前言
这个系列算是科普文吧,尤其这第一篇可能会比较长,因为我这 8 年里一直在 AI 领域里做测试,涉及到的场景有些多, 我希望能尽量把我经历过的东西都介绍一下,算是给大家科普一下我们这些在 AI 领域内做测试的人,每天都在做什么事情。 当然 AI 领域很庞杂,我涉及到的可能也仅仅是一小部分,这篇帖子算是抛砖引玉,欢迎大家一起来讨论。
我打算先简单讲解一下人工智能的原理,毕竟后面要围绕这些去做测试, 并且包括了在测试大模型以及其他一些场景的时候,需要自己构建模型来辅助测试, 所以我觉得至少先讲明白迁移学习的原理,这样我们后面做模型微调定制自己的模型的时候才有据可依。
PS:由于是科普性质的,所以不会讲的特别深, 很多地方我都简化过并且翻译成大白话方便大家理解。 要是每一个点都很详细的深入的去讲,那估计都能写成本书了。
宣传下星球
我最近开了一个知识星球,定期更新 AI,云计算,自动化测试,性能测试等场景的文章,并且定期开直播, 最近在开启从 0 开始写 AI 评测平台的直播内容。

专家系统与机器学习
我们举一个信用卡反欺诈的例子, 以前的时候在银行里有一群业务专家, 他们的工作就是根据自己的知识和经验向系统中输入一些规则。例如某一张卡在一个城市有了一笔交易,之后 1 小时内在另一个城市又有了一笔交易。这些专家根据以前的经验判断这种情况是有盗刷的风险的。他们在系统中输入了 1 千多条这样的规则,组成了一个专家系统。 这个专家系统是建立在人类对过往的数据所总结出的经验下建立的。 我们可以把它就看成一个大脑,我们业务是受这个大脑控制的。但这个大脑是有极限的,我们要知道这种规则从 0 条建立到 1 条是很容易的,但是从几千条扩展到几千零一条是很难的。 因为你要保证新的规则有效,要保证它不会跟之前所有的规则冲突,所这很难,因为人的分析能力毕竟是有限的。 我听说过的最大的专家系统是百度凤巢的,好像是在 10 年的时候吧,广告系统里有 1W 条专家规则。但这是极限了,它们已经没办法往里再添加了。 所以说这是人脑的一个极限。 后来呢大家引入机器学习, 给机器学习算法中灌入大量的历史数据进行训练, 它跟人类行为很像的一点就是它可以从历史数据中找到规律,而且它的分析能力更强。 以前人类做分析的时候,可能说在反欺诈的例子里,一个小时之内的跨城市交易记录是一个规则,但如果机器学习来做的话,它可能划分的更细,例如 10 分钟之内有个权重,10 分钟到 20 分钟有个权重,1 小时 10 分钟也有个权重。 也就是说它把这些时间段拆的更细。 也可以跟其他的规则组合,例如虽然我是 1 小时内的交易记录跨越城市了,但是我再哪个城市发生了这类情况也有个权重,发生的时间也有个权重,交易数额也有权重。也就是说机器学习能帮助我们找个更多更细隐藏的更深的规则。 以前银行的专家系统有 1000 多条规则,引入了机器学习后我们生成了 8000W 条规则。 百度在引入机器学习后从 1w 条规则扩展到了几十亿还是几百亿条 (我记不清楚了)。 所以当时百度广告推荐的利润很轻易的提升了 4 倍。 我们可以把专家系统看成是一个比较小的大脑,而机器学习是更大的大脑。 所以说我们叫它机器学习,是因为它像人类一样可以从历史中库刻画出规律,只不过它比人类的分析能力更强。 所以在网上有个段子么,说机器学习就是学出来海量的 if else, 其实想想也有道理,套路都是 if 命中了这条规则,就怎么么样的,else if 命中了那个规则,就怎么怎么样的。 人类的分析能力有限么,专家系统里人类写 1 千,1w 个 if else 就到头了。 但是机器学习给你整出来几百个亿的 if else 出来。 我们就可以把机器学习想的 low 一点么,不要把它想的那么神秘。
那深度学习是什么呢, 深度学习就是机器学习的一个分支,他把基础的机器学习算法(逻辑回归),扩展成了神经网络:
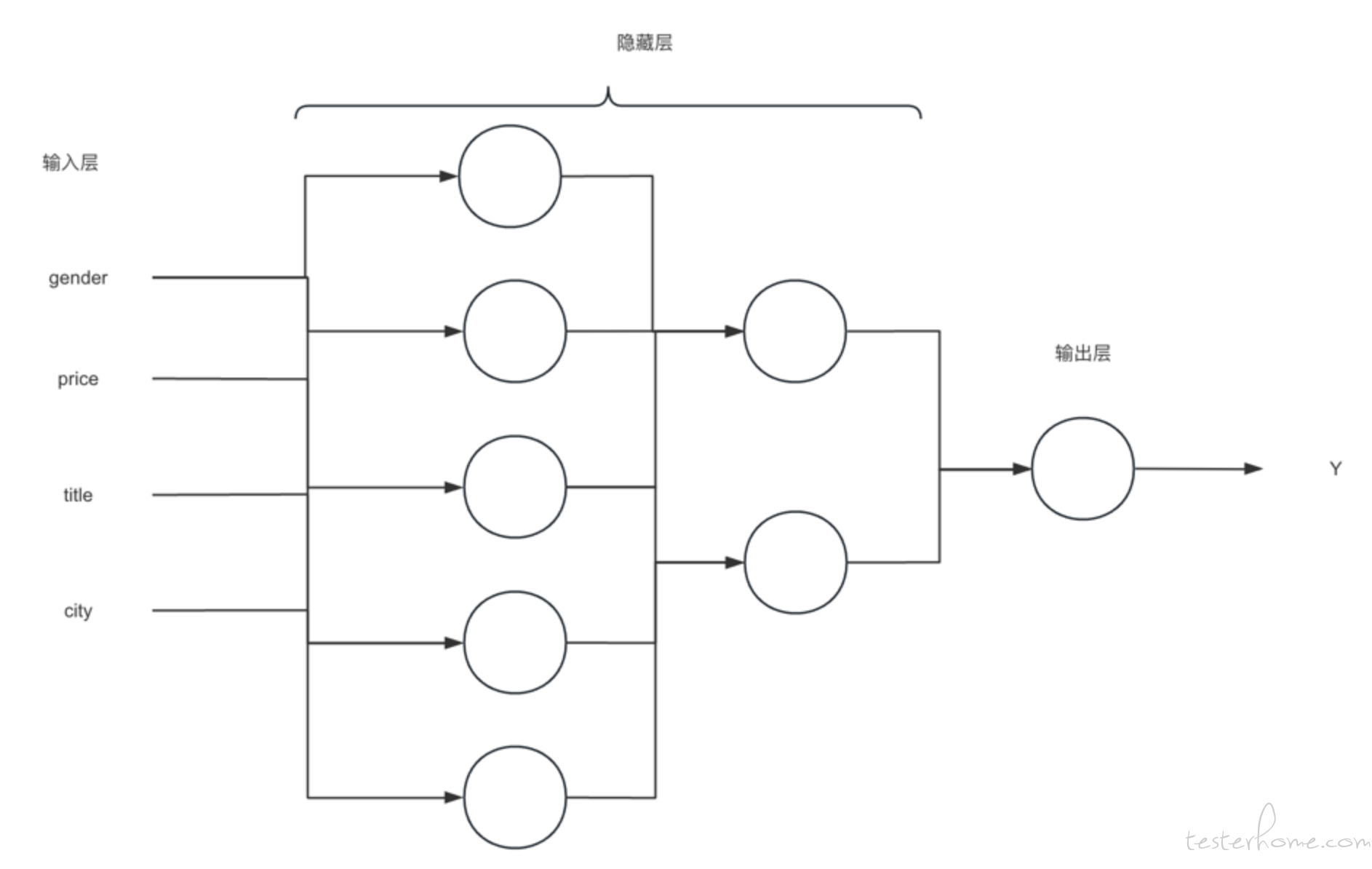
上面是一个神经网络的结构图, 可以理解为这个神经网络里, 除了输入层外,每一个神经元(节点)都是一个逻辑回归, 这样我们的算法就更加的复杂,能够计算更加复杂的情况。 所以我们说传统的结构化数据比较少会用到深度学习, 因为结构化数据比较简单,不需要那么复杂的计算。 而为了能够计算图像和 NLP 领域内的复杂场景,才需要用到神经网络。 而深度学习就是一个拥有很多个隐藏层的神经网络,科学家们把这种情况命名为深度学习。
什么是模型
人类负责提供数据提取特征, 而算法负责学习这些特征对应的权重, 比如我们有下面这张表:
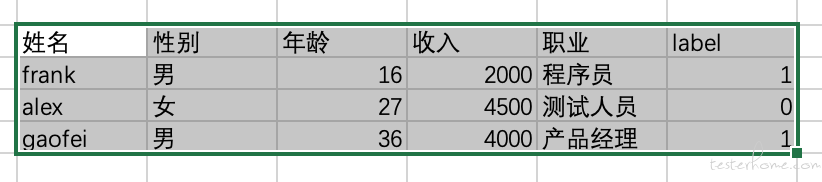
还是以信用卡反欺诈为例子,假设这张表中 label 列就是表明该用户是否是欺诈行为的列。 当我们告诉算法, 性别,年龄,职业和收入是有助于判断用户行为是否为欺诈行为的重要特征,那么算法就会去学习这些特征对预测最终结果的权重。 并把这些保存成一个模型。 我们可以理解为模型就是保存这些特征和权重的数据库。 比如可以简单理解为模型里保存的主要是:
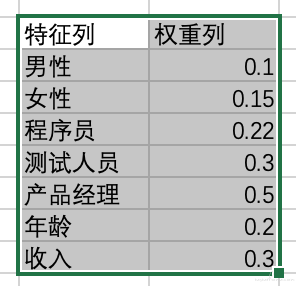
当用户的一条数据过来后, 就要到模型里面去查询对应特征的权重了, 比如新来了一条数据,是男性,收入 2300,年龄 24,职业是程序员。那么算法的计算过程就是:y = 男性 *0.1 + 程序员 *0.22 + 2300*0.3 + 24 * 0.2 。 假设最终的结果是 0.8,代表着这条数据有 80% 的概率是信用卡欺诈行为。 然后我们自己设定一个阈值, 或者叫置信度, 比如这个值是 0.7,意思是如果模型预测这个数据是欺诈行为的概率是大于 0.7 的,那我们就让系统认为这个用户就是欺诈行为, 而如果模型预测的解雇欧式这个数据是欺诈行为的概率小于 0.7,那我们就让系统判定它是非欺诈行为,这就是一个典型的二分类模型的原理 -- 算法输出的是概率,系统通过设定阈值来做最后判断。 所以算法本身的公式其实就是: y= w1*x1+ w2*x2 + w3*x3 ...... wn*xn +b 。 其中 x 是特征, w 是特征对应的权重,b 是偏移量。其实模型的原理换成大白话来说还是比较简单的。
而我们说机器学习, 它学习的就是 w 和 b(因为我们特征值的已知的),算法要通过一种方式来学习什么的 w 和 b 的值能让最终的结果与真实的情况最接近, 而这个方法就叫梯度下降,但是我不打算在这里讲它的原理了, 因为毕竟我们这里是讲如何做测试的, 不懂这个梯度下降的原理也没关系。 感兴趣的同学可以查查我之前写的深度学习的帖子。
什么是迁移学习
还拿上面的例子来说明,我们已经训练好了一个模型,在这个模型中针对职业分别保存了程序员,测试人员和产品经理的特征和权重,它在当前场景下工作的很好。 我们想把这个模型放到另外一个公司里面使用,但是这个公司里除了这 3 种职业外,还有财务人员和行政人员,这样这个模型的效果就不能满足新公司的需要了。 这时候怎么办呢?再根据新公司的数据重新训练一个模型么?可以是可以, 但是这个成本可能太高了, 因为模型是要基于很大的数据进行训练的,这对数据质量和算力都有比较高的要求。 所以这时候我们可以换个思路,虽然旧的模型中没有财务人员和行政人员的记录,但是它里面的程序员,测试人员和产品经理在新公司里也有这些职位的,所以旧模型并不是完全没用,起码在这三个职位上我们还可以用旧模型工作起来。 那假如我们让算法去学习在财务和行政人员的权重后,再更新到旧的模型里,可不可以呢:
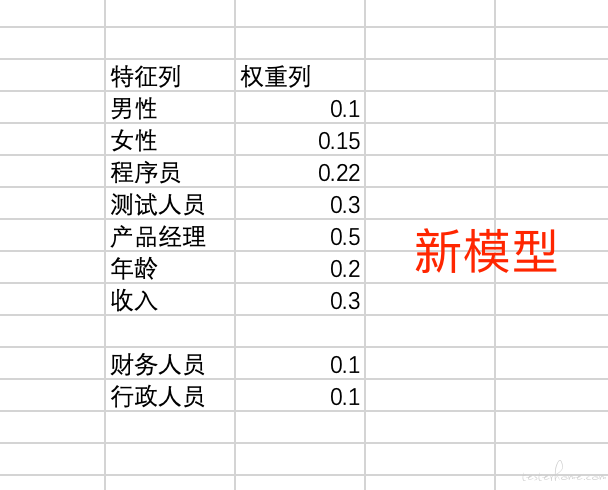
答案是可以的, 这就是迁移学习,也叫模型微调。 在已有的模型的基础上稍微进行调整来满足新的场景。打个比喻,就好像我们有一本练习题, 之前有位学霸已经写下了练习题的所有答案了, 后来这本练习题出了新的版本,但其实 90% 的题还是老的。 只有 10% 的题不一样,那么我们只需要把老的题的答案都照着抄下来, 我们自己去写剩下 10% 就可以了。
当然在模型微调的时候也可以修改旧模型中的特征, 比如我们觉得那位学霸在明朝历史方面的造诣不如我们自己, 那我们就可以选择在这方面更相信自己的判断,并不会全盘照抄(参数冻结,后面讲微调的时候我们会说)。
迁移学习对于人工智能的发展至关重要, 我们可以使用权威的模型(这些模型经过了时间和各个项目的考验)并进行微调以适应自己的场景。 这也为在某些场景下测试人员利用模型的能力来辅助测试场景带来了可能性(毕竟从头训练一个新模型的成本太高)
模型评估指标
接下来终于要说到如何测试模型了, 在这个领域里模型其实没有 bug 一说, 我们通过会说一个模型的效果好或者不好, 不会说这个模型有 bug -- 因为世界上没有 100% 满足所有场景的模型。 那我们要如何评估模型呢。 下面以分类模型为主。分类模型就是需要模型帮我们判断这条数据属于哪些分类,比如是信用卡欺诈行为或者不是,这就是二分类。 也可以是判断目标是猫,还是狗,还是老鼠或者是人, 这种就是多分类。 一般要评估这种分类模型,我们需要统计一些标准的评估方法。 首先说一下为什么不能直接用模型预测的正确率。正确率越高说明模型效果越好, 这其实是一个普遍的误区。 举一个例子把,假设我们有一个预测癌症的场景,健康的人有 99 个 (y=0),得癌症的病人有 1 个 (y=1)。我们用一个特别糟糕的模型,永远都输出 y=0,就是让所有的病人都是健康的。这个时候我们的 “准确率” accuracy=99%,判断对了 99 个,判断错了 1 个,但是很明显地这个模型相当糟糕,在真实生活中我们大部分场景都是正/负向本相差十分悬殊的,一旦分布十分悬殊那么准确率这种简单粗暴的方法就难以表达模型真正的效果, 所以准确率往往是我们最不常用的评估方法。因此需要一种很好的评测方法,来把这些 “作弊的” 模型给揪出来。
混淆矩阵
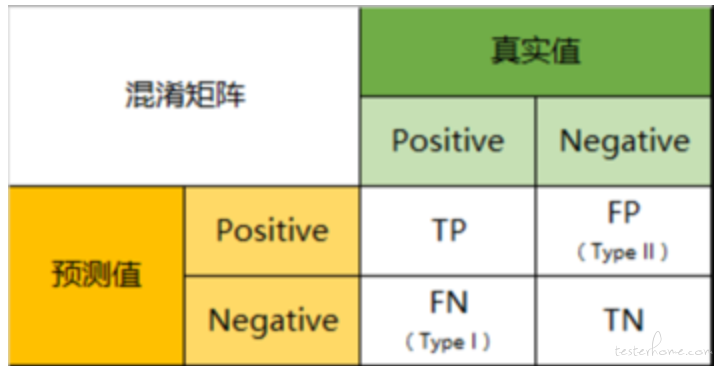
混淆矩阵是一个用于描述分类模型性能的矩阵,它显示了模型对于每个类别的预测结果与实际结果的对比情况。
以分类模型中最简单的二分类为例,对于这种问题,我们的模型最终需要判断样本的结果是 0 还是 1,或者说是 positive 还是 negative。
我们通过样本的采集,能够直接知道真实情况下,哪些数据结果是 positive,哪些结果是 negative。同时,我们通过用样本数据跑出分类型模型的结果,也可以知道模型认为这些数据哪些是 positive,哪些是 negative。
因此,我们就能得到这样四个基础指标,我称他们是一级指标(最底层的):
真实值是positive,模型认为是positive的数量(True Positive=TP)
真实值是positive,模型认为是negative的数量(False Negative=FN)
真实值是negative,模型认为是positive的数量(False Positive=FP)
真实值是negative,模型认为是negative的数量(True Negative=TN)
将这四个指标一起呈现在表格中,就能得到如下这样一个矩阵,我们称它为混淆矩阵(Confusion Matrix):
多分类的混淆矩阵
当分类的结果多于两种的时候,混淆矩阵同时适用。
下面的混淆矩阵为例,我们的模型目的是为了预测样本是什么动物,这是我们的结果:

二级指标
但是,混淆矩阵里面统计的是个数,有时候面对大量的数据,光凭算个数,很难衡量模型的优劣。 所以我们需要在混淆矩阵的基础上引入其他几个指标
因此混淆矩阵在基本的统计结果上又延伸了如下几个个指标:
- 召回率:recall,召回率就是说,所有得了癌症的病人中,有多少个被查出来得癌症。公式是:TP/TP+FN。 意思是真正类在所有正样本中的比率,也就是真正类率
- 精准率:precision,还是拿刚才的癌症的例子说。精准率 (precision) 就是说,所有被查出来得了癌症的人中,有多少个是真的癌症病人。公式是 TP/TP+FP。
召回和精准理解起来可能比较绕,我多解释一下,我们说要统计召回率,因为我们要知道所有得了癌症中的人中,我们预测出来多少。因为预测癌症是我们这个模型的主要目的, 我们希望的是所有得了癌症的人都被查出来。不能说得了癌症的我预测说是健康的,这样耽误人家的病情是不行的。 但同时我们也要统计精准率, 为什么呢, 假如我们为了追求召回率,我又输入一个特别糟糕的模型,永远判断你是得了癌症的,这样真正得了癌症的患者肯定不会漏掉了。但明显这也是不行的对吧, 人家明明是健康的你硬说人家得了癌症,结果人家回去悲愤欲绝,生无可恋,自杀了。或者回去以后散尽家财,出家为僧。结果你后来跟人说我们误诊了, 那人家砍死你的心都有。 所以在统计召回的同时我们也要加入精准率, 计算所有被查出来得了癌症的人中,有多少是真的癌症病人。 说到这大家可能已经看出来召回和精准在某称程度下是互斥的, 因为他们追求的是几乎相反的目标。 有些时候召回高了,精准就会低。精准高了召回会变低。 所以这时候就要根据我们的业务重心来选择到底选择召回高的模型还是精准高的模型。 有些业务比较看重召回,有些业务比较看重精准。 当然也有两样都很看重的业务,就例如我们说的这个预测癌症的例子。或者说银行的反欺诈场景。 反欺诈追求高召回率,不能让真正的欺诈场景漏过去,在一定程度上也注重精准率,不能随便三天两头的判断错误把用户的卡给冻结了对吧,来这么几次用户就该换银行了。 所以我们还有一个指标叫 F1 score, 大家可以理解为是召回和精准的平均值,在同时关注这两种指标的场景下作为评估维度。F1 = 2PR/(P+R) 其中,P 代表 Precision,R 代表 Recall。
多分类评估举例
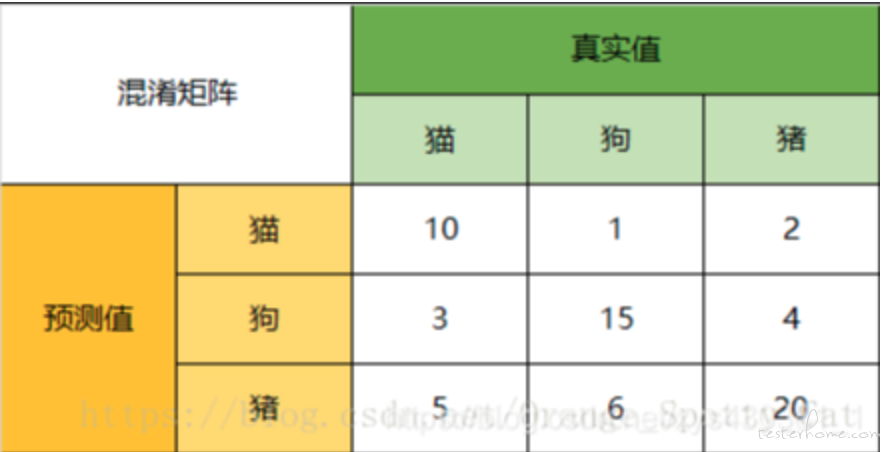
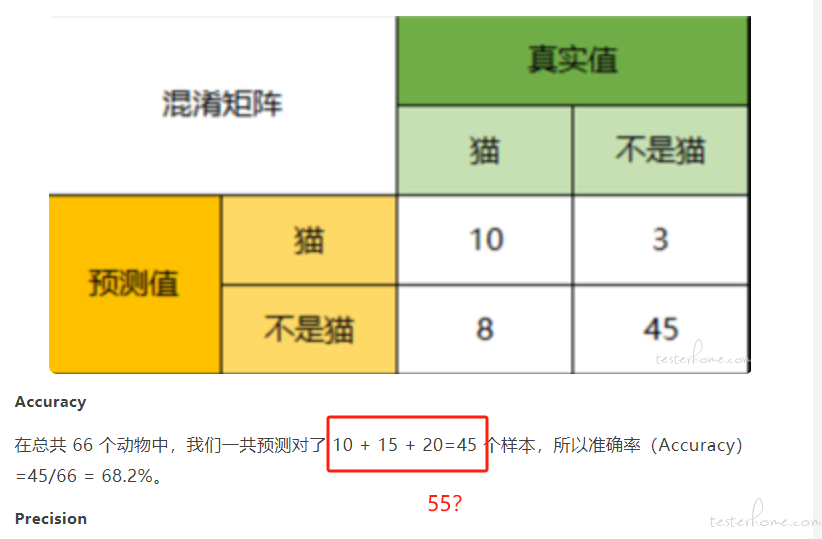
将多分类混淆矩阵二分化,以猫为例,我们可以将上面的图合并为二分问题:

Accuracy
在总共 66 个动物中,我们一共预测对了 10 + 15 + 20=45 个样本,所以准确率(Accuracy)=45/66 = 68.2%。
Precision
所以,以猫为例,模型的结果告诉我们,66 只动物里有 13 只是猫,但是其实这 13 只猫只有 10 只预测对了。模型认为是猫的 13 只动物里,有 1 条狗,两只猪。所以,Precision(猫)= 10/13 = 76.9%
Recall
以猫为例,在总共 18 只真猫中,我们的模型认为里面只有 10 只是猫,剩下的 3 只是狗,5 只都是猪。这 5 只八成是橘猫,能理解。所以,Recall(猫)= 10/18 = 55.6%
F1-Score
通过公式,可以计算出,对猫而言,F1-Score=(2 * 0.769 * 0.556)/( 0.769 + 0.556)= 64.54%
ROA 与 AUC
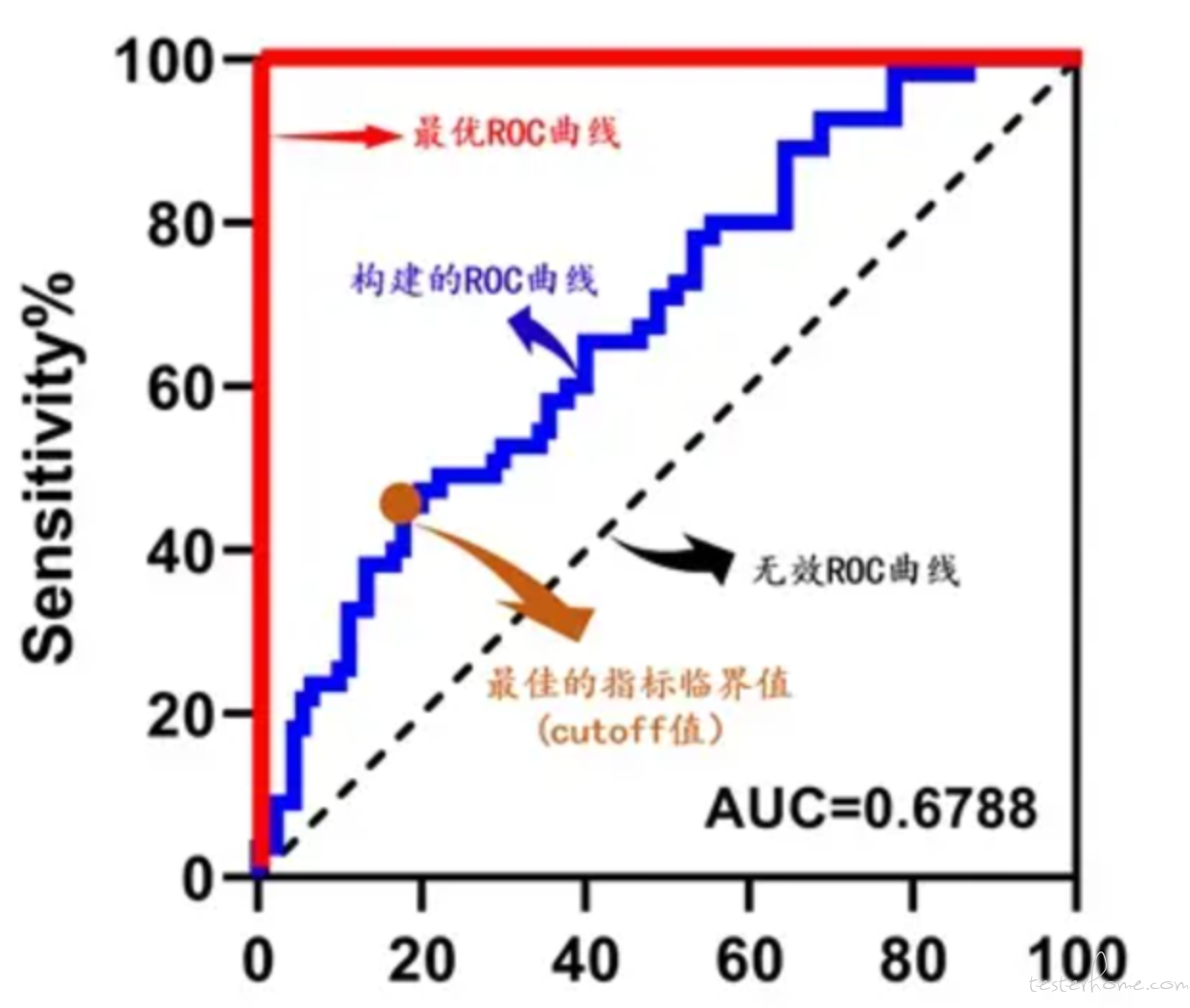
ROC(Receiver Operating Characteristic Curve)和 AUC(Area Under Curve)是评价分类模型性能的指标,常用于二分类问题。
ROC 曲线是将真阳性率(True Positive Rate,TPR)和假阳性率(False Positive Rate,FPR)在不同阈值下的表现绘制成的曲线。TPR(也称为敏感性)表示正类样本中正确识别的正类样本所占的比例,而 FPR(1-特异性)表示负类样本中错误识别为正类样本的负类样本所占的比例。
AUC 则是 ROC 曲线下的面积,用来量化模型的分类能力。AUC 越大,表示模型的分类性能越好。
在二分类问题中,ROC 曲线一般是从左上角到右下角,曲线下的面积(AUC)为 0.5,表示模型对正负类的预测概率相等。如果 AUC 大于 0.5,表示模型对正类预测较好,如果 AUC 小于 0.5,表示模型对负类预测较好。
ROC 曲线和 AUC 可以作为评估分类模型性能的参考指标,并且可以帮助选择合适的分类阈值。
一般在一些机器学习的库中,会有相关的算法去统计 AUC 指标,比如在 spark 库中:
from pyspark.ml.evaluation import BinaryClassificationEvaluator
from pyspark.ml.feature import VectorAssembler
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StructField, DoubleType, IntegerType
spark = SparkSession.builder \
.appName("AUC Calculation") \
.getOrCreate()
data = [(0, 1.0), (1, 0.9), (0, 0.8), (1, 0.7), (0, 0.6), (1, 0.5), (0, 0.4), (1, 0.3), (0, 0.2), (1, 0.1)]
# 定义数据模式
schema = StructType([
StructField("label", IntegerType(), True),
StructField("probability", DoubleType(), True)
])
# 将数据转换为 DataFrame
df = spark.createDataFrame(data, schema=schema)
# 计算 AUC
evaluator = BinaryClassificationEvaluator(rawPredictionCol="probability", labelCol="label")
auc = evaluator.evaluate(df)
print("AUC:", auc)
分组指标的统计
我们现在有了一些常用的评估指标。 但这些往往还是不够,因为我们每一个模型都是有业务场景的,业务场景有很复杂的逻辑和不同的侧重点。 以前在测试模型的时候经常的漏测场景就是忽略了业务含义而做的测试。 举个例子,我们拿某视频网站的视频推荐系统来说。 我们使用二分类模型来做推荐问题, 怎么做呢, 我们有一个用户, 同时有 2000 个视频候选集,我们分别用这些视频和用户分别用模型算出 2000 个概率,意思是每个视频用户会点击的概率。然后从高到低排序。把排行前面的视频推荐给用户。 所以我们就把一个推荐系统的问题转换为一个分类问题。只不过这里我们不设置阈值了而已。如果按照我们刚才讲的评估指标,我们计算了 AUC,召回,精准。 就可以了么,大家想一想这样做有没有什么问题? 问题是这些指标的统计都是建立在所有测试集下进行的统计的,粒度是非常粗的。 也就是说我们并没有对测试数据进行分类。 举个例子, 在视频网站中, 新用户和新视频的点击情况可能也是比较看重的指标。 尤其是视频网站上每日新增的视频是很多的,对于新增的热点视频的曝光率也就是被推荐的概率也是很重要的维度。 假如我们有一个模型,我们测试之后发现各项指标都很好,但其实可能它对新用户或者新视频的预测并不好,只是由于新增的用户和视频在整个数据集中的占比太小了,所以从整体的评估指标上来看是比较好的。 所以一般我们测试一个模型的时候,要根据业务引入分组指标的统计。并且要保证每一个分组都有足够的样本,如果某个分组的样本数量太少,那么不足以表达它的真实效果。所以在数据采集的时候就需要注意。
其实就是需要测试人员要理解你的业务, 熟悉你的数据。 你需要了解产品的用户画像, 需要知道用户要切分成多少个分类。 比如按职业分类, 按性别分类, 按爱好分类, 按时间段分类,按年龄分分类, 按行为分类等等等等。 只要足够了解了用户和数据,测试人员才知道都需要从哪些维度评估模型的效果。 我们说搞算法测试的人 8 成时间都是在跟数据打交道, 就是因为这样。 所以比起对 AI 算法的理解, 数据处理技术可能对测试人员来说才是更重要的。比如处理结构化数据需要学习 spark,hive 这样的分布式计算框架,处理图像数据需要学习 opencv 和 ffmpeg。 因为需要对数据进行采集,分析,统计。 毕竟符合场景要求的数据不会自己飞到你面前。下一篇文章会详细介绍数据处理相关的内容, 这一次只介绍效果测试的方法。
计算机视觉下的模型效果测试
上面我们聊的所有的场景都是在结构化数据下的,通常在金融领域或者在某些互联网系统中(比如推荐系统)。 但在计算机视觉场景里,模型的评估指标会稍微有些不一样。 但其大部分的基本方法论仍然是通用的,比如召回,精准, FIcore 依然是通用的。只是在一些特殊场景里会有不同。 比如在目标检测场景中:

这是我周末带老婆孩子去体育场玩时拍下来的照片。 我使用这张照片输入到 yolo 模型中(计算机视觉中非常著名的算法),希望模型可以识别出图片中的人类并画出人类所在位置的长方形的框(框上面的数字是这个目标属于人类的概率)。 而这就是目标检测,同时目标检测也是计算机视觉中的基础算法,很多其他场景都需要依赖目标检测。 比如 OCR 要识别文字, 就需要先定位到文字所在的位置,所以需要先经过目标检测。
那么在这样的场景中,我们同样需要使用召回率,精准率这些指标来统计目标识别的效果,用来评估有多少真正的目标被识别出来了,又有多少非目标物体被错误的识别出来了。 但也需要额外再去评估这个框的准确性, 就是虽然目标识别出来了, 但是你画框的位置有偏差,这样就不好了。 就像我们刚才说 OCR 的流程是先跑一个目标检测把目标的位置识别出来, 然后再把目标位置的图像信息输入到另一个模型(负责文字识别),所以如果位置识别的有偏差, 可能会造成最终结果的南辕北辙。而评估这个位置的指标,我们叫 IOU。直接上代码:
# IoU是目标检测中常用的一种重叠度量,用于衡量检测框和真实标注框之间的重叠程度。IoU值越大,表示检测结果越准确。它的达标标准取决于具体的应用场景和需求。
# 在目标检测任务中,常用的IoU阈值为0.5或0.7,即当检测框与真实标注框的IoU值大于等于0.5或0.7时,认为检测结果正确。在一些特定的应用场景中,IoU阈值可能会更高或更低,比如如果用于OCR, 那么准确度要求是非常高的。
def compute_iou(box1, box2):
# 计算两个矩形框的面积
area1 = (box1[2] - box1[0] + 1) * (box1[3] - box1[1] + 1)
area2 = (box2[2] - box2[0] + 1) * (box2[3] - box2[1] + 1)
# 计算交集的坐标范围
x1 = max(box1[0], box2[0])
y1 = max(box1[1], box2[1])
x2 = min(box1[2], box2[2])
y2 = min(box1[3], box2[3])
# 计算交集的面积
inter_area = max(0, x2 - x1 + 1) * max(0, y2 - y1 + 1)
# 计算并集的面积
union_area = area1 + area2 - inter_area
# 计算IoU值
iou = inter_area / union_area
return iou
box1 = [50, 50, 150, 150] # 左上角坐标为(50, 50),右下角坐标为(150, 150)
box2 = [100, 100, 200, 200] # 左上角坐标为(100, 100),右下角坐标为(200, 200)
# 计算两个矩形框之间的IoU值
iou = compute_iou(box1, box2)
# 输出结果
print('IoU:', iou)
NLP 的评估指标
刚才我们提到了 OCR, 其实 OCR 本身也算是沾着 NLP 的边的,毕竟他有个需要理解人类语言的过程。 那一般在 NLP 领域里我们会如何评估它的效果呢。 就拿 OCR 来说:
- 字符识别准确率,即识别对的字符数占总识别出来字符数的比例,可以反应识别错和多识别的情况,但无法反应漏识别的情况
- 字符识别召回率,即识别对的字符数占实际字符数的比例,可以反应识别错和漏识别的情况,但是没办法反应多识别的情况,可以配套字符识别准确率一起使用。
- 整行准确率:一个字段算一个整体,假如 100 个字分为 20 个字段,里面错了 5 个字,分布在 4 个字段里,那么识别率是 16/20=80%。
- 平均编辑距离:是一种衡量两个字符串之间相似度的度量。在 OCR 中,我们可以使用平均编辑距离来评估 OCR 系统的效果。具体来说,我们可以将 OCR 系统识别的文本与实际的文本进行比较,计算它们之间的平均编辑距离。较低的平均编辑距离表示 OCR 系统的效果较好,因为它能更准确地识别和转换图像中的文本。
可以看出精准和召回仍然是比较主要的评估方法,下面给出计算平均编辑距离的 python 代码
import Levenshtein
def average_edit_distance(predicted_text, ground_truth_text):
return Levenshtein.distance(predicted_text, ground_truth_text) / max(len(predicted_text), len(ground_truth_text))
# 示例
predicted_text = "Hello world"
ground_truth_text = "Hello, world!"
aed = average_edit_distance(predicted_text, ground_truth_text)
print(f"Average Edit Distance: {aed:.2f}")
上面的评估方法在 OCR 里比较常用, 相对来说是比较简单的,因为它有 1 对 1 的答案, ocr 识别出来的内容在评估的时候不存在歧义行, 图片里的文字是什么,你识别出来的文字就应该是什么,所以可以在字符级别很容易统计出指标。 但在其他 NLP 领域里就没有那么简单了。 比如对一个翻译模型来说。它翻译出来的内容往往是没有唯一的标准答案的, 比如 my name is frank 和 frank is my name 意思是基本一样的,在一个语言里,你可以用完全不同的表达形式来表述同一个意思,所以有很多时候评估是很主观的, 需要这个语言的专业人员来进行评估,并且也不再是字符级别的,而是针对语句和段落级别来统计翻译的正确率了。
那有没有一种普通的测试人员可以使用的方法呢, 也是有的。 比如 BLEU,ROUGE,METEOR, TER。 这些指标其实都是用一些算法来计算文本之间的相似程度的。
下面以 METEOR 为例子:
from nltk.translate.meteor_score import meteor_score
# 生成文本
generated_text = ['my', 'name', 'is', 'frank']
# 参考文本列表
reference_texts = [['my', 'name', 'is', 'frank'],['frank', 'is', 'my', 'name']]
# 计算 METEOR 指标
meteor = meteor_score(reference_texts, generated_text)
# 打印结果
print("The METEOR score is:", meteor)
操作也比较简单, 我们一般会准备几个参考的答案,把模型生成的本文和参考文本一起输入到算法中,让算法去挨个计算他们之间的相似程度。 这也为自动化测试提供了基础。 这些算法的具体原理就不讲了, 一个是讲不完, 再一个我自己其实也糊里糊涂的, 并且其实完全没必要知道原理, 只需要知道他们是计算文本相似度的就可以了。
其实我更喜欢用 bert 模型来计算文本相似度, bert 是 nlp 领域内非常著名的预训练模型, 它本质上其实是个词向量模型, 用户可以基于 bert 去做模型的微调来完成各种任务。 现在有一个开源项目叫 bert-score,它是专门计算文本相似度的,并且给出相关的精准,召回和 FI score 的指标,要使用 bert-score,需要下载 bert-base-chinese 模型, 这是 bert 针对中文的词向量模型。 然后准备下面的脚本:
from bert_score import score
cands = ['我们都曾经年轻过,虽然我们都年少,但还是懂事的','我们都曾经年轻过,虽然我们都年少,但还是懂事的']
refs = ['虽然我们都年少,但还是懂事的','我们都曾经年轻过,虽然我们都年少,但还是懂事的']
P, R, F1 = score(cands, refs,model_type="bert-base-chinese",lang="zh", verbose=True)
print(F1)
print(f"System level F1 score: {F1.mean():.3f}")
print(f"System level Precison: {P.mean():.3f}")
print(f"System level Recall: {R.mean():.3f}")
输入结果:
System level F1 score: 0.957
System level Precison: 0.940
System level Recall: 0.977
R(召回率 Recall):
- 评估生成文本中有多少与参考文本相匹配的内容。
- 召回率越高,说明生成文本覆盖了更多的参考文本内容。
P(精确度 Precision):
- 评估生成文本中与参考文本匹配的内容所占的比例。
- 精确度越高,说明生成文本中的内容与参考文本的匹配度越高。
F(F1 Score):
- 是 Precision 和 Recall 的调和平均数。
- F1 Score 能够平衡精确度和召回率,提供单一的性能衡量指标。
相比之前的算法,我更喜欢用 bert 来评估文本之间的相似程度。 尤其在大模型的测试中,通常会评估大模型生成的答案,和预期的答案之间的相似程度。 实际上这种用模型测试模型的方法,在大模型场景中也算是不少见了。 那接下来我们聊聊大模型的测试场景。
大模型
其实大模型是典型的生成式模型(用来生成内容的),并且多数能力属于 NLP 领域。 事实上大模型的训练原理也是 NLP 的。 transformer 原本就是用于训练 NLP 模型的, 后来才应用在了大模型中。所以其中的很多的测试方法可以参考 NLP,比如文本相似度的计算。 但这种生成式模型,我们需要考虑几个问题。
数据收集
首先是数据问题, 测试数据的收集向来都是繁杂和枯燥的, 只能一点点按部就班的收集数据并进行评估。由于自然语言的复杂和多样性,这也导致了我们需要
评估的内容非常多。 所以需要建立起一套或多套的问卷来进行评估。 当然也可以用行业公开的数据集和指标。 比如在语言安全方面(内容审核)可以使用 Safety-Prompts,
中文安全 prompts,用于评测和提升大模型的安全性,将模型的输出与人类的价值观对齐。

也可以使用中文通用大模型评测标准 SuperCLUE,23 年 5 月在国内刚推出, 它主要回答的问题是:中文大模型的效果情况,包括但不限于"这些模型不同任务的效果情况"、"相较于国际上的代表性模型做到了什么程度"、 "这些模型与人类的效果对比如何"。
该标准可通过多个层面,考验市面上主流的中文 GPT 大模型的能力。一是基础能力,包括常见的有代表性的模型能力,如语义理解、对话、逻辑推理、角色模拟、代码、生成与创作等 10 项能力;二是专业能力,包括中学、大学与专业考试,涵盖从数学、物理、地理到社会科学等 50 多项能力;三是中文特性能力,针对有中文特点的任务,包括中文成语、诗歌、文学、字形等 10 项能力。
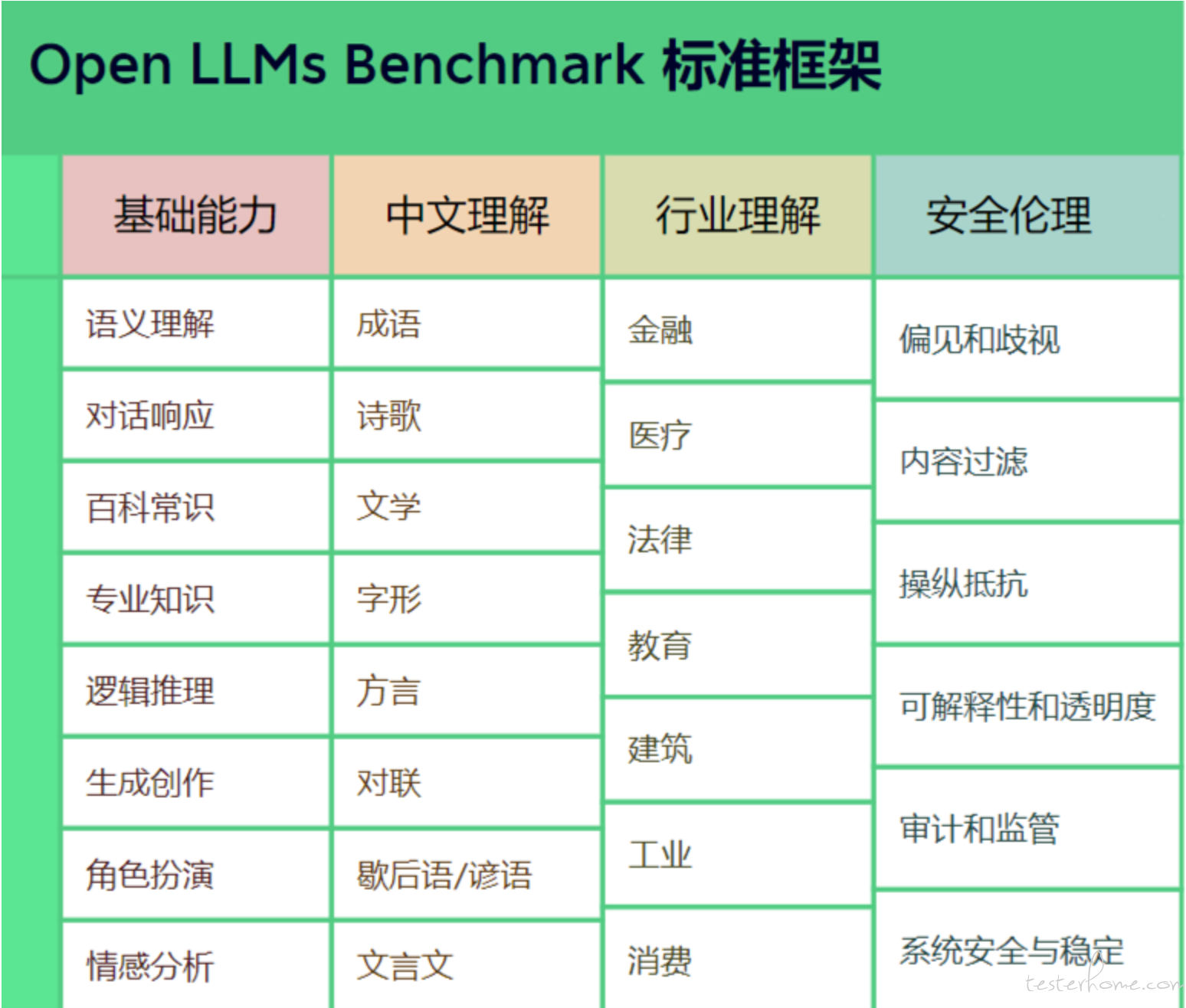
或者 C-Eval:
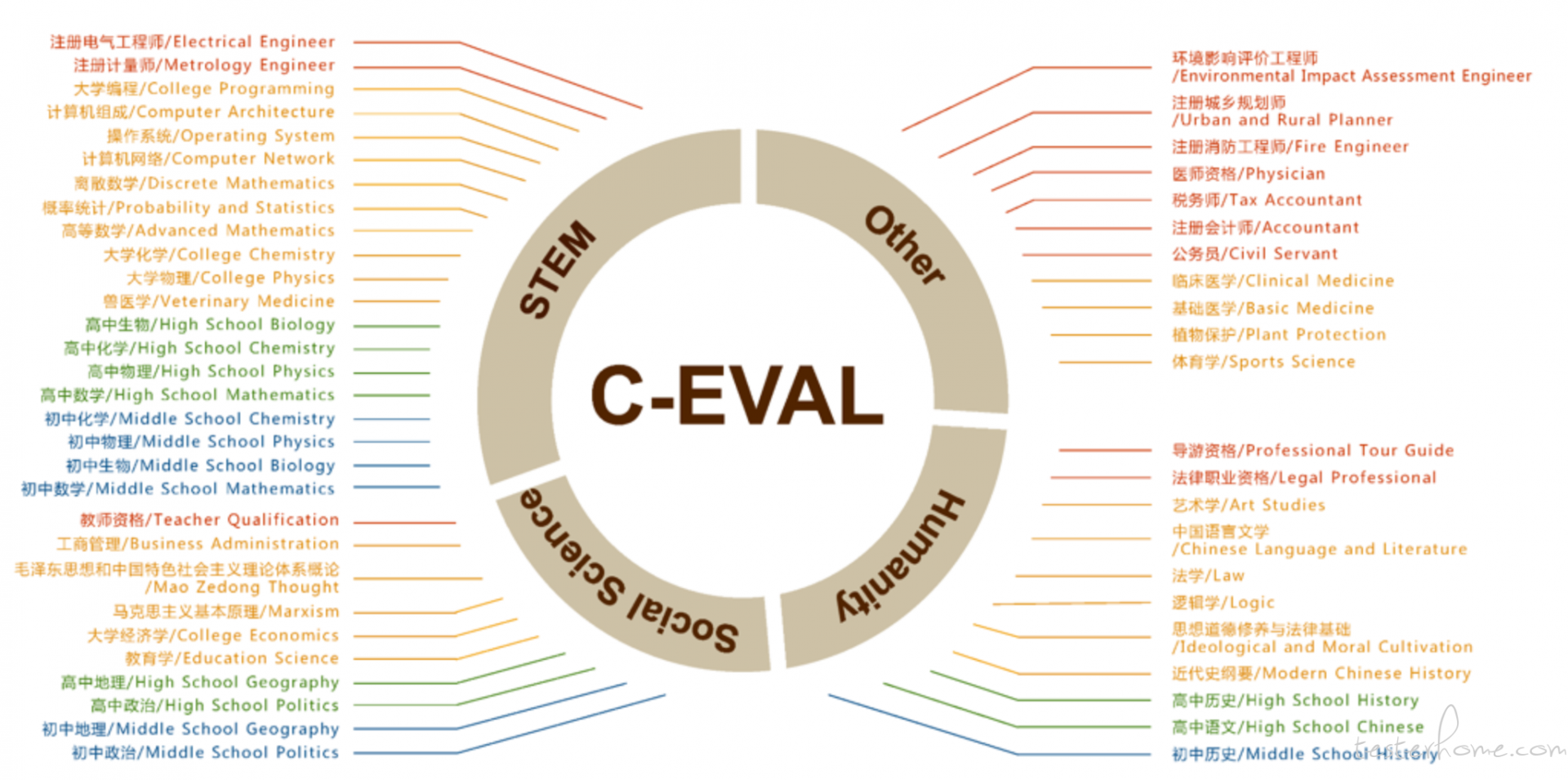

C-Eval 也支持为用户的大模型进行打分, 所以我们可以让自己的大模型去回答 C-Eval 的问题,然后把结果上传回 C-Eval 的官方网站, 就可以得到一个评分结果, 让你知道你的大模型在全球的排名。
但即便有这样的数据测试人员也会遇到如下的问题:
- 一个问题的解答方式是可以有不同的方法的(一题多解)并且在很多领域十分的专业,测试人员没有专业的知识来判断准确性。(这个没有办法解决,没有专业知识是不行的,只能找专业人员评估,所以一个大模型或者生成式模型,需要很多不同职业不同角色的人来进行评估,不是测试人员自己可以搞定的。 在初期的时候需要这些专业人员准备问题和参考答案。 测试人员针对这些问题和答案进行测试,计算文本相似度。)
- 很多问题的答案带有很大的主观理解,比如生成一张图片到底美观不美观,一首诗写的好或不好,是非常看个人的主观意愿的。
- 现实的情况太多了, 测试人员是永远没有办法穷举出用户所有的 prompt 了, 甚至连相当比例的 prompt 都无法穷举出来,这个工作量太过于庞大了。
第一个问题不过多说明了,文本相似度的计算已经在上面说过了。 我们来看看如何解决下面的两个问题。
怎样解决主观差异问题
- 多人打分取平均:假设取 100 分为满分, 别被找 n 个人为结果打分, 然后取平均值。
- 两人打分,并由第三人仲裁:提前设定一个可接受的分差范围,如最大接受 2 个人打分分差为 20 分,对每篇作文,由 2 个人分别独立打分;若分差大于可接受范围,则由第 3 个人参与打分。
主观问题一般只能投票解决了, 我们暂时还没有更好的办法来解决, 如果各位有什么好的方法,也请说出来让我学习参考。
用模型来测试模型
对于这种大模型场景或者生成式场景来说, 测试人员不可能枚举出所有的问题和答案,这个太不现实了。 虽然我们可以爬取到线上用户提的所有问题, 但是我们没办法把他们作为测试数据, 因为这些问题的答案需要人工来判断。所以测试人员能枚举的情况是有限的。 老实讲这个难点几乎无解, 只能是投入大量的人力去收集测试数据。 在 AI 领域里不管是算法人员还是测试人员,都要面临巧妇难为无米之炊的窘境, 而数据就是那个米。 但是测试人员在这里还是可以做一些事情的。 我们可以去总结一些特定的场景。 比如我在将大模型数据的时候,一开始的那个内容审核的场景或者叫安全场景。 大家看当用户输入了辱骂,违法,歧视,黄色,暴力等 prompt 候,我们的模型必须是要明确反对,劝导和拒绝的。 所以我们可以用自己收集的,或者公开的安全场景的数据集输入到模型中, 只要模型明确的输出了带有反对,劝导和拒绝的带有这种感情色彩的答案,就是对的,没有返回就是错的。 这种测试类型也是很重要的(参考之前网络上流传的各种模型翻车的案例,如果严重了会被下架)。所以如果我们的程序可以判断模型输出的答案是否有这种感情色彩就可以了。 于是乎,我们把这样的问题抽象成了一个文本分类,或者叫文本的情感分类场景。 这时我们就可以自己训练一个模型来完成这种判断。 当然从头训练一个模型基本是不现实的,这个成本太高了。 所以我们要利用迁移学习的思路,用一个成熟的模型经过微调后来满足我们的场景。 这也是为什么我在开篇要先讲迁移学习的原因之一。 我这里先给出一段 demo, 这是用 bert 来进行微调的文本分类模型的训练代码,代码有点长,需要安装 pytorch 环境以及下载 bert 中文的预训练模型:
import torch
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
from transformers import BertTokenizer
# 加载 BERT 分词器
print('Loading BERT tokenizer...')
tokenizer = BertTokenizer.from_pretrained('bert-base-chinese', do_lower_case=True)
sentences = ['我是谁', '我在哪', '你是谁', '你在哪', '我知道我是谁', '我知道你是谁']
labels = [1, 1, 1, 1, 0, 0]
# 输出原始句子
print(' Original: ', sentences[0])
# 将分词后的内容输出
print('Tokenized: ', tokenizer.tokenize(sentences[0]))
# 将每个词映射到词典下标
print('Token IDs: ', tokenizer.convert_tokens_to_ids(tokenizer.tokenize(sentences[0])))
input_ids = []
attention_masks = []
# 对文本进行预处理, bert要求文本需要CLS和SEP token并且需要固定的长度,tokenizer.encode_plus能够帮助我们自动的完成这些预处理操作
for sent in sentences:
encoded_dict = tokenizer.encode_plus(
sent, # 输入文本
add_special_tokens=True, # 添加 '[CLS]' 和 '[SEP]'
max_length=64, # 填充 & 截断长度
pad_to_max_length=True,
return_attention_mask=True, # 返回 attn. masks.
return_tensors='pt', # 返回 pytorch tensors 格式的数据
)
# 将编码后的文本加入到列表
input_ids.append(encoded_dict['input_ids'])
# 将文本的 attention mask 也加入到 attention_masks 列表
attention_masks.append(encoded_dict['attention_mask'])
# 将列表转换为 tensor
input_ids = torch.cat(input_ids, dim=0)
attention_masks = torch.cat(attention_masks, dim=0)
labels = torch.tensor(labels)
# 输出第 1 行文本的原始和编码后的信息
print('Original: ', sentences[0])
print('Token IDs:', input_ids[0])
from torch.utils.data import TensorDataset, random_split
# 将输入数据合并为 TensorDataset 对象
dataset = TensorDataset(input_ids, attention_masks, labels)
# 计算训练集和验证集大小
train_size = int(0.9 * len(dataset))
val_size = len(dataset) - train_size
# 按照数据大小随机拆分训练集和测试集
train_dataset, val_dataset = random_split(dataset, [train_size, val_size])
print('{:>5,} training samples'.format(train_size))
print('{:>5,} validation samples'.format(val_size))
from torch.utils.data import DataLoader, RandomSampler, SequentialSampler
# 在 fine-tune 的训练中,BERT 作者建议小批量大小设为 16 或 32
batch_size = 2
# 为训练和验证集创建 Dataloader,对训练样本随机洗牌
train_dataloader = DataLoader(
train_dataset, # 训练样本
sampler = RandomSampler(train_dataset), # 随机小批量
batch_size = batch_size # 以小批量进行训练
)
# 验证集不需要随机化,这里顺序读取就好
validation_dataloader = DataLoader(
val_dataset, # 验证样本
sampler = SequentialSampler(val_dataset), # 顺序选取小批量
batch_size = batch_size
)
from transformers import BertForSequenceClassification, AdamW, BertConfig
# 加载 BertForSequenceClassification, 预训练 BERT 模型 + 顶层的线性分类层
model = BertForSequenceClassification.from_pretrained(
"bert-base-chinese", # 预训练模型
num_labels = 2, # 分类数 --2 表示二分类
# 你可以改变这个数字,用于多分类任务
output_attentions = False, # 模型是否返回 attentions weights.
output_hidden_states = False, # 模型是否返回所有隐层状态.
)
optimizer = AdamW(model.parameters(),
lr = 2e-5, # args.learning_rate - default is 5e-5
eps = 1e-8 # args.adam_epsilon - default is 1e-8
)
from transformers import get_linear_schedule_with_warmup
# 训练 epochs。 BERT 作者建议在 2 和 4 之间,设大了容易过拟合
epochs = 4
# 总的训练样本数
total_steps = len(train_dataloader) * epochs
# 创建学习率调度器
scheduler = get_linear_schedule_with_warmup(optimizer,
num_warmup_steps = 0,
num_training_steps = total_steps)
import numpy as np
# 根据预测结果和标签数据来计算准确率
def flat_accuracy(preds, labels):
pred_flat = np.argmax(preds, axis=1).flatten()
labels_flat = labels.flatten()
return np.sum(pred_flat == labels_flat) / len(labels_flat)
import time
import datetime
def format_time(elapsed):
'''
Takes a time in seconds and returns a string hh:mm:ss
'''
# 四舍五入到最近的秒
elapsed_rounded = int(round((elapsed)))
# 格式化为 hh:mm:ss
return str(datetime.timedelta(seconds=elapsed_rounded))
import random
import numpy as np
# 以下训练代码
# 设定随机种子值,以确保输出是确定的
seed_val = 42
random.seed(seed_val)
np.random.seed(seed_val)
torch.manual_seed(seed_val)
torch.cuda.manual_seed_all(seed_val)
# 存储训练和评估的 loss、准确率、训练时长等统计指标,
training_stats = []
# 统计整个训练时长
total_t0 = time.time()
for epoch_i in range(0, epochs):
#开始训练
print("")
print('======== Epoch {:} / {:} ========'.format(epoch_i + 1, epochs))
print('Training...')
# 统计单次 epoch 的训练时间
t0 = time.time()
# 重置每次 epoch 的训练总 loss
total_train_loss = 0
# 将模型设置为训练模式。这里并不是调用训练接口的意思
# dropout、batchnorm 层在训练和测试模式下的表现是不同的
model.train()
# 训练集小批量迭代
for step, batch in enumerate(train_dataloader):
# 每经过40次迭代,就输出进度信息
if step % 40 == 0 and not step == 0:
elapsed = format_time(time.time() - t0)
print(' Batch {:>5,} of {:>5,}. Elapsed: {:}.'.format(step, len(train_dataloader), elapsed))
# 准备输入数据,并将其拷贝到 cpu 中
b_input_ids = batch[0].to(device)
b_input_mask = batch[1].to(device)
b_labels = batch[2].to(device)
# 每次计算梯度前,都需要将梯度清 0,因为 pytorch 的梯度是累加的
model.zero_grad()
# 前向传播
# 该函数会根据不同的参数,会返回不同的值。 本例中, 会返回 loss 和 logits -- 模型的预测结果
# loss, logits = model(b_input_ids,
# token_type_ids=None,
# attention_mask=b_input_mask,
# labels=b_labels)
output = model(b_input_ids,
token_type_ids=None,
attention_mask=b_input_mask,
labels=b_labels)
loss = output.loss
logits = output.logits
print(loss)
print(logits)
# 累加 loss
total_train_loss += loss.item()
# 反向传播
loss.backward()
# 梯度裁剪,避免出现梯度爆炸情况
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
# 更新参数
optimizer.step()
# 更新学习率
scheduler.step()
# 平均训练误差
avg_train_loss = total_train_loss / len(train_dataloader)
# 单次 epoch 的训练时长
training_time = format_time(time.time() - t0)
print("")
print(" Average training loss: {0:.2f}".format(avg_train_loss))
print(" Training epcoh took: {:}".format(training_time))
# 开始用验证集评估效果
# 完成一次 epoch 训练后,就对该模型的性能进行验证
print("")
print("Running Validation...")
t0 = time.time()
# 设置模型为评估模式
model.eval()
# Tracking variables
total_eval_accuracy = 0
total_eval_loss = 0
nb_eval_steps = 0
# Evaluate data for one epoch
for batch in validation_dataloader:
# 将输入数据加载到 gpu 中
b_input_ids = batch[0].to(device)
b_input_mask = batch[1].to(device)
b_labels = batch[2].to(device)
# 评估的时候不需要更新参数、计算梯度
with torch.no_grad():
output = model(b_input_ids,
token_type_ids=None,
attention_mask=b_input_mask,
labels=b_labels)
loss = output.loss
logits = output.logits
# 累加 loss
total_eval_loss += loss.item()
# 将预测结果和 labels 加载到 cpu 中计算
logits = logits.detach().cpu().numpy()
label_ids = b_labels.to('cpu').numpy()
# 计算准确率
total_eval_accuracy += flat_accuracy(logits, label_ids)
# 打印本次 epoch 的准确率
avg_val_accuracy = total_eval_accuracy / len(validation_dataloader)
print(" Accuracy: {0:.2f}".format(avg_val_accuracy))
# 统计本次 epoch 的 loss
avg_val_loss = total_eval_loss / len(validation_dataloader)
# 统计本次评估的时长
validation_time = format_time(time.time() - t0)
print(" Validation Loss: {0:.2f}".format(avg_val_loss))
print(" Validation took: {:}".format(validation_time))
# 记录本次 epoch 的所有统计信息
training_stats.append(
{
'epoch': epoch_i + 1,
'Training Loss': avg_train_loss,
'Valid. Loss': avg_val_loss,
'Valid. Accur.': avg_val_accuracy,
'Training Time': training_time,
'Validation Time': validation_time
}
)
print("")
print("Training complete!")
print("Total training took {:} (h:mm:ss)".format(format_time(time.time() - total_t0)))
# 这里走一下模型推理,用一个文本数据输入到模型中让他分类
# 要分类的文本
text = "我知道我是谁"
# 对文本进行编码
inputs = tokenizer(text, return_tensors="pt")
# 进行预测
with torch.no_grad():
outputs = model(**inputs)
logits = outputs.logits
# 获取预测结果,因为走的是多分类的接口, 所以需要取概率最高的那个作为最终的预测结果
predictions = torch.softmax(logits, dim=-1)
predicted_class_idx = torch.argmax(predictions, dim=-1).item()
print(f"Predicted class: {predictions}")
print(f"Predicted class index: {predicted_class_idx}")
上面的代码需要各位有一定的 pytorch 的知识储备,也需要了解 bert 模型的一些原理才能知道怎么预处理数据(bert 要求数据处理成它要求的格式,尤其是需要在文本中添加 CLS 和 SEP,还需要把文本都处理成固定长度,长度不够的要 padding 补全等)。 这个比较遗憾的可能不是能在特别短的时间内速成的。 不过上次跟蚂蚁的老师交流的时候,他介绍给我一个名字叫 EasyNLP 的开源项目, 这个接口用起来非常简单:
easynlp 的安装:
git clone https://github.com/alibaba/EasyNLP.git
$ cd EasyNLP
$ python setup.py install
代码:
from easynlp.appzoo import ClassificationDataset
from easynlp.appzoo import get_application_model, get_application_evaluator
from easynlp.core import Trainer
from easynlp.utils import initialize_easynlp, get_args
from easynlp.utils.global_vars import parse_user_defined_parameters
from easynlp.utils import get_pretrain_model_path
initialize_easynlp()
args = get_args()
user_defined_parameters = parse_user_defined_parameters(args.user_defined_parameters)
pretrained_model_name_or_path = get_pretrain_model_path(user_defined_parameters.get('pretrain_model_name_or_path', None))
train_dataset = ClassificationDataset(
pretrained_model_name_or_path=pretrained_model_name_or_path,
data_file=args.tables.split(",")[0],
max_seq_length=args.sequence_length,
input_schema=args.input_schema,
first_sequence=args.first_sequence,
second_sequence=args.second_sequence,
label_name=args.label_name,
label_enumerate_values=args.label_enumerate_values,
user_defined_parameters=user_defined_parameters,
is_training=True)
valid_dataset = ClassificationDataset(
pretrained_model_name_or_path=pretrained_model_name_or_path,
data_file=args.tables.split(",")[-1],
max_seq_length=args.sequence_length,
input_schema=args.input_schema,
first_sequence=args.first_sequence,
second_sequence=args.second_sequence,
label_name=args.label_name,
label_enumerate_values=args.label_enumerate_values,
user_defined_parameters=user_defined_parameters,
is_training=False)
model = get_application_model(app_name=args.app_name,
pretrained_model_name_or_path=pretrained_model_name_or_path,
num_labels=len(valid_dataset.label_enumerate_values),
user_defined_parameters=user_defined_parameters)
trainer = Trainer(model=model, train_dataset=train_dataset,user_defined_parameters=user_defined_parameters,
evaluator=get_application_evaluator(app_name=args.app_name, valid_dataset=valid_dataset,user_defined_parameters=user_defined_parameters,
eval_batch_size=args.micro_batch_size))
trainer.train()
执行:
easynlp \
--mode=train \
--worker_gpu=1 \
--tables=train.tsv,dev.tsv \
--input_schema=label:str:1,sid1:str:1,sid2:str:1,sent1:str:1,sent2:str:1 \
--first_sequence=sent1 \
--label_name=label \
--label_enumerate_values=0,1 \
--checkpoint_dir=./classification_model \
--epoch_num=1 \
--sequence_length=128 \
--app_name=text_classify \
--user_defined_parameters='pretrain_model_name_or_path=bert-small-uncased'
EasyNLP 的使用明显简单很多了, 因为它把复杂的东西都封装了起来, 不过折腾环境有点费尽, 中间遇到过各种问题。 并且文档也是不太好,我研究了好一段时间才知道怎么训练并保存中文的文本分类模型。
AIGC
大模型除了生成文字外, 还有生成图像的 AIGC, 其实我本人还没有开始参与 AIGC 的测试工作。 但跟其他同行交流过后,也大概知道了要怎么来利用 yolo 模型和 blip 模型来做这种测试,同样我也借鉴这个思路开发了一个数据挖掘工具(这个我们下篇讲数据的帖子里再详细讲解)。 我们假设去测试生成人有关的图片, 这里面常见的问题有:
- 肢体异常:多肢体,多头
- 手部异常:多指,残指
- 性别错误
- 错误特征:错误生成胡子,人种偏差
- 色情: 低俗,露点
- 其他业务问题
所以其实我们可以训练一个 yolo 模型,专门去识别人类的手部(或者直接找公开的手部识别模型),识别到手部的位置后,把手抠出来,然后再用一个 blip 模型(或者也是个 yolo 也可以)去识别这个手是否是残指,多指。 其实就是一个目标检测目标先把目标抠出来, 然后一个分类模型去识别这个目标是不是有缺陷的(跟 OCR 的思路很像。 具体怎么微调 YOLO,怎么使用 blip 我下篇讲数据挖掘工具的时候再说,总之这种自动化测试的思路差不多是这样的。)
模型测试模型的总结
总结一下这种测试方法之所以会出现,就是因为收集海量的标准问 - 答数据的成本是非常高的, 所以我们可以从线上拉到用户的输入的文案, 然后简单的通过简单的切词来匹配场景,比如用户的文字中包含了:小孩,女孩,男人,男孩,老人等等明显是跟人有关系的关键词,这时候就可以知道这是一个生成人的场景, 所以就可以把这些数据输入到大模型中, 然后我们用自己训练的模型去判断生成的图片中有没有残指,多头等已知的特别容易出现的缺陷(在 AIGC 领域中手指和头是比较出名的不容易处理,容易出问题的场景)。
所以其实我们的思路就是在测试场景中抽象出已知的明显容易出现问题的场景, 然后告诉算法什么样的图片是好的,什么样的是不好的(就是收集这些不好的图片作为训练数据),由于迁移学习的存在,可能我们只需要 1 千张图片就有比较好的场景(文本也是一样的)。 当然我们自己调整的模型,它的效果肯定没有那么好。 但我们用量来补充这个缺陷。 比如可以测试 1W 甚至 10W,用量来弥补准确率的不足。 只要样本的量足够的多, 我们就能挖掘到更多的问题。
需要注意的是这种方式不能代替人工测试的,它只能是一种辅助手段,用模型来帮助我们挖掘潜在的问题(毕竟人的精力有限,不可能测试到那么多的样本),所以人工测试,仍然是非常重要的手段。 我们一般可能人工测试 1000~5000 个样本, 机器测试 1W 个或者 10w 个样本甚至更多,用这样的策略让人和机器一起去挖掘潜在的问题。
自学习与线上的效果监控
在一些实际的业务场景里,会更加偏向线上的监控和 A/B Test 而非离线的测试。 我们先看一下什么是自学习。
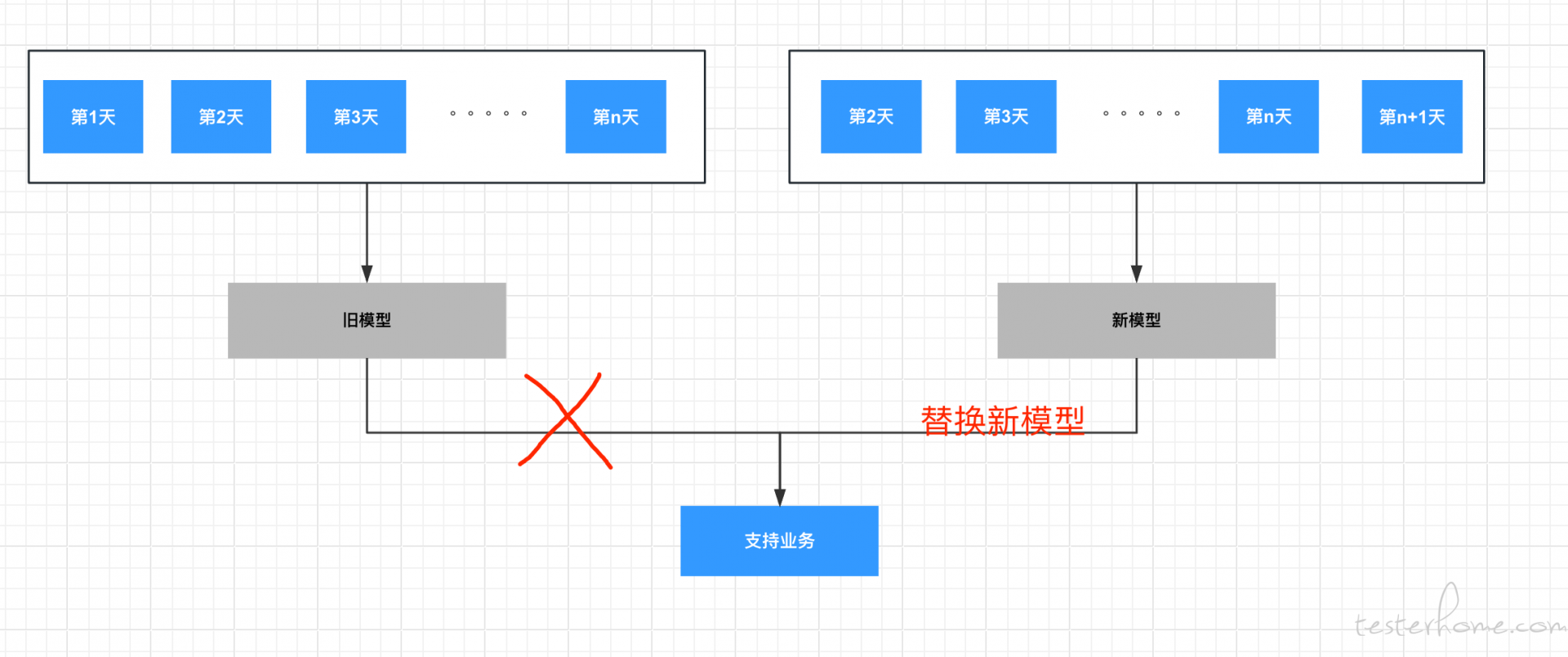
自学习是比较好理解的,在一些场景里,一个模型是不能永远都生效的,因为用户在变化, 数据也在变化。 我们说机器学习是你给他什么样的数据,他就会学习出什么样的效果。 所以当用户和数据变化后,我们也需要用最新的数据来更新模型以保证它的效果。 通常我们说这种场景的特征是随着时间发生巨变的, 所以我们也需要一定频率的自学习系统来更新模型。 但这个更新模型的过程其实是比较严谨的。 它可能需要经过一个数据闭环的流程:
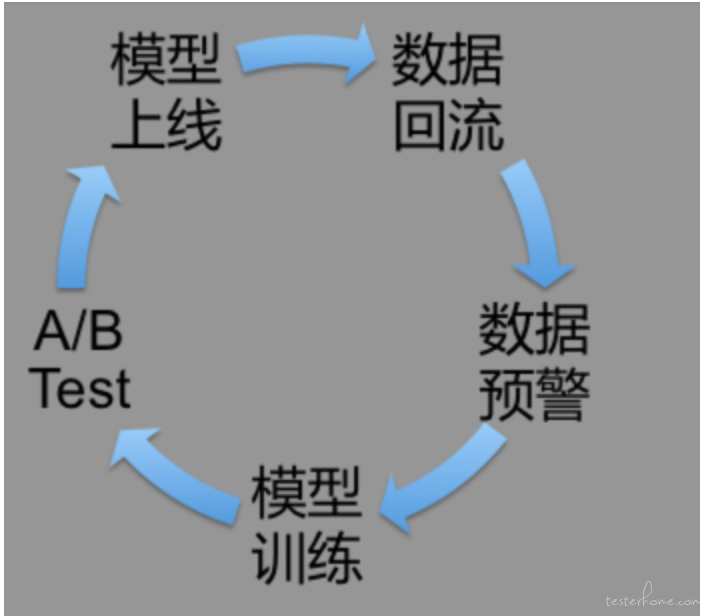
- 数据回流:也可以说是数据采集, 需要把数据采集下来才能加入到后续的模型训练中。
- 数据预警:需要对采集的数据进行测试, 因为数据本身可能也会出现质量问题, 毕竟它经过了很多道程序,每一道程序可能都会让数据出现偏差, 一旦出现偏差就会直接影响后面的模型。 这里通过会通过 flink 或者 spark 这类的手段来对数据进行扫描。
- 模型训练:自学习的过程, 利用最新的数据训练出新的模型。
- A/B Test:新模型虽然已经训练出来并且可能也经过了效果的评估, 但仍然需要 A/B Test 来慢慢的让新模型取代旧模型。比如可以先把 10% 的流量打到新模型上,而其余的 90% 仍然打到老模型中, 持续对比新老模型的效果。 原则上新模型的效果不能衰退才可以。 就这样慢慢的切换流量到新模型上, 最终实现完全的取代。
- 模型上线:模型上线,对接流量, 用户的数据通过模型的预测又产生了新的数据。
- 数据回流:上一步的数据在拼接好 label 后(就是之前说的答案,也是数据标注的过程, 一个数据需要告诉算法这个数据到底是否是欺诈行为, 算法才能去学习相关的规律。所以这个数据标注过程是所有监督学习都绕不过去的坎,因为大部分标注行为都需要人力介入,无法自动化完成)经过数据采集系统重新进入循环产生新的价值。 这样我们就实现了数据闭环。
凡是应用了人工智能的团队,都在追求构建出上面的数据闭环系统,形成良性循环。 而在这个数据闭环系统里,根据业务形态的不同, 它的周期可能也是不同的。比如在反欺诈系统里,最后一步的拼接 label 不是可以自动化完成的, 需要人工介入(一条交易记录最终是否是欺诈行为,需要人来判断,也就是数据标注的过程还是人来完成的,这就导致数据标注的成本比较高), 并且骗子们的欺诈手段也不会天天都更新,所以它做不到也没有必要做到高频率的自学习。 而推荐系统就完全相反, 首先它的数据标注过程是完全可以自动化的,因为只要用户点击这个广告/视频/文章/买了产品 了那就算用户对它感兴趣了,所以不需要人来介入标记数据。 再一个是推荐系统必须高频的自学习, 因为它就是之前说的典型的数据随着时间发生巨变的场景,用户的兴趣会随着时间,社会热点发生急剧的变化。 所以自学习必须高频, 高频到什么程度呢, 可能高频到根本来不及做离线测试的程度。 对的,没有时间给测试人员在线下做效果测试了。 模型的时效性很短,等测试人员磨磨唧唧去测试完后,模型的时效已经过了。 所以 A/B Test 才会显得那么重要。 同样对线上模型的效果监控也变的额外的重要。尤其往往大的推荐系统里,模型是非常多的。 可能会为每一个客户都定制一个模型, 比如给阿迪定制一个广告推荐模型, 耐克又一个, 李宁也有一个, 每个大的广告客户都会有一个独立的模型为他们服务。 所以要在线上组建一个比较庞大的实时效果监控系统, 一旦效果发生衰退, 需要及时告警并处理, 因为这背后都是钱, 跟客户都签了合同,要求要保证转化率。所以假设我用当前的预算投放了一波广告后,没有达到预期的效果客户是不答应的,那么就要及时对效果进行监控。
结尾
这一篇写到这就差不多了, 想了想应该覆盖到我这些年里跟效果测试有关的大部分场景了,但 AI 场景其实还有很多其他的,只是我都没有解除大了 ,毕竟 AI 这个领域太大了, 我能接触到的东西还是有限。 而且其实这次主要也是讲了方法论, 实操的东西并不多, 尤其是在数据处理上的实操不多。 做 AI 测试大部分时间都是跟数据打交道的, 只有解决了数据问题, 才轮得到今天讲的这些方法论。 这些数据相关的东西就放到下一次写吧, 想想要写的东西也挺多的, 得讲数据标注的事情, 得讲 spark,得讲 ffmpeg,得讲 opencv,想想就感觉有点累。。。



 。
。
 :
: