前言
有段时间没碰过 UI 自动化的东西了。 最近出了新产品要搞 UI 自动化,所以又开始把以前的东西捡回来。 在这里分享一下我们使用的 UI 自动化设计军规。
PS: 此军规是在 java 1.8 的背景下设计的
总体规则
所有模块设计均遵循 page object 结构

- 用例层:测试人员编写测试用例代码的地方,可以调用 page 层和封装层。
- page 层:一个页面一个类,包含该页面的业务逻辑封装以及部分控件定义。
- 封装层:根据业务需要,封装常用的业务逻辑 (相比于 page 层的业务逻辑封装,它的范围更广,有些时候是跨页面的业务逻辑。 属于模块级的业务封装)
页面设计规则
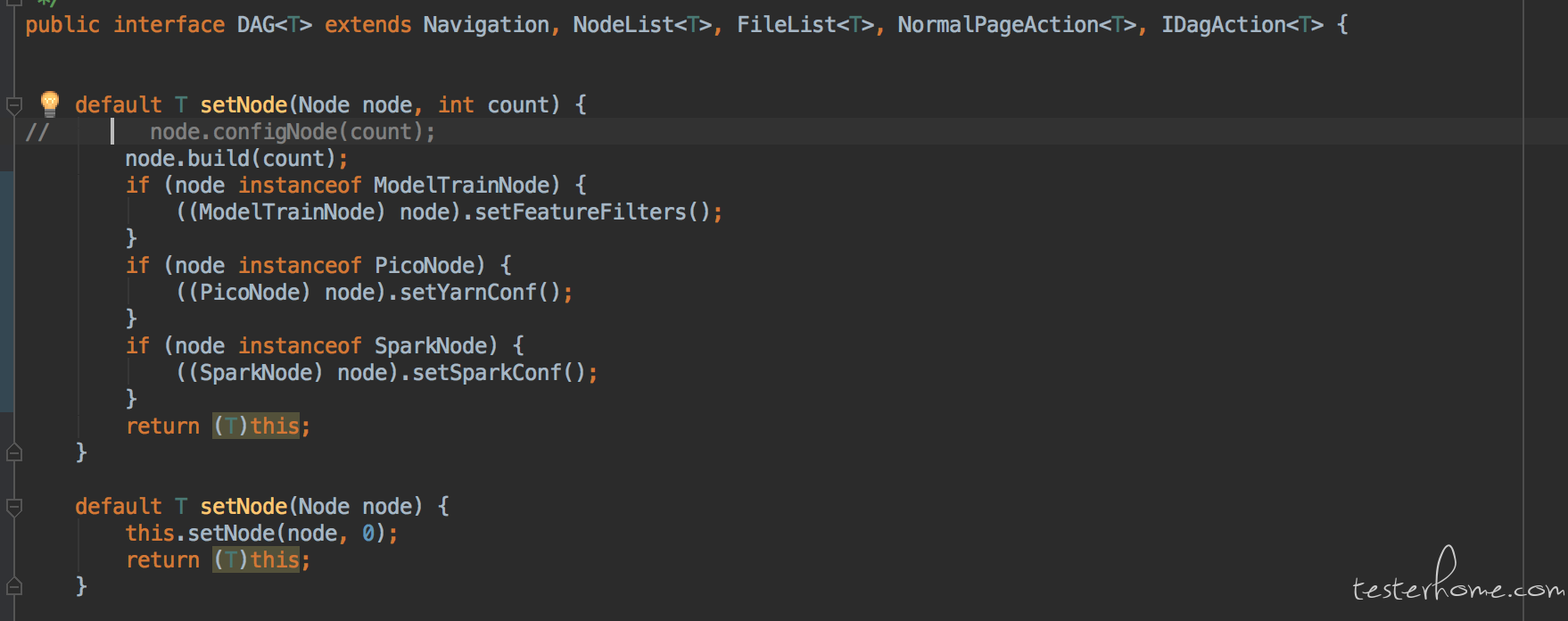
所有导航,页面辅助以及会跨越多个页面的逻辑均涉及为接口,接口中定义默认实现。
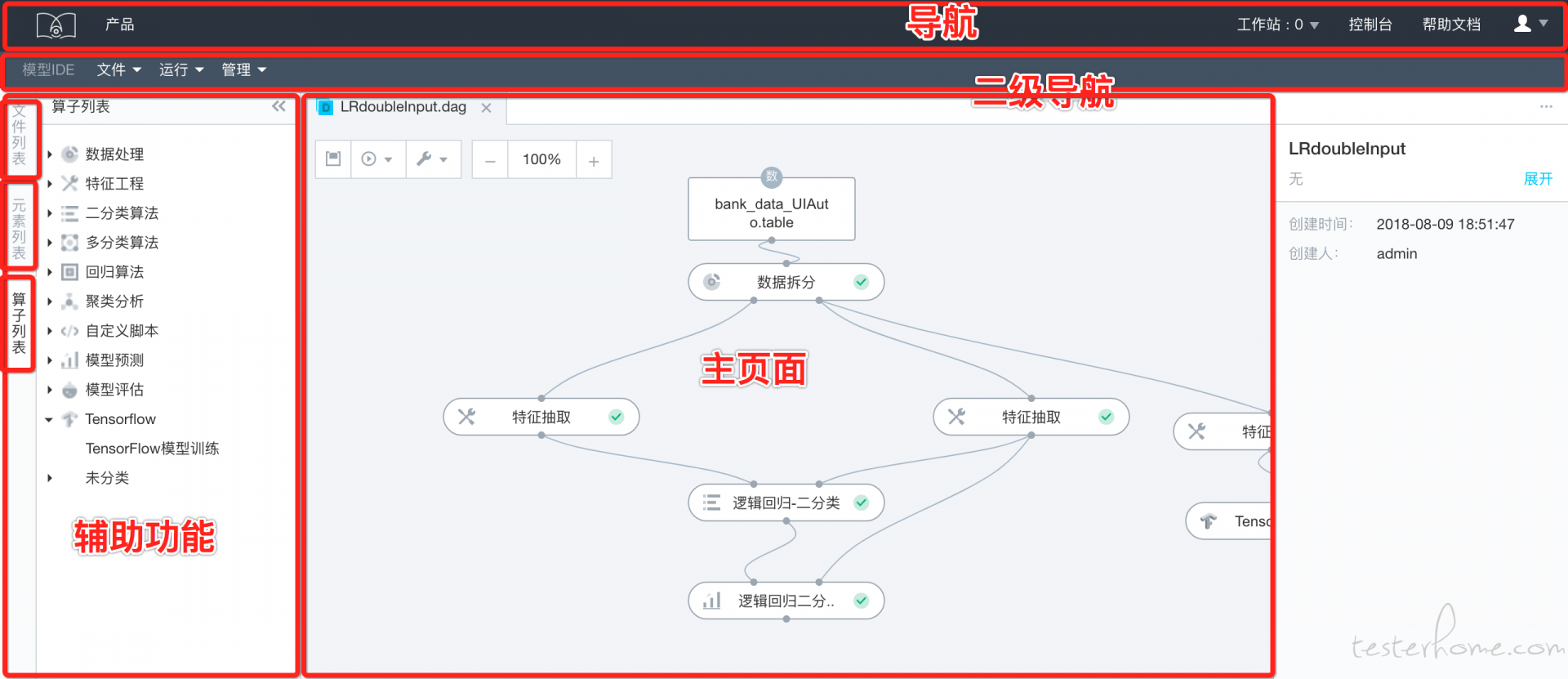
如上图的导航,二级导航以及页面辅助功能都会在不同的主页面上出现。 一级导航为几乎所有页面都会用到, 二级导航为该模块下所有页面会用到。 页面辅助功能为不同的页面会用到不同的页面辅助功能。比如 DAG 页面会使用元素列表和算子列表。 但是 notebook 文件只使用元素列表。 基于此种特性, 我们将这些功能设计为接口并提供默认实现。哪个页面需要用到就去 implement。以此来达到代码复用的目的。例如:
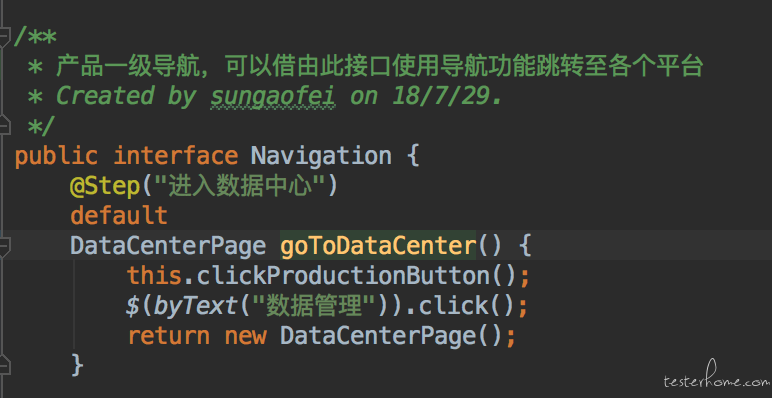
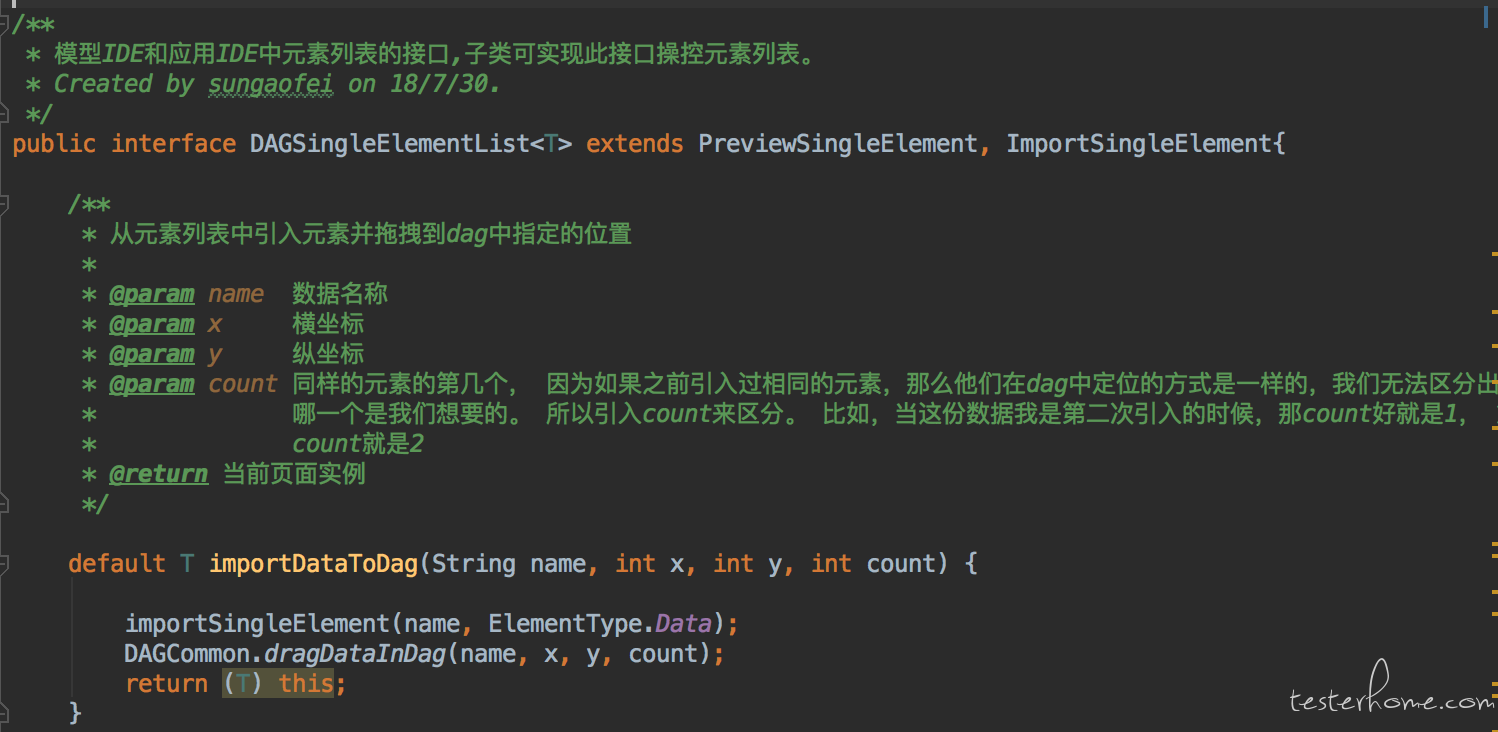
由于 jdk 1.8 的接口有 default 实现的功能。所以需要用到相应功能的子类直接实现接口以继承相应的能力。 这也是为什么选择用 jdk1.8 的主要原因。
每个 page 类只负责自己页面的逻辑
page 类遵循一个原则---- 产品 UI 上这个页面能做什么, 这个 page 类就只能做什么。 不准许跨页面逻辑合并在一个类中实现 (页面可以有跨页面和模块级功能,但是具体每个页面的逻辑必须由每个页面自己实现)。 出现多个页面共用的功能参考上一条规则将其实现为接口。
页面类的类名以 Page 为结尾。 接口 (共用逻辑) 不得使用 Page 结尾
页面较多的时候用来区分页面和共用逻辑的规则
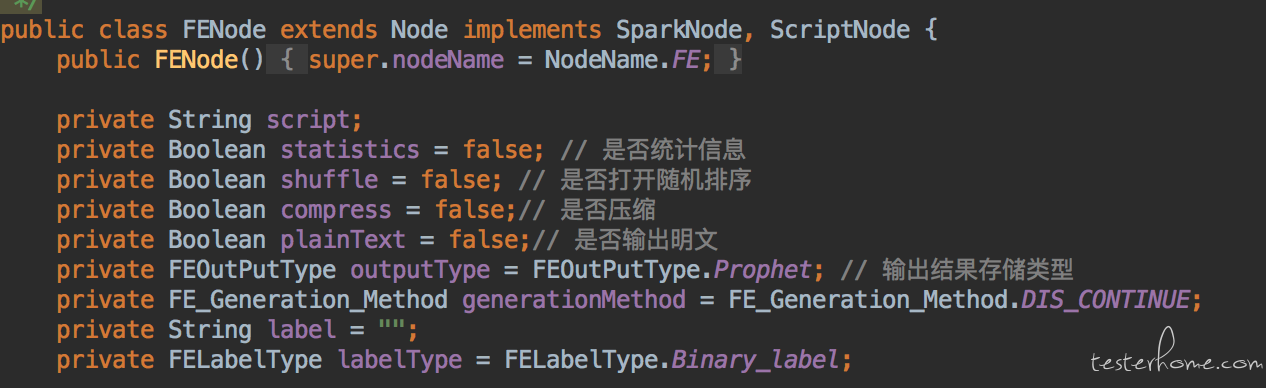
每个页面以封装业务逻辑为主,通过参数控制调用不同的业务逻辑。 无特殊情况下不要让外界知道控件的信息。
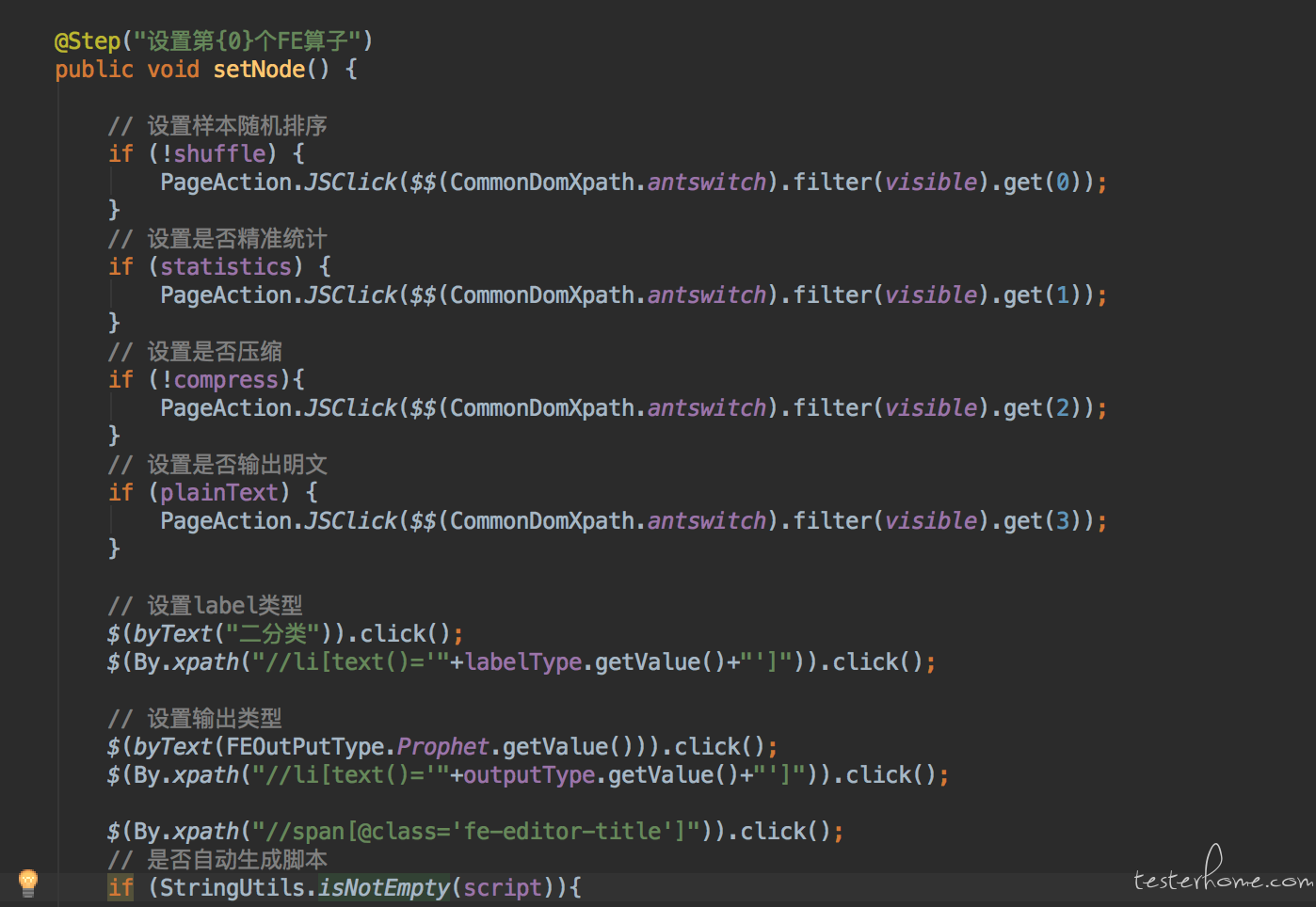
如上图,这是一个设置 FE 算子的逻辑,其他任何页面或者测试用例都通过此逻辑来设置 FE 算子。外界不感知任何控件信息。 如需要不同的算子设置,可以在初始化该类对象的时候,set 不同的属性值。如下:
所有页面逻辑皆返回特定页面对象,以保证测试用例使用 workflow 式 API。
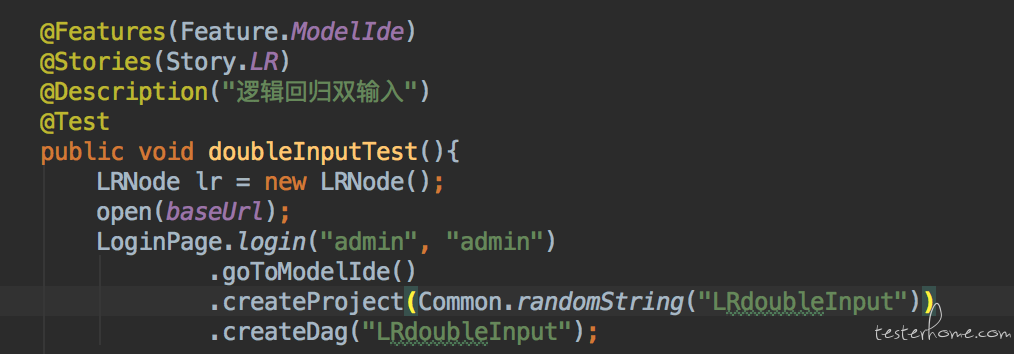
以登录为例。 如下图:

登录后,进入导航页,然后在导航页的方法如下:

在进入模型 IDE 的时候返回模型 IDE page 的对象。
这样可以保持测试用例始终保持 workflow 式的调用。 如下:
除特别简单的逻辑外。所有业务逻辑的参数均使用 java bean 以及枚举封装,禁止使用基本数据类型 (int,String, long 等),并按照 UI 实际情况设计默认值
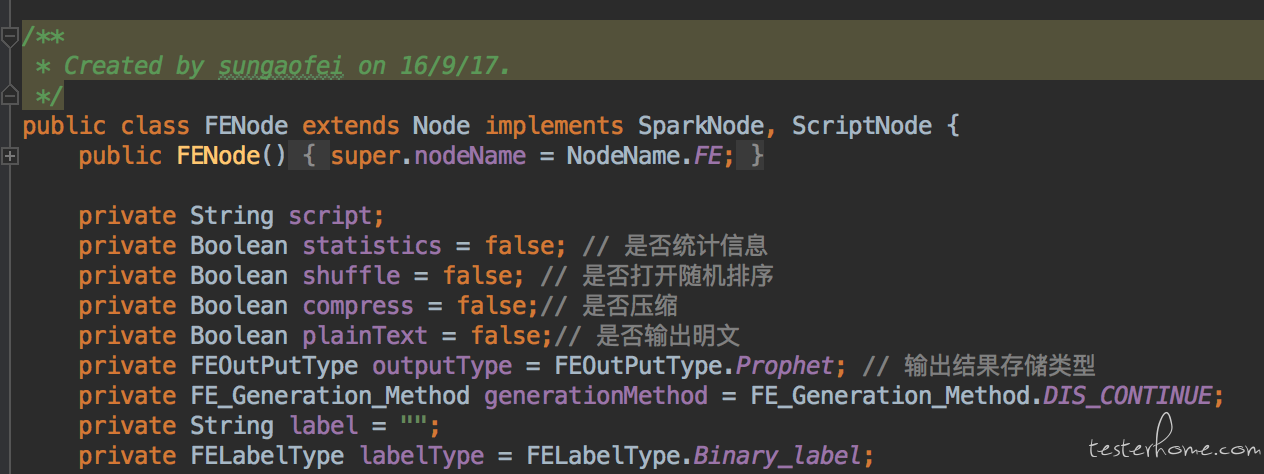
为防止产品设计变化,所有的业务逻辑参数都由 java bean 封装。 因为如果不使用 java bean 而是使用基本数据类型。那么在产品变化的时候,比如 UI 上多了一个必填的元素的时候。方法签名就会变化,导致所有调用此方法的调用方都要变化。 而是使用 java bean 封装的参数可以在其中直接增加一个属性并设置默认值即可。
如下图:图 1 为 FE 算子的配置类,图二为调用方。
所有状态吗,产品特定文案,内置类型等均使用枚举定义。并使用枚举来规范入参。
产品文案会变化,状态流转会变化。 有些时候我们会使用相应的文案来搜索页面控件, 有时候我们也会以查询数据库的方式来跟踪任务的状态, 并且这些会在整个测试的各个地方使用到。 所以严禁在 case 中或者 page 类中直接使用字符串或者数据类型的变量直接使用。 而是要将他们提取为枚举来使用。如下图:
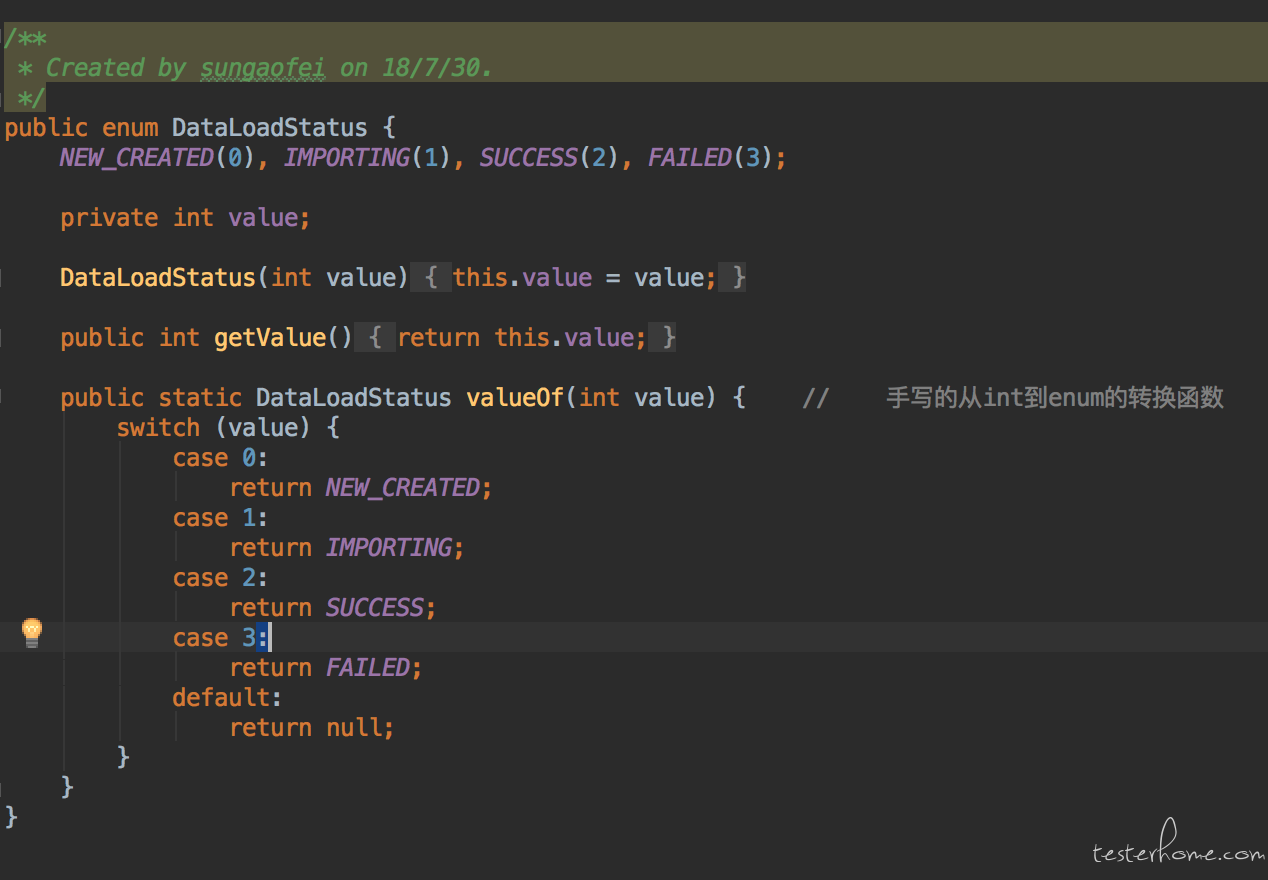
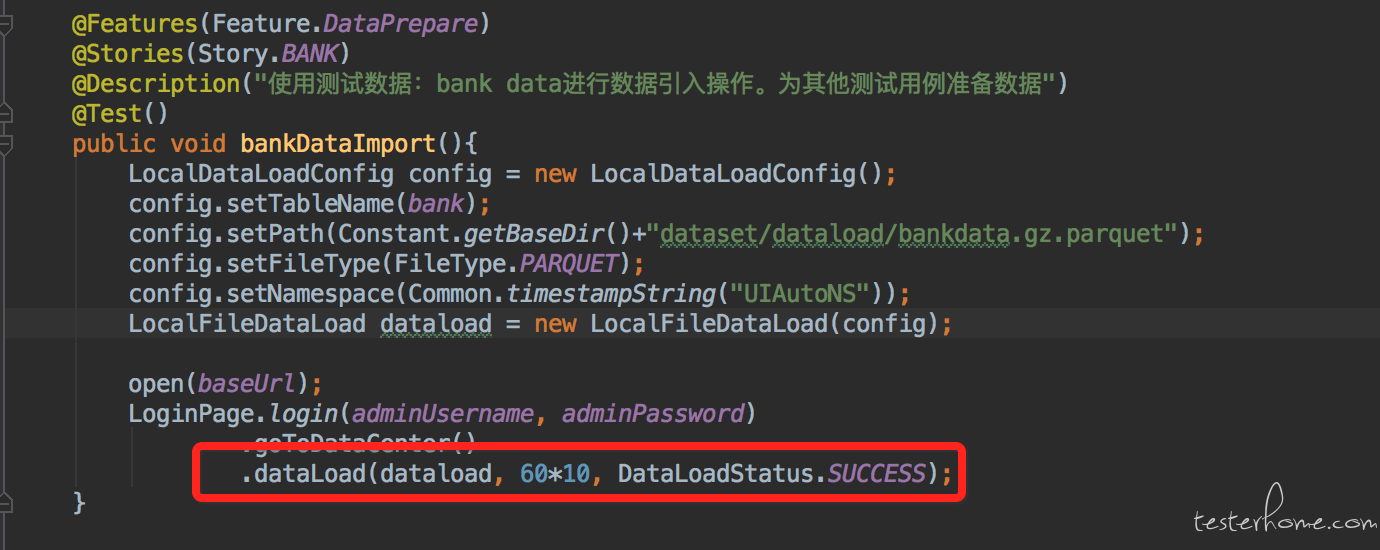
上图是数据库中一个任务当前状态的枚举类型,在 case 运行时会动态查询数据库中此任务的 status 字段来判断任务当前状态。在 case 中调用等待任务完成的时候,需要传入此枚举表示这个用例期望这次任务的结果是哪种状态,如下图表示期望 dataload 运行成功。 当然也有些 case 会期望任务失败。
模块间有数据依赖的时候。每个模块自己负责提供对外接口。
比如测试模型中心或者预估服务的时候,首先必须要有模型事先产出。而产出一个模型需要在模型 IDE 中执行很复杂的步骤,跳转多个页面。 那么模型 IDE 负责对外提供一个封装了所有逻辑的简单接口对外使用。 例如:

ModelIDE 负责提供 modelFactory,调用方只需要传递一个模型训练算法的默认配置就可以产出相应算法的模型出来。 至于里面如何创建 project 和 dag, 使用什么数据,怎么抽取特征等等都不是调用方关心的。 他们只要一个模型出来,至于这个模型怎么出来的逻辑,不要暴露给调用方。
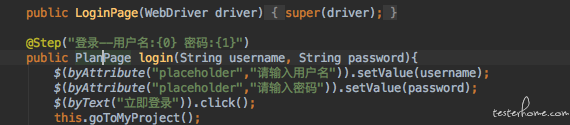
所有业务逻辑使用@Step标注进行标记 (allure 的特性).
用例编写规则
每个 case 都必须使用 Features,Stroies, Title 标注来为 case 添加 report 信息 (我们使用的是 allure 这个 report 框架), 根据情况可以添加 Description 标注。
具体如下:

case 中涉及 UI 上创建的实体名称,比如项目,数据,模型,用户等都需要使用随机名称。 不能使用固定名称。 以防一个环境多次运行的时候因为名称冲突而失败
case 中不准许出现页面元素信息,所有页面元素的封装和业务逻辑的封装要写在 page 层中
结尾
到这里差不多了,主要是一些设计上的规范,剩下的什么命名规范之类的就不讲了。 下一次更新一把 UI 自动化中常用的设计模式。
