自动化工具 测试服务化小试-RobotFramework 测试库云构建
前言
- 最近一段时间在研究测试服务化和测试智能化的一些知识,每天都在翻论坛翻帖子,测试服务化和测试智能化是目前测试行业的大趋势,服务化如云测,浏览器测试环境云,智能化如图像识别,还有论坛有些小伙伴用到机器学习作为测试方案的一个技术载体,日新月异的发展,所以我也找个自己比较熟悉的方向来做一下这两方面的实践,这次主要是分享测试服务化中的一个小点:RobotFramework 云服务化的实践
测试服务化
一、测试需求分析
-
RobotFramework(后称 RF)是很多测试人员的挚爱,包括我,虽然用过许多测试框架,甚至自己也实践开发过,但 RF 扩展性是我最喜欢的,用过 RF 的朋友应该知道,RF 是通过导入本地的测试库来支撑整个测试过程的运行,所以这样就会带来一些问题,比如:
- 1、更换测试执行机器时或重新部署 RF 时往往需要重新下载和导入原本使用的库
- 2、一些自己和业务结合而写的测试库每次维护后需要其他使用到测试库的小伙伴将维护后的测试库重新导入
- 3、有部分场景或用例需要用到类型相同但版本不同的库,比如用例 A 需要 library1 的 1.0 版本,用例 B 需要用道 library1 的 1.1 版本(场景比较少见,但还是会有)
- 4、有部分库在机器 1,有部分在机器 2,是否可以用一个服务把所有的机器上的库都关联服务化起来?
面对上面的一些问题,我在想是否可以将测试库这一块资源给服务化,用云的形式来承载,答案当然是可以的,那接下来就是设计实现
二、测试设计
1、技术预研:
- 要能提供云服务的能力,这里肯定涉及到远程调用的,对于 RF 的远程调用,大家可能都知道有 robotremoteserver-基于 SimpleXMLRPCServer 实现的一个 RPC 远程调用服务器,看了网上的很多例子,大部分是这样用的,在目标机器上启动远程服务器,并将要调用的测试库实例化后,在目标机器上执行测试,简单说就是库在那里,就在那里执行测试
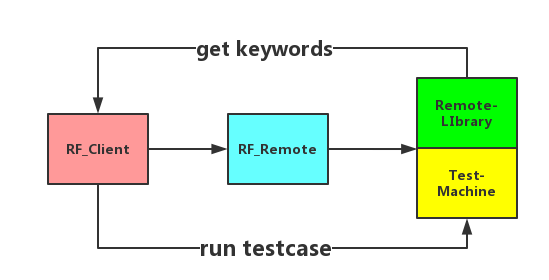
-
上面的方式有个大毛病,比如同时实例化了 Selenium2Library 和 AppiumLibrary,用上面的远程调用方式是通过一个新库去同时继承父类库来实现远程调用,这样一来会带来问题:
- 1、多重继承会存在父类库的冲突,比如 Selenium2Library 和 AppiumLibrary,也就是说你不能同时用这两个库
- 2、不够能做到自定义的去选择导入那些库,必须重新实例化并且要另起服务后才能导入
太不人性化了,脑洞放开一点,既然可以作用在目标机器,也就是说其实可以将测试库独立分离开来管理,形成自己的一套服务,也就是说可以这么玩:
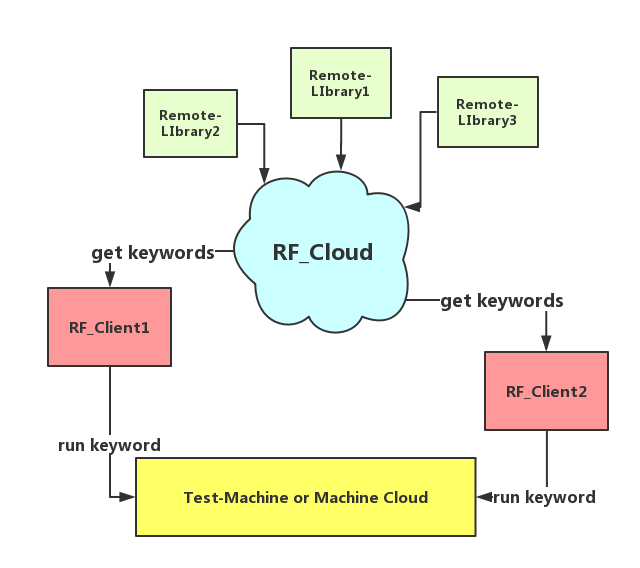
有了上面一套预研结论之后,就可以开始设计实现的方案
2、设计方案:
| 方案 | 描述 |
|---|---|
| 架构方案 | 采用 C/S 模式,客户端参照 Remote.py 实现,服务端参照 robotremoteserver 实现 |
| 调用方案 | 通过客户端带特定的参数请求服务端来调用指定的测试库 |
| 云测试库管理方案 | 通过读取配置文件,用标签和测试库一一对应,并生成可执行实例化的云服务器程序 |
- 好吧,说了一大圈,还是开始动手落地吧
三、测试实现和落地
- 1、服务器的实现:
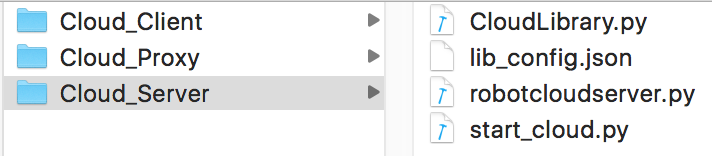
- 其中 lib_config.conf 是用于实现管理方案的,其内容如下:
[
{"api":"appium","lib":"AppiumLibrary"},
{"api":"selenium","lib":"Selenium2Library"},
{"api":"request","lib":"RequestsLibrary"},
{"api":"macaca","lib":"MacacaLibrary"},
{"api":"easy","lib":"EasyLibrary"}
]
- 然后通过执行 start_cloud.py 生成执行的云服务器,执行 python start_cloud.py 之后会产生 CloudLibrary.py 这个文件,并执行,其中 CloudLibrary.py
#coding=utf-8
import sys
import xmlrpclib
from AppiumLibrary import AppiumLibrary
from Selenium2Library import Selenium2Library
from RequestsLibrary import RequestsLibrary
from MacacaLibrary import MacacaLibrary
from EasyLibrary import EasyLibrary
class CloudLibrary():
def __init__(self):
self.appium=AppiumLibrary()
self.selenium=Selenium2Library()
self.request=RequestsLibrary()
self.macaca=MacacaLibrary()
self.easy=EasyLibrary()
def get_library(self,library):
if library=="appium":
return self.appium
elif library=="selenium":
return self.selenium
elif library=="request":
return self.request
elif library=="macaca":
return self.macaca
elif library=="easy":
return self.easy
else:
return self
if __name__ == '__main__':
from robotcloudserver import RobotCloudServer
RobotCloudServer(CloudLibrary(),"192.168.1.1",8270,None)
- 这里运用了单例模式和简单工厂模式,保证调用到库的实例都是唯一的,同时通过提供 get_library 方法来参数化获取不同的库实例,实现调用方案
- 里面还有一个 robotcloudserver 的文件,这个才是真正的服务器,也就是通过服务库的实例来获取不同的测试库,执行 python start_cloud.py 之后运行正常的显示:

服务器会自动获取本地 ip 并启动服务
2、客户端的实现:
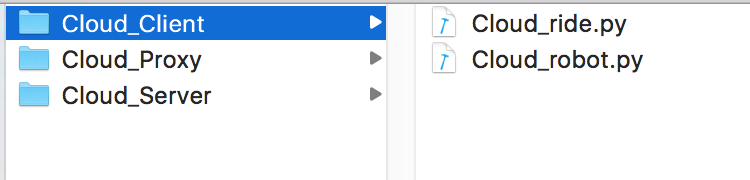
客户端是参照了 Remote.py 的方式,增加了参数化解析,具体的内容大家可以下载去查看,这里主要讲部署使用
-
如上图分别有 Cloud_robot.py 和 Cloud_ride.py,其实是分别放在 robot 和 robotide 的目录下:
Cloud_robot:/Library/Python/2.7/site-packages/robot/libraries Cloud_ride:/Library/Python/2.7/site-packages/robotide/lib/robot/libraries 在 win 系统上也是一样的,就是找到 site-packages 文件夹就好,放好之后将两个文件都重命名为 Cloud.py,并且修改 libraries 下的init.py 模块导入的内容:
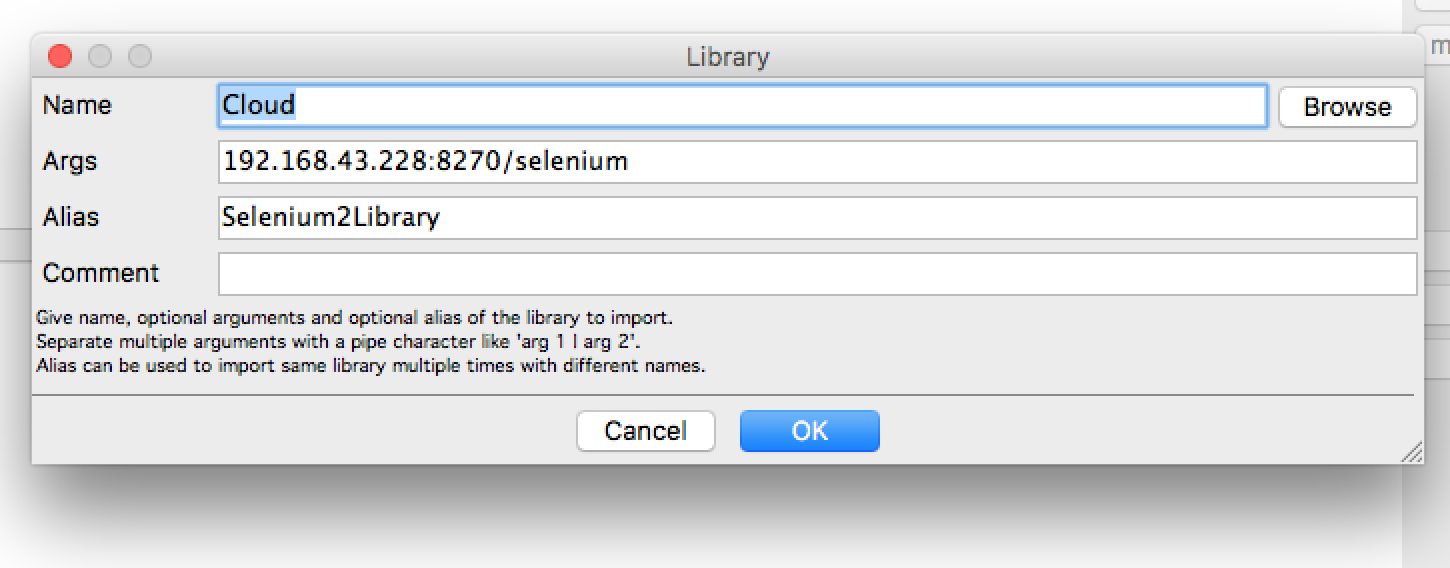
都搞定之后就是在 ride.py 上的调用,导入测试库的时候可以这样子:
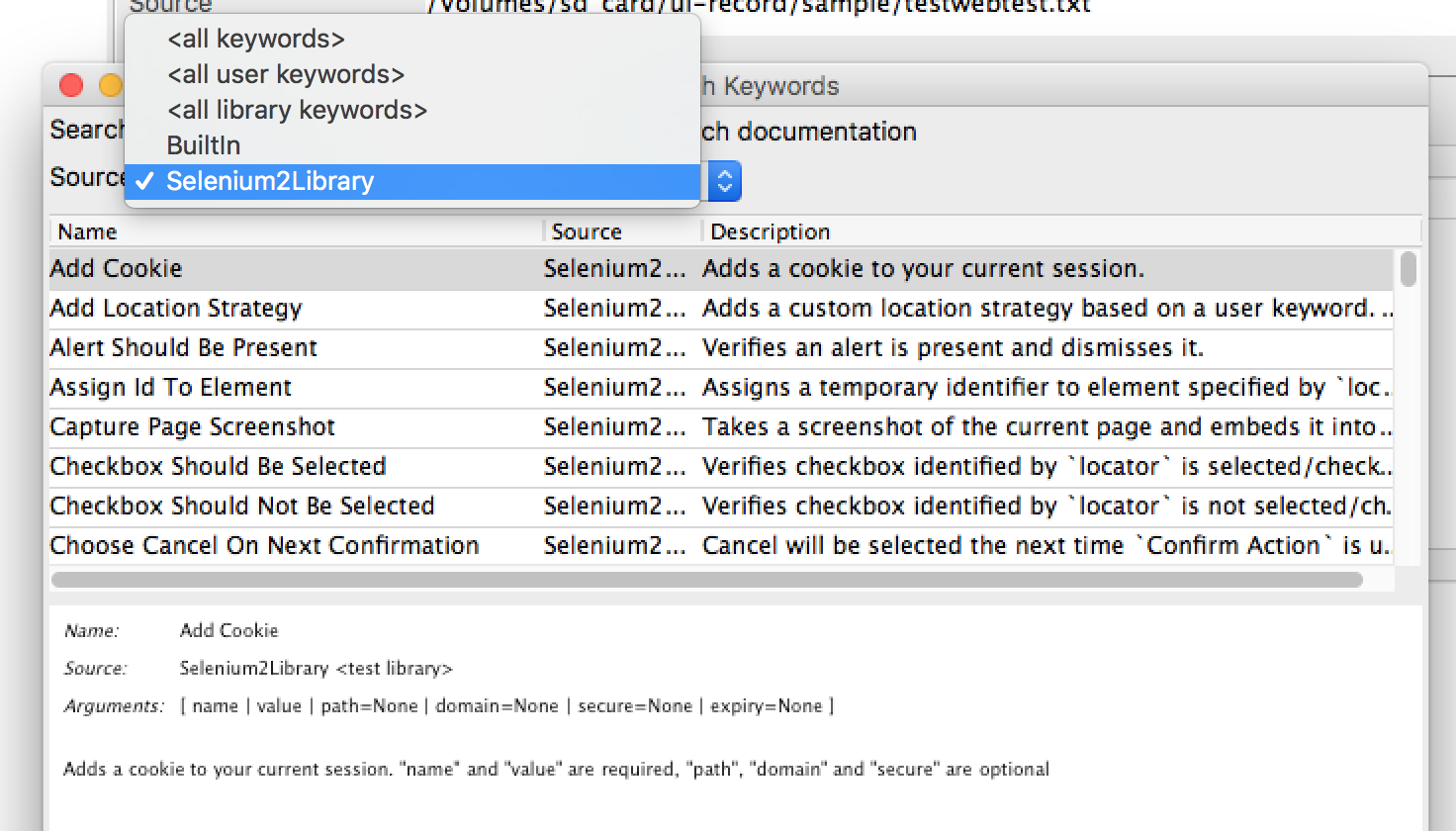
导入成功之后,查看一下关键字
然后在尝试一下执行,对于 selenium2library 的调用执行,要使其做用在本机或其他远程目标机器的话,比如用 nodejs 版的 selenium-standalone 启动了一个服务,用上 remote_url 参数就好,Appium,Macaca 也是一样道理,只要对得上 ip 地址就 ok,结合之前实现过的 docker-selenium-grid 的浏览器云并发方案,以及 f2etest 的浏览器云那就更方便了
*** Settings ***
Library Cloud 192.168.43.228:8270/selenium WITH NAME Selenium2Library
*** Test Cases ***
testweb
Open Browser http://www.baidu.com chrome \ remote_url=http://192.168.43.4:4444/wd/hub
sleep 0.5
- 本地开启一下 webdirver,然后调用执行,看看效果
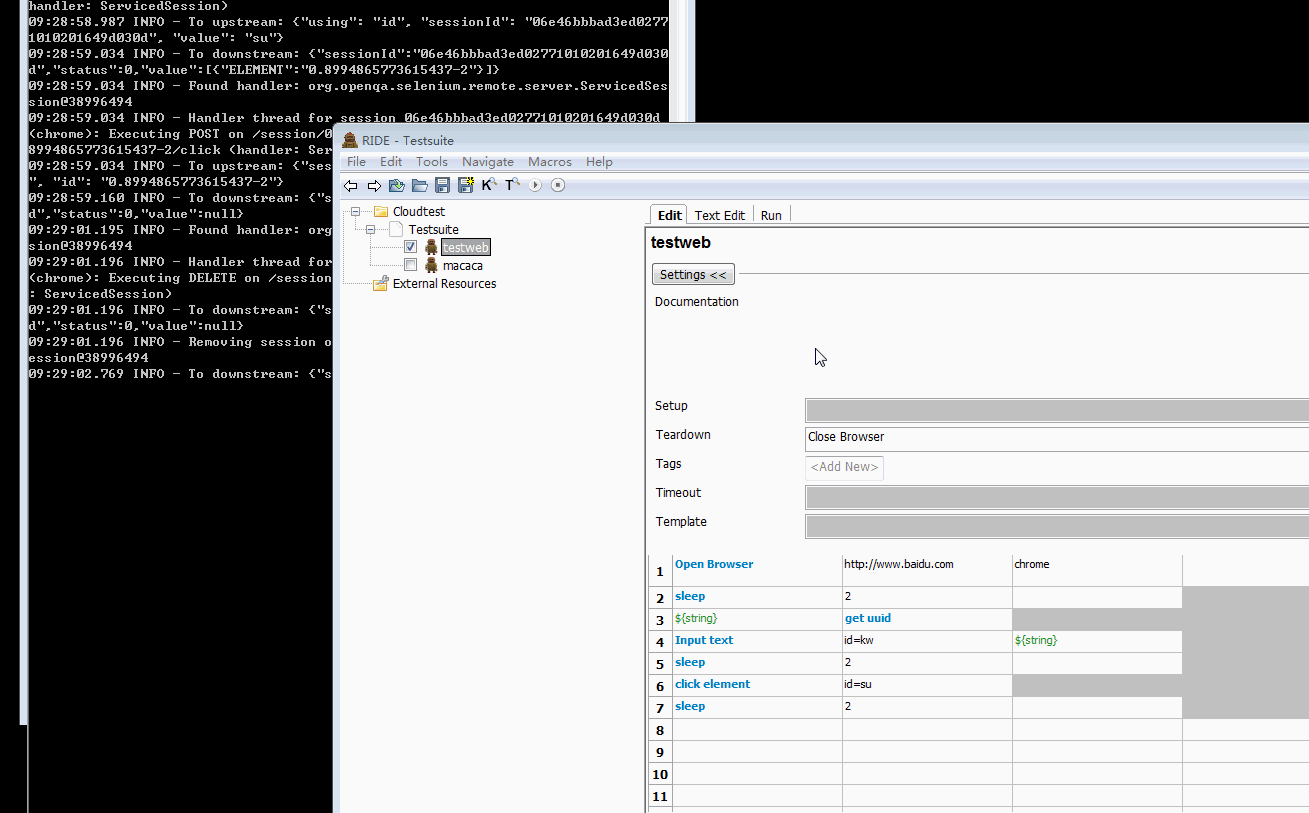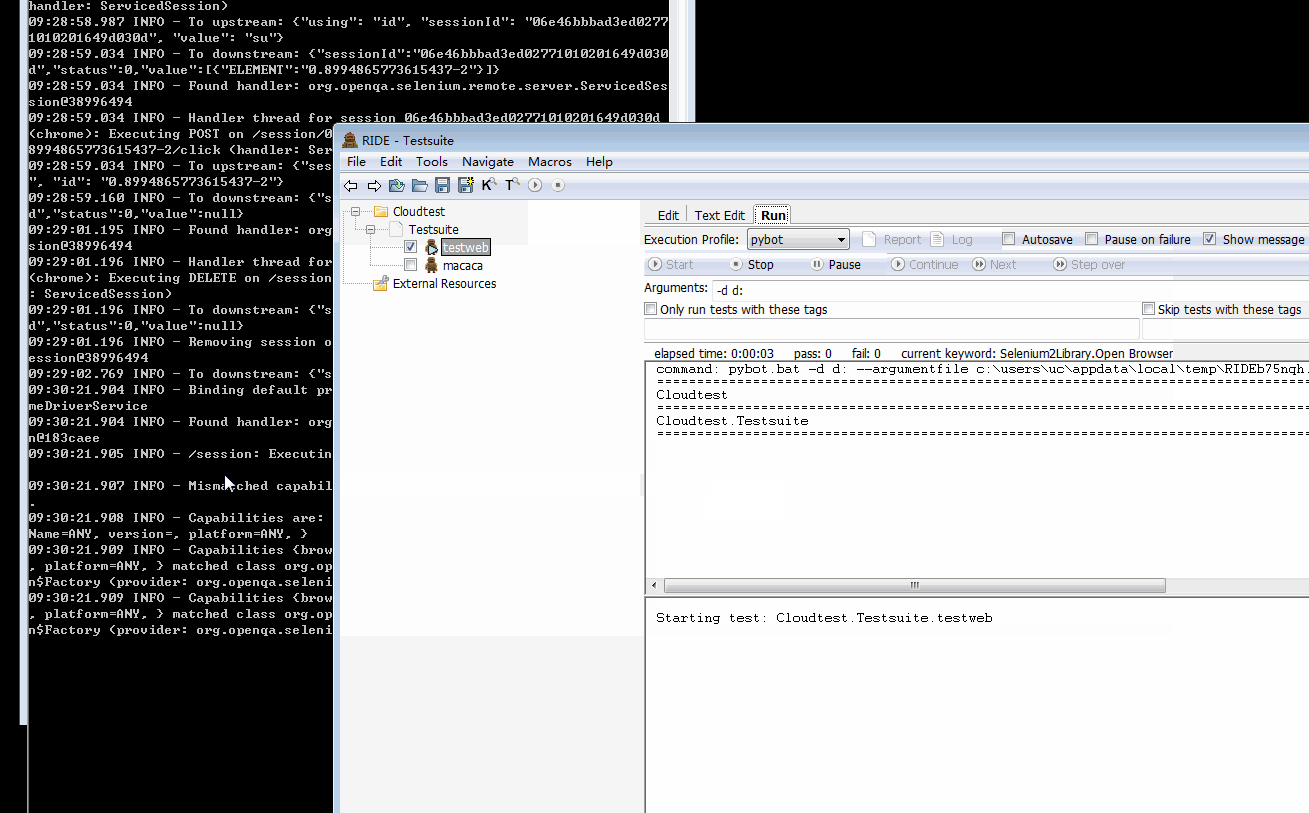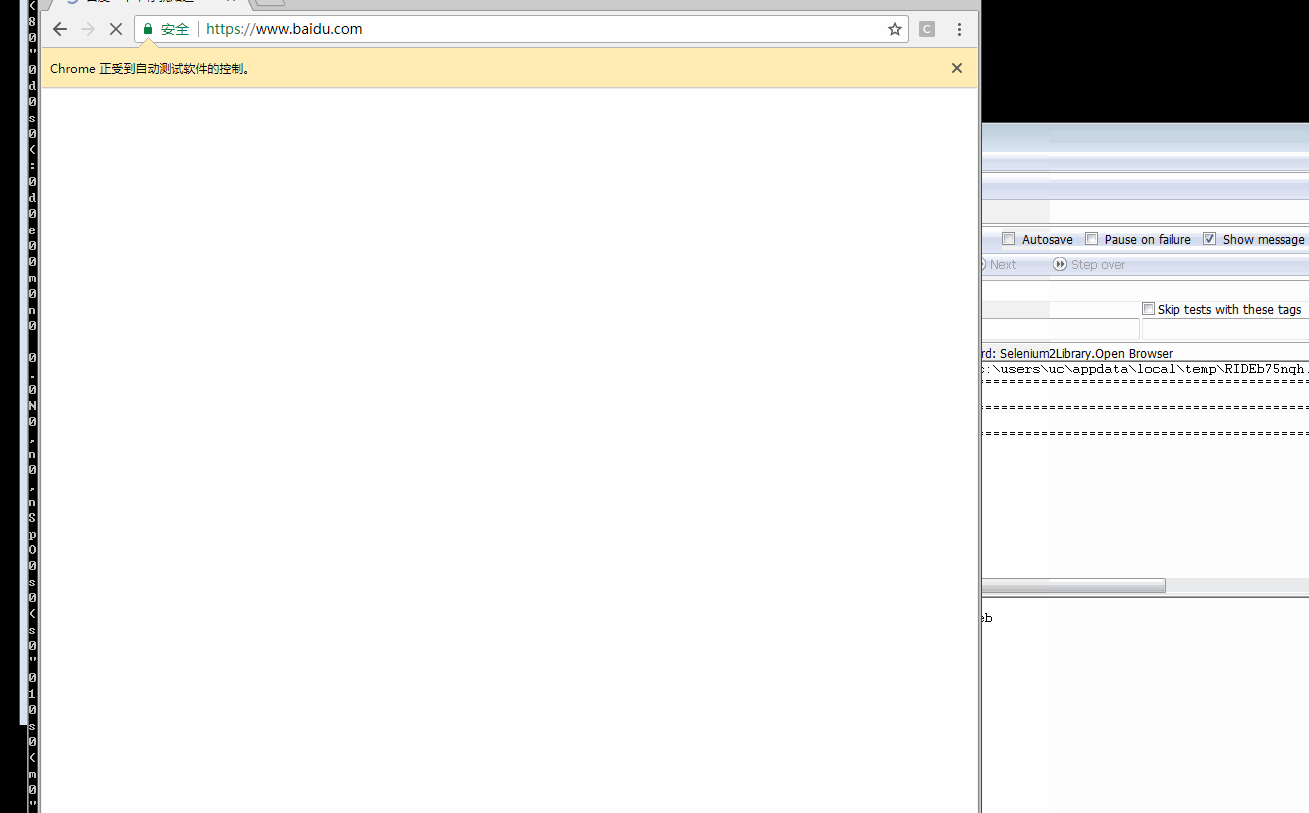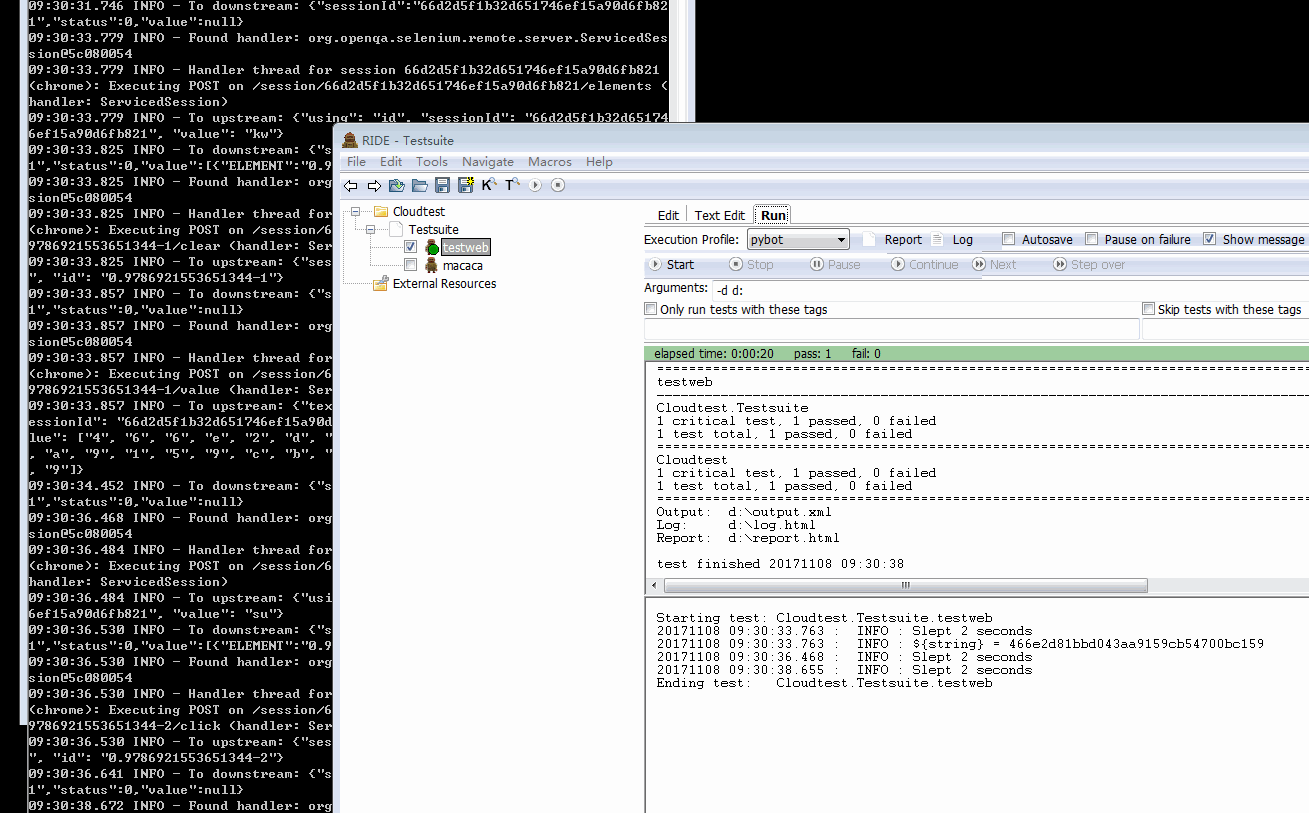
和在本地使用差异不大,参数就是我们在配置文件里面定义的 api,比如 selenium 对应就是导入 SeleniumLibrary,request 导入 RequestLibrary

查看导入的库,都是 ok 的,但这样就不用自己去维护测试库了,测试库只要维护一份,就可以整个团队共用,同时可以根据不同的参数导入自己需要使用的测试库,这方便了对测试库的管理和应用,这几步下来就已经解决问题 1 和 2
3、中心代理服务器的实现:
正如问题 3 和 4,更多的会偏向 4,比如测试库 A 在机器 A 上,测试库 B 在机器 B 上,但这个两个库都需要调用,按照上面的方法启动两个服务器的话,需要连接到两个不同的云来切换库,是否可以有一种方法可以让所有库的连接 ip 地址都是唯一的,于是就想到了这种架构
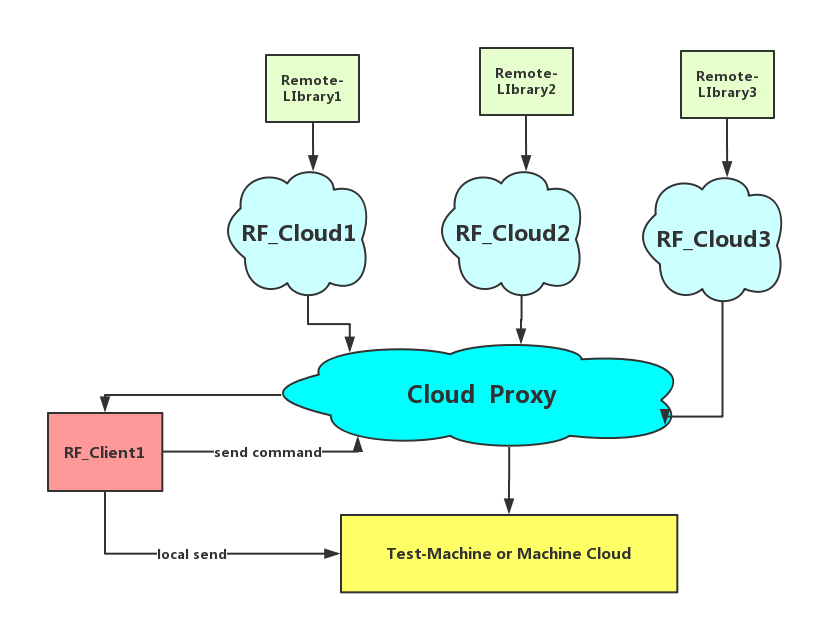
- 实现的过程就是建立一个中心代理服务器的方式,独立的测试库云通过在代理服务器上注册好自己云的名字以及填上对于的 ip 地址,就可以在代理服务器上记录,客户端通过既定的参数连接到代理服务器,通过云名字参数解析将连接指向到指定的云,这样就能实现了一个代理转发的过程,实现如下:
cloud_proxy.py
import xmlrpclib
import socket
from SimpleXMLRPCServer import SimpleXMLRPCServer
cloud_dict={}
def get_ip():
iplist=[]
iplist = socket.gethostbyname_ex(socket.gethostname())
ip=iplist[2][0]
return ip
def set_register(cloud_name,cloud_addr,cloud_port):
clo_address="{cloud_addr}:{cloud_port}".format(cloud_addr=cloud_addr,cloud_port=cloud_port)
try:
print cloud_dict[cloud_name]
tmpaddr=cloud_dict[cloud_name]
print "the cloudname:{cloud_name},ip:{addr} is exist".format(cloud_name=cloud_name,addr=tmpaddr)
return False
except:
cloud_dict[cloud_name]=clo_address
print cloud_dict[cloud_name]
print "the cloudname:{cloud_name} register ok,ip:{addr} ".format(cloud_name=cloud_name,addr=clo_address)
return True
def get_cloud_address(cloud_name,taga=None):
try:
print "aaa "+cloud_dict[cloud_name]
ipaddr=cloud_dict[cloud_name]
print "It point to {cloud_name}:{ipaddr}\nImport the lib:{taga} ".format(cloud_name=cloud_name,ipaddr=ipaddr,taga=taga)
return "http://"+ipaddr
except:
ipaddr="http://"+str(get_ip())
print "The cloud is not exist,It point to local center cloud:{ipaddr}".format(ipaddr=get_ip())
return "error"
ipaddress=get_ip()
server = SimpleXMLRPCServer((ipaddress, 8280))
print "The Cloud Proxy Server Listening on {ip}:{port} ...".format(ip=ipaddress,port=8280)
server.register_function(get_cloud_address,"get_cloud_address")
server.register_function(set_register,"set_register")
server.serve_forever()
- 主要是 set_register 方法和 get_cloud_address 方式,前者是测试库云到服务器上注册的方法,后者是客户端 Cloud 去获取测试库地址的方法,对于测试库云的注册,只要在执行 start_cloud 时带入-c:代理服务器的 ip 地址 和 -n:测试库云的名字,这样来启动就可以自动注册到代理服务器,首先先启动代理服务器:

- 然后执行 python start_cloud.py -c {proxy_ip} -n cloudname

这样就代表注册成功了,一般云名字都是唯一的,如果有其他测试库云再用如 cloud1 来注册的话,这样是代理服务器会返回云名字已存在,那换个名字注册就好了
- 然后客户端的调用方法
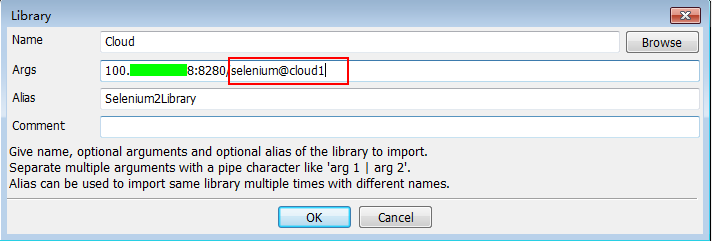
其实就是在本身的 api 参数后面通过@cloud_name来指向对应云名字的服务器地址,获取其 ip 之后创建对应的连接客户端,这样就能够指向到名字叫 cloud1 的测试库云并使用对应的资源,对应其他测试库也是一样的,这样就能保证连接的 ip 是唯一的,通过不同的云名字来指向到不同的测试库云,实现了测试库云的集群,这才是一个比较基础的云服务,这样一来问题 3 和问题 4 都解决了
-
4、难点攻克::
- a、 一开始在网上参考了别人对测试库的构建方式,基本上都是通过继承父类库来实现,前文也提到,这样的话是无法灵活选择自己需要的测试库的,所有一开始就想到通过参数来实例化测试库,一开始是每次调用都是产生一个新的实例,但这样有个问题,如果一个测试脚本里面同时调用了两个库,在库的切换的时候就会再次产生新的实例,这样会导致前面所执行的步骤是实例 A 做的,后面是实例 B 的做的,像 selenium 这种是不允许这样的,所以后面想到用单例模式,在测试库云初始化的时候将测试库实例化作为云的一个属性,之后的调用就能保证实例是唯一的了,可以阅读上文 CloudLibrary 的实现方式,以及 robotcloudserver 中的方法: robotcloudserver
def _get_keyword_by_tag(self,name,tag):
tmpliby=self._library.get_library(tag)
if type(self._runliby)==type(tmpliby):
pass
else:
self._runliby=tmpliby
if name == 'stop_remote_server':
return self.stop_remote_server
kw = getattr(self._runliby, name, None)
if not self._is_function_or_method(kw):
return None
return kw
就是这样通过客户端调用上面的方法,传入不同的 api 参数来获取测试库的唯一实例,保证了库的正常运作和稳定性,当然这里看是只有一个实例,其实多人调用也是可以的,比如像 Selenium 这种,其他调用的更多是 webdriver 的实例,这个是每次 open broswer 的时候都会创建的,用库的实例找到 webdriver 的实例来运行, 其他库也是一样的道理,我在之前的并发自动化的时候也验证过这个过程,所以说这种云的方式是能实现多人共用同一测试库的方案,而且这样以后只需要维护一套测试库即可
5、局限性分析::
-
基于上面的实现方式是有局限的
- a、目前只适合局域网使用,私有云部署,如果要往公有云发展,需要建立节点代理方式,这个就说来话长了
- b、部分测试库不适用,但目前只发现 AutoitLibrary 以及 SkuliLibrary,原因是这两库暂时无法和目标机器分离,这个有待研究,大部分测试库可行
简单总结
- 通过对上面测试库云方案的小实践, 让我对测试服务化有了实践的理解,将有效的资源整合成云的方式对使用方提供服务能力,可以大大提升对资源的使用效率,比如现在很多测试工具都往平台或云的方向去开发,服务化是测试技术的一个大趋势,在做这个之前自己还做了一个图像识别适配兼容测试工具,这里就偏向于测试智能化的方向,所以测试服务化和测试智能化会作为我目前重点技术方向,大家也可以在这两方面多做研究,多些时间,一起把大趋势推得更快些,同时希望大家吐槽一下这样子实现的一些坑,我自己也感觉不太完美,对于小团队来说基本是满足需求的,但需要精益求精,做得更好
参考资料
- 项目 github 地址:如有需要,请联系本人
- F2etest 浏览器云:https://github.com/alibaba/f2etest
- Docker-Selenium-grid 分布式环境:https://testerhome.com/topics/8148

