-
有个疑惑点,好像你 config 配置里的类名,和截图里的被测应用,有点不大一样?
这个情况以前还没怎么遇到过,不大清楚是什么原因。 @kujiale-qa @kujiale 看有没有遇到过?
-
业务测开的尴尬定位 at 2020年12月14日
每天业务测试量贼多,做工具又得加班做,想做工具不给排期
想问下楼主,你的业务测试量和团队里其他没有测开 title 的相比,是一样的吗?如果是,那感觉你领导没把你当测开来用,如果不是,说明领导其实已经在尽自己所能给你时间了。
不过业务测开这个混合名称,个人理解其实和高级测试差不多,重心还是在业务测试,所以才加上业务两个字。这类岗位一般定位是用好工具提高效率,自己要开发或者二次开发的工作量应该并不多,而且也不会对开发工具有太高要求。
-
如何实例化不同页面对象对应不同的 iframe,而不用频繁切换 at 2020年12月11日
hmm,消耗的内存差异应该不太大,而且对于测试代码来说不会 7x24 长时间执行,不大需要考虑内存的问题
至于代码简洁程度和案例编写流畅度,这个有点见仁见智,特别编写流畅度这个比较主观。建议你可以按这个思路分别写个 demo 对比一下?也可以听下团队其他要一起参与写自动化用例同学的意见。
-
如何实例化不同页面对象对应不同的 iframe,而不用频繁切换 at 2020年12月11日
对于楼主 3 楼提到的场景,想到一种思路,让 iframe2 对象的任意方法执行的时候,都统一先判断当前 frame 对不对,不对的话走一遍 switch_to.frame(iframe2) ,同理其他 iframe 也可以这么操作。
实际代码编写上,可以在 frame 的类里面重写 find_element 之类的基本大部分操作都会用到的方法,让它在 find 之前先切换,这样可以节省代码量。
-
测试开发应该具备哪些能力才可以拿 30k,大佬们可以说一下吗 at 2020年12月10日
匿名贴回复默认匿名,个人觉得没啥问题吧?
底部有显示名字选项,选中就会非匿名了。
-
既然大家如此热烈讨论 AI,那我来问一下,该如何学习 AI at 2020年12月10日
建议先学会思路,再用框架吧。学 AI 比学一个框架要复杂多,基本相当于一个新领域了。不要抱着学一个框架的想法去学习,你会发现入门都很困难。
可以看看西瓜书,或者 google 的 ai 课程(本身就是针对编程人员的,有可以直接运行代码的教程,个人用起来比较顺手)。对于一个陌生领域的从零开始学习,最好还是像以前学编程语言那样去学一些相对系统化的课程,这方面领域知识比学一个框架要复杂得多,不是看一天框架文档就能基本上手使用这么简单的。
如果只是应用别人已经做好的基于 ai 的框架,可以看看 appium 那个图像识别的扩展插件。
-
App 自动化《元素定位方式、元素操作、混合应用、分层设计、代码方式执行 Pytest 命令》 at 2020年12月08日
不是说二维码,是说正文的结尾
实际做自动化测试,Web 网页是很复杂的,App 自动化测试的周期要比 Web 自动化时间要短很多。
写框架先写页面,首先研究下页面构造,看下页面功能的关联性。
感觉好像还没说完。
-
ui 自动化有必要更换并验证图片吗 at 2020年12月08日
你要考虑维护成本。比如后面要求从小于 300kb 变成小于 500kb,开发只需要改个参数,1 分钟不到的事情,然后你的自动化用例得重新找等于 500kb、大于 500kb 的素材并替换进去,还得跑一遍确认下对不对,一般至少需要 5 分钟。这么算,你的成本至少是开发的 5 倍。
并且 UI 自动化由于各种偶然因素,失败率一般会比较高,所以为了保障稳定性能达到 90% 以上,还需要做一些调优;用例多了执行起来太慢,要并行之类的加速。这些调整都是成本。
自动化应该主要关注出问题会 P0 故障的场景,这些是尽可能保障每次代码变更都不会出问题的,所以要自动化高频率跑。至于那些出问题其实影响不大的,不一定值得做自动化。
-
ui 自动化有必要更换并验证图片吗 at 2020年12月08日
@ 醋精测试媛 说个题外话,怎么感觉你现在自动化已经逐渐到了只要人工做测试的都要做自动化的程度了?
-
App 自动化《元素定位方式、元素操作、混合应用、分层设计、代码方式执行 Pytest 命令》 at 2020年12月07日
结尾有点怪怪的,有点像还没写完。确定所有内容都有转过来了吗?
-
测试驱动开发在项目中的实践 at 2020年12月07日
赞,这种实际实战出来的 tdd,比理念宣传 +demo 强多了。特别是写用例还要考虑后面其他同学的维护成本,从这个角度考虑,用例是越少越好,只要能把握住最核心的功能就可以。
-
各位大佬求指教安卓 7 以上版本怎么抓包 at 2020年12月07日
抓包时不用安卓 7 系统的可以不?
基本上应用不大会根据系统版本发不同的请求吧。
-
如何选择元素定位方式 at 2020年12月06日
个人经验:
能用 id 尽量 id,一般 id 能保证唯一性,且基本不会变(一般是做业务逻辑用的,就算改界面布局也不会动到)
不能 id 再考虑 xpath 或 css -
厦门 “泰斯特 Club” 第一届测试技术沙龙 at 2020年12月06日
支持一下,孔老师好样的!
-
没有人测出微博的 bug 吗 at 2020年12月06日
第 2 点有点没看懂,小号指的是手机号还是微博账号?好像没见过有什么系统登录后会显示不止一个用户的,不知道微博是否有这样的设计。
然后第 3 点,你用微信登录有有绑定回你的手机号吗?正常来说直接微信登录由于拿不到除了微信 id 之外的信息,所以其实没法和你自己手机号绑定的,得人工绑定,且一般要求此时手机号没有绑定过其他账号(按照实名制的要求,一般 1 个手机号只能 1 个账号,确保身份唯一)
第 4 点,爹是谁,娘是谁?建议除了步骤外,也写上你的预期结果和实际结果吧,这样更清晰,现在通过步骤没看懂你觉得怎样才是对的,所以都不知道具体问题在哪。
-
没有人测出微博的 bug 吗 at 2020年12月06日
看半天没看懂什么 bug,能分步骤 1234 说么?
-
11111 at 2020年12月05日
额,不建议强调 “女” 这个特点,这个帽子太大。我以前团队里女生都很强的,有追求也耐压,干起活来不必男生差甚至更好,所以不要一上来就 “女测试” ,让人有歧视嫌疑。
其实这种问题和男女关系不大,也有遇到过男的类似这样的同学。基本上特点是比较关注工作和生活的平衡,工作之余应该自己也有不少的活动安排,一旦工作加班就会对这些活动产生比较大的影响。倒也没问题,每个人都有自己的追求,只是可能不一定适合自己团队。不妨面试的时候问下对加班的态度如何,可以了解到一些端倪。
不过我觉得,核心点是你招聘时不知道出于什么原因,太倾斜她了,别人都要求的到了她身上就没要求了。这些导致你招了一个其实不那么符合岗位要求的同学进来。
感觉她应该会稳定一些不知道依据是什么?另外,请不要在面试时产生因为是男生/女生,所以要区别对待的想法。和工作无关的一些人性化的事情可以区别一下(比如加班时尽量男生先上,绅士风度帮忙做一些体力活之类的),但面试考察的是基础能力,这个地方上降低要求的话,后面双方都痛苦。
-
mock server 实践 at 2020年12月05日
知道了,踩了暗坑,port forward 模式下转发时,一些和 host 有关的内容没有做替换,只是把内容做了转发。比如 header 里的 host 没改为 proxyRemoteHost 的值。所以背后真实服务看到 host 不大对,就不会正常返回了。
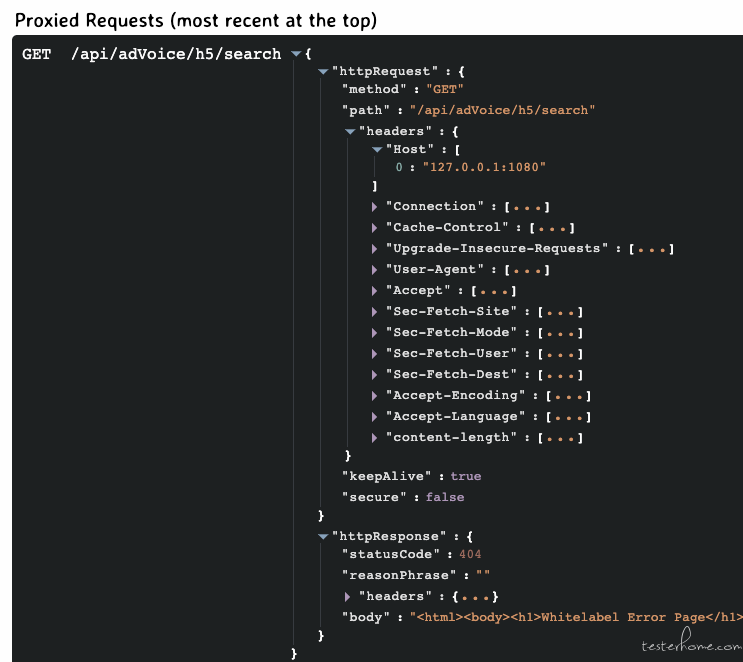
我实际启动命令里的相关配置:
java \ -Dmockserver.initializationJsonPath=${mock_file_path} \ -Dmockserver.watchInitializationJson=true \ -jar mockserver-netty-5.11.1-jar-with-dependencies.jar -serverPort 1080 \ -proxyRemotePort 80 \ -proxyRemoteHost xxx.lizhi.fm根据日志,转发时使用的 Url 和 header 中 host 字段还是 127.0.0.1:1080 ,不是我配置的 proxyRemote 相关信息。而且通过查服务端日志,会没有相关日志,估计是被框架层处理,都到不了业务逻辑层。
给请求加上 -H 'Host: xxx.lizhi.fm' 后,才能正常返回。详细的后面得再看看源码。
-
mock server 实践 at 2020年12月05日
开发场景,客户端和服务端同步开发,客户端前期需要通过 mock 获取所需返回值。
测试场景也偶尔会用到,用于模拟返回特定错误码。试用了下 port forwarding 的 proxy 方法,配置了 proxyRemotePort 和 proxyRemoteHost 。通过 mock-server 访问返回 404,但直接访问是可以的,看来还要再看看具体源码了。
-
VUE 传递数据 at 2020年12月04日
这个片段看得有点一头雾水,如果是个人笔记可以放在记事本里面?
-
mock server 实践 at 2020年12月04日
命中规则返回 mock response, 没有命中规则的话转发给真实服务。
这个是这个 java 应用直接具备的功能,还是通过文中的 go 脚本实现的?看了下 go 脚本,貌似没见到有相关的逻辑。文中的 java mockserver 有提供 proxy 的方式,但也必须要在被测服务里加配置才能实现。
目前实际项目里,需要用到这种指定规则的 mock,非指定的走真实流量。找到的各种 mock 基本都是 mock 整个服务,或者需要到被测系统里加配置,缺少类似网关的实现方式自由选择哪些 mock 哪些直接转发,不大合适。
-
input 框的删除问题汇总。 at 2020年12月04日
客气啦。
建议下次遇到这类问题,可以先从开发源码角度看看,开发是怎么做的,再去倒推测试怎么做。现在前端已经发展到基本不怎么需要接触最原生的 html 和 js 的程度了,甚至 css 也基本用框架提供的预置 class,但 selenium 等测试工具为了通用,操作的还是最底层的原生控件。
-
input 框的删除问题汇总。 at 2020年12月03日
看到正文更新的源码了,确实是基于双向绑定获取 input 的内容,然后再把 双向绑定的 js 中属性值(在你正文源码里对应的是 formMess.phone ) 放到请求里发给服务端。很常见的 vue 写法,没什么问题。
我也试验了下,vue 的双向绑定应该是基于输入框的一些内容变化的 event 触发的,具体是哪些 event 没深入研究过不大了解。而这些 event 可能没法监听你用 selenium 直接操作 input 输入框 value 这种场景(这种场景用户是做不出来的,只有程序能做出来,所以 vue 不考虑也正常),所以没有触发属性值的更新。
具体试验方式:在 https://vuejs.org/v2/guide/forms.html#Basic-Usage 中,找到 text 的示例,通过 js 直接修改 input 输入框的 value ,输入框的值更新了,但进行双向绑定的 message 没有更新:

一般用 vue 编程,实际发送请求用的是双向绑定后 v-model 里面的属性值,所以有可能这个原因你通过编程直接改变的 input 值,没有同步更新到 v-model 对应属性值里。而你 ctrl+a 再用退格键,基本就和用户操作一样了,所以 event 能捕获到。
-
input 框的删除问题汇总。 at 2020年12月03日
贴下开发相关的源码吧?看描述有点一头雾水。如果用的 vue ,把 *.vue 文件的源码贴上来,包括模板部分和 js 部分
得先搞清楚开发怎么实现的输入框提交,才能对应找到最佳的清除方式。vue 这类框架底层自动做了双向数据绑定,输入框的值变化会自动引起某个 js 里面变量的变化,js 变量变化也会自动引起界面绑定元素的变化,所以光看 F12 的编译后代码 html 部分是看不出怎么做的,很多动作是在 js 库中实现的。
PS:如果用了 vue,一般都不会用这个 html 内置的 submit 事件来提交了,因为限制了必须用 form 格式提交,服务端不一定用这个格式解析。结合用 axios 调后端接口更爽呀。
-
通用的 Java 接口白盒测试,大家都是怎么进行的呢? at 2020年12月03日
都做 Java 接口级别的测试了,还要专门搞个工具给没有代码能力的同学去测试,感觉是不是有点本末倒置?
不是应该想办法让大家学习掌握些测试所需的写代码能力么?做代码相关的测试,却不掌握代码能力,那不如让开发直接基于 sdk 能力搞个 app(类似各种控件 demo app),让你界面直接调用 sdk 提供的各项功能,做黑盒测试?