前言
接上一次的帖子,今天讲一下我再 UI 自动化中常用的设计模式。 由于网上已经有非常多的文章详细讲解了设计模式的编码实现,所以我今天也就不讲实现细节了。 就是讲我也讲不出什么花来,只是网上的文章基本都是讲解设计模式的本身实现,很少针对某一领域的实际场景去讲具体改怎么用设计模式。 所以今天我只针对一些实际的场景来说一下如何使用这些设计模式来完善 UI 自动化。
工厂
每种语言实现设计模式的方式都不一样,这里仅以 java 为例。 一般来说,工厂模式是为了把创建一个对象的操作都集中在一起管理,其他所有需要用到这个对象的代码都调用工厂类来创建对象。 在 UI 自动化中,工厂类有一个重要的作用就是提供数据的能力。 这里直接上一个例子, 在我的项目中有这样一个场景, 我们的测试都分模块的, 不同的模块有不同的 QA。 测试模型中心模块的 QA 想要测试的话就需要依赖建模 IDE 来产出各种各样的模型。 那根据上一个帖子我讲到的一个设计原则--模块间有数据依赖的时候。每个模块自己负责提供对外接口。 模型 IDE 的 QA 需要提供一个可以生产出各种不同模型的 API 来。 如下:
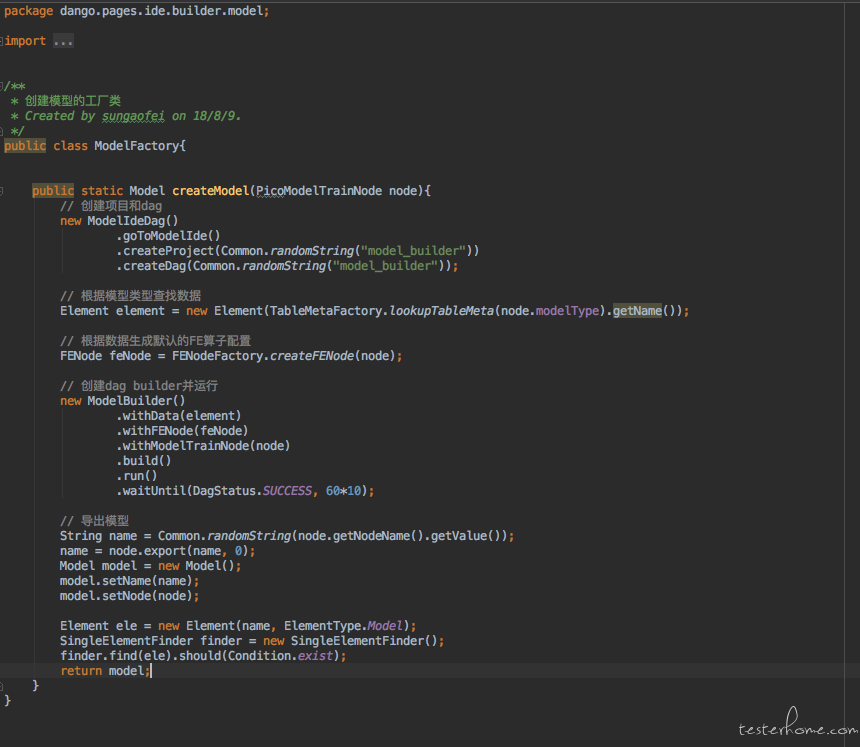
上面我们我们用一个简单工厂来实现创建各种模型。 其他模块调用此工厂方法满足自己对模型的需求。 如果我们创建模型的类型更复杂的话,可以引入工厂模式和抽象工厂模式。 但实际上我最常用的还是简单工厂,偶尔用工厂模式抽象工厂基本没用过。使用设计模式的时候最容易出现的是过度设计, 把过于复杂的模式硬搬到项目中来。 这是不可取的。
那接下来说一说这个工厂存在的意义吧。 简单工厂算是设计模式里最简单的了, 简单到它几乎不是一个什么模式。 它其实只有一种思想,就是把创建一个东西的操作都统一放到一起,调用方只需要知道我要一个东西,我需要把什么参数传递进来就可以得到这个东西。 比如我们的这个例子里,调用方只需要传递我需要一个什么类型的模型的参数。 至于如何创建这个模型它不需要知道,里面包含了多复杂的 UI 操作它也不需要知道。 这样做的好处是:
- 代码复用,我们使用工厂的来创建的东西一般都是比较复杂的,需要很多的步骤才能创建。 如果只是随便 new 一下就可以得到的对象也就犯不着专门搞个工厂方法了。 如果任由写 case 的人根据自己的想法去创建这些对象,不仅造成了很多的重复代码。 而且这些碎片的话的代码在后期的维护上也是一个难以接受的事情。
- 封装变化,我们把创建模型的所有操作都统一放在一起。之后生产模型的操作发生变化,比如需求变动。那我们只需要改动这一处就可以了。而且调用方也完全不感知
- 解耦,就如开始说的那个设计原则一样, 调用方不感知复杂的模型生产过程, 达到解耦的作用。 在 UI 自动化中,尤其是业务逻辑特别复杂的大型项目中。 多人协作有个比较重要的点在这里提一下。 就是解耦,不要让其他模块的人感知自己模块的任何实现细节。 他们了解的越少,操作的越少, 出错的概率就越小,学习成本就越小。 画地为界,分而治之。 其实我个人觉得整个设计模式就是在解决两件事情:解耦和代码复用
单例
我们有了上面的工厂方法来帮助我们创建模型, 但是这里有个问题。 就是我有太多的 case 依赖这些模型了。 如果每个 case 都执行一遍上面的操作重新创建一个模型的话会有两个问题:
- UI 操作尤其耗时,尤其是生产模型这种异步操作
- UI 本就不稳定,这些重复的操作会增加 case 失败的概率
所以我们希望除了有这种创建新模型的能力之外。 还能够复用之前已经产生的模型。 于是我们就有了使用单例模式的需求。 一般提到单例模式,基本上就是懒汉式,饿汉式什么的。 但这两种大概率都是不可用的。 因为首先我们的操作是延迟加载的,只有到了使用的时候才会去 UI 上执行创建模型的操作。 总不能直接在类加载的时候就执行吧。 至于在不加锁的情况下判断一下对象是否为 null 也是不行的。 因为现在的大规模 UI 自动化都是并发执行的。 所以可选的方案就是加锁的双重检查机制以及静态内部类了。 这里主要讲一下静态内部类吧, 双重检查机制估计大家都玩烂了。 如下:
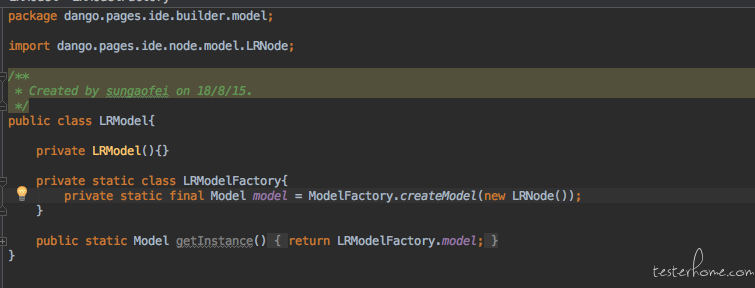
- 静态内部类不会再 LRModel 的类加载的时候就加载,而是有人调用 getInstance 的时候才会加载。所以保证了延迟加载
- java 的 classloader 会保证静态内部类的线程安全,所以不用担心并发的问题
上面是静态内部类的实现方式,优点是相较于锁的双重检查方来说实现起来简单,坑少。 比如没有那个经典的指令重排序的问题。 当然缺点也明显, 就是一旦创建对象失败, 那以后就再也没有机会重新创建对象了。 而 UI 自动化又是出了名的不稳定。 所以还是要慎重的。
模板
模板模式在 UI 自动化中比较常用的原因是在产品中有很多的操作路径是复用的。 所以我们可以使用模板模式, 把固定的路径抽象出来,由子类去实现那些独立的逻辑。 比如:
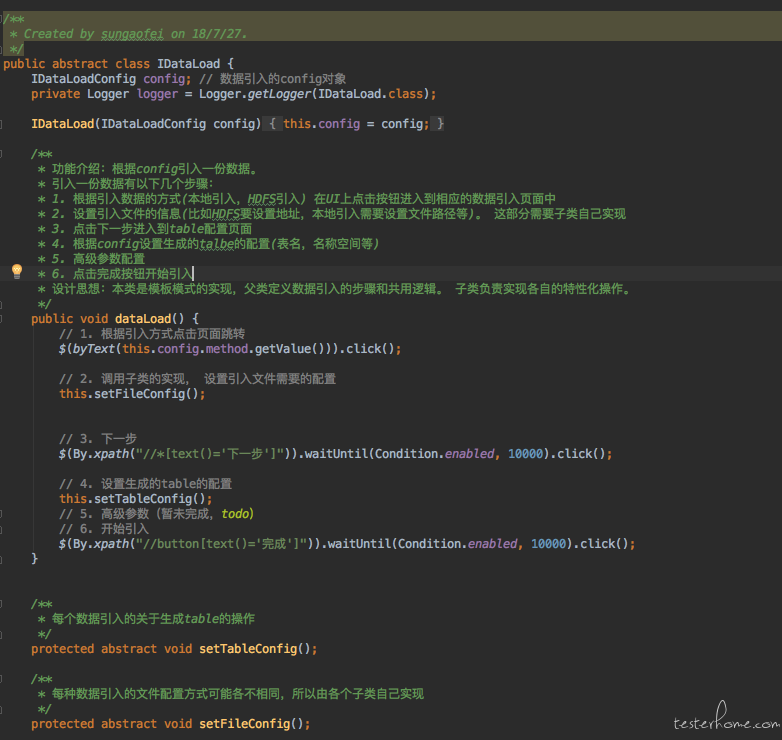
上面是我们的产品引入一份数据的逻辑。 我们的数据引入有很多种类型。 比如从本地引入, 从数据库引入,从 hdfs 引入,从 ftp 上引入等等等等。但是他们的基本步骤都是一样的 (看截图中的注释), 所以模板模式的思想是使用父类来规定到执行操作的步骤, 为了代码复用所以也会实现一些通用的步骤比如所有的引入都得点击某些 button,填写一些都行。 然后留下一些 abstract 的方法给子类实现。 这种父类规定骨架,子类实现细节的方式就是模板方法了。 在这里我们的父类定义好了所有的步骤,但是部分的具体实现细节由子类完成。 这里我们发现子类需要实现两个方法
- 每个数据引入的关于生成 table 的操作的 setTableConfig
- 每种数据引入的文件配置方式操作的 setFileConfig
当然模板方法也是可以有较深的结构的。 比如上面说的一些引入方式虽然都属于数据引入,但是也分为两大类, 一个是结构化数据,一个是图片数据。 而且凡是属于结构化数据的引入方式有很多步骤都是相同的。 凡是属于图片数据引入的方式的大部分步骤也是相同的。 所以我们继续有抽象类如下:
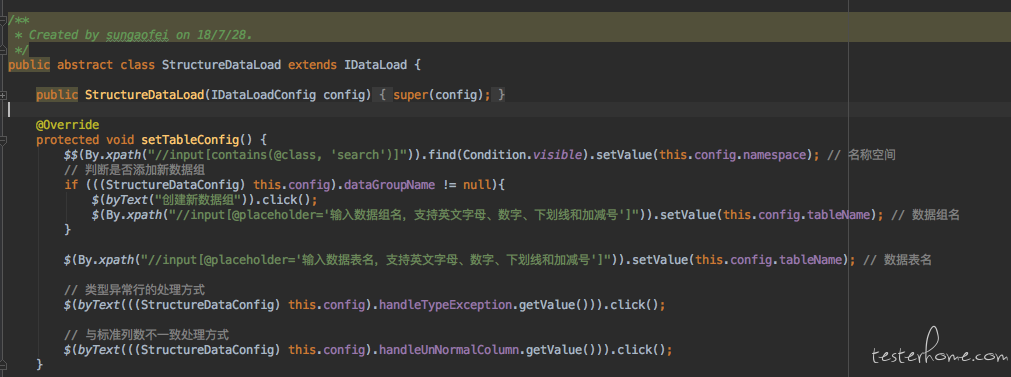
上面是结构化数据的抽象类。 他实现了父类 IDataload 的 setTableConfig 方法。 因为所有结构化数据引入的这个页面操作都是一样的。然后才是我们具体的本地文件的数据引入的类。如下。
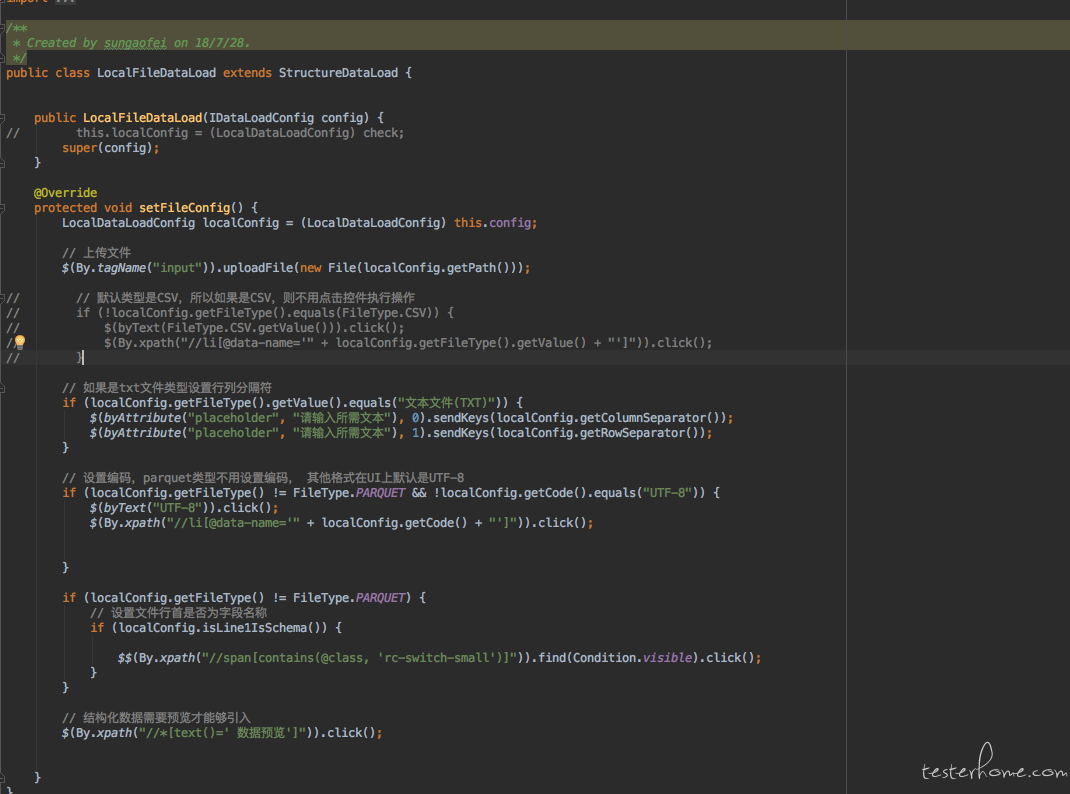
这个具体的本地文件引入的类实现了方法 setFileConfig。 这样我们就看到了这个模板模式的全貌。
- 基类 IDataload 负责定义执行步骤,以及个别 UI 操作的实现。 规定子类必须实现 setTableConfig 和 setFileConfig 这两个方法
- 类 StructureDataLoad 继承基类 IDataload,并实现了 setTableConfig 方法。 因为所有的结构化数据引入在这里使用的是同样的页面
- 具体的实现类 LocalFileDataLoad 继承 StructureDataLoad,代表着本地数据引入并实现了针对于本地文件引入所独有的页面操作 setFileConfig
所以实际上调用方要做的事情就是这样的
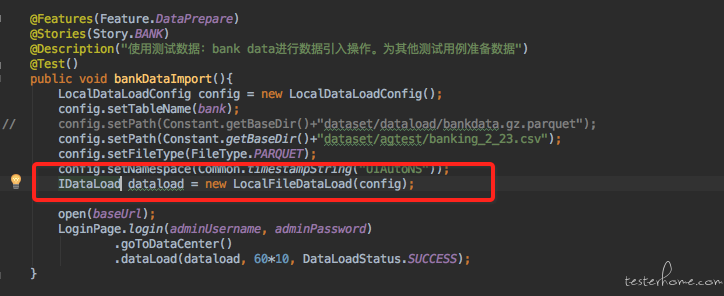
模板模式的优点:
- 代码复用, UI 上很多操作路径都是重复的,甚至说不同的业务流程操作中的部分页面使用的是相同的页面。 使用模板模式可以很好的整理我们的代码结构,将业务逻辑分类并组织起来,可以服用的代码由上层的父类实现。
模板模式的缺点:
- 如果类层级结构较多的时候,维护起来有点麻烦。
策略
策略模式也是非常常用的, 甚至很多时候它是其他模式的基础。 它的思想也特别简单。 当初它诞生的原因是为了摆脱大量的 if else, 把每个条件分支做一个策略类。 具体原理我就不介绍了,不知道的可以 google 一下,网上一堆讲设计模式的文章,我也讲不出什么花来,我就讲在 UI 自动化中我们怎么做。 举一个最简单的例子。如下:
在我们的测试中,大量的 case 都需要经过如下的操作步骤:
- 打开浏览器
- 登录
- 进入模型 IDE 页面
- 创建一个工程
- 创建一个 DAG
- 在 DAG 页面上 build 一个 DAG
- 运行 DAG 并等待运行结束
既然大量的 case 都需要执行上面的操作,那我们当然就希望能做到代码复用,所以就写了一个方法来做这个事情。 但是我们发现这些步骤中有一个操作是无法预测的。 也就是如何 Build 一个 DAG, 我们的产品的 DAG 如下
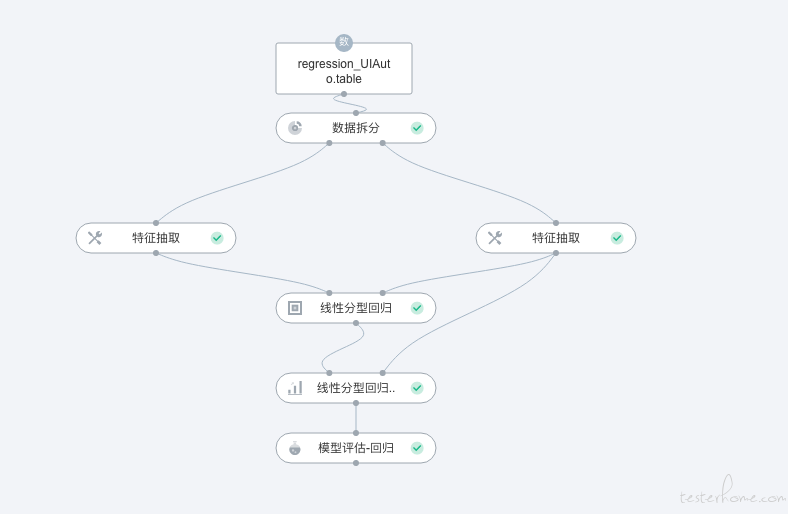
每个 DAG 中都有不同的算子组合在一起,形成一个图形。并且每个算子有它不同的配置。 要在 UI 上 build 一个 DAG 还是需要很多的操作的。 并且 case 之间要 build 的 DAG 的图形也是不一样的。 有的 case 需要 5 个算子组成一个图形, 有的 case 可能需要 10 个算子组成一个图形。 这些是完全不一样的操作, 也就是说虽然我们想写一个方法来封装上面所有的操作。但是其中构建 DAG 这一步是我们预先控制不了也复用不了的。这怎么办? 所以我们索性把 build DAG 的操作定义为一个接口。 如下:
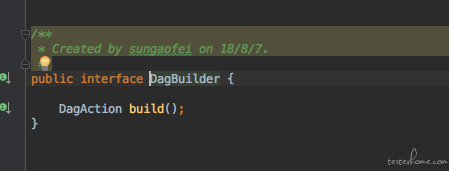
它只有一个方法,就是 build(), 意思是这个方法要实现 build 一个 DAG 的操作。 但具体 build 一个什么图形什么配置的 DAG, 由子类自己实现。
于是我们有了很多固定图形的 dag 的子类, 他们分别实现不同的固定图形的 build 操作。 如下:
于是我们创建这个可以用来复用的方法:
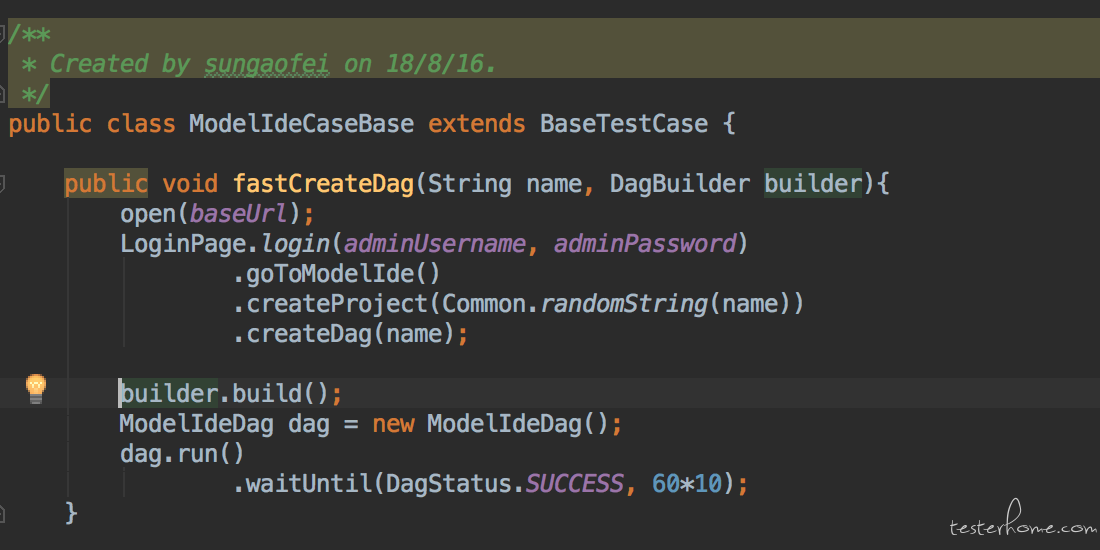
可以看到这个方法里我们执行了上面说的所有的步骤,比如打开浏览器,登录,跳转页面,创建工程等。 但是在 build 一个 dag 的时候,我们依赖一个 DagBuilder 类型的参数,也就是我们之前的定义的那个接口,当然这个 dagbuilder 使用了建造者模式,这个我们之后会讲。 现在我们在 case 中就可以很愉快的使用很少量的代码完成测试了。 如下:
当然熟悉函数式编程的同学会觉得这玩意非常眼熟。 实际上在 java8 中也完全可以使用 lamda 表达式来完成 DagBuilder 的构造
建造者
这里会涉及到建造者,策略和工厂三种模式的混合使用。可能会比较啰嗦还请大家耐心看完。
建造者模式和工厂模式都是用来创建对象的。 建造者模式适用于一个对象的内部有特别多的属性需要外部来传递的情况。 比如在上一个说策略模式的例子中。我们把 Dagbuilder 作为策略类,在 case 调用的时候动态传递一个具体的 Dagbuilder 类型决定如何 build 一个 DAG. 那么刚才我们也看到了一个 DAG 是非常复杂的,里面有不同的图形, 并且即便图形固定了, 但是里面的算子的类型和配置可能都会变化。 比如,按照上面的一个通用的模型训练的 DAG 图形, 我们就可以用下面的代码来构建。
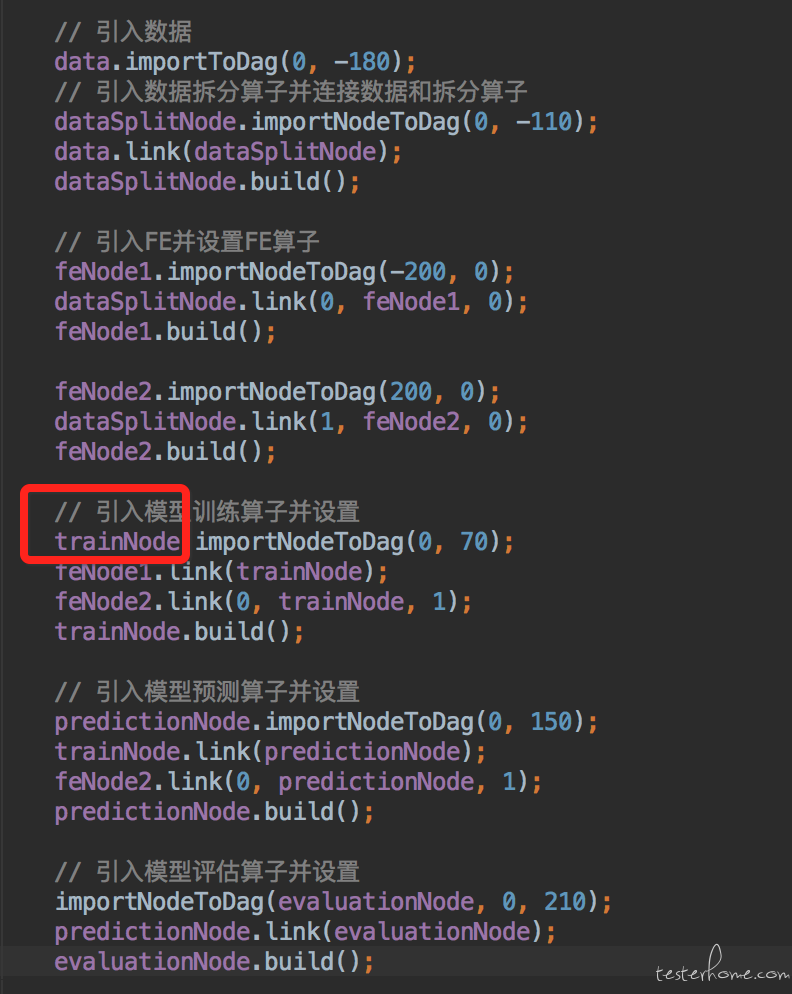
可以看到上面每个一个 node 的 importToDag 的方法中都会有两个 int 类型的数字参数。 这个意思是将算子拖拽到 DAG 中的哪一个点上。 并且 link 方法用来连接两个算子, build 方法会执行 UI 操作配置当前算子。 通过这样一段代码就可以构建出上面讲策略模式的时候,截图中的那个 DAG 图形。 我们会发现非常多的 case 都会用到这个图形。 比如测试所有的模型训练算法的时候, 都是走这个 DAG 图形的。 所以我们理所应当的会想把这个图形封装起来给很多个 case 使用。 但是虽然 case 使用的图形一样,可是每个算子的配置可能是不一样的, 而且可能在某一个节点上使用的算子都是不一样的,这需要调用方动态的传递。 所以 builder(建造者) 模式是一个包含了很多个零件的对象, 它封装了如何操作这些组件创造出最终调用方想要的东西。但是需要调用方自由的传递这些不同的零件给 builder。 首先我们看看这个 DAG 的 builder 类中定义要使用的零件。
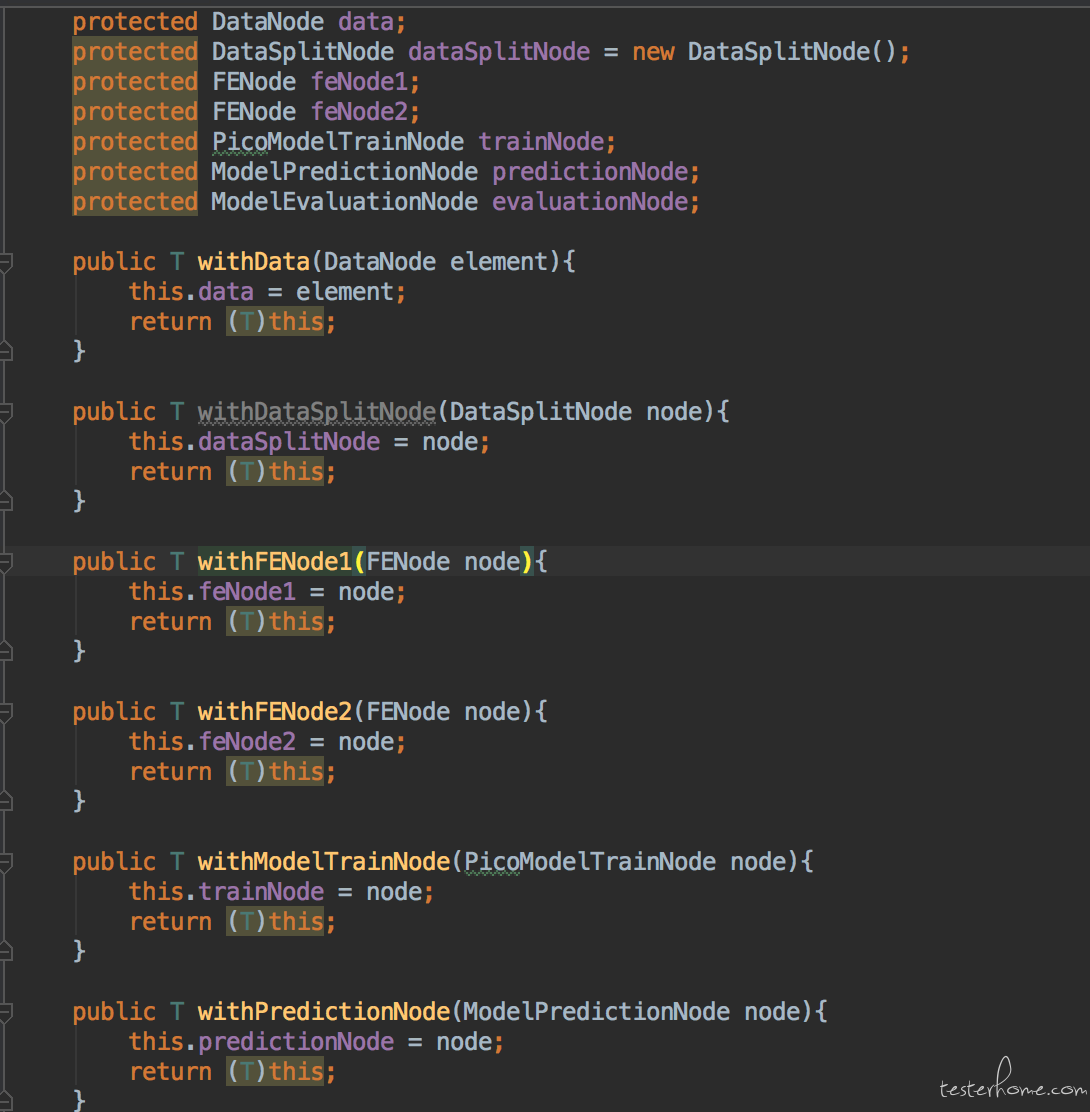
上面是我们构建这个模型训练双输入 DAG 所需要的零件。 可以看到由一个数据节点,一个数据拆分算子,两个特征抽取,一个模型训练,一个模型预测和一个模型预估组成。 而且这些零件都分别有 set 方法让调用方来设置。然后我们就可以在 builder 的 build 方法里使用本节里一开始贴出的代码来动态的构建图形了。
策略模式的混用
这里需要注意一点的是,这些零件大部分都是具体的实体类。 但是有些不是,比如模型训练算法,我们规定的是一个抽象类型。 如下:

为什么这么做呢,因为对于所有要测试模型训练的 case 来说。 图形是固定的, 某些算法也是固定的。 不论测试什么模型训练算法,都是一个数据下面连接数据拆分算法,再下面连接两个特征抽取算法。 也就是说对于模型训练算法来说,这些流程都是固定的,我们实现就知道该拉取什么样的算子,只是配置需要调用方动态传递。 但是测试的时候我们有各种不同的模型训练算法,这些可不是配置不同,而是连算子都变了, 所以我们把模型训练算法抽象成策略类。我不需要知道到底该拉取哪一个算子,让调用方动态传递就好了。 只要它传递的是我规定的策略类型,有规定的方法来设置这个算子就可以了。
工厂模式的混用
根据上面的策略模式和建造者模式的混用我们就可以比较方便的构建 DAG 图形给 case 使用了。 但是还是有一点麻烦。那就是一个 builder 需要传递的零件太多了。这个体验有点不友好。 而且我们发现在大多数的模型训练测试场景下,我们只关心模型训练算法的配置参数,而不是很在意其他算法的配置是什么样子的。 这种场景下让我一个一个的去传递这些零件还是有点麻烦。 或者说在有些情况下,我们是可以动态的推导出其他算子的配置的。 比如我这次要测试的是逻辑回归这个算子。 那么逻辑回归是一种二分类算子,那么其实它只能使用二分类的数据,特征抽取算法中只能使用二分类的 label 处理, 相应的下面也只能连接二分类算子的预测和评估算子。 这些都是我们可以动态推导出来的。 没有必要让使用者一个一个的去传递。所以我们在 builder 外面再包一层工厂, 一个创建 builder 的工厂。如下:
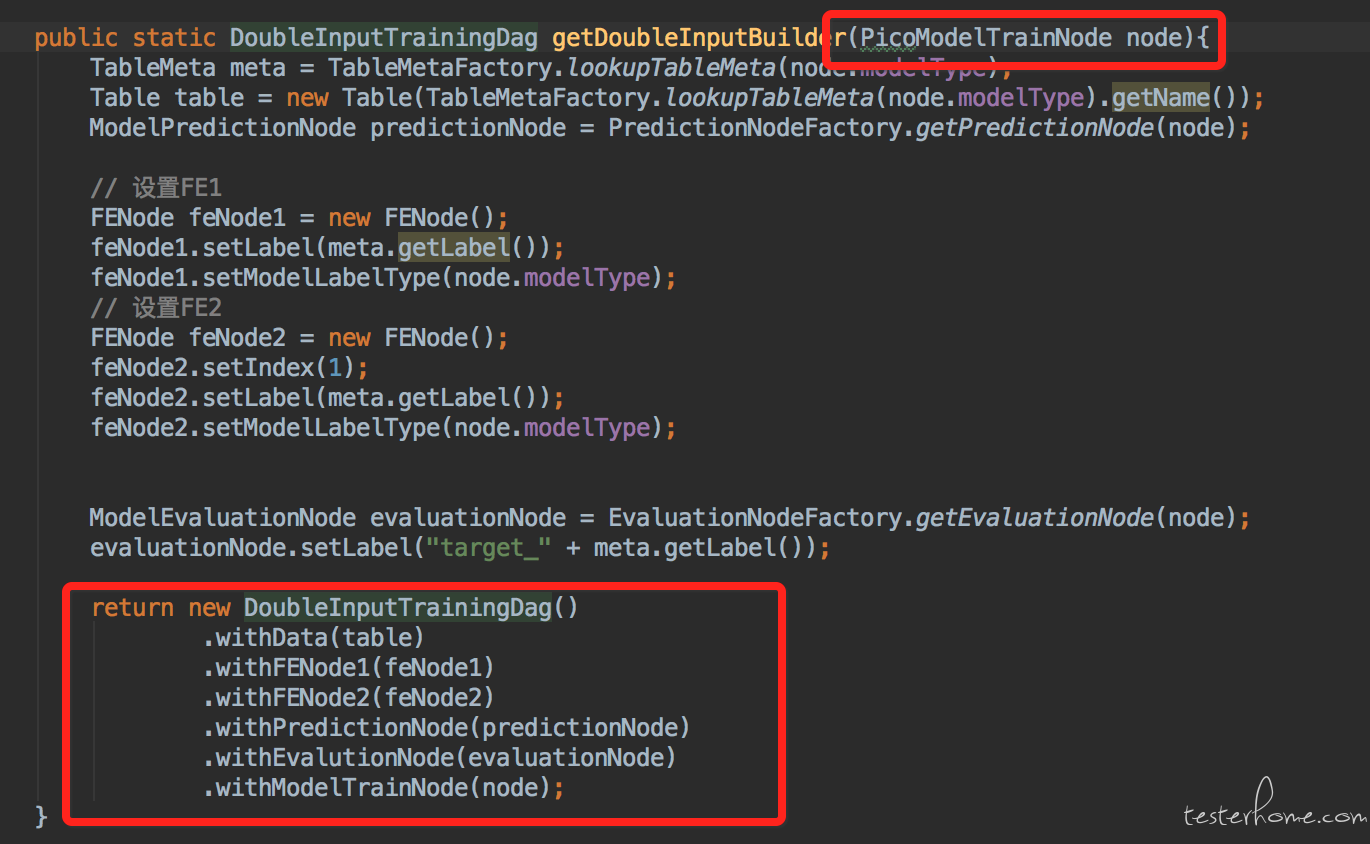
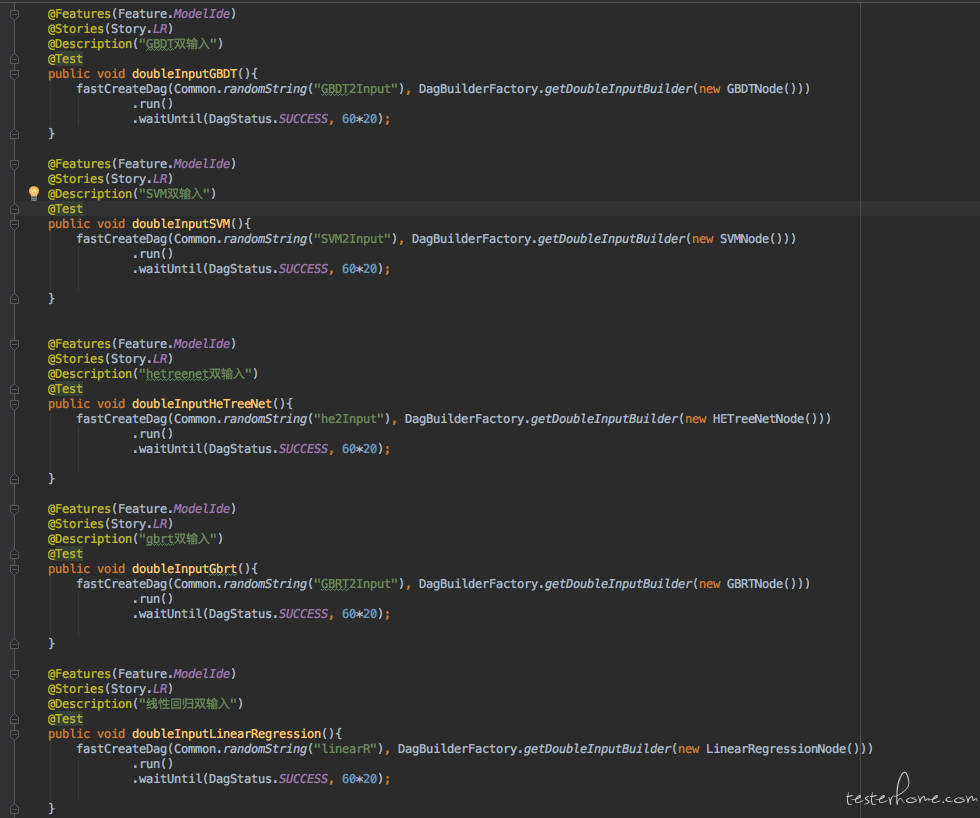
如上图,根据传递的模型训练算子的类型找到预先导入的数据,配置好特征抽取,推导出所有依赖的算子配置后。 配置好这个 builder 并返回给调用方。这样我们通过之前讲的 fastCreateDag 的策略模式的例子。 就可以在 case 中只写入非常少量的代码就完成了测试用例的编写:
@Features(Feature.ModelIde)
@Stories(Story.LR)
@Description("GBDT双输入")
@Test
public void doubleInputGBDT(){
fastCreateDag(Common.randomString("GBDT2Input"), DagBuilderFactory.getDoubleInputBuilder(new GBDTNode()))
.run()
.waitUntil(DagStatus.SUCCESS, 60*20);
}
@Features(Feature.ModelIde)
@Stories(Story.LR)
@Description("SVM双输入")
@Test
public void doubleInputSVM(){
fastCreateDag(Common.randomString("SVM2Input"), DagBuilderFactory.getDoubleInputBuilder(new SVMNode()))
.run()
.waitUntil(DagStatus.SUCCESS, 60*20);
}
@Features(Feature.ModelIde)
@Stories(Story.LR)
@Description("hetreenet双输入")
@Test
public void doubleInputHeTreeNet(){
fastCreateDag(Common.randomString("he2Input"), DagBuilderFactory.getDoubleInputBuilder(new HETreeNetNode()))
.run()
.waitUntil(DagStatus.SUCCESS, 60*20);
}
@Features(Feature.ModelIde)
@Stories(Story.LR)
@Description("gbrt双输入")
@Test
public void doubleInputGbrt(){
fastCreateDag(Common.randomString("GBRT2Input"), DagBuilderFactory.getDoubleInputBuilder(new GBRTNode()))
.run()
.waitUntil(DagStatus.SUCCESS, 60*20);
}
@Features(Feature.ModelIde)
@Stories(Story.LR)
@Description("线性回归双输入")
@Test
public void doubleInputLinearRegression(){
fastCreateDag(Common.randomString("linearR"), DagBuilderFactory.getDoubleInputBuilder(new LinearRegressionNode()))
.run()
.waitUntil(DagStatus.SUCCESS, 60*20);
}
@Features(Feature.ModelIde)
@Stories(Story.LR)
@Description("线性分型回归双输入")
@Test
public void doubleInputLFCRegression(){
fastCreateDag(Common.randomString("LFCRe"), DagBuilderFactory.getDoubleInputBuilder(new LFCRegressionNode()))
.run()
.waitUntil(DagStatus.SUCCESS, 60*20);
}
@Features(Feature.ModelIde)
@Stories(Story.LR)
@Description("逻辑回归多分类双输入")
@Test
public void doubleInputLRMultiClass(){
fastCreateDag(Common.randomString("LRMulti"), DagBuilderFactory.getDoubleInputBuilder(new LRMultiClassNode()))
.run()
.waitUntil(DagStatus.SUCCESS, 60*20);
}
可以看到上面的每一个模型训练的 case 的代码量都非常的少。
结尾
又 12 点多了今天就写到这吧。 以后有时间再继续更新设计模式相关的东西。

