Selenium 结合 Docker-Selenium 镜像进行 Web 应用并发自动化测试
一、前言
- 最近一直在还去年的技术债,去年我们测试团队投入一大堆测试技术,但没有多少个是做精的,那今年的目标就是做到极致,去年团队落地了 Web 和移动端的自动化测试,但随着用例的增加,执行自动化脚本的时间越来越长,我们还需要做快速迭代的,很多时候一天还可能发几个版来响应客户的需求,那面对频繁地发版。自动化测试的支撑就应更加高效,所以就想到落地并发自动化测试来提高自动化测试的执行效率,但对于 web 应用,一台机器上跑多个浏览器的时候,对于业务交互时也比较麻烦,而且一种浏览器在一台机器上一般只有一个,那要做并发就要多台机器,问题在没有那么多资源的情况下要怎么做,正好最近翻其他技术网站的时候翻到Docker-selenium,通过 selenium gird+docker 容器很好地把多台分布式容器利用起来,更充分的利用机器的资源,这样 web 的并发自动化测试就可以落地了,并解决了在多个浏览器跑兼容测试的难题
二、操作过程
先说明一下具体的并发架构
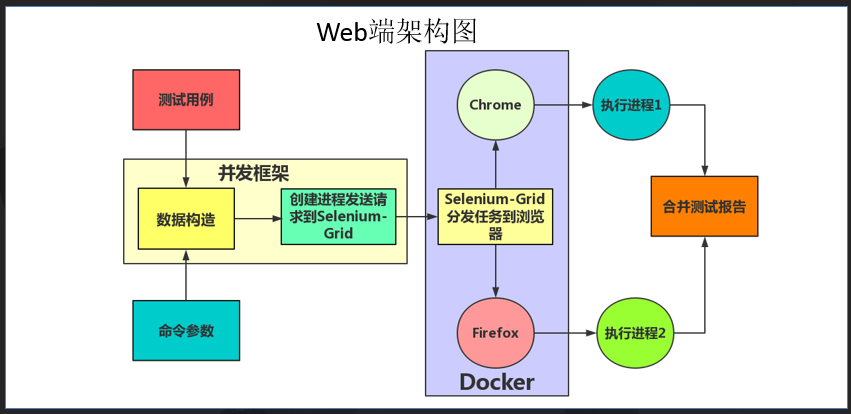
自动化具体执行的流程
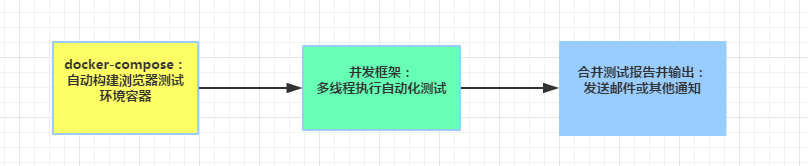
第一步:docker-compose 自动构建浏览器测试环境容器
首先还是先看一下前言中的链接如何使用 selenium gird+docker,对于 selenium gird 的容器的启动,可以用 docker-compose.yml 做容器自动编排,这样就不用手工一步一步去启动容器和 link 了
具体的 docker-compose.yml 描述
docker-compose.yml
hub:
image: lunkrtech.rd.mt/wqzhou/selenium-hub
ports:
- 4444:4444
firefox:
image: lunkrtech.rd.mt/wqzhou/node-firefox-debug-zh
ports:
- 5901:5900
links:
- hub
chrome:
image: lunkrtech.rd.mt/wqzhou/node-chrome-debug-zh
ports:
- 5902:5900
links:
- hub
chrome2:
image: lunkrtech.rd.mt/wqzhou/node-chrome-debug-zh
ports:
- 5903:5900
links:
- hub
其中 hub 就是 selenium gird 的容器,启动的时候使用 4444 端口,其他的是浏览器的镜像,而且这里也说明一下浏览器容器的 5900 端口,在 docker.io 获取浏览器镜像时,会有 debug 版,debug 的话是可以通过 VNC Viewer 连接映射的端口来查看调试浏览器和用例的具体执行情况,一般也建议直接用 debug 版,上面分别用了 2 个 chrome 和 1 个 firefox 的容器集群构建成分布式的 web 自动化测试环境
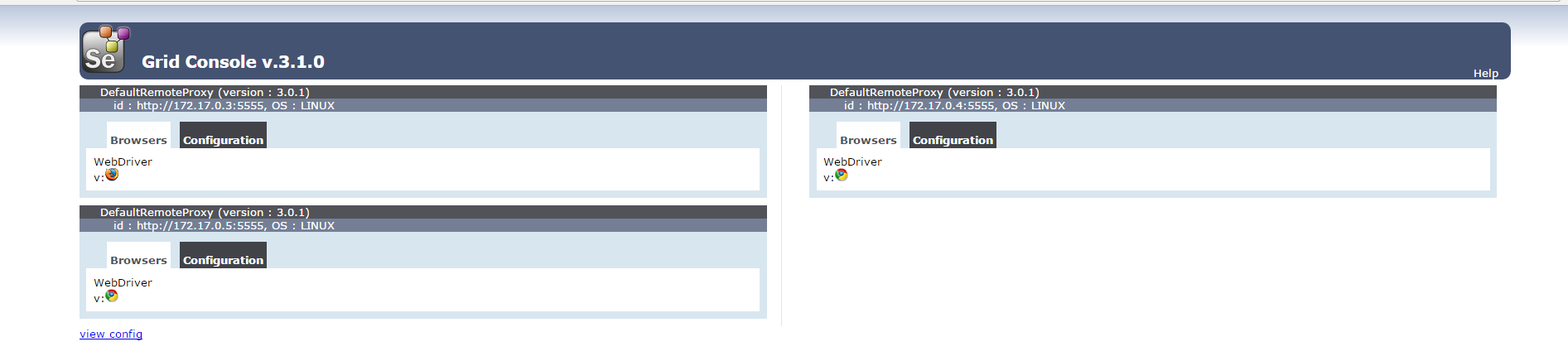
启动完整之后打开 selenium gird,就能看到具体浏览器容器的启动情况,当然,这一步也是要做到自动检查是否启动成功的
第二步:并发框架设计
- 并发的框架也是利用了 python 多线程的方法去实现的,其实具体的思想可以参考简单入手移动端并发自动化测试,不过比起这个当然是有改良的,之前用了 bat 脚本,这样执行的时候一旦并发多了总是弹窗口,显然就不好用了,后面就结合 robot 的 tag 来改良了并发框架
- 首先是 robot 的测试用例或测试套件分别贴上 tags,代表分布在不同的容器上执行,其中 node1 和 node2 在远程容器中执行,所以要加上 remote_url,local 是指在本地执行,本地执行还是必要的,像一些上传本地文件的操作,放到远程机器上是执行不了的,所以保留本地执行
*** Settings ***
Library Selenium2Library
*** Test Cases ***
open_baidu
[Tags] node1
Open Browser https://www.baidu.com firefox remote_url=http://lunkrtech.rd.mt:4444/wd/hub
sleep 6
[Teardown] Close Browser
open_lunkr
[Tags] local
Open Browser https://www.lunkr.cn chrome
sleep 3
Wait Until Page Contains Element id=setting 3
[Teardown] Close Browser
open_coremail
[Tags] node2
Open Browser http://www.coremail.cn chrome remote_url=http://lunkrtech.rd.mt:4444/wd/hub
sleep 6
[Teardown] Close Browser
tags 标记好用例之后,那就是并发框架的设计了,核心代码如下:
def run(arg):
os.system(str(arg))
threads = []
testsuite=sys.argv[1]
tags=sys.argv[2]
taglist=tags.split(',')
for tag in taglist:
cmd='pybot -i {0} -o .\\resultDir\\output-{0}.xml -l .\\resultDir\\log-{0}.html -r .\\resultDir\\report-{0}.html {1}'.format(tag,sys.argv[1])
t= threading.Thread(target=run,args=(cmd,))
threads.append(t)
-------这里省略产生多线程的代码-----------
os.system(u"rebot --output .\\resultDir\\output.xml -l .\\resultDir\\log.html -r .\\resultDir\\report.html --merge .\\resultDir\\output-*.xml")
脚本 robot_mutil_dev.py 接收两个参数,第一个,执行的测试套件或文件夹,第二个,以逗号分隔的多个标签,然后有多少个标签,就启动多少个线程根据不同的标签执行 pybot -i tag 的命令,至于怎么使用 python 的多线程这里就不用多说了,大家估计比我还熟悉,最后所有自动化测试的线程都结束之后执行 rebot 的命令来合并自动化测试报告
三、执行过程演示
具体的执行过程就是执行 python 脚本就好了,当然我们可以用 jenkins 来做自动构建触发自动化测试的执行,jenkins 的流程可参考之前写过的一篇,
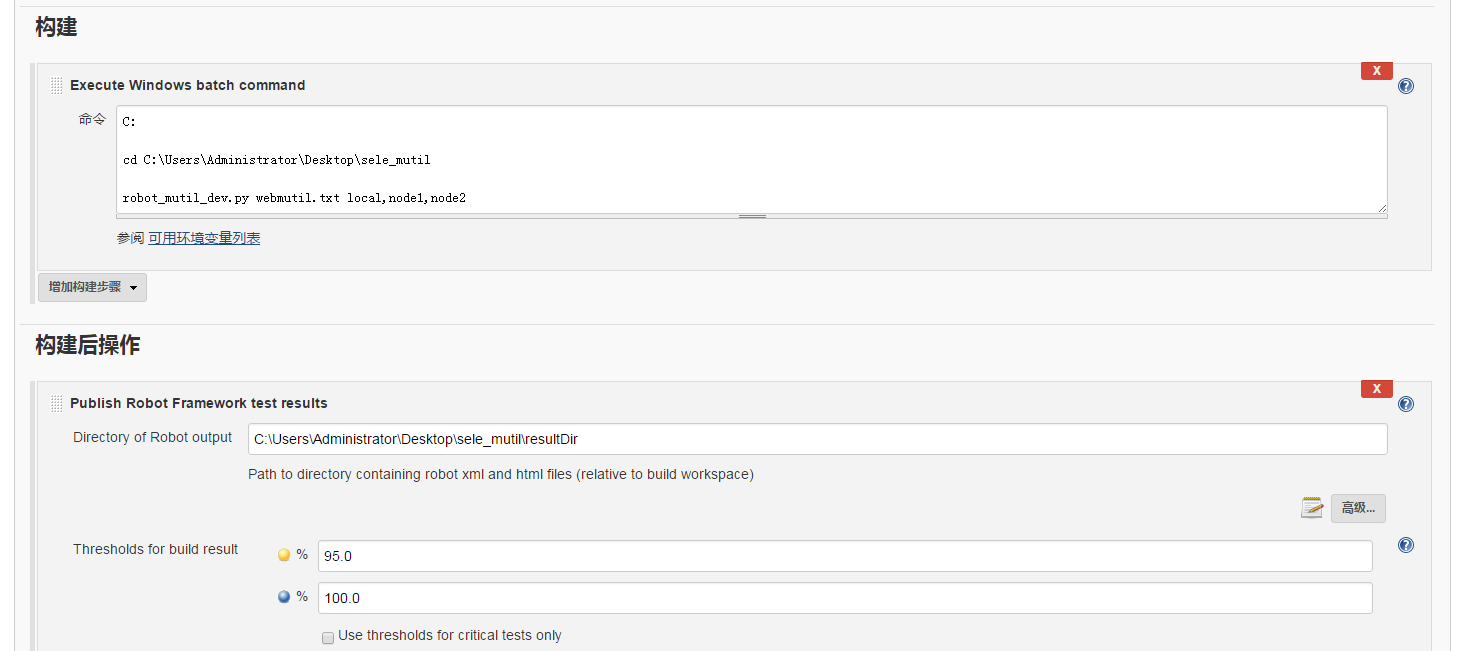
其实就是执行robot_mutil_dev.py webmutil.txt local,node1,node2,webmutil.txt 是测试套件,后面的是刚才标记的 tags执行过程:

上面有 2 个浏览器就是通过 VNC viewer 来连接到容器中查看远程浏览器的情况的,在连接到 selenium gird 的时候,gird 会自动判断哪个浏览器是空闲的,那 gird 就会把用例分配到对应空闲的浏览器中执行
大概并发的自动化测试就实现了,当然这里还有一个注意的地方,就是执行用例失败之后的截图,如果是多线程执行的话,截图也是多线程的,线程 1 产生的截图 1 命名为 selenium-screen-1.png,线程 2 也会产生的截图 1 命名为 selenium-screen-1.png,那这样线程 2 的截图就会把线程 1 的截图给覆盖了,那解决办法是,既然用到线程,那肯定有线程或进程 id 的,那就在图片命名中加一个线程 id 号就能解决问题了,具体的就是在 selenium2library 中的_screenshot.py:
def _get_screenshot_paths(self, filename):
if not filename:
self._screenshot_index += 1
pid=os.getpid()
filename = 'selenium-%s-screenshot-%d.png' % (pid,self._screenshot_index)
else:
filename = filename.replace('/', os.sep)
那这样就万事大吉了,执行完测试之后具体生成的文件,在 jenkins 把对应路径配置好上传必须的文件就好了:
最后一步当然是执行完成以后看到的测试报告
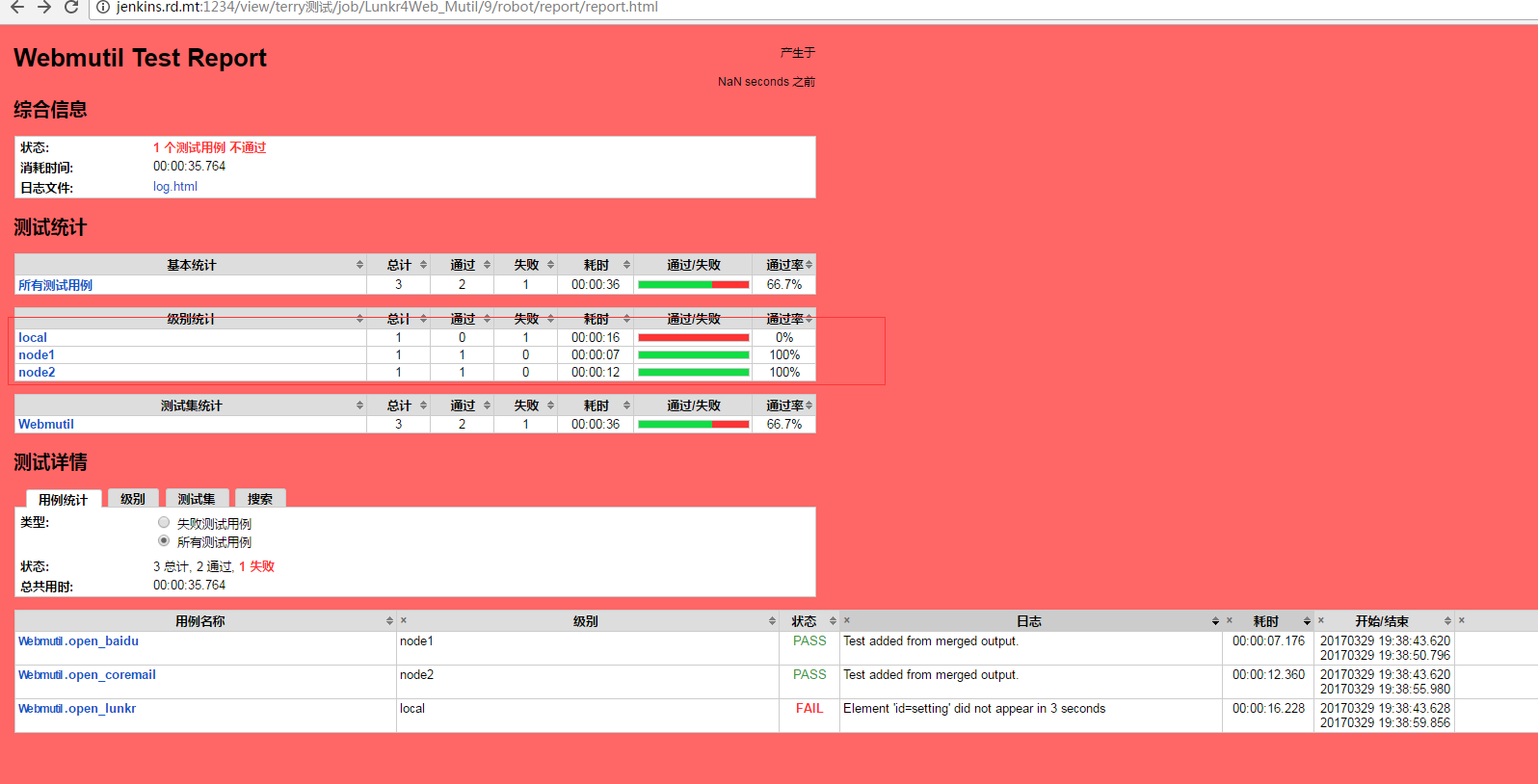
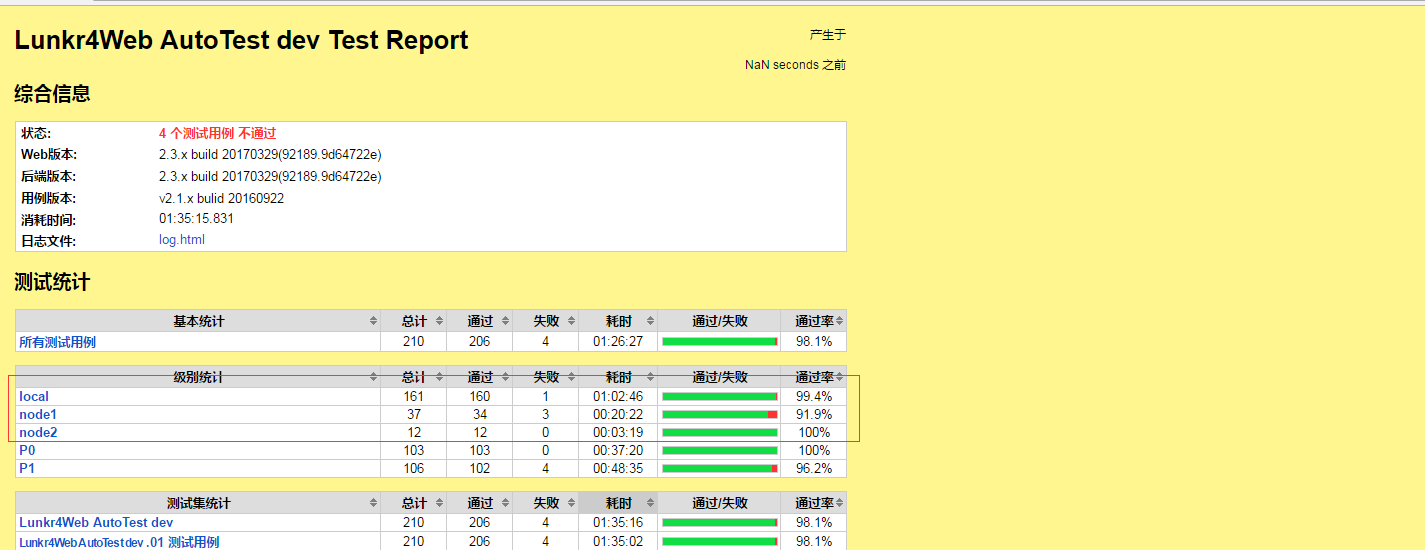
也可以从测试报告的 tags 中看到,有多少个用来在对于的 tags 执行的,而且在具体的用例日志中也看到报告是通过合并得到的,大致的过程就是这样子啦在我们自己产品的使用中,有具体的效率对比

提升的速度不多,原因是我分配到各节点的用例不均匀,但这个起码从本质上提高了自动化测试执行的效率,只要分配好执行的用例,效率肯定会很明显的提高的
四、最后说几句
前些天写那篇简单入手移动端并发自动化测试其实是个未成品,后面我们测试团队也按照本文的思想将并发框架改良,也很好地实现了移动端的并发自动化测试,当然之前还看到小红书的那个,我们现在也计划做成那个样子,docker 能很好地发挥资源优势,大家都可以多结合 docker 去做设计测试解决方案
还是回到那句,去年做了一大堆技术,今年就追求做到极致,其他还不仅是自动化测试,像我之前写的那个用Anyproxy+Moco做的 mock 服务器,我自己都将那个服务器迭代了 5 个版本了,放弃了 moco 和分离了数据,服务器的操作更加灵活,过几天有空的话可能也会继续分享一下我的 mock 服务器改良版,还有接口自动化测试的,以前一直是苦于环境,有很多测试数据是一次性的,那现在可以用 docker 对接口测试环境进行管理,执行测试或重现问题时可以自动构建环境,结合微服务的思想将数据和程序分离,然后,这样一次性的数据也可以多次使用了,所以今年就是要把去年的一大堆东西做到真正高效地解决测试的难题以既能保证质量,又能快速迭代地去响应客户需求,争得更多的市场,好吧,说那么多,希望大家也一起加油,把 2017 年做得极致,谢谢

