-
219 个赞 / 104 条回复
-
172 个赞 / 43 条回复
-
171 个赞 / 68 条回复
-
161 个赞 / 46 条回复
-
148 个赞 / 62 条回复
-
140 个赞 / 39 条回复
-
138 个赞 / 55 条回复
-
123 个赞 / 33 条回复
-
115 个赞 / 34 条回复
-
112 个赞 / 154 条回复
-
105 个赞 / 22 条回复
-
99 个赞 / 20 条回复
-
86 个赞 / 16 条回复
-
84 个赞 / 18 条回复
-
84 个赞 / 49 条回复
-
82 个赞 / 35 条回复
-
80 个赞 / 91 条回复
-
78 个赞 / 31 条回复
-
77 个赞 / 138 条回复
-
76 个赞 / 29 条回复
-
74 个赞 / 53 条回复
-
65 个赞 / 54 条回复
-
63 个赞 / 37 条回复
-
61 个赞 / 16 条回复
-
60 个赞 / 41 条回复
-
互联网是真凉了吗 at 2026年07月07日
还有什么论坛比较火了? 感觉好像现在都挺凉的。。。。
-
有没有老哥在做大模型测试或 AI 业务相关的测试啊 at 2026年06月18日
我在社区写过科普帖:https://testerhome.com/articles/43703 大概有六万字, 你可以先看看。 详细的教程我基本都写在知识星球里了
-
从 0 开始学习 AI 测试 - 基础工具篇 at 2026年06月14日
新帖子已经出了哈
-
直播录屏 - AI 驱动 UI 自动化测试实践 at 2026年06月02日
 能落地就是好的, 能自己折腾出来就不用花钱。
能落地就是好的, 能自己折腾出来就不用花钱。 -
直播录屏 - AI 驱动 UI 自动化测试实践 at 2026年06月01日
但现阶段 AI 对测试工作的实际助力有限
不像编码这种立竿见影的效果
这两个观点我认为都是有问题的,测试人员是需要编写代码的。以前很多测试同学不写代码可能是能力不行或者被分配到了打杂的工作上,而不是不需要。现阶段 AI 对测试工作的实际助理有限, 那也可能是很多人不懂得如何用 AI。 AI 不是一个傻瓜式的工具, 它是需要很专业的知识才能驾驭的东西。 同一个 AI,不同的人用,效果完全不一样。
比如前几天《丧尸清道夫》这个 AI 短片火遍全网,甚至火到了好莱坞,连好莱坞的导员都发邮件给这个短片的作者。 这个短片我也看了,一股子爱死机的质感,质量非常高。 那问题来了,为什么只有这作者能做出来?他甚至用的只是即梦 AI,是所有人都能用的模型。就像我说的,AI 在不同的人手里,效果是不一样的。 网上有个段子说这个作者给 AI 的提示词堪比核弹说明书。想要效果好,提示词就是要这样专业和精细。 绝对不是一个玩票性质的玩家随便说几句话就可以达到的。
拿 AI 生成测试用例这一个最基础的事来说。 我自己生成测试用例的 skill,里面的提示词里的字数,保守说也数以万字了(如果把知识库都算上)。 所以想要效果好,那不是把需求文档简单往里扔就可以的。 所以如果效果不好, 是不是要先想一下,自己把 AI 想的太简单了, 或者把 AI 想的太傻瓜式了。
-
测试开发是不是已经是最没用的岗位 at 2026年06月01日
如果对于测试开发的定义就只是去写写平台,写写页面, 那确实这个岗位是拉完了。 如果对于开发人员的理解就是 crud,那开发这个岗位也确实拉完了。 所以对于一些只会 CURD 的开发人员,还有只会写写平台页面的测试开发人员来说,确实天都塌了。
但显示是,软件开发不是只有 CURD,测试开发也不是只在写平台工具。 不同的人用 AI,效果也是完全不一样的。 AI 仍然是一个需要十分专业的知识才能驾驭的东西。 它不是一个傻瓜式的工具。 大多数人都觉得用 AI 去做事情就好像跟豆包对话一样随意。 那他们根本感受不到 AI 的威力。 只是在听说 AI 能怎样怎样
-
直播录屏 - AI 驱动 UI 自动化测试实践 at 2026年06月01日
是全部了, 直播就 2 个小时。 都在这个链接里
-
AI 写测试用例的疑问 at 2026年05月29日
需要搭建知识库,你需要让模型了解你的产品,知道你希望的设计测试用例的方法论。 这些我再以前的教程,也在我得星球里写过。 比如:
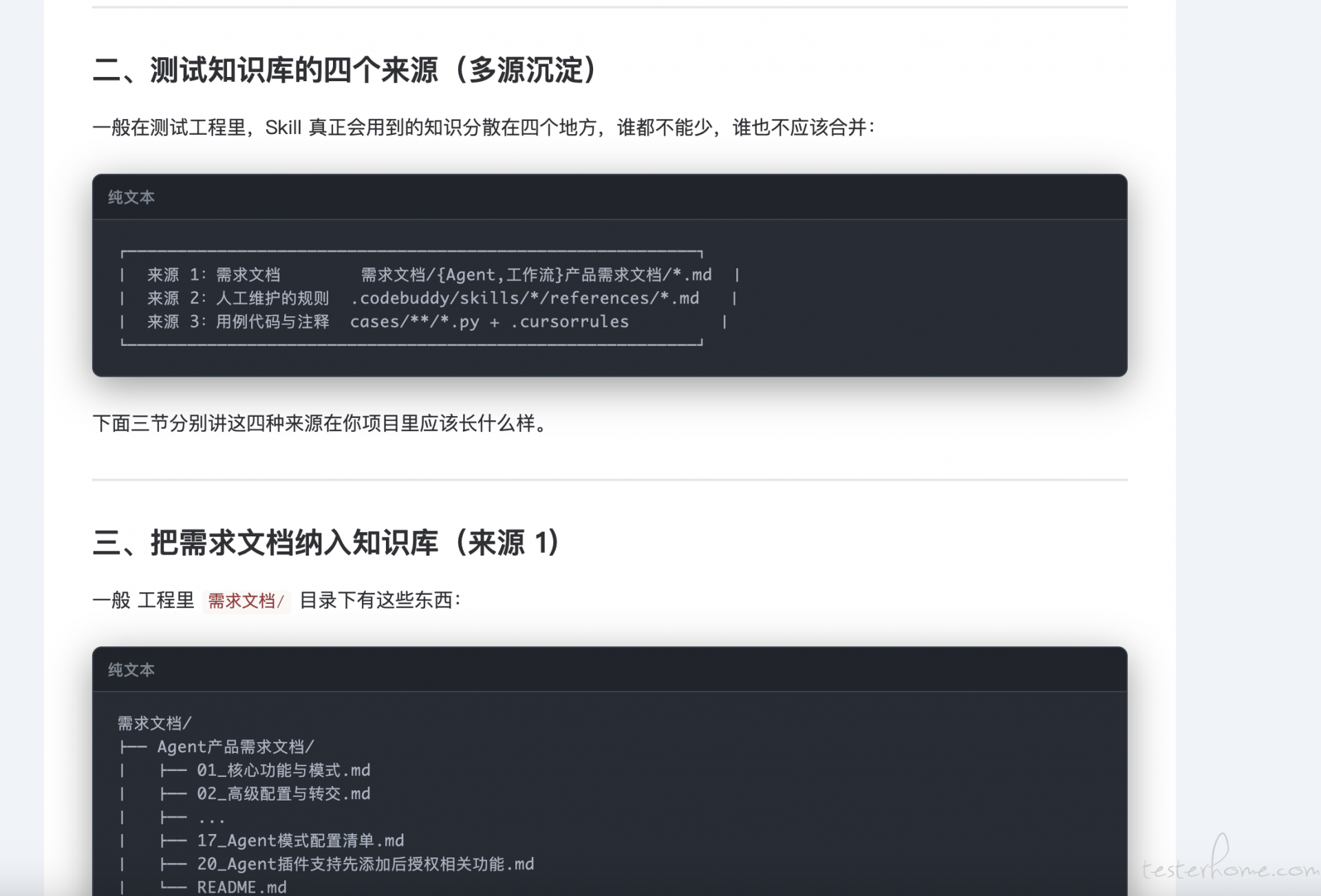
-
coding plan 都按 token 量收费了,成本飙升,还适合让 AI 做自动化测试吗? at 2026年05月26日
多学习一些 Skill 的设计方法, 会有一些节省 token 的方案的。 我现在也开始尝试牺牲一些准确率来节省 token 的尝试。
-
AI 时代下测试人员要如何转型 at 2026年05月22日
我大概明白了, 你的诉求应该是自然语言转接口自动化测试用例。 这个需要你事先把接口录入给大模型,让他生成访问的代码。 或者有接口的详细调用文档。 要 AI 去写代码,还是必须要有知识库的。 这样你就可以用自然语言的测试用例转成自动化测试代码了。