业务背景
系统中大部分接口的数据是实时处理的。但其中有一个接口由于数据量越来越大,而且请求持续时间短,因此会导致短时间内数据并发量上升,从而带来处理性能方面的风险。于是决定对该接口数据改为异步处理。
改造方案
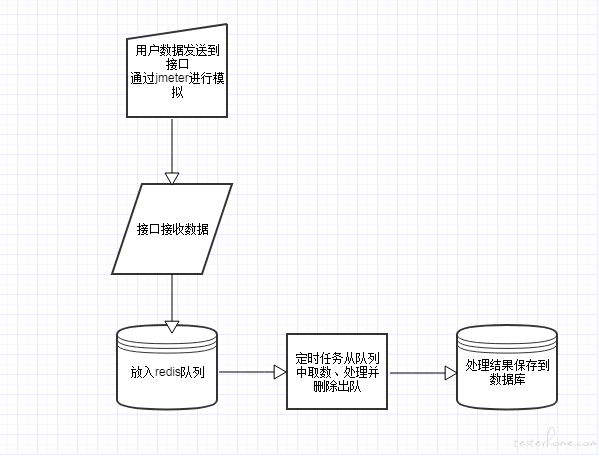
由于这部分数据对于实时性要求不高,因此接收到该接口数据后,放入 redis 队列中,并启用一个定时任务批量处理队列中的数据。定时任务的执行频率、单次执行的数据量可根据实际情况进行调整。
处理流程如下:
测试方法
编写 jmeter 脚本,对该接口进行一定时长的压测,并最后统计 jmeter 发送的成功请求数、接口接收的实际请求数、最终处理入库的请求数,评估该处理方案是否能保持数据完整。
预期结果:
所有数据可以在预期时间内正常处理并正确入库。
过程中发现的 bug
1. jmeter 发送的请求数量、接口接收的数据都是 8W,但最终任务完成后入库的只有 6W。其中四分之一的数据丢失。
问题分析
1.1 数据从 jmeter 发送到接口时是否产生了丢失?
经过统计对比,jmeter 产生的数据和接口接收的数据量是一致的,不存在丢失的情况。
1.2 是否存在重复数据,导致入库时产生了去重?
- 检查 jmeter 脚本,已对关键字段进行了时间戳 + 随机数的参数化,产生重复数据的几率应该不存在。
- 收集服务器接口端的日志,并对关键字段进行提取,最后放到 Excel 中删除重复数据,发现重复数据不存在。
因此可以排除重复数据的因素。
1.3 是否队列处理逻辑存在问题?
经过日志分析,发现部分批次日志里没有更新到任何数据:
如下图示,正常情况下每次任务可以更新 100 条数据,但任务执行到后期,开始出现很多更新数据为 0 的情况:
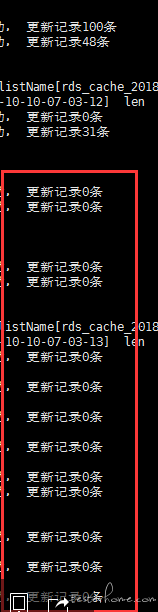
与开发人员讨论并查看这部分代码, 更新数据为 0,代表这批数据都是重复的,无法入库。与上面 1.2 中排除了重复数据这一结果产生了矛盾。
进一步分析数据:
- 总的数据量中丢失了四分之一,没有入库。 很可能这四分之一数据没有被处理即被出队。
- 在批次日志里,部分批次的数据无法入库。 很可能是同一批数据在处理完成后没有正确出队,导致被重复处理。
总结分析: 可能是入队、出队的逻辑存在问题。
问题定位:
带着上面的疑问排查相关代码,发现入队、出队都是从队列的右边开始操作,导致在取数、处理、出队的过程中,新的数据在同一个方向入队,导致位置发生变化,从而产生错误。
获取前 100 条数据进行处理:

处理完成后,将前 100 条数据删除出队:

与开发人员核对该部分代码,确认问题并修改为左侧入队、右侧出队。问题解决。

2. 经过问题 1 的修复后再次测试,发现 8W 条数据中,仍有几十条数据丢失。
问题分析:
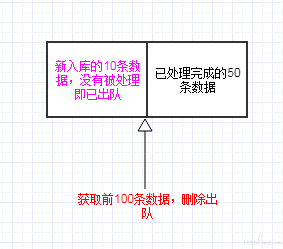
进一步分析取数、处理、出队的逻辑,发现如果数据总量不足单次处理总量时,出队时没有指定对应的相同的数量,导致少量数据仍然在没有处理的情况下就被删除出队。
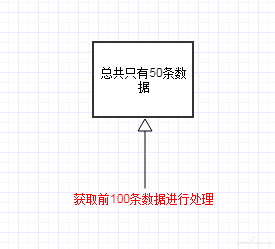
如设定的单次处理能力是 100:
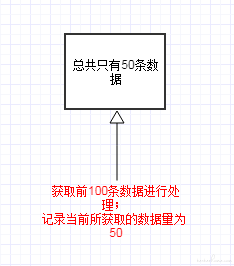
当前数据总量为 50,则取前 100 条数据进行处理时,获取到的数据是 50.
数据处理完成后,将前 100 条数据删除出队。 此时如果恰好有新的 10 条数据已经入队,则获取到的数据是 60,从而将新入队未处理的 10 条数据错误地删除出队。
修复方案:
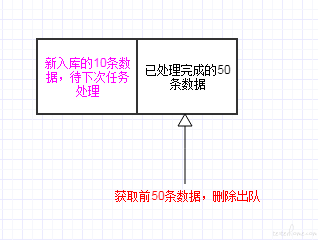
在获取数据时,记录下当前获取的数据量大小 N ; 数据处理完成后,将队列左侧前 N 条数据删除出队。
取数时记录下所获取的数据量:
只对已获取的数据进行出队:
验证测试:
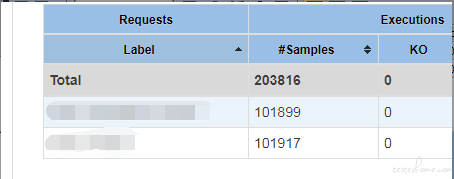
经过再次测试,所有数据均能正确入库。
jmeter 数据统计:
数据库数据统计:
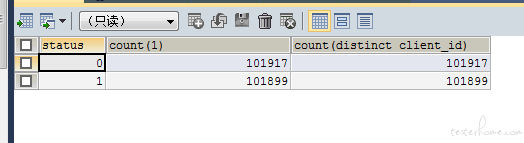
问题总结:
- 制定此类需求的测试方案时,一定要做好数据独立性、并发量、并发时间等方面的评估。
- 测试结果数据必须严格跟踪,从数据产生到数据沉淀的每个步骤的数据量都需要确认保持一致。
- 在时间充足的情况下,需要对开发人员的设计方案进行充分的评审和代码 review。
- 除了对业务熟悉外,也需要对技术方案有足够的理解,才能挖掘技术方案设计、实施各环节可能产生的 bug。
我在【TesterHome 系列征文活动 | 有意思的 bug】https://testerhome.com/topics/33905 等你,一起 day day up!