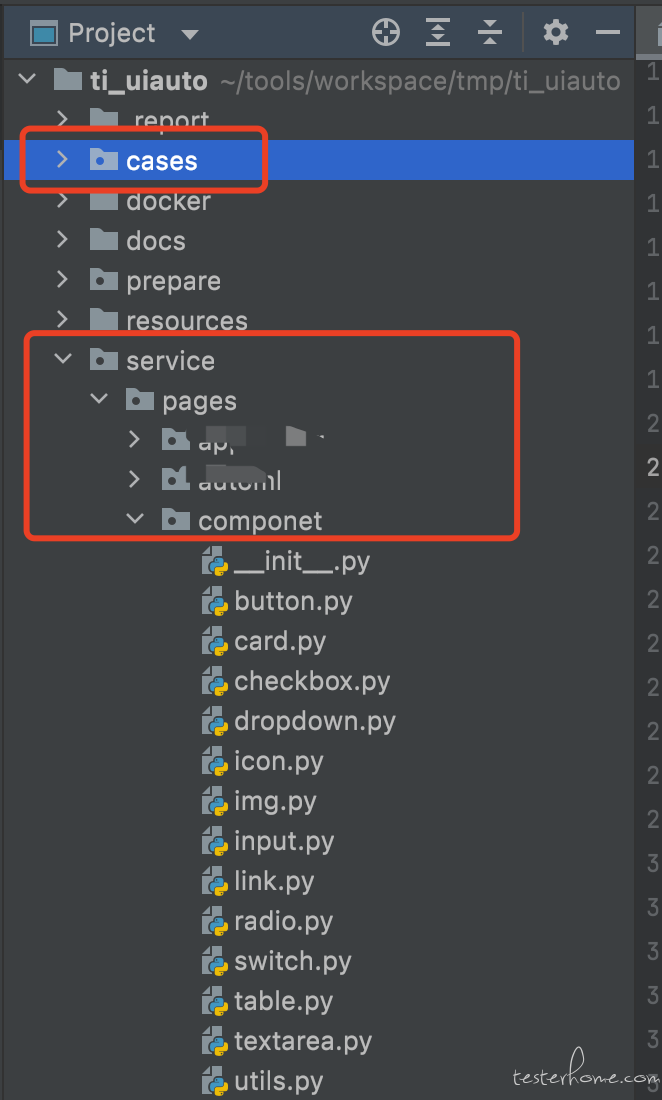
结构很简单的
-
UI 自动化中的分层设计 at 2021年11月07日
测试