-
前端兼容测试思路请教 at 2020年12月22日
toB 产品,一般乙方应该可以提供需要兼容的浏览器版本清单吧?
toC 才是采集用户数据,因为用户没法主动告诉你。
-
[求助] 在 Linux 下执行 web 自动化测试,pytest 报错了,大家帮忙看看这是啥问题啊? at 2020年12月22日
INTERNALERROR> File "/data/longfor_oa/conftest.py", line 149, in _capture_screenshot INTERNALERROR> driver.save_screenshot(screen_path) INTERNALERROR> AttributeError: 'NoneType' object has no attribute 'save_screenshot'把
/data/longfor_oa/conftest.py这个文件的内容发上来吧,从日志上看,直接原因是调用 save_screenshot 时,driver 对象还是没被初始化,还是最初的 None 。但具体为啥是 None ,不看你写的代码看不出来的。 -
大数据测试场景科普 -- 流计算篇 (上) at 2020年12月21日
当领导问你:你怎么确定你测试过的的数据是对的
我理解你说的这个,是测试出来的结果和数据使用方的数据口径是否一致的问题,类似一般功能里的 “是否满足需求” 问题?
也想听下你的想法。 -
手机连接 STF 可以查找设备,但是点击进入时,显示断开连接,手机提示如下 at 2020年12月21日
信息太笼统了,至少把相关 stf 服务的日志、手机 Logcat 、你这台手机的详细信息发一下?
-
面试:如何回答你能给我们带来什么价值? at 2020年12月20日
补充一个点,如果是在你说了你的期望薪酬后问这个问题,基本就是说明你提的薪酬期望比他们预期的高了,他们想借这个问题卡你一下,好找理由把薪酬降一下。属于比较套路的问题。
-
大数据测试场景科普 -- 流计算篇 (上) at 2020年12月20日
对于你提到的这两个问题,我曾经呆过公司里看到的情况是,大数据团队都是自测上线,靠计算结果的数据监控来发现问题和修正问题的。测试团队基本不介入这部分测试。
所以我是基本认同飞哥的观点,不了解背后的技术或者复杂的业务,是做不好大数据测试的,至少很难让大数据研发团队信服你的结果。
另外,谷歌了下 test oracle ,有对应中文名称,叫做 测试准则 。不过这个词的解释我看了好久也没看明白,它涵盖的范围有点大。所以也很少用。
-
大数据测试场景科普 -- 流计算篇 (上) at 2020年12月20日
终于看完了,大数据只了解皮毛,勉强能跟上
好奇问一个点,这里提到测试是否有达到数据一致性的方法,是注入故障。那具体怎么注入才能保障能做到文中期望的端到端上每个点的 exactly once 做到位,避免遗漏?
-
面试:如何回答你能给我们带来什么价值? at 2020年12月19日
同意一楼说法,了解他们要什么,你匹配了什么,然后直接讲就是了。
一般能聊到薪资这一步,说明你还是匹配他们需要的。
-
动态页面 Appium 定位好慢,有解决办法吗? at 2020年12月19日
按以前对 appium 底层 dump 元素用的 uiautomator 原理看,用 locator 定位,前提是要能拿到完整的元素树。但元素持续高频变动,那元素整个树的结构就不稳定,导致很难 dump 出来(dump 基本要从根节点开始向下递归,会有一定耗时)。这个原理决定了比较难用 locator 定位。
相对坐标这个方法还是挺不错的,如果担心由于设备屏幕大小不同导致坐标要适配,可以考虑用图像元素识别类的定位方法。
-
年底了,大家开始写年终报告了吗 at 2020年12月18日
写有什么是比上一年做得好的,甚至是从零突破的。
-
测试开发的技术是否在混沌探索时期,这时候抓住机会就可能一飞冲天 at 2020年12月18日
乐观积极是好事,确实测试开发的技术潜力是挺大的。
但有些点想要纠正一下:
首先,不是学会一点技术就容易上升,是做出成绩才容易上升。任何时期,任何公司基本都一样。只是刀耕火种的时候,做出成绩会相对 “简单”。而且刀耕火种的时候,技术其实反而复杂,门槛反而高,比如没有类似 antd design 或者 element-ui 这类前端框架的时候,大家直接撸 html+css+ 原生 js,还得关注各种浏览器下的兼容性(比如万恶的 IE6),比调用模板复杂多了。能做到在这种情况下提取成框架并且经受住业务考验,一点都不简单,只是现在你都知道答案了,会觉得简单。
另外,测试开发大概是 15 年左右开始兴起的概念,现在我理解应该不至于是混沌探索了,比如 UI 自动化和接口自动化的框架,已经基本是一个百花齐放的阶段。当然,机会还是挺多的,但不是那种简单学学技术就能上升的了,得有业务落地的能力才行。
-
(转载 --- 上篇) 分布式系统测试那些事儿 - 理念 at 2020年12月17日
不错的文章,加个精
建议目录加一下中篇和下篇的地址,并且说明下原文出处?
-
接口测试,如果我想把用例的成功率,带在邮箱标题中,该怎么带呢? at 2020年12月17日
邮件是怎么发的?jmeter 和 ant 应该都没有自动发邮件的能力吧。
只要有源码,没啥是改不了的。
-
[面试] 记录一次来自 bigo 的电话面试 at 2020年12月17日
真不是大佬,还有好多东西要学习。技术不断在变,学无止境
-
repeater 有自己的钉钉沟通群,github 项目 readme 底部有。repeater 的几个主要作者也都在里面。
-
测开---编写测试工具有什么好的方法论吗 at 2020年12月17日
前两个问题,直接去业务里面轮岗测 1-2 个需求,就能找到了。好工具的共同点就是能解决实际问题。
第三个,不知道你的 GUI 和 web 差异是啥?GUI 指的是图形化界面吧,web 也有呀。
-
[面试] 记录一次来自 bigo 的电话面试 at 2020年12月17日
额,还没到大佬级别哈。针对你说的这几个问题,如果是我,我可能这么回答:
12、你觉得小程序测试与 web 测试有什么区别?
这里的小程序是微信小程序吗?如果是,个人理解大概有这些区别
1、功能方面,一个是微信授权的对接是否正常,另一个是控件及界面在不同屏幕下的适配效果。测试环境的话需要想办法构造入口,便于测试时按需切换环境/造数据。(记得某年小红书分享小程序测试的时候有提过这个坑,不知道现在还有没有。实际工作目前也没太专项测过小程序)
2、非功能方面,需要关注下发包大小、不同微信版本下的功能适配。小程序官方有个性能体验测评的东西,可以借助这个来大致评估下13、有想过 web 和移动端的前端性能测试有什么区别吗?
web 的由于是随用随加载特性,所以性能关注的除了界面展示是否流畅(特别低端机型),还有加载时间是否尽可能短、需要加载的文件是否尽可能少和小
移动端由于是提前下载安装包,大部分资源都已经加载好,所以性能关注的除了界面展示是否流畅,还有流量消耗是否尽可能少(现在 4G 和 5G 普及,流量多很多,这个优先级基本降低了)、cpu 及内存使用是否会过高(会引起卡顿甚至直接被 kill)、是否有内存泄漏、耗电量是否尽可能少(特别是后台时)、弱网下体验尽可能好16、如何解决版本迭代数据兼容性的问题?比如当前有一个排名,然后代码修改之后,怎样确定修改之后会不会出异常?
1、设计时,尽可能采用新增字段的策略,尽量不要改动已有字段的定义或内容
2、提测前,看代码具体改了啥,评估这个改动对于历史数据是否会有问题
3、测试时,从线上脱敏导一些相关的历史数据到测试环境,验证下有没有问题,测试环境本来就有最佳。不行的话可以在测试后期,线上拉一个节点部署新版本服务,只对公司内网开放,然后在上面测试一些历史数据的读取,确认正常
4、上线时,采用灰度上线策略,持续监控日志是否有异常。这样就算历史数据有问题也不至于影响太多用户22、你觉得怎样的模块是不合适做自动化,哪一些是适合做自动化的?
经常变化且不持续使用的模块不适合做自动化,比如一些只会持续 1-2 个月的活动页。不经常变化且出问题影响比较大的适合做自动化,比如支付子系统。
-
[面试] 记录一次来自 bigo 的电话面试 at 2020年12月17日
好奇问下,面试结果是?
-
如何使用 jacoco 统计多个 docker 容器服务的测试覆盖率 at 2020年12月16日
端口是附属在 ip 下面的,基本对应关系是 ip=主机(不是物理上的,是逻辑上的,比如 docker 内部网络下,每个容器都有自己的 ip,但在 docker 网络外部,整个 docker 主机只有一个 ip),端口=应用
之所以不同应用要换端口,原因是一个 ip 下面一个端口只能绑定给一个应用监听,你多个应用绑定时,第二个开始就会绑定失败。
你在 docker 网络外部访问里面的容器,所有容器用的都是 docker 主机的 ip,自然必须要每个容器都用不同的端口。
当你在 docker 网络内部访问里面的容器(比如起一个采集服务的容器,访问其他容器),每个容器用的是 docker 内部网络分配的 ip,一个容器一个 ip,自然就不用错开端口了。
你例子写的也是一样,A 和 B 服务器只要是用不同的 ip ,就可以用同样的端口而不冲突,A 上面多个容器,每个就得错开端口。 -
面试之 get 和 post 区别 at 2020年12月16日
post 和 put 是不是反了?我了解的是 post 对应 create ,put 对应 update 。
不过也没啥好纠结的,实际用只要前后端约定好就行。
-
面试之 get 和 post 区别 at 2020年12月16日
之前看到一篇讲得挺详细的,搬运一下:https://testerhome.com/topics/25530
在实际工作中,主要区别还是 get 是读场景,post 大多是写场景,当然也不绝对,也有见过不管三七二十一全部都是 post 的系统。
-
测开入门篇《环境管理、编码规范、项目结构》 at 2020年12月15日
规范写得挺全的,不错。个人经验,其实与其给非常多的规范约束,不如直接搞个脚手架仓库,让大家基于脚手架来扩展添加自己的业务功能,用起来更方便?用的人只要都是模仿已有的写法去延续,那风格就会保持一致,基本上这个脚手架就能保障大家是按照这些相对规范的写法来写自己的项目。
PS:项目结构里面,sample 存放项目的核心代码应该不是规范吧。我接触的项目,sample 一般是放示例项目用的。
-
业务测开的尴尬定位 at 2020年12月15日
并不是所有功能测试都外包,而且很多时候大公司的非外包测试 title 都变成测试开发了,但并不一定全都是做我们通常理解的开发工具的测试开发工作,也有一部分实际主要是做功能测试的,只是都会有代码能力要求,不是纯功能。
-
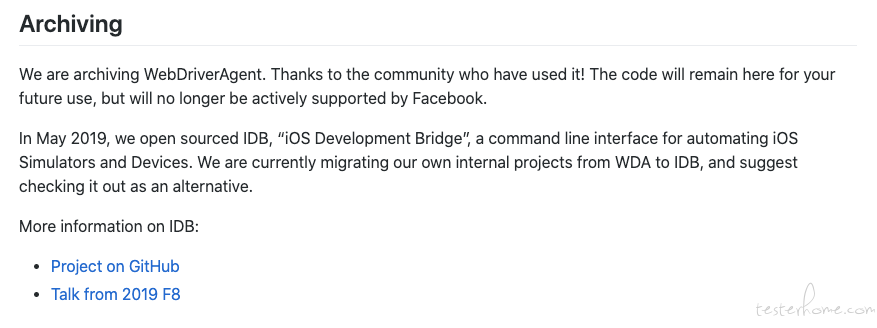
理解和使用 WebDriverAgent at 2020年12月14日
facebook 官方已经停止维护 WDA 了,项目会被整合到 https://github.com/facebook/idb/ 。建议综合考虑下是否真的要基于原生的 WDA 做二次开发。
-
如何使用 jacoco 统计多个 docker 容器服务的测试覆盖率 at 2020年12月14日
不用啊,你采集覆盖率部分的服务也部署到 docker 同一个网络里面,就可以按主机名或者 ip 来区分各个服务了。
实际只有获取 ec 文件这个步骤需要访问这个端口,后续的生成报告啥的都是基于 ec 文件了。