Python python 中封装日志 logging,为何打印行号固定在同一行?
python 封装日志如下
在用例中使用时:
Logger("日志消息", "testcase")
但是日志中打印全部都是打印的是,封装的这个文件的第 25 行,即 logger = logging.getLogger(),为什么?
请问如何改呢?不希望在用例还使用 logging 库中的函数。
import logging
import time
import os
class Logger:
@classmethod
def logger(cls):
file_path = "../resource/log/%s/" % time.strftime("%Y%m%d")
if not os.path.exists(file_path):
os.makedirs(file_path)
file_name = file_path + '%s_log.log' % (time.strftime("%Y%m%d"))
logging.basicConfig(
level=logging.INFO,
format='%(levelname)s %(asctime)s %(filename)s[line:%(lineno)d] %(message)s',
datefmt='%Y-%m-%d %H:%M:%S',
filename=file_name,
filemode='a'
)
return logging.getLogger()
@classmethod
def info(cls, text):
Logger.logger().info(text)
@classmethod
def error(cls, text):
Logger.logger().error(text)
@classmethod
def debug(cls, text):
Logger.logger().debug(text)
@classmethod
def warning(cls, text):
Logger.logger().warning(text)
@classmethod
def print_info(cls, text):
print(text)
Logger.logger().info(text)
@classmethod
def print_error(cls, text):
print(text)
Logger.logger().error(text)
@classmethod
def print_debug(cls, text):
print(text)
Logger.logger().debug(text)
@classmethod
def print_warning(cls, text):
print(text)
Logger.logger().warning(text)
你应该返回 logger 对象,在调用相应的方法
打印的行号是调用 logger 对象的所在行。你现在封装后 logger 对象永远只有你这个类在调用,别的类都没调用,所以行号都在你自己这个类里了。
PS:看你的用法,应该是想打印的日志里带有用例名称?这个原生 loggging 框架完全可以做到的,用 logging.getLogger(__name__) 就可以了。
分享一个在书中看到的方法,个人觉得非常巧妙。
先通过装饰器获取调用栈的信息
import sys
def findcaller(func):
def wrapper(*args):
# 获取调用该函数的文件名、函数名及行号
filename = sys._getframe(1).f_code.co_filename
funcname = sys._getframe(1).f_code.co_name
lineno = sys._getframe(1).f_lineno
# 将原本的入参转变为列表,再把调用者的信息添加到入参列表中
args = list(args)
args.append(f'{os.path.basename(filename)}.{funcname}.{lineno}')
func(*args)
return wrapper
在自己封装的日志模块中调用装饰器,并把调用者信息加到日志输出中去
@findcaller
def log_info(self, msg, caller=''):
self.logger.info(f'[{caller}] - {msg}')
原来是:
logger = logging.getLogger()
logger.info(msg)
我想要自己的这个类 Logger 替代 logger.info,直接 Logger(……) 就可以了,请问可以实现吗
您好,谢谢,请问这样的话在外面只能先建立一个 Logger 的实例,然后调用其中的方法,感觉很不方便,可以不可以直接每次创建 Logger 实例的时候直接就建立一条日志了呢,即 Logger 类替代 logger.info,直接 Logger(……) 就可以了
换一种思路。每次 info 的时候实例就已经创立好了。你看我前面贴的代码,可以实现直接调用 info 方法,而不需要显式的先创建示例。因为 info 方法内部已经创建好了实例
我刚刚试了一下,感觉这样确实挺灵活的。另外现在的 basicConfig 可以加 handlers,所以不用写 print log 了。如下:
# 打印到控制台
stream_handler = logging.StreamHandler()
# 回滚文件输出
rotating_handler = RotatingFileHandler(filename, maxBytes=1024*1024*5, backupCount=10)
# 设置logging的输入内容形式及输出渠道
logging.basicConfig(format=fmt, datefmt=date_fmt, level=logging.INFO, handlers=[stream_handler, rotating_handler])
我想要自己的这个类 Logger 替代 logger.info,直接 Logger(……) 就可以了,请问可以实现吗
你现在的就是这个方式的实现了,因为你这里是一个类的初始化方法,所以 logger 对象肯定是在你的初始化方法里初始化的,没法获取到你这个 Logger("xxx") 被调用的位置
用 @cheunghr 的方法就可以了。你想要不 new 直接调用方法,其实就是调用静态方法(python 里对应就是有 @classmethod 注解的类方法),用这个思路就可以了,只是这种用法其实有点怪。
日常接触,大部分用法是使用模板模式,搞个用例基类,里面已经初始化好 logger 对象,然后用例里面直接用 logger.info() 就直接记录日志。这样也不浪费 getLogger(__name__) 可以让日志打印出所在类的特性。而且这种情况下,除了 logger 对象,还可以有很多通用的对象可以在基类里面初始化(比如 UI 自动化里初始化 driver ,或者接口测试里面初始化一些和数据库的连接),节省用例里面额外 new 的语句。
看了不少代码后,个人感受大部分时候规范的写法比自己想出来的极简的写法综合起来更好,因为这些规范都是前人经过无数踩坑后总结的最佳实践,能满足最常用的场景且也有足够的灵活性,关键是这些使用姿势以后换公司换框架都能继续沿用,而不会被框架特有写法绑定死。至于这些规范写法或者优雅写法怎么写,建议可以看看 Python cookbook
后来我反复地看了您这段话,有几个问题想要确认一下:
1.这个基类可以说是一个工具类,那么如何保证单例性呢,比如基类中有一个公用的 driver,假设基类为 Utils,是否是如下的方式:
class Utils:
def init_driver():
""""初始化driver"""
return driver
utils = Utils()
driver = utils.init_driver()
# 在用例中导入driver即可
2.如果是以上方式,是否这个包会非常频繁地被导入,甚至有 from utils import driver, logger,...,这样子地导包感觉不是很优雅。
以上问题出于我对代码规范以及设计模式还是不太了解,我只是以自己看代码的舒适度来判断,所以如果有不对的地方请谅解。
基类不是工具类,他是要被继承的。
通过继承,子类拥有父类已拥有的东西,子类不用重复编写或者引入这些东西。
推荐你找个相对流行的 UI 测试框架,看看它自带的 demo 之类示例看看,你需要先扩展视野,要不你的感觉是不大准的。
曾经见过为了写法上节省个 new,然后全部类都搞成静态类,然后由于对象共用,导致用例间相互影响无法并行的,这就有点捡了芝麻掉了西瓜了。
现在使用的框架是 selenium+python+unittest。
晚上确实有查到 unittest 存在一个用例基类,但是我不仅想把在用例里写日志,还想在 basepage 中封装每个 selenium 的方法时写日志,所以考虑到是否是工具类。
如果仅是用例基类,basepage 中及其它地方则无法使用日志。
好像这样子日志的封装能够比较优雅的完成,且行号正确。
继承 Logger 方法,在里面对 Filter, handler 进行一些赋值
这就是继承了 logging.Logger 模块,是可以做到你说的 filter 、handler 赋初值。但这个我理解不改变 logger 的调用方式吧?
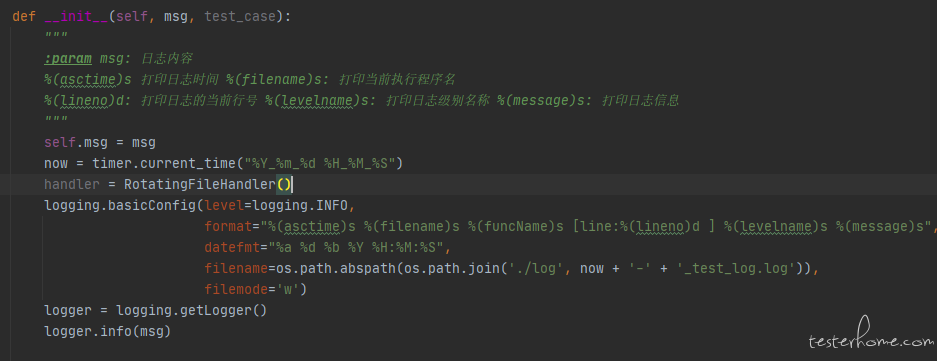
确实不改变,我也尝试了你说的方式,感觉用例基类的方式也是不改变的:
class BaseCase(unittest.TestCase):
@classmethod
def setUpClass(cls) -> None:
# 获取当前时间
now = timer.current_time("%Y_%m_%d")
filename = dir_config.logs_dir + r"\{}.log".format(now)
# 格式
# %(asctime)s 打印日志时间 %(filename)s: 打印当前执行程序名
# %(lineno)d: 打印日志的当前行号 %(levelname)s: 打印日志级别名称 %(message)s: 打印日志信息
fmt = "%(asctime)s %(filename)s %(funcName)s [line:%(lineno)d ] %(levelname)s %(message)s"
date_fmt = "%a %d %b %Y %H:%M:%S"
# 打印到控制台
stream_handler = logging.StreamHandler()
stream_handler.setLevel(logging.ERROR)
# 回滚文件输出
rotating_handler = RotatingFileHandler(filename, maxBytes=1024 * 1024 * 5, backupCount=10)
# 设置logging的输入内容形式及输出渠道
logging.basicConfig(format=fmt,
datefmt=date_fmt,
level=logging.INFO,
handlers=[stream_handler, rotating_handler])
cls.logger = logging.getLogger(cls.__name__)
在其他用例中即使用self.logger.info(...)
要把 self.logger 省掉也是可以的:
class BaseCase(unittest.TestCase):
@classmethod
def setUpClass(cls) -> None:
# 获取当前时间
now = timer.current_time("%Y_%m_%d")
filename = dir_config.logs_dir + r"\{}.log".format(now)
# 格式
# %(asctime)s 打印日志时间 %(filename)s: 打印当前执行程序名
# %(lineno)d: 打印日志的当前行号 %(levelname)s: 打印日志级别名称 %(message)s: 打印日志信息
fmt = "%(asctime)s %(filename)s %(funcName)s [line:%(lineno)d ] %(levelname)s %(message)s"
date_fmt = "%a %d %b %Y %H:%M:%S"
# 打印到控制台
stream_handler = logging.StreamHandler()
stream_handler.setLevel(logging.ERROR)
# 回滚文件输出
rotating_handler = RotatingFileHandler(filename, maxBytes=1024 * 1024 * 5, backupCount=10)
# 设置logging的输入内容形式及输出渠道
logging.basicConfig(format=fmt,
datefmt=date_fmt,
level=logging.INFO,
handlers=[stream_handler, rotating_handler])
cls.logger = logging.getLogger(cls.__name__)
def log(str):
self.logger.info()
子类里面直接调用 log("我是日志") 就可以打印日志了,基本简化到和你 Logger("日志") 差不多了,但看你有没有必要咯,别人看起来可能会比较奇怪。
PS: 上面不建议搞静态(类)方法,静态和动态混在一起会比较乱,全动态方法(不带有 @classmethod 注解的方法)就好了,这样每个子类都是独立的,不会相互影响,也比较清晰。
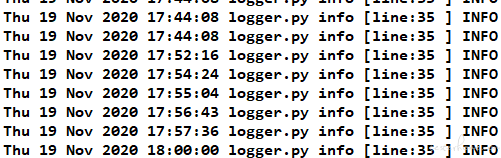
这样做不是看起来奇不奇怪的问题,而是这样做到时候日志里面显示日志所在行和所在文件会是固定的,都是 BaseCase 这一行。所以我放弃了这个方式。
好的,谢谢你耐心解答我的疑惑。我也学到了用例基类这个方法,虽然我不是接口测试,只是 web UI 测试,但是感觉还是很好用的
您好,网上用例基类的信息非常少,对于它的使用我仍然存在疑惑但是无法找到答案:
1
如果我想要对每个用例出错时进行处理,比如截图,记录日志之类的,是否可以不对每个 test case 进行处理,而是在BaseCase里面处理就可以呢?
目前我想到的是,使用函数装饰器,在每个用例前加上@decorator_name,装饰器如下:
def decorator_name(url):
def decorator(fun):
@wraps(fun)
def wrapped_function(self, *args, **kwargs):
# 传入url,做判断
if self.driver.current_url != url:
self.driver.get(url)
try:
fun(self, *args, **kwargs)
except:
# 如果用例发生了问题,则进行一些错误处理
raise
return wrapped_function
return decorator
这些操作每个用例是相同的,所以没必要每个用例都写一遍,但是装饰器有时候也会容易忘记,是否可以通过BaseCase解决这个问题呢?
2
或者在每个用例类中都有一个专门的变量 x,但是在进入用例前,我需要对 x 进行一些判断,比如 x 是否大于 1,这个肯定是需要一个装饰器传入参数的,我想过在BaseCase上将这个装饰器装饰到 setup 上,但是如何把值传过来呢?在这个场景中,是否可以用用例基类呢?
1、每个用例出错进行截图,这个建议直接在 unittest 的 fail hook 里面直接加就好了,不用弄 BaseTestCase,如果有 driver 实例,那就调用一下 driver 的截图函数。写用例的人不用管任何事情。
fail hook 可以用这个方法 https://docs.python.org/zh-tw/3/library/unittest.html#unittest.TestResult.addFailure ,使用的实例可参考 https://github.com/SeldomQA/HTMLTestRunner/blob/master/TestRunner/HTMLTestRunner.py
2、没看懂你这个场景。能否举个具体的例子说明一下?
装饰器本身对应的是设计模式里的装饰器模式(https://www.runoob.com/design-pattern/decorator-pattern.html),是有自己对应的典型使用场景的,没看懂你的场景所以不知道是否适合。但装饰器应该是不支持继承的,所以应该做不到父类该函数加了装饰器,子类就可以不用加。
1.问的两个场景,一个用例执行前进行的处理,一个是用例执行后进行的处理。
2.场景:在每个用例发生前,我需要检查一下 url 是否为正确的,如果是,则直接进入用例,如果不是,则需要将将页面进入设定的 url,那么这个情况下,每个用例都有自己的 url,但是,如果每个用例去写一遍 if……else,对于代码的复用以及维护就不太方便了,如果之后这个逻辑变了需要每个用例去删除,如果用装饰器,我觉得也差不多,需要一个一个删,但是如果装饰器 +BaseCase 的setup,之后每个用例继承这个 Base Case,那么也继承了 setup,是否可行呢,但是也存在 url 无法传到BaseCase情况吧,这个场景该如何使用BaseCase呢,或者该如何实现呢?
3.这两天一直在读 HTMLRunner 代码,看懂了您发的实例,确实感觉有一定的实用性,在想 def startTest(self, test) 可否完成 2 中的场景?
1、你说的执行前和执行后,指的是 setUp 和 tearDown 吗?如果是,那可以把这些部分放在父类的方法里,子类 setUp 方法第一行调用下 super() 就好
2、这个场景,建议你可以直接不用做判断,直接都进入设定的 url,这样就不用 if else 了。由于这个部分每个 case 对应 url 有点不一样,复用度不高,建议你还是写在 case 里吧。
3、原理上可以实现,但这样有点把业务的东西带到框架里了,对框架通用性不大好,这点建议要综合考虑。
为什么要做判断是因为,每次测试之后都会 refresh 一下,这样会导致刷新两次,另外进入整个系统之前会 get url,那么第一个运行的用例也会 get url 两次,两次刷新/get url,我觉得不太好。所以判断一下比较好,我目前做的是使用一个装饰器,将其装饰到可能会涉及两个页面的用例上。
截图也是使用一个装饰器,装饰到在 Base Case 中重写的 assert*** 函数上,但是这样可能有不好的地方,我觉得截图还是放到 Runner 中更好。
我尝试在 addFailure 中截图,但是令人失望的是,它截图好像截的是在函数 tear down 之后的,我看不到真正发生错误时的图片,这是为什么呢
两次刷新/get url,我觉得不太好
具体是为啥不太好?为了让它不刷新,付出的成本比收益高,而且可能引起其他额外问题(比如有的 web 框架切换展示内容是不会改变 url 的,所以判断 url 并不准确)
对于你这个点,还有一种常用的办法,就是不要用原生 driver ,用你自己额外封装的 driver(driver 实例可以在 BaseTestCase 里面初始化,后面的用例只管用就是了)。然后改写里面的 get_url 方法,让它全部都先判断,不一致再切换 url。
您说的对,我做这个是为了改善重跑机制中如果用例使用了两个页面,跳转到第二个页面中时发生错误即使重跑也没有用的问题。
PS:不太好是觉得看着它一直刷新,领导会一脸???o( ̄┰ ̄*) ゞ不好意思
因为自动化刚起步,而且只有我自己做,暂时还没有落地,肯定要盯着看看效果。
刚刚我试了一下,addFailure会在tear down后面执行,如果这样的话,是否有一个问题,tear down不允许 refresh。
可以多试几个 hook 函数,找到最适合自己的。应该有函数可用的。
如果实在没有,那就规范限制 tearDown 里不要做 refresh 操作咯,或者考虑换个测试框架。毕竟 unittest 是 python 自带的一个能满足基本单测要求的框架而已,不是为集成测试设计的,功能丰富度不是很高。实际项目要支持各种扩展,一般用 pytest 或者 nose
好的,刚刚用您的建议尝试了一下,最终:
- url 的判断在封装的 driver 中,每次只需在
setUpClass中初始化 url 即可
2.用例失败时的截图在 TestResult中完成
3.用例错误时的截图我还是写了一个装饰器,原因是BasePage中已经封装了截图功能,在BasePage的每个函数中都引用了这个函数,要改动的地方比较大,装饰器只需要在封装截图函数处加一个 @ 即可。
你好,我有个问题和你的情况相似.我想实现的是,在日志中输出当前用例的名字,主要目的是想判断当前用例的执行的开始和结束.其中,我是每个 py 文件一个用例,每个用例继承一个基础用例 BaseCase,其中 BaseCase,里面只写了 setup 和 teardown,,,想在 setup 里面做文章,因为每个用例的 setUp 都一样.,请问这样该如何实现
正如上面讨论的,logger 可能还是要继承一下 Logging,不然行和函数什么的信息会出错。
我尝试过将用例名字放到日志里,我是这样做的,先用类 testCaseInfo 来表示用例的各种信息,如下:
class TestCaseInfo(object):
def __init__(self, test_id="", name="", owner="", result="Failed", start="", end="", error_info=""):
self.id = test_id
self.name = name
self.owner = owner
self.result = result
self.start = start
self.end = end
self.error_info = error_info
因为我跟你不一样,我一个 py 里面很多的用例,所以是用的函数装饰器,放到每一个用例的前后进行一些赋值,比如用例执行前,时间复制到 start
def create_test_info(func):
@wraps(func)
def wrapper(self, *args, **kwargs):
try:
# 这里就可以把用例的名字还有注释放进去啦!
self.testCaseInfo = TestCaseInfo(test_id=func.__name__, name=func.__doc__)
self.testCaseInfo.start = timer.current_time()
func(self, *args, **kwargs)
self.testCaseInfo.result = "Successful"
except Exception as err:
self.testCaseInfo.error_info = str(err)
logger.error(f"测试执行失败!错误信息:{err}")
raise err
finally:
# 这里是logger!
logger.info(f"测试{func.__name__}的详细信息:{result}")
return wrapper
不过还有类装饰器,如果你想直接在 BaseCase 一劳永逸,可以直接试试装在类上面的装饰器?
有一个链接,可以参考一下【类的函数装饰器:装饰器为函数,被装饰对象为类】https://blog.csdn.net/LaoYuanPython/article/details/111303395