-
设计一个多 Agent 的 UI 自动化测试工程(一)基础原理 at 2026年07月22日
个人选择~ 用哪个都一样的
-
从 0 开始学习 AI 测试 - 从接口测试来教你如何用 AI 来生成自动化测试代码 at 2026年07月21日
如果是经常用的,很多 case 都复用的。 那就把很多个接口串联过程做一个 service 的公共方法
-
Midscene 视觉定位与交互机制深度解析 at 2026年07月21日
只有图片烧 token,AI 不参与分析 DOM 树,它只推算坐标。 开了缓存, 我一个月也就几十块钱
-
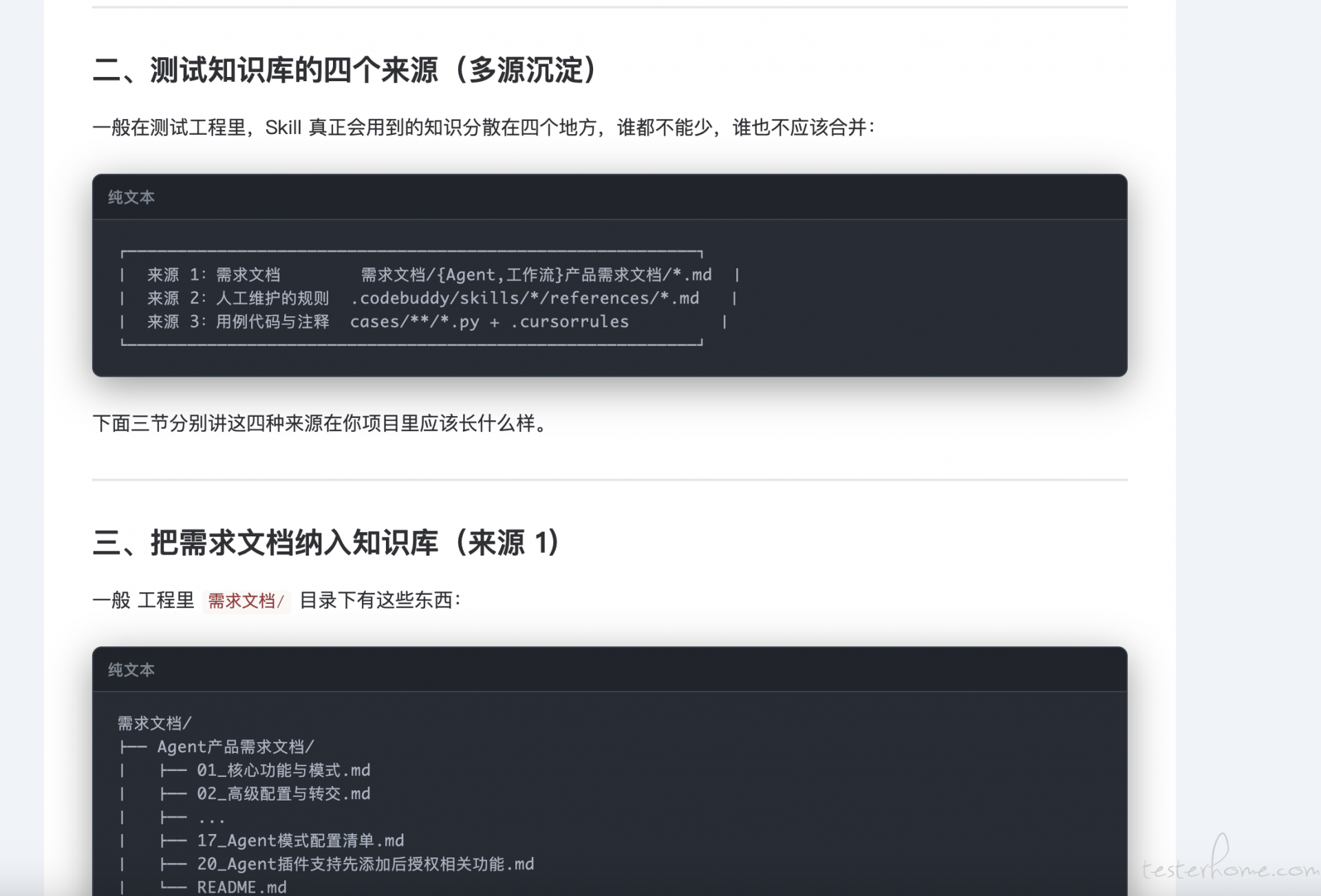
周六直播预告 - 从需求生成测试用例的 SKILL 设计思路(主要是知识库设计) at 2026年07月20日
有的哈,
录制: 从需求生成测试用例的 SKILL 设计思路(主要是知识库设计)
日期: 2026-07-04 19:32:40
录制文件:https://meeting.tencent.com/crm/Kz8Go7Q8bb -
互联网是真凉了吗 at 2026年07月07日
还有什么论坛比较火了? 感觉好像现在都挺凉的。。。。
-
有没有老哥在做大模型测试或 AI 业务相关的测试啊 at 2026年06月18日
我在社区写过科普帖:https://testerhome.com/articles/43703 大概有六万字, 你可以先看看。 详细的教程我基本都写在知识星球里了
-
从 0 开始学习 AI 测试 - 基础工具篇 at 2026年06月14日
新帖子已经出了哈
-
直播录屏 - AI 驱动 UI 自动化测试实践 at 2026年06月02日
 能落地就是好的, 能自己折腾出来就不用花钱。
能落地就是好的, 能自己折腾出来就不用花钱。 -
直播录屏 - AI 驱动 UI 自动化测试实践 at 2026年06月01日
但现阶段 AI 对测试工作的实际助力有限
不像编码这种立竿见影的效果
这两个观点我认为都是有问题的,测试人员是需要编写代码的。以前很多测试同学不写代码可能是能力不行或者被分配到了打杂的工作上,而不是不需要。现阶段 AI 对测试工作的实际助理有限, 那也可能是很多人不懂得如何用 AI。 AI 不是一个傻瓜式的工具, 它是需要很专业的知识才能驾驭的东西。 同一个 AI,不同的人用,效果完全不一样。
比如前几天《丧尸清道夫》这个 AI 短片火遍全网,甚至火到了好莱坞,连好莱坞的导员都发邮件给这个短片的作者。 这个短片我也看了,一股子爱死机的质感,质量非常高。 那问题来了,为什么只有这作者能做出来?他甚至用的只是即梦 AI,是所有人都能用的模型。就像我说的,AI 在不同的人手里,效果是不一样的。 网上有个段子说这个作者给 AI 的提示词堪比核弹说明书。想要效果好,提示词就是要这样专业和精细。 绝对不是一个玩票性质的玩家随便说几句话就可以达到的。
拿 AI 生成测试用例这一个最基础的事来说。 我自己生成测试用例的 skill,里面的提示词里的字数,保守说也数以万字了(如果把知识库都算上)。 所以想要效果好,那不是把需求文档简单往里扔就可以的。 所以如果效果不好, 是不是要先想一下,自己把 AI 想的太简单了, 或者把 AI 想的太傻瓜式了。
-
测试开发是不是已经是最没用的岗位 at 2026年06月01日
如果对于测试开发的定义就只是去写写平台,写写页面, 那确实这个岗位是拉完了。 如果对于开发人员的理解就是 crud,那开发这个岗位也确实拉完了。 所以对于一些只会 CURD 的开发人员,还有只会写写平台页面的测试开发人员来说,确实天都塌了。
但显示是,软件开发不是只有 CURD,测试开发也不是只在写平台工具。 不同的人用 AI,效果也是完全不一样的。 AI 仍然是一个需要十分专业的知识才能驾驭的东西。 它不是一个傻瓜式的工具。 大多数人都觉得用 AI 去做事情就好像跟豆包对话一样随意。 那他们根本感受不到 AI 的威力。 只是在听说 AI 能怎样怎样
-
直播录屏 - AI 驱动 UI 自动化测试实践 at 2026年06月01日
是全部了, 直播就 2 个小时。 都在这个链接里
-
AI 写测试用例的疑问 at 2026年05月29日
需要搭建知识库,你需要让模型了解你的产品,知道你希望的设计测试用例的方法论。 这些我再以前的教程,也在我得星球里写过。 比如:
-
coding plan 都按 token 量收费了,成本飙升,还适合让 AI 做自动化测试吗? at 2026年05月26日
多学习一些 Skill 的设计方法, 会有一些节省 token 的方案的。 我现在也开始尝试牺牲一些准确率来节省 token 的尝试。
-
AI 时代下测试人员要如何转型 at 2026年05月22日
我大概明白了, 你的诉求应该是自然语言转接口自动化测试用例。 这个需要你事先把接口录入给大模型,让他生成访问的代码。 或者有接口的详细调用文档。 要 AI 去写代码,还是必须要有知识库的。 这样你就可以用自然语言的测试用例转成自动化测试代码了。
-
AI 时代下测试人员要如何转型 at 2026年05月22日
没看懂, 你这是要做什么?
-
AI 时代下测试人员要如何转型 at 2026年05月22日
手动测试的时候怎么造的数据, 就让 AI 怎么造
-
AI 时代下测试人员要如何转型 at 2026年05月21日
当前项目中所有的代码和文档,默认都会 embedding 并且保存到向量数据库中。 所以大模型每次运行其实都会去参考已有的文档和代码,这样它就能明白, 你说的用例步骤,其实在其他 case 里写过类似的并进行参考。 这也是为什么我一直说 知识库 是 AI 编程最重要的东西。 那什么是知识库? 在你工程里一切的代码和文档都可以是知识库。
-
AI 时代下测试人员要如何转型 at 2026年05月19日
各种专项测试的工作流其实很有价值的,我现在性能测试和高可用测试都用 Agent 来执行
-
各位大佬,目前研发 ai 提效很高,代码产出指数级上升,测试压力很大 at 2026年05月19日
首先用例和需求肯定是要积累成一些文档的, 然后生成 case 的方法论和产品测试要点也要有。 再然后你可以搜一下 harness 的设计方法论, 这个方法论是能让 Agent 稳定高效运行的方法论,按这个思路去设计。如果你觉得 harness 太耗时或者太废 token, 那你也可以单纯遵循 “渐进式披露” 原则, 先写一个生成 case 的 skill 出来试试看。 你可以搜一下我提到的这几个设计方法。
-
各位大佬,目前研发 ai 提效很高,代码产出指数级上升,测试压力很大 at 2026年05月19日
想要 AI 效果好,知识库必须要好好积累。 这个知识库不仅仅是业务功能文档,还有设计测试用例的方法论和你的产品的测试特点。 比如在我们的产品里,如果模型广场里新增了模型,或者动了模型的逻辑。 那需要遍历到整个产品里所有跟模型有关的功能点。 所以在我的知识库里,专门有个文档是记录所有与模型相关的功能点,并在 skill 里告诉大模型,在这种情况下一定要遍历这里的所有模型相关的功能点。 而如果是涉及到前端的逻辑,知识库里也写好了各个模块的前端交互的流程,并且在 skill 里写了工作流, 就是识别到跟前端有关的操作。 要反复向用户确定是否有 figma 的交互稿,如果没有,设计到的输入框是否有字符数的限制等问题。
同一个模型, 不同的人用的效果天差地别,就在于使用的 “人” 是否有耐心,愿意去学习如何跟 AI 打交道。
-
各位大佬,目前研发 ai 提效很高,代码产出指数级上升,测试压力很大 at 2026年05月16日
开发人员用 AI 编写代码带来的最大的问题就是质量会更差。起码现阶段是这样的,很多开发同学还不得的用 Harness 的理念去设计 Agent,所以导致出错的概率比较大。所以呢,我们为了解决这个问题需要利用 AI 来去快速地生成大量的自动化测试用例。我们现在公有云的门禁的运行时间,就需要跑 5 个小时了。这是大量的自动化测试用例积累的结果。基本上这个门禁能跑下来。产品的质量问题就不会很大了。
-
各位大佬,目前研发 ai 提效很高,代码产出指数级上升,测试压力很大 at 2026年05月16日
有些时候,一些不起眼的地方,提升起效率来也挺夸张的。你比如说测试用例的编写,用传统的方式去写测试用例,花的时间很长。我们假设要编写 100 条测试用例。如果说要编写的相对比较详细一些,那么这 100 条测试用例的编写工作可能就会耗费一天时间,甚至更长。但用 AI 来去写的话,可能就是 10 分钟之内的事情。即便说你没有很好的知识库,让它自动探索出很好的用例。但我们就用人力来去编写测试点,然后让 AI 去生成更详细的步骤。这也是效率的一个很大的提升。
-
各位大佬,目前研发 ai 提效很高,代码产出指数级上升,测试压力很大 at 2026年05月16日
我比较赞同这位兄弟的看法,我们目前也是一使用 AI 快速搭建接口和 UI 的自动化。同时使用 AI 来完成各种专项,比如容灾测试、性能测试。还有一些其他的提升效率的比较散的地方。比如利用 AI 的总结能力去快速地理解需求文档,利用 AI 的能力快速完成一个调研行动。很多时候,来了一个任务没有什么特别好的思路,问问 AI 可能很快就能够把这个任务完成。我这里的更多的呢是在接到一些新的需求的时候,里面会涉及到一些我不懂的知识。尤其我在做这种技术型产品的时候,经常会遇到这种问题。用 AI 呢,我就能很快地去学习了解这方面的知识,并且拿到一个很好的解决方案来进行测试。 总结一下,就是多利用 AI 的能力来寻找方案。
-
AI 驱动 UI 自动化的完整 DEOM 工程 at 2026年05月15日
AI 定位控件的时候,可以开缓存, 缓存存在本地。 只要定位过一次, 下一次就不用 AI 了。 也可以先用 css 定位再用 AI 兜底。 至于用 AI 去编写 case 的成本。 可以用差一点的模型, 或者精简一下 skill。
-
AI 驱动 UI 自动化的完整 DEOM 工程 at 2026年05月15日
就写 sql 执行就好了, AI 是用来写 case 和定位控件的