背景
最近很荣幸能参加饿了么和 tester home 社区合作举办的线下测试沙龙。 感谢大家对我的信任,让我有机会分享一些我再工作中的实践。由于最近一有时间就准备 PPT 和演讲稿。所以一直也没有继续更新关于 spark 的帖子了。 之后我会慢慢的恢复连载,不过我滴儿子要出生了哈哈 (狂笑中),可能未来要停刊一段时间了。现在我把之前为线下分享准备的演讲稿整理一下。分享给社区的小伙伴。里面有我这次分享的全部内容。也包含了一些我演讲中没有说出来的东西。 第一次演讲,有些紧张,好几段都没讲出来哈哈。
===================分割线,以下是演讲稿内容=================
自我介绍
大家好,我叫孙高飞,是自第四范式的测试开发工程师。由于工作的关系,最近一年都在研究一些容器技术。最近两年,容器技术非常火,随之而来的 devops 也流行了起来。运维开发这个职位也火了一把。那容器技术已经慢慢开始普及的今天,对我们测试人员有什么变革性的影响呢。今天我就想跟大家聊一聊 docker 在我们公司的测试环境中扮演了怎样的角色。

大家看到这个图了,这是 docker 公司在互联网上用 799 美元找人设计的 logo。 Docker 自己是这样说鲸鱼的:The logo is a Whale carrying a stack of containers. It is on its way to deliver those to you.它托着许多集装箱。我们可以把宿主机可当做这只鲸鱼,把相互隔离的容器可看成集装箱,每个集装箱中都包含自己的应用程序。鲸鱼或许代表着创始人 Solomon Hykes 眼中的互联网愿景,就像 20 世纪 50 年代集装箱颠覆了全球物资运输方式一样,它将会颠覆信息运输方式,让货物在互联网的火车、汽车、轮船之间畅通无阻。
这个跟我们今天的主题也很像。docker 就是这个鲸鱼,它有能力承载着我们庞大的测试环境。
困境
首先我们介绍一下背景,从我们曾经面临了哪些问题讲起,慢慢的介绍为什么我们的 docker 方案会是现在的这个样子。
- 环境搭建困难:我们的产品是一个机器学习的平台级产品,它提供了很多复杂的能力。例如说模型调研,模型上线,自学习,自监控,资源伸缩以及用户可二次开发等种种不同的能力。这样一个系统注定是很复杂的,模块众多,我们在 git 上有 30 多个 repo。涉及了多种不同的编程语言,例如我们的机器学习算法是 C++ 写的, 业务层是 java,大数据处理使用的是 scala,服务发现相关使用的是 go 语言,前端使用 reactJS,监控模块是 python。每个模块每种语言都有不同的编译和部署方式。 所以部署这样一个复杂的系统是十分困难的。因为大家都是只熟悉自己开发的模块。没有任何人有能力搭建一整套产品环境。并且每一个模块都有不同的编译时和运行时依赖。即便我们把整个编译部署过程自动化。但是在我们添加新的测试环境的时候仍然很困难。因为编译和运行时依赖很难构建。
- 环境不一致:环境没有何部署规范性,没有标准化。每个环境都是不一样的,很多人都上去搞,你不知道最后环境被搞成了什么样子。很容易出现开发环境没问题,测试环境或者生产环境出问题。
- 多人共用一套环境:由于搭建环境比较困难所以我们的环境并不多。一个环境都是多人共享。互相踩踏问题很严重。经常这边正在测试呢,那边重启了某一个服务。效率很低下
- 测试机器稀缺,资源紧张:这个大家应该都遇到过,假如我做 UI 自动化测试,case 太多,任务也太多,我们想分布式执行。框架都已经搭好了,却发现没那么多机器给你用。用例执行的还是很慢。
解决方案
我们的工作效率很低。我们在测试环境上投入了很多精力但并没有显著的提高效率。所以我们急需一套测试环境的管理方案,起码提供以下三个能力:
- 自动化:一键部署。
- 标准化:开发,测试,生产环境保持一致。
- 集群化:为什么说要集群化呢,因为在以往的经验中,测试环境是一种稀缺资源。假如说有一个测试任务要执行,我是不能随便使用测试环境的,要走流程去申请。我再老东家的时候,甚至有一段时间协调测试机器是需要靠吼的,我想用就在群里吼一声,别人如果也在用就也吼一声告诉我不能用,跟他冲突了。所以我们吼完了也走完流程之后,已经花掉很多时间了。效率很低,究其原因是因为我们的测试环境的数量不够多。除了测试人员以外,开发要环境联调自测,产品要稳定的环境演示,调研。有限的测试环境逼的我们去制定流程来协商测试环境的归属权问题。 多人共用一套环境的情况很常见。这就出现了我刚才说的互相踩踏的问题。就像我说的,测试环境是稀缺资源。而我们现在希望测试环境能扩展到一定的量级,让它从稀缺资源变成一个人人可简单获取的普遍性的基础资源。而集群化能很好的帮助我们做到这一点,因为容器技术的出现以及现在任何开源的分布式框架都提供了良好的资源调度策略,能最大化的利用服务器的资源。
Docker
docker 有很多的优势,要详细说明要很多时间,我就列一下我们主要关注的几点。
- 节省资源:我们知道容器技术节省资源就在于它并不是一个完整的操作系统,所有的容器都是共享主机内核的。你可以理解为它直接将主机的 rootfs 挂载到容器内。这是为什么我们能支持那么多套测试环境的原因之一。
- 用完既删:容器的启动和删除都是极其简单快速的,秒级启动和秒级删除。这样我们可以使用一种模式,就是那些并不需要持续提供服务的容器可以在使用完就删除掉,等到再使用的时候现场启动就好。 举个例子,我们可以并发 N 个编译容器完成任务立即就可以销毁。而虚拟机的方案需要一直存在若干台编译机提供服务。这也是 docker 节省资源的一个原因
- 迁移方便:java 圈有一句话叫一次编译到处执行。那 docker 圈里也有类似的一句话。镜像一次制作,到处执行。所以你可以随意的删除和扩展我们的测试环境。而且这些环境绝对是标准化的。他们没有任何不同。 我们可以很简单的把环境从一台机器迁移到另一台上。也可以很快速的从 10 个环境扩展到 100 个。
- swarm,kubernetes,Mesos 多个成熟的开源分布式管理框架任君选择。
- 简化运维成本。 举个例子:我们的产品使用 mariadb,而我这个不知道几手的运维在当时根本不知道怎么搭一个 mariadb 出来。所以干脆从 docker hub 上下载一个官方镜像直接启动,整个过程不超过 5 分钟。 搭建 testlink 的时候也一样,下载 mysql 和 testlink 镜像以后,配置一下就可以用了。可以说 docker 生态圈的出现让普通的 QA 也能 own 整个的测试环境管理成为了可能。
我们用 docker 做什么
- 日常测试环境: 这是最主要的容器。我们把测试环境都放在容器里。
- 基础服务:testlink,jira,wiki,jenkins 等基础设施
- 测试执行环境:就拿我刚才说的 UI 自动化的例子,我们想分布式执行用例来提高运行速度。但我们以往并没有足够的机器来做这件事。那现在我分别下载了 grid-hub 和 chrome-node 的镜像。启动多个测试节点还是很容易的。像我刚才说的,docker 比虚拟机要节省很多的资源。所以我们能够比以前启动更多的测试节点。
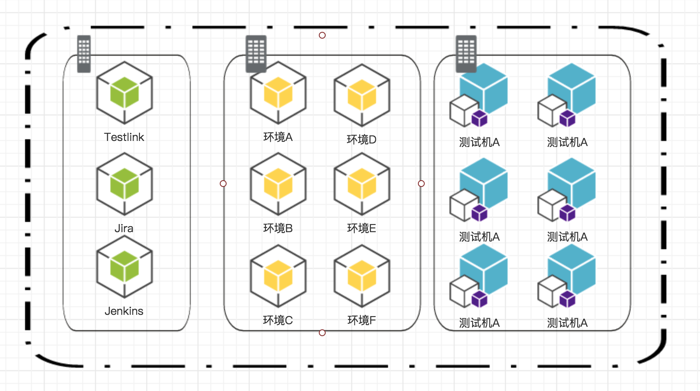
就如上面的图一样,我们把所有我们想要的服务都放到容器里。 也一如一开始我们说的那个 logo。 docker 这条鲸鱼承载着很多的集装箱,集装箱里就是我们的服务。 那么我们的问题来了,我们如何跟这些集装箱中的服务通信呢? 我们知道容器并不是虚拟机,我们不能像以前一样做了。所以我们先介绍一下网络的玩法。
网络的玩法
端口映射
我们先说端口映射。容器并不是真正的机器,我们在外部与容器通信通常都是通过端口映射来解决的 --- 将容器的端口映射到宿主机上,这样外部可以通过宿主机 ip+ 端口的方式与容器通信。请看下图
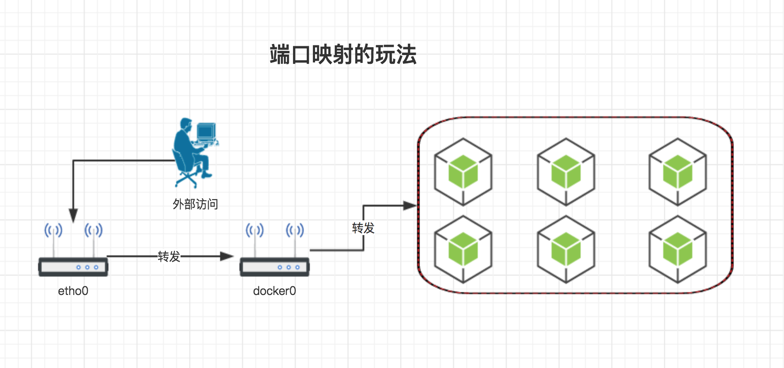
细心的朋友可能在玩 docker 的时候就发现了安装 docker 的时候默认会创建一个叫 docker0 的虚拟网桥。而且 iptables 里面多了很多条规则。 实际上 docker 的网络就是在玩 iptables,尤其玩的是 NAT 这张表。当你使用 ip+port 的模式访问的时候,iptables 就会把你发的报文拆开并使用 DNAT 修改你的目标地址,转发到 docker0 上。然后 docker0 才会转发到容器上。 实际上 docker 的前三种网络模式:host,briage,container 玩的都是这种转发规则。这种方式的优点有两个:1. 使用简单,docker 默认的网络玩法就是这样的。2.安全,因为外部是没办法随意的访问容器的。docker 给所有容器分配的 ip 都是虚拟 ip,只能在一个节点的所有容器内部使用。
那这时候我们就有一个问题了,通过端口映射的方式很不方便。一个测试环境往往要对外暴露很多接口。例如我们做测试要访问 mysql,那就得把 3306 端口映射到宿主机的某一个端口上。要访问 web 服务可能要暴露 80 端口,为了能 ssh 到容器中又得暴露个 22 端口。而且你 ssh 的时候还得手动指定端口号了。也就是说一套环境你要记住好几个端口号。 总之就是很麻烦。如果我们能够像访问虚拟机一样访问容器就好了。只需要记住一个 ip 就可以。 所以就衍生出了下面固定 IP 的玩法
固定 ip
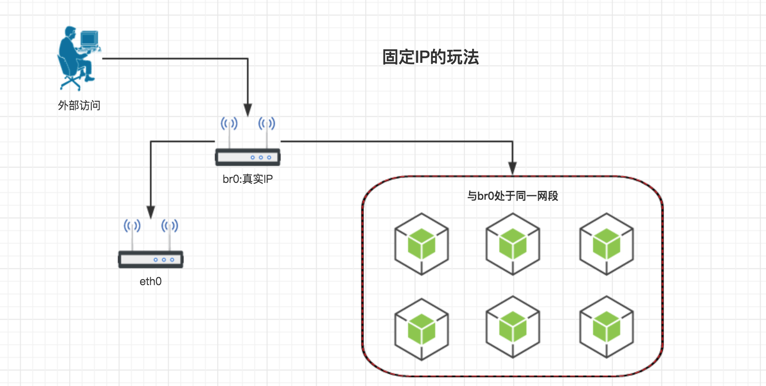
首先我们不用 docker0 了,删掉它。 在宿主机上创建一个新的 br0 的这么一个网桥,然后把宿主机的网卡指到这个网桥上,为网桥分配 ip。 修改 docker 的网桥配置,指定网桥为我们新建的 br0. 再修改 docker 启动容器的时候分配的 ip 地址段的配置,分配真实的,跟宿主机处在同一个网段上的 ip 地址范围。 这样,我们再启动每一个容器的时候,容器就会被分配到一个真实的可被路由规则的 ip 地址。 我们实现了可以外部登录容器的需求。 但是还有一个问题。这种模式是依赖 docker 的 briage 模式的。每次启动容器分配的 ip 是不可控的。那么下面要解决让我们自己设定固定 ip 的问题。 docker 的最后一种网络模型为 none,就是没有网络。 我们启动容器的时候指定 none 模式。 然后使用第三方的 pipework 工具给容器分配固定 ip。 这样,我们就好像是在使用虚拟机一样的在使用容器了。
固定域名
那这个模式看上去好像已经很完美了。 但是它还是有一个缺点的。 因为你要求的是固定 ip。所以你必然要维护一个 ip 列表。如果其他人启动容器的时候跟你的 ip 地址冲突的话,是很难能查出来的。其实你用虚拟机也会碰到问题。 那这时候怎么办? 我跟我的同事讨论的之后,觉得可以继续使用 briage 模式,由 docker 自己分配 ip。这样就不会冲突了。但是我们做一些手脚。 我们把 DHCP 和 DNS 跟 docker 打通。在启动容器的时候 DHCP 会分配 IP 地址的同时也会到 DNS 上注册一个跟容器名称一样的域名。这样,我们可以通过域名访问容器了。 不用维护 ip 列表,不用死记 IP 地址也不必担心 ip 冲突了。
缺点
后面两个模式当然也是有缺点的。这些容器都是暴露在真实的网络里的。也就是说它们和都处于一个广播域内,它们和我们真实的机器也是一个广播域内。 如果我们的容器变多的话,容易引起广播风暴。 同样如果我们的 docker 宿主机比较多,那再每台机器配置网桥,划分网段也是很麻烦的。 所以这种玩法不适合规模比较大的环境的。
测试环境的玩法
OK,搞定了网络以后,我们聊聊最关心的环境部署问题。 我们最初的模式是下面这样的
container 模式
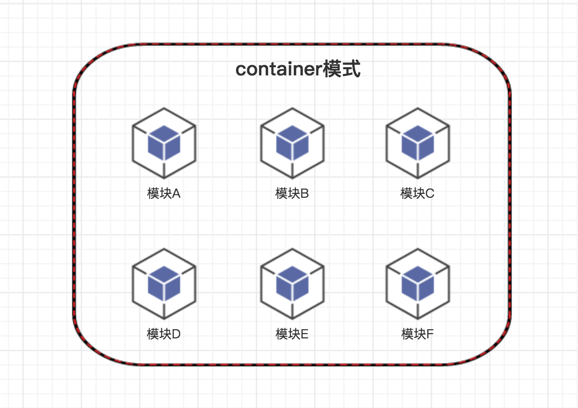
这是我们最开始的模式,也是效率最高的模式。 开发人员很喜欢。 这个模式有以下 3 个优点
- 充分利用了 docker 的 container 网络模型,把所有的容器都绑定到一个 ip 上。方便配置管理。因为配置管理中心里统一写 localhost 就好了。
- 编译容器也是部署容器,直接在同一个容器内编译 + 部署。免除了打包操作节省时间的同时保留了编译环境。 开发人员很容易在容器内开发和实验
- 并发编译部署,速度快
这种模式是开发人员最喜欢的。但是有优点当然也就有缺点。缺点也很纠结:
- 标准化问题:我们并没有微服务架构。所以我们的生产环境并不是这样部署的。所以会有环境不一致问题
- container 模式破坏了 ssh。 因为一个 ip 多个容器共享。所以 ssh 登录变成了问题。
- 长时间存活的容器多。
打包模式
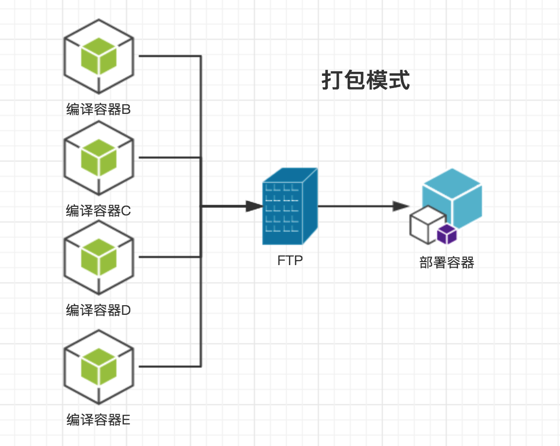
这个就有点像我们经常做的模式了。 首先并发 N 个容器编译并上传到 FTP 服务器上。 然后删除编译容器启动部署容器拉包部署。 这个图里后面不是说就所有东西都在一个容器里部署。 我的意思是就按生产环境标准部署。 每家公司的都不一样。所以我就画一个容器在这上面了。
当然这套有优点也有缺点:
优点:
- 环境标准化
- 所有编译容器走 host 模式,不占 ip。任务结束就 kill。省资源
缺点:
- 跟第一种模式比起来,慢很多
- 没有编译环境,开发不爽。
测试机器的玩法
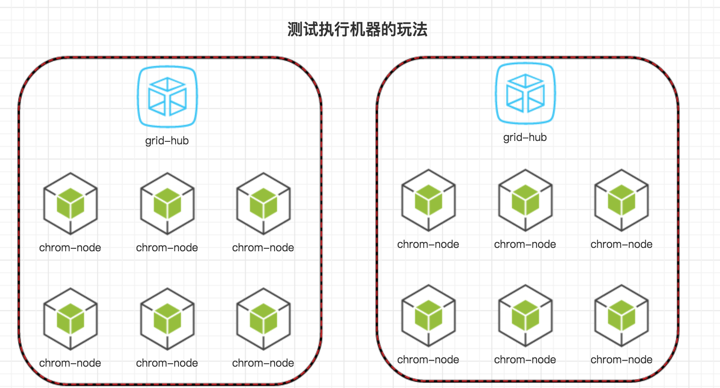
我刚才说过一些这方面的事。 就以 UI 自动化为例。 下载 grid-hup 和各个浏览器的 Node 的镜像。我们可以很轻松的组建分布式执行用例的环境。平时这些容器都是不启动的。任务过来的时候统一启动这些容器,由于都是 docker 镜像,秒级启动。测试结束后统一 kill 掉。
存储的玩法
在我们能够把服务放到容器中后就会考虑一些问题,我们的数据如何持久化出来。 例如如果容器不小心被删除了,那里面的数据怎么办?所以我们需要一些方式保存我们的数据
外部存储
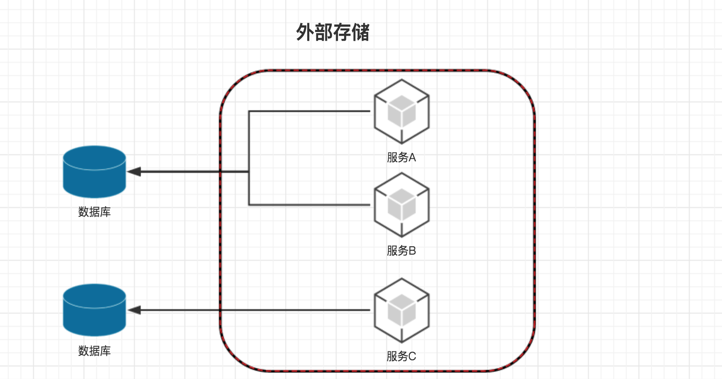
把数据库这样的存储设备放在 docker 外面。自然就不需要担心容器被人删除了。 一切就跟虚拟机时代一样
volumes
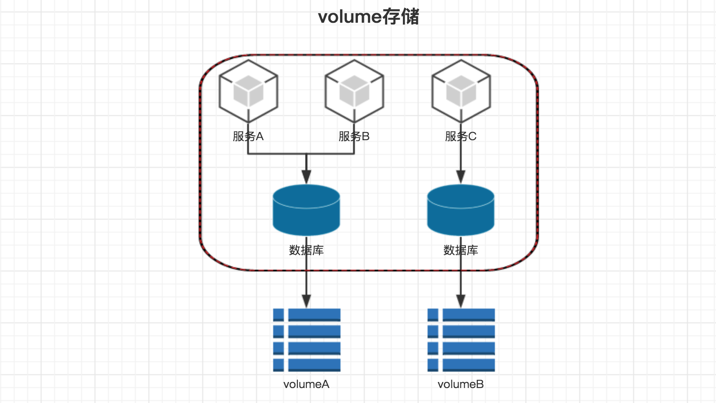
通过数据卷将数据挂载到文件系统中。可以是宿主机的文件系统。也可以是 NFS 这种网络文件系统。docker 支持很多种类型的数据卷。
集群
当我们的测试环境越来越多的时候,必然会遇到一台服务器无法支撑的情况。所以我们扩展成 2 台,3 台甚至更多。 这时候集群化会显的比较有必要。统一接口管理,合理的资源调度。开源的监控工具等等都为我们的日常管理提供了便利。下面我先跟大家简单的介绍下容器界的 3 位大咖。
- 最先火起来的集群管理框架,其实它并不是专门为 docker 设计的,只不过在 docker 火起来以后它就兼容了 docker。 它本身只关注集群资源,你可以通过安装各种 framework 来实现第二阶段的调度。例如现在 mesos 上最火的 marathon。它是目前 3 种框架中最复杂的一个,我觉得它并不适合 QA 来使用。
- kubernetes:k8s 现在的发展趋势颇有些业界领导的意思。他是 google 大名鼎鼎的分布式集群管理项目 Brog 的开源版本。本来 k8s 才应该是复杂度最高的框架,但是 google 很聪明。在保持自由度的同时 k8s 也借鉴了 swarm mode 的设计模式。虽然无法像 swarm 一样完全的傻瓜式。但是 kubeadm 和 kubectl 等客户端工具已经极大的简化了我们的日常工作。同时 google 本身推出了容器化部署方案,有很多官方镜像来支持 k8s 设置各种服务。所以使 k8s 的使用变的简单了起来。
- swarm: docker 内置的集群管理框架。无需安装任何额外的东西。 这个东西用一个词概括就是简单。这玩意简单到你都不信它是集群管理框架。以服务发现来说,Mesos 要装 MesosDNS, k8s 要装 kubeDNS。 以跨节点容器互联来说,Mesos 和 k8s 都需要额外的网络插件。虽然 google 都提供了 k8s 的各种服务的镜像,安装起来都不难。 但是 swarm 连让你多输一个命令都不需要。一个 swarm init 解决所有问题。虽然 k8s 的 kubeadm 一直再模仿 swarm。但是它仍然需要是额外安装一些东西的。 swarm 简单归简单,但是它失去了自由度,例如你只能用它提供的 overlay 网络,overlay 网络的性能不好但你又没办法换别的。它在集群中的概念就是 service。不像 k8s 提供了 pod,deployment,service 等概念。没有很好的集群管理和监控方案等等。
k8s 简介
其实最一开始的时候我们使用的是 swarm,因为够简单。 但是由于我们的 SaaS 环境也开始集群化并使用了 k8s。 为了统一技术栈,并且也考虑到 k8s 比 swarm 确实强大很多。所以就在前些日子开始迁移 k8s 上。k8s 的概念比较多,限于时间不能详细说明了。我先介绍一下最基本的几个概念,以方面我开始讨论。
- pod:pod 是 k8s 最小的控制单元,它可以由一个容器或者多个容器组成。是一个逻辑概念。在一个 pod 中除了有我们的容器以外,还有一个 Pouse 容器。所有的容器都共享这个 Pouse 容器的网络和 volume,就好像我们在单机模式的时候用的 container 模式一样。这样这个 pod 中的所有容器就可以互相通信了。
- deployment:deployment 的前身是 replica Controler。意思是定义了一种部署状态,这个部署可以有很多个 replica,也就是分片。 这些分片就是 pod。用人话说就是 deployment 由多组相同的 pods 组成。设置了多少分片,就有多少个 pod。deployment 会维护这些 pod。当有 pod 因为意外挂掉的时候,deployment 会负责重新创建起来。 也就是说 deployment 提供了高可用服务
- service:pod 和 deployment 都是在 k8s 内部运行的,它们是无法对外提供服务的。 所以 service 扮演了对外提供的服务。同样的也可以由多个相同的 pod 组成,并且 service 自动提供负载均衡的能力,把请求分到这些 pod 中。
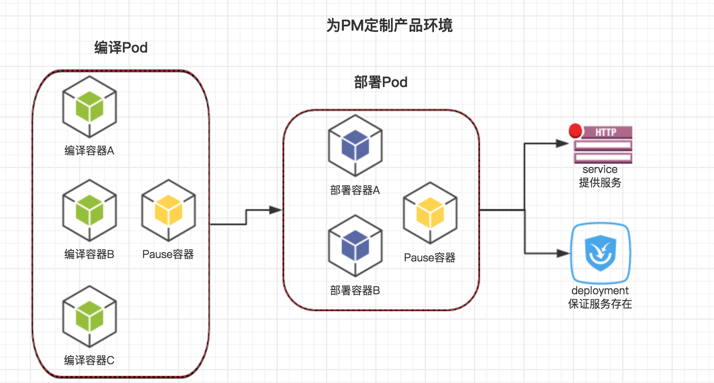
上图就是一个我们为 PM 定制环境的方案。我们公司的业务比较独特,我们是 TO B 的模式。所以线上并没有最近的环境。 有些时候 PM 要跟客户和领导演示我们的产品。这些演示都是很重要的。所以环境绝对不能出问题。这个环境要是稳定的,没有 bug 的。 但我们都知道我们的测试服务器是比较容易出事的。因为好多人都在上面乱搞。 所以我们才有了上面这个图。使用 pod 编译,部署。 但是用 deployment 设置几组 pod 共同提供服务。当有一个 pod 挂掉后,deployment 会自动监控到并请求调度系统重新创建一个新的 pod 使用。 而 service 则提供负载均衡的能力。在这几个 pod 中分发请求。如果一个 pod 挂了。它就给另外的 pod 发请求。这样就组成了我们高可用的需求。
集群服务
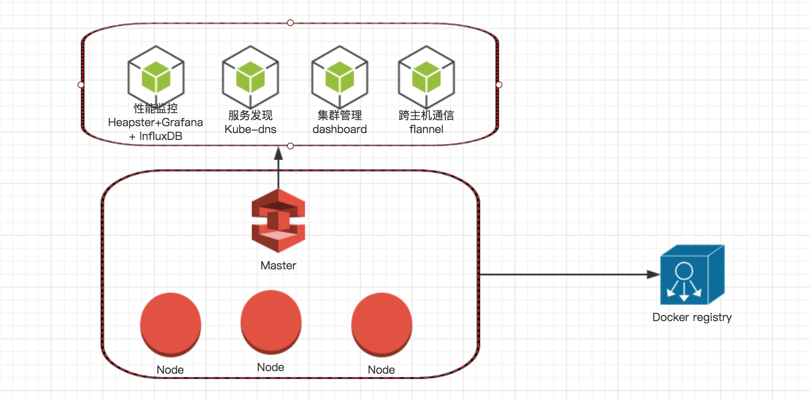
为了能够管理集群,我们需要安装一些服务。好在 google 推行了容器化部署。所以这些服务都是有官方镜像的。只要我们下载下来直接使用就好了。下面我们分别来介绍一下吧。
- 跨主机通信:我们一开始就说过 docker 给容器分配的 ip 都是虚拟 ip,只能在一个节点中的所有容器中使用。那再集群中我们如何让不同的节点中的容器互相通信呢。这时候我们就需要 flannel。除了 flannel 你可以安装自己想要的网络插件。例如我用的是 weave。
- 服务发现:我们的容器不仅仅是虚拟 ip,每一次的启动的 ip 地址还会变化。所以我们在配置的时候怎么办呢? 最好是有个 DNS 来为我们的服务注册域名。我们只要记住域名就可以了。 所以我们要安装一个 kube-DNS
- 集群管理:我们目前所有的集群管理操作都是用的命令行,如果有一个 web 服务能让我们管理所有的 pod,监控资源。观看日志就方便多了。所以我们要安装 kube-dashboard
- 容器级监控:为了管理集群,我们不仅要能监控每个节点的性能,还要监控每个容器的性能消耗来辅助性能测试。 所以我们要安装 Heapster + influxDB + Grafana 来做更专业的性能监控。
- 镜像仓库:为了能在所有节点共享镜像。我们需要搭建一个镜像仓库来让每个节点都能拉取最新的镜像
所以我们有了以下的架构图
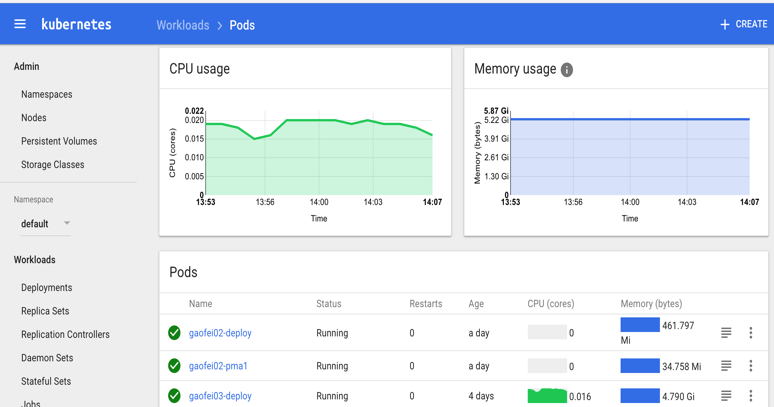
我们再看看 dashboard 的管理页面
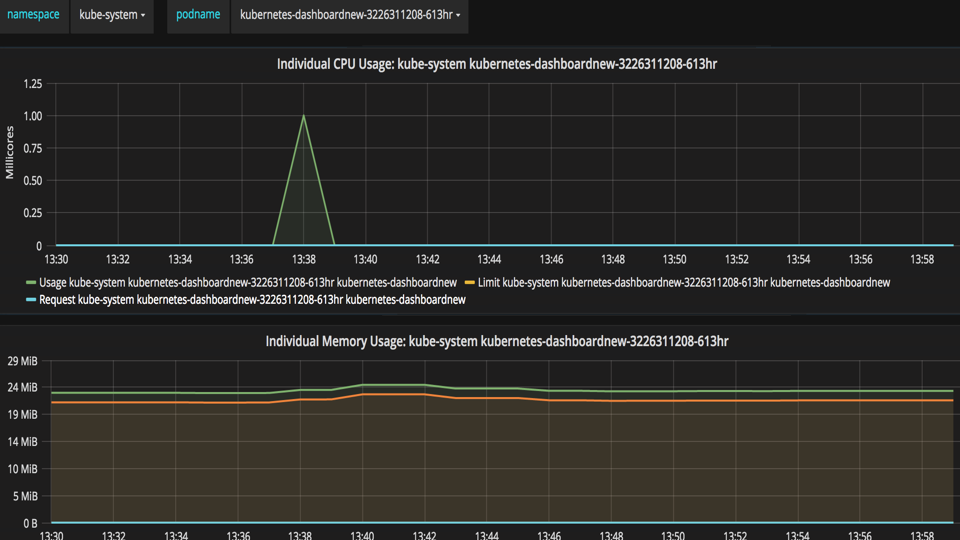
我们再看看 Heapster + influxDB + Grafana 的性能监控页面
尾声
今天由于时间的限制呢,我们可能没办法将太多了。所以我做个总结吧,我觉得器技术的蓬勃发展不仅是给了 devops 用武之地,让运维开发这个职业火了起来。同时对于测试行业来说也是个机会。因为它无形中的为我们打破了很多技术壁垒。如果换做以前,我是绝对做不到今天讲的这些东西的。所以我建议没接触过 docker 的同学可以去学习一下。后续我也会写一个关于 docker 和 k8s 的系列教程连载在 testerhome 上。今天就先到这里吧。
