Selenium 如何实现 mysql 导出数据,验证页面正确性?
通过 selenium 验证某个搜索功能时,需要验证每一行是否正确,领导建议从数据库里面取然后验证,尝试学习了 pymysql,确实……可能是我的 sql 写不对,老是有问题,主要是很难与本来已经写好的 PO 模式结合起来。
本来想好的页面功能也需要重新写,写代码的时候遇到的问题是
验证搜索功能往往需要验证每一页,每一行,每一列的数据,然而元素定位每一行的每一列着实困难,也不知道通过什么验证比较合适,对象?字典?
如何封装 element.find_elements?由于已经封装了 get_element_text……等通过 location 获取的方法,列表数据的验证是需要通过元素获取元素的,这样就导致还要写通过元素获取 text 等方法,是否封装的那些 get_text 等方法要重新写过呢?
放到 page 的页面功能中验证是否正确呢还是放到用例中?是否会导致用例很长,放到页面功能中验证又该如何验证呢,搜索会有一些条件,是通过 ddt 传过来还是页面功能拆开搜索方法呢?
感觉好难结合起来,网上的例子也比较少,比较纠结怎么构建代码和框架,尽量做到简洁。
关于第二点,已经有了思路,感谢@fiskeryang
验证数据正确性通过接口跟查询 sql 结合不是更好吗
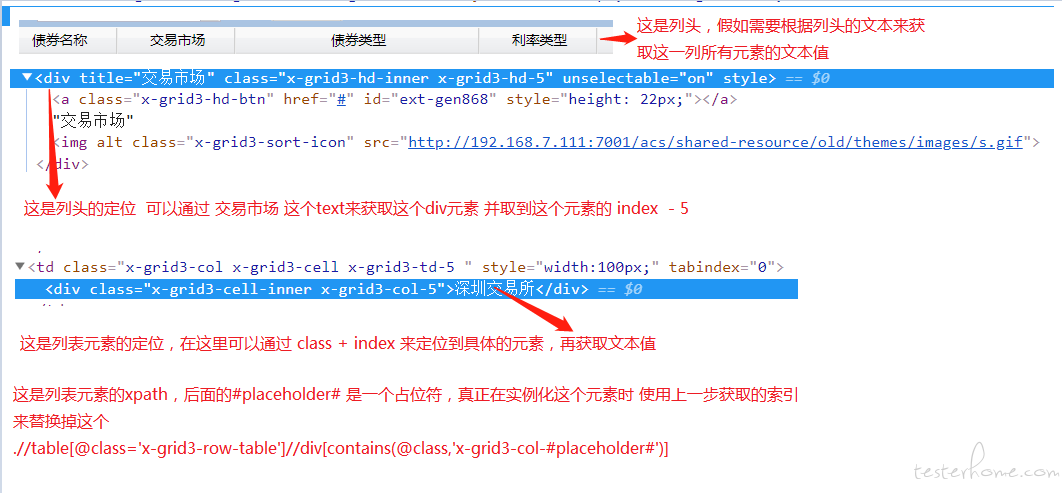
列表数据的校验是一个难点,我的方式是通过列头的文本值来通过 xpath 相对定位获取这一列所有元素 再逐个与期望值校验
请问这个和 PO 模式结合的时候,需要重写 BasePage,肯定需要用到通过元素查找元素,并获取元素的 text,这个该怎么封装呢?
我之前已经封装了通过 location 获取元素文本等了。
如果只是做 UI 层的校验的话,直接调用 后端的接口不好吗?
分别回答你的 3 个问题。
- 通过良好的用例设计,将搜索结果控制在一页,既能达到验证的目的,又能达到方便验证的目的。
- 不太明白这个问题,但感觉按前一条说的做了就不存在这个问题了。
- 验证部分必须放在用例中,不同的搜索条件对应不同的用例。拆分的好处是有利于用例实现和维护。
通过 selenium 验证某个搜索功能时,需要验证每一行是否正确,领导建议从数据库里面取然后验证
这个出发点有点不对吧,如果搜索功能不是用 sql 实现,而是大数据通过推荐算法来做就 gg 了,压根没 sql 给你查。。。
如果你是纯验证 ui ,可以对比相同参数请求接口的返回值是否正确,基本上选 2-3 个抽样检查就好了。
如果你是要 ui 和服务端功能都验证,那建议你还是拆开两端来测试吧。
PS:搜索功能绝大部分逻辑在服务端,本身更适合接口测试。客户端的 UI 自动化去验证这个有点本末倒置了,效率也不高。UI 自动化!=手工检查的点都变成自动化检查 ,最典型的例子就是排版问题。手工一眼能看出的排版问题,对 UI 自动化却是个技术难题(当然现在也有公司已经突破了,可以自动识别排版异常),这种情况就不大适合用 UI 自动化去做。
真的需要每一行都去校验吗?比较同意 7 楼的看法:对比相同参数请求接口的返回值是否正确,基本上选 2-3 个抽样检查
1.用例存在空搜索,即搜索内容为空时,点击搜索,这个情况出来的是全部的,需要一个一个比对,因为之前出过每次点击一个新页面都重新排序的 bug
2.每一排都有一个 class,我可以很好的定位列表的每一排,但是无法定位每一列【列没有固定的 class,只有一个 tag td】,如果需要定位的话,需要这样
row_element.find_elements((By.TAG, "td"))
这样的话需要对每一个进行解析,没有封装 element.find_element 方法,而且如果封装了的话,由于要获取其中的 text,还需要封装 get_element_text_by_element.因为之前封装的 get_text 是通过定位获得的
3.我明白验证需要放到用例中,但是是否可以在页面功能类中添加方法,对比不用 assert,而是用 if,如果不对,返回 False 呢,如果全放到用例中,两个列表对比,肯定是要 for 循环,放到用例中感觉又不太合适
想问您一个封装的问题,在 BasePage 中已有封装
其他封装的方法都是依据它来的,如:
请问还需要封装 element.find_element 方法和 get_element_text_by_element 方法吗
1.用例存在空搜索,即搜索内容为空时,点击搜索,这个情况出来的是全部的,需要一个一个比对,因为之前出过每次点击一个新页面都重新排序的 bug
抽样也能发现这个问题,比如固定抽取 1、3、5 三个样本,排序类问题是可以发现的。也建议你了解下,之前这个 bug 是服务端问题还是客户端问题,如果是服务端问题,那通过接口测试预防成本更低。测试应该用最低成本发现最多问题,做自动化更要留意这个点,因为自动化不同方法之间成本会差别挺大的
如果全放到用例中,两个列表对比,肯定是要 for 循环,放到用例中感觉又不太合适
好奇问下,为啥觉得不太合适?个人觉得倒是最合适的地方了,因为用例需要做检查点校验。至于 for 循环,你做抽样的话就不用循环了,固定写死 2-3 个位置就好。
请问还需要封装 element.find_element 方法和 get_element_text_by_element 方法吗
能否详细说明下你想封装这两个方法的原因,以及模拟下封装和不封装在用例实际写法上的区别?这个要看实际使用场景的,没有绝对的答案。按现在的信息不是太充分,不好给你意见。
因为用例需要做检查点校验。至于 for 循环,你做抽样的话就不用循环了,固定写死 2-3 个位置就好。
1.请问抽样是什么意思呢?我之前没有接触过。是接口测试里面的吗?对比相同参数请求接口的返回值是什么意思呢
2.固定写死是否会导致只测到这几个位置,其他位置有问题呢?比如现在由于测试环境数据库存在脏数据,1、2、3 页都没有问题,后面几页才出现问题。
3.区别其实我也不太清楚,但是我知道将 driver 的方法封装,ui 测试失败率大大降低了,所以我觉得应该封装,另外重复的代码减少了。模拟封装的话可能是
def get_elements_by_element(el, *loc):
child_el = el.find_elements(*loc)
return child_el
def get_element_text_by_el(el):
text = el.text
return text
# (里面存在try except对异常的处理)
# 从传入loc -> 变成传入element
# 第一个函数可以获取一个元素的子元素,但是我也考虑到它是element的方法,不是driver的方法
用例中如下:
# ①没有对异常的处理
row_ele.find_element(*loc.column_1_loc).text
# ②
column_ele = self.find_elements_by_element(row_ele, *loc.column_1_loc)[0]
column_1_text = self.get_element_text_by_el(column_ele)
PS: 您说的对,我问清楚了,这些都是服务器问题,已经和领导沟通 ui 和接口分开做。
4.将 UI 上的数据和从接口获取的数据结合,那么接口如何请求呢,selenium?request?
- 将搜索内容为空作为独立用例处理;将验证点击新页面是否重新排序作为独立用例处理。
- 还是没看明白,但感觉处理得好繁琐,还是那句,照前条说的做,测试场景设计优化后,既能达到验证的目的,又能达到便于验证的目的。
- 验证必须放用例中,不能使用 if,必须使用 assert,assert 的多种重载中支持 object 参数,可以直接对比两个列表而避免使用循环。举例,Assert.AreEqual(listExpected, listActual, msg);
您好
搜索为空,作为独立用例时,如何验证呢?是否要逐页点击确认,当点击第二页,即发生了点击新页面事件,这时获取到的列表如果是重新排序过的,可能会验证失败。我觉得测试场景设计确实要优化,但是对于测试结果还是需要验证的。
每一列的 class 每次点击都会变化,这种情况,我如何获取每一排每一列的文本信息呢(直接 driver 我知道,但是我不知道如何结合 page object 模式来做,因为要封装 selenium 原生方法不是吗)
您说的对。
测试用例设计优化,既包含测试步骤优化,又包含测试数据优化。无论是否优化,测试结果验证都是必须的步骤,没有结果验证那不叫测试用例。
搜索结果是单页是能够达到验证目的的。搜索为空,按默认或某列排序,会有个期望的单页搜索结果 listExpected(已排序),执行测试步骤后会得到单页搜索结果 listActual(已排序),在用例中直接 Assert.AreEqual(listExpected, listActual, msg) 即可,不用拆开进入 list 并循环对比验证。这么做了就不会有你后面说的逐行逐列验证问题。
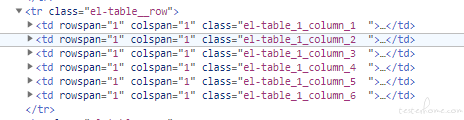
假设 class 每次都会改变,这个情况该如何处理呢,比如第一次是 el-table_1_column_1 ,第二次是 el-table_2_column_7 ,确认是同一行同一列
并且很好奇,这个占位符是如何在实例化该元素时替换掉的呢
这个要结合 header 和 cloumn 一起看
不管你的元素具体的 class 里数字是多少
只要 列头和列表元素的数字是有规律能对应起来的就行了
比如 列头的 class 里 数字是 2 那列表元素的 class 里也是 2 或者是固定的偏移量 都可以
好的,谢谢。
这个占位符是使用赋值的方法将其改变吗?
如果是赋值,我觉得页码元素定位和页面功能分开可能耦合性更低一点,所以没有用这个方法,否则我之前也是用的这个方法
request 如何和 selenium 结合呢,在必须传入 header 的情况下
请问 UI 自动化测试和接口测试结合,怎么获取 authorization 呢?
我反复思考了很久,觉得
获取接口的数据,成本好像更高
实际是两个步骤
第一个步骤 是输入 你需要核对的 列头的文本列表 获取 各自对应的 index 保存下来
第二个步骤 是根据上一步获取的 index 获取列表元素对象,再去逐一比对期望值
能理解吗
怎么获取 authorization 呢
这个,你先了解下开发是怎么获取的?这个东西没有一个标准的方式的,web 常用 cookies 做鉴权,移动端常用 token,甚至还会有别的姿势。这么问我不知道怎么回答你。
这个其实是纯接口测试范畴的问题了,如果你原来就没有接口测试,那从零开始鉴权这块肯定是要首先解决的,初期成本会相对高一点,但突破后只要系统不大改就能继续沿用,属于一次性成本。
如果你们确实本身没有接口测试,现阶段也没打算投入去做,那就先忽略这个点,继续去做纯 UI 自动化呗。个人理解 UI 自动化不应该过度关注实际返回值对不对,只需要关注有返回值、展示正常就可以了。如果非得关注返回值对不对,可以在用例设计上想办法,让每一行的内容相对固定,这样就避免要去问后端,而是可以写死在代码里了。
UI 自动化和人通过 UI 做功能测试还是有差异的,UI 自动化的工具框架基本都是只针对 UI 界面操作,而人去测试 UI 基本都不会只针对 UI 操作,还会结合查数据库、查后台、抓包等动作,多处检查。所以还是我前面说的,不要直接把人测试的用例直接套到 UI 自动化中,成本会比人操作高不少,而且还可能由于涉及系统多,影响稳定性。
经过几天的思考,终于对于您的建议有了一点理解,不过我还是疑惑:如何设计用例【验证点击新页面是否重新排序】呢?
以每页显示 10 条搜索结果为例。
首先设计测试数据—25 条记录,设计的准则是 “17 条符合搜索条件 A,8 条不符合”。17 条结果按照字段 X 排序并以 10 为单位分页,得到第 2 页的 listExpected(包含后 7 条结果,包含前 10 条结果的 list 弃之不用)。
然后执行测试步骤。
1.来到搜索页面,输入搜索条件 A,点击搜索 (搜索结果显示 17 条、2 页、按照默认排序)。
2.点击按照字段 X 排序 (页面刷新为按照字段 X 排序),点击下一页。
3.获取第 2 页结果 listActual,验证实际结果跟预期结果相符:Assert.AreEqual(listExpected, listActual, msg);
最后销毁测试数据—这 25 条记录。