我感觉自己说的拉垮了:
测试中发现了一个使用 Integer 作为自增 id 的,当数值过大时,自增 id 开始变为负数
测试的时候先抓接口查看报错情况,再查询服务器日志(撒谎的),定位到报错的原因,发 bug,然后转给相应的开发,最后跟踪没问题了关闭 bug
3.把该问题加入到回归测试用例里面,对其他数据库的自增 id 进行排查
面试官:你在这个没起到多少作用呀
我:???
求问基础扎实的大神,这类问题该怎么回答
我觉得可以朝着三个方向拓展回答。
第一个方向,往业内大厂开源的类库引发的 bug 说,这类 bug 往往比较知名,有可能就能引起面试官的共鸣,例如 druid,fastjson 等引起的性能的或安全的 bug,这些是如何影响你们的业务的,你们是怎么排查出来的,怎么解决的。
第二个方向,往 jvm,操作系统层面说,比如莫名奇妙 cpu 利用率 100%、GC 异常、OOM、socket 连接数过大等,如何分析这些问题,有什么样的工具可以用,这些问题如何解决的,怎么验证是否得到了解决等。
第三个方向,往业务、需求、用户行为方面说,如何发现这些低复现率 bug,你的埋点方案是什么,都采集了哪些数据,如何进行的数据分析,出现 bug 的根因是什么,以后如何避免再出现类似的 bug
我没太弄清楚面试官想得到什么答案,他的意思是你没起到多少作用,但是你不是说把问题原因定位到了么。 难道他想你直接改 bug 么哈哈哈。 可能你这个问题比较简单吧,所以面试官不以为然。 一般回答这种问题都是往高逼格上回答。 就找你印象里最有技术含量的 bug 说就行了。 回答方向上主要经清楚测试过程,排查过程和验证过程,中间多讲讲怎么帮助研发排查问题的。 如果能知名的开源软件的 bug 就更好,比如我一般会说 k8s 的 bug。 因为这个显逼格哈哈哈。 比如:
我们在测试环境中发现服务不稳定,总是很卡。甚至请求失败。通过监控 k8s 集群上发现有 2 个节点的 cpu load 高达 200,但是在这两个点上启动的服务其实很少,而且 CPU 使用率也很低。通过 ps 命令发现当前节点的进程数量有好几千个,所以初步判断是由于进程过多导致的进程上下文切换造成的 cpu load 变高。 找到若干个进程查看其 stack 发现都是 fork from xxx 的进程,怀疑都是由某个进程 fork 出来执行 shell 命令的。 查看 kubelet 的日志发现有很多的报错信息显示 du 命令运行出错。 不知道跟这个有没有关系,所以到 github 上查找是否有相关问题。 最终找个有人提过相关的 issue。原因是 k8s 1.8 版本中 kubelet 对外暴露的 metric 接口是给普罗米修斯对接监控用的。他会周期的执行收集监控数据的命令。 其中会执行 du 命令来收集磁盘信息数据, kublet 1.8 使用的是老版本的收集功能,有一个偶发的缺陷是调用 du 命令会出错。所以 kubelet 中会一直抛出这个异常,而因为一直出错所以一直重试,所以才会有那么多 fork 出来的进程执行 du 命令导致 CPU load 变高。 所以按照 github 上提供的 workaournd 我们把 du 命令直接删除。 这样找不到 du 命令只会抛一次错但是不会导致不停的重试。 后面我们找到了不少这样的低版本 k8s 的 bug 导致的产品不稳定问题,甚至直接影响到了生产环境。所以在 19 年的时候升级到 k8s 1.16 版本后就彻底解决了这个问题。
这个 bug 是不是听起来就很有逼格了。 引申下去可以跟面试官探讨一下这种开源产品的 bug 你们怎么处理的问题。
ps:面试这玩意都是吹着唠的, 有些 bug 可能不是你处理的,但是只要你知道细节,不怕面试官深问,你就拿来说是自己处理的就成
楼上的 k8s 走天下
印象深指的是难发现、难处理、较稀有的 bug,例如:通过工具扫描发现 php 的版本漏洞绕过证书验证直接控制用户系统,或者说一些事件比较大条的线上 bug,导致损失的。

我也提供一个例子。上家公司有个很简单的点赞取赞功能,测试时正常点赞取赞功能正常,但是用 jmeter 去压这 2 个接口,虽然都是取赞点赞,但是最终的点赞数却一直变大,不是理想的 0/1。然后后面就开始扯定位了,开发的代码里锁没有加好,队列消费有问题。。。。。
https://testerhome.com/topics/16406
这个是我记忆比较深刻的一个 bug。当时在对某个接口进行压测的时候分析总数据对不上,开发一直没有头绪。经过测试结果分析,代码排查,最后帮开发定位到了原因。
感谢大佬们,学到了很多了
楼主的回答主要还是没体现技术含量。一般问这个问题其实是想通过这个例子了解你的技术水平,以及是否能说得清 bug 背后的原理、原因及解决方案。
如果沿着楼主这个例子,作为面试官期望听到:
1、为何会出现这个问题,是 mysql 某个版本的 bug 还是官方有明确说过会出现这个问题?官方给出的正确用法是什么?
2、开发的具体修复方式是怎样的,改了什么代码或者配置?这个改进方案会不会只是掩盖问题,而非解决问题?(比如 Integer 改为 Long ,延迟问题的发生)
3、后续怎么把这个变成规范或者流程,尽可能保障以后其他人、其他项目不会再踩同样的坑?
之前遇到一个 bug,购物车增加商品时,当遇到有小数的商品价格,购物车的金额显示了很长的小数,最终定位到是 JS 的浮点数相乘导致的精确度不准确,属于语言本身问题,可用其他方式规避,例如 *100 后再计算等等,不过对于价格类的更推荐是后端去计算。
以前发现一个 bug,开发找了 1 个周没找到原因,后面开发请假,帮他修改了打了个补丁,后面开发请吃了顿饭。哈哈
能体现技术含量的,比如性能问题,可靠性问题,安全性问题,底层问题等,你怎么推动解决这个问题的。进一步讲会不会存在类似的共性问题,总结出什么经验分享给团队。
最好讲下你是如何通过技术手段,一步一步去分下排查原因的。
记一个自己写的 bug(对全局变量,类变量生命周期不理解导致的)
有个变量叫 today,是格式化后的今天日期,很多地方用到,我就把它封装到了工具类的全局变量中。
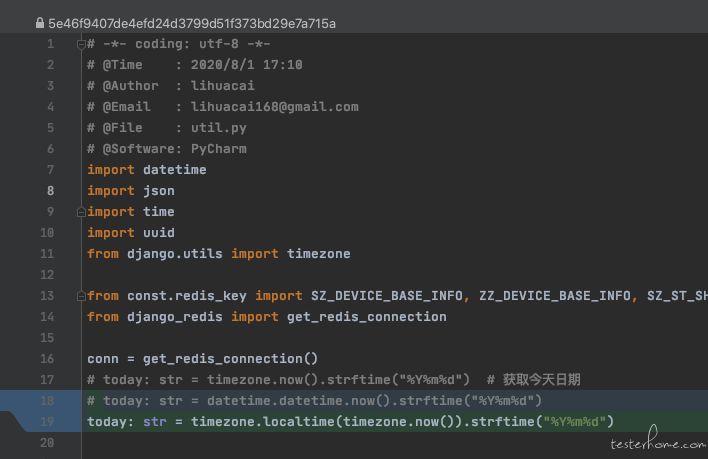
本地调试没问题,结果是正常,在服务端跑也是正常的。可是第二天获取的日期就不对,还是前一天的日期。
难道是缓存的问题?重试服务试试,结果还真的就行了。搞定,笑嘻嘻~
可是到第三天,怎么又是变成了前一天的日期???真的是见鬼了。
本地调试看看,代码没问题啊,能正常获取。这到底是怎么回事啊!
难道 Python 标准库出问题了?不会吧。换 Django 日期工具类试试。
推送代码,重新部署服务,看看获取结果,一切正常。妥妥的。这下应该不会再有问题了吧?
又是一天早上,哦豁,怎么结果又是获取了昨天的日期。
我不信,重启服务。嗯,结果是对的,果然重启能解决 99% 的问题。
就这样,通过定时任务每天重启服务的方式过了几个月。
直到有一天,要获取一个当前时间戳的变量,也是很多地方用到。代码大概是这样
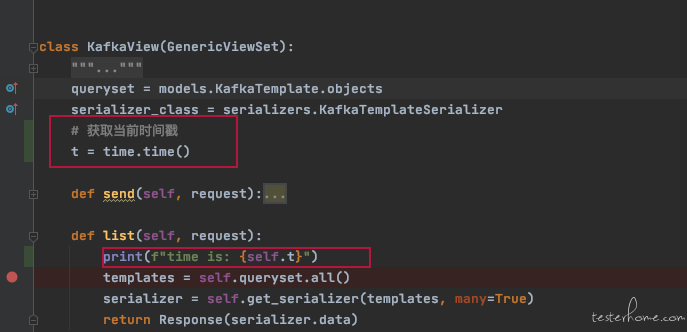
一看日志,恍然大悟
[12/Jan/2021 21:17:15] "GET /api/kafka/config/ HTTP/1.1" 200 216
time is: 1610457411.562096
[12/Jan/2021 21:17:26] "GET /api/kafka/template/ HTTP/1.1" 200 5838
time is: 1610457411.562096
[12/Jan/2021 21:17:29] "GET /api/kafka/template/ HTTP/1.1" 200 5838
time is: 1610457411.562096
[12/Jan/2021 21:17:31] "GET /api/kafka/template/ HTTP/1.1" 200 5838
可以看到打印的 t 一直是没变化的,但日志时间是不停变化的
t 是类变量,并不会在 list 方法结束后就释放内存,然后下次请求进来重新获取。而是程序重启之后才会重新获取。
之前 today 那个坑不容易看出来,因为是日期,隔天才变化。
你从另一个角度看,就是专精某一个领域。 这年头不都说要成为领域专家不要做杂而不精么。
而且我好像写过挺多其他的类似自动化测试啊, 持续集成啊,大数据啊之类的东西。 我也不是除了 k8s 什么都不会。 只不过我最擅长 k8s 那我就总拿 k8s 来说事呗
还是要说清楚和需求的关系,和开发的关系,自己的工作流程和关键技术难点,最后还要强调他人的合作。
套路,千层套路。
补充一下,这个不是语言的问题,是本身浮点数精度有限造成的,比如,每个语言都有这个问题,比如:https://draveness.me/whys-the-design-floating-point-arithmetic/
所以如果要做金额类精确计算,要不全部转整数进行计算,要不用各个语言提供的科学计算库(如 java 的 BigDecimal)。
所以说,这道题考的是语文
请教下,这个问题你说是 k8s 1.8 版本的问题,后面是升级到 1.16 版本解决了,为啥是高版本升低版本?可能是我没理解,求解,感谢大佬

这种问题,总归要是耗时间,耗精力,多学习,多合作的才是高逼格。
楼主确实做的不错,不过在后面两点不涉及,可以换个 case 说说