版主
Rikasai (花菜)
第 18783 位会员 / 2017-06-30
81 篇帖子 • 538 条回帖
-
生成 100w 条数据,哪种方式最快 at 2023年07月28日
innodb_write_io_threads 默认值是 4,但没有 load data,user-threads 这个参数哦,多客户端的话就太麻烦了。
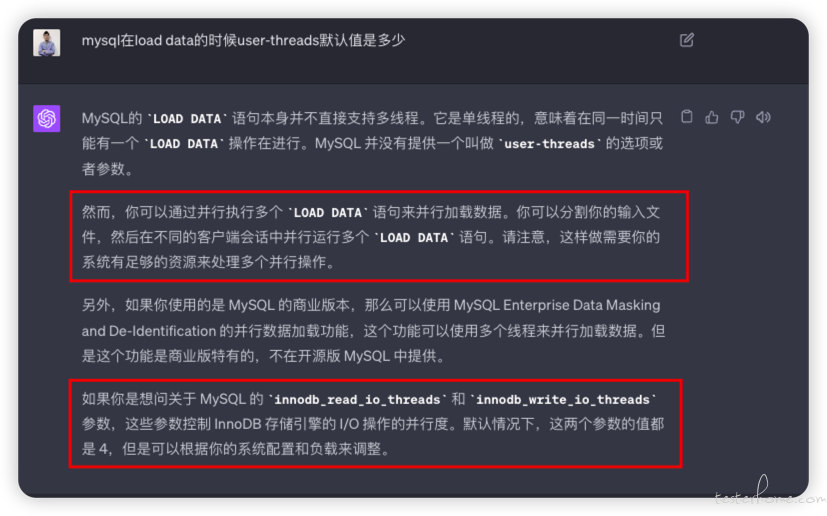
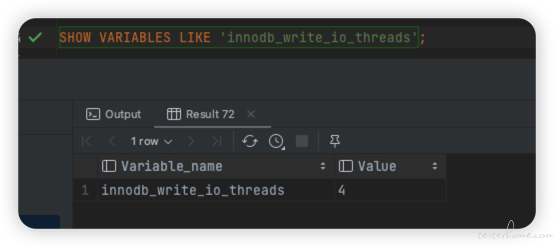
-
生成 100w 条数据,哪种方式最快 at 2023年07月28日
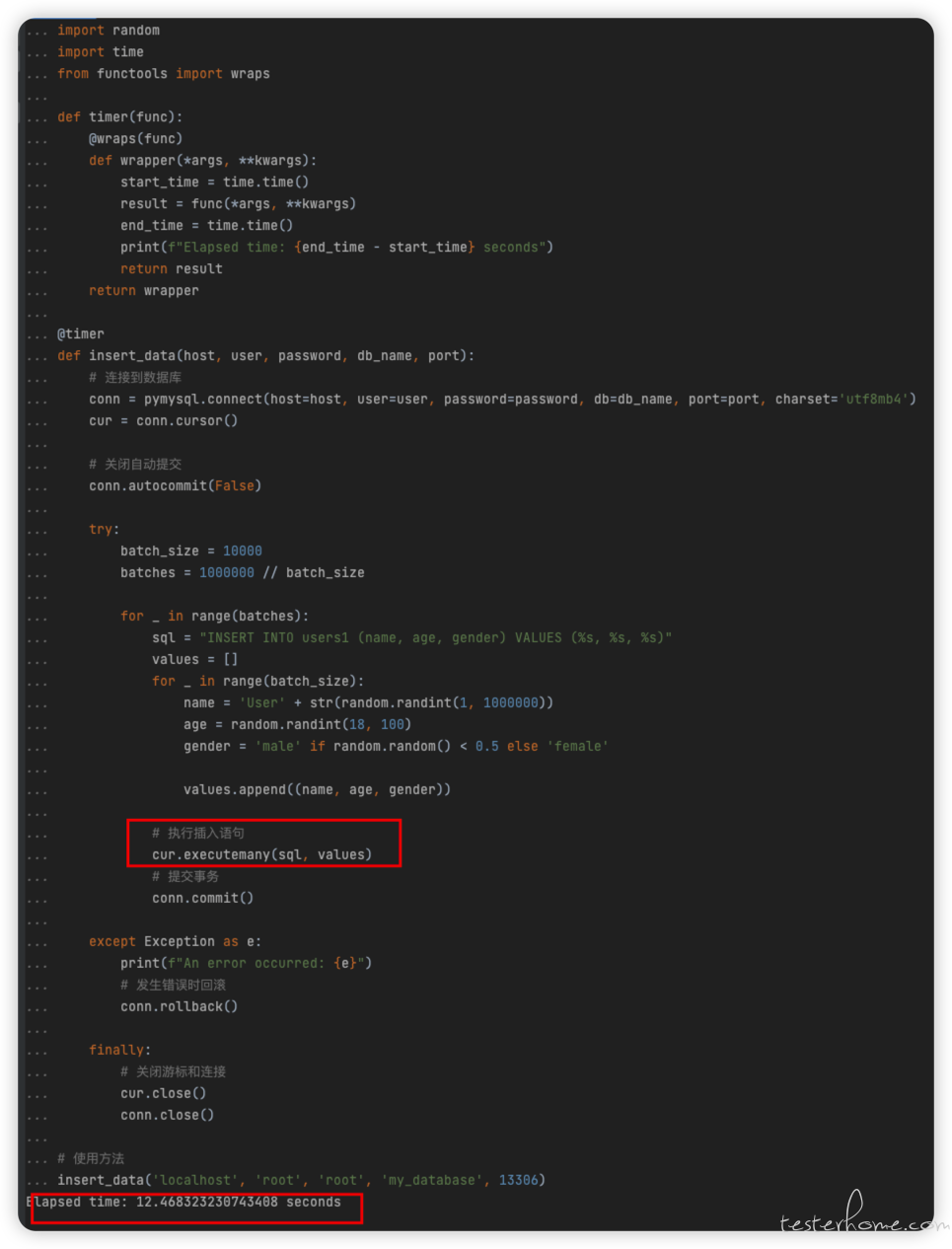
这里是一个线程,但是用分批 + 批量的方式,效率会有大幅度提高 -
生成 100w 条数据,哪种方式最快 at 2023年07月27日
白嫖的,只能将就啦
-
生成 100w 条数据,哪种方式最快 at 2023年07月27日
读取文件不会是瓶颈,频繁的网络 io 才是瓶颈;
后面测试了 Python 分批提交,效果会好很多 -
生成 100w 条数据,哪种方式最快 at 2023年07月27日
我用手机打开没问题哦,可能是 CloudFlare 的 R2 图床对部分地区不友好

-
生成 100w 条数据,哪种方式最快 at 2023年07月27日
存储过程是 gpt4 写的,效率上可能存在一定问题,有懂的大佬,欢迎指正
-
禅道指派 bug 关闭情况监控 at 2023年07月26日
crontab 就好了,为啥要搞一个 Jenkins 哦
-
聊聊最近找工作和入职新公司的感悟 at 2023年07月21日
可以关注我公众号,会分享一些通用的
-
各位大神,大家都用什么开源测试用例管理平台? at 2023年07月20日
写个脚本自动备份 db 就好啦
-
测试该干点啥提升自己? at 2023年07月15日
应该是 spring boot,不是 sprint boot?
业务也技术都到头了,现在有开始带人,拉通对齐研发和产品了吗
另外坐等拿赔偿也是不错的选择
-
聊聊最近找工作和入职新公司的感悟 at 2023年07月14日
阔怕,9 点还好,已经卷到 ptsd 了吗
-
聊聊普通人如何应对 chatGPT at 2023年07月05日
有个疑问,什么才是革命性的平台解决方案,历史上哪些产品属于这个。
-
聊聊最近找工作和入职新公司的感悟 at 2023年06月27日
是啊,所以建了群,说不定就能帮上忙
-
聊聊最近找工作和入职新公司的感悟 at 2023年06月26日
然而我有。。。
-
聊聊最近找工作和入职新公司的感悟 at 2023年06月25日
嗯呐,有空会更新的,关注就好
-
聊聊最近找工作和入职新公司的感悟 at 2023年06月24日
-
聊聊最近找工作和入职新公司的感悟 at 2023年06月21日
停更了快半个月,终于有时间写点东西啦~~
-
Python 方法能在参数位置就设定传入参数的可选择范围吗? at 2023年06月20日
安装 pydantic
pip install 'pydantic[dotenv]'执行以下代码
from pydantic import Field, validate_arguments, ValidationError @validate_arguments def my_func(i: int = Field(..., ge=1, le=100)): # 你的函数逻辑在这里 print(f"Input {i} is within the valid range.") try: my_func(50) # 正确的输入,应该打印"Input 50 is within the valid range." my_func(150) # 错误的输入,会引发ValidationError异常 except ValidationError as e: print(f"Invalid input: {e}")输出
Input 50 is within the valid range. Invalid input: 1 validation error for MyFunc i ensure this value is less than or equal to 100 (type=value_error.number.not_le; limit_value=100) -
请问如何用 python 实现表格去重不改变原表格格式 at 2023年05月24日
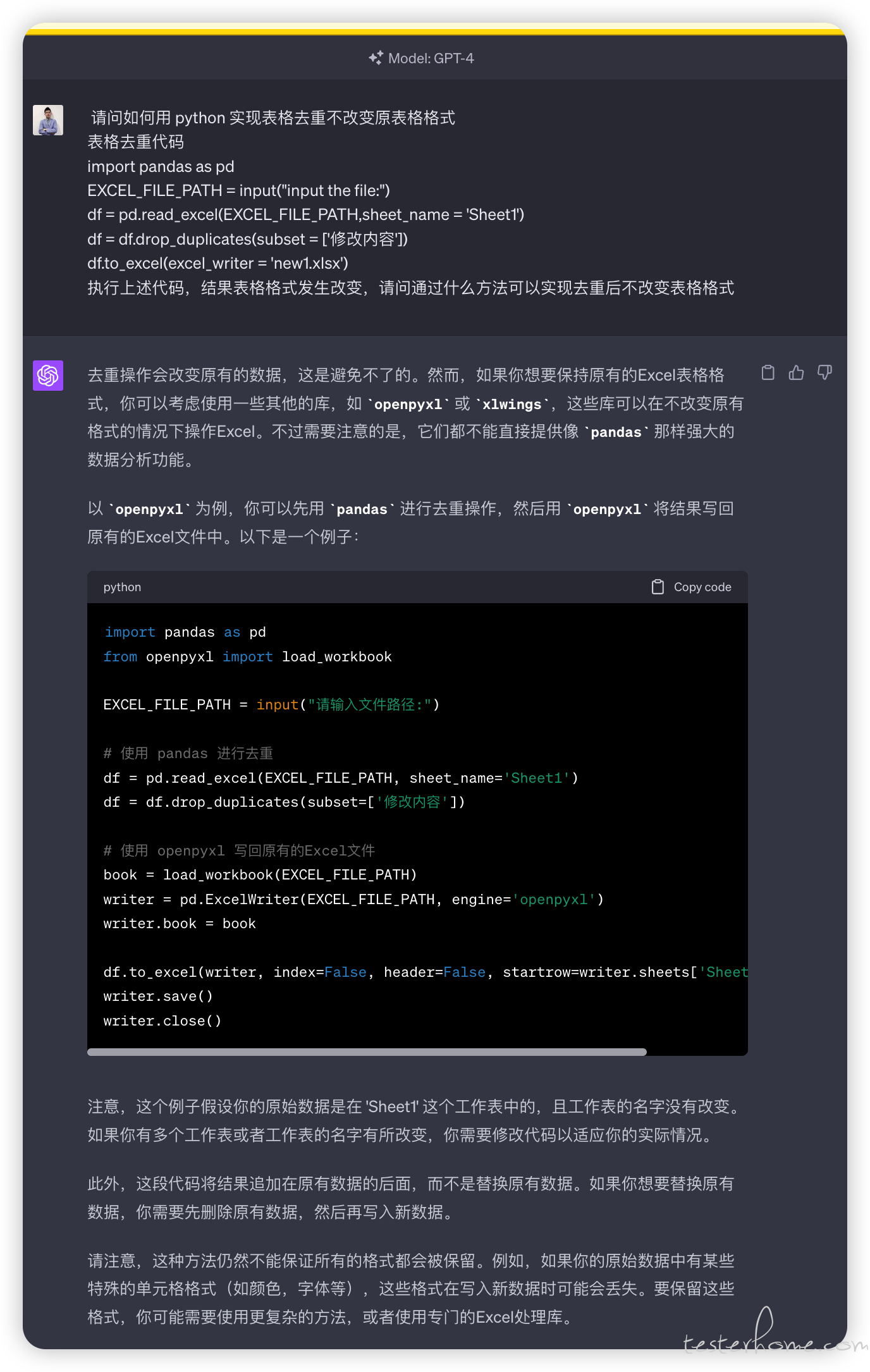
import pandas as pd from openpyxl import load_workbook EXCEL_FILE_PATH = input("请输入文件路径:") # 使用 pandas 进行去重 df = pd.read_excel(EXCEL_FILE_PATH, sheet_name='Sheet1') df = df.drop_duplicates(subset=['修改内容']) # 使用 openpyxl 写回原有的Excel文件 book = load_workbook(EXCEL_FILE_PATH) writer = pd.ExcelWriter(EXCEL_FILE_PATH, engine='openpyxl') writer.book = book df.to_excel(writer, index=False, header=False, startrow=writer.sheets['Sheet1'].max_row) writer.save() writer.close()可以试试这个
-
提升开源项目质量与效率:使用 GitHub Actions 自动化流程 at 2023年05月19日
真不错啊!
-
GPT 支持联网了,插件好强啊 at 2023年05月18日
嗯,这仅仅是一个简单的例子。GPT 的强大之处,我在别的文章有体现过呢
-
GPT 支持联网了,插件好强啊 at 2023年05月17日
-
GPT 支持联网了,插件好强啊 at 2023年05月17日
-
GPT 支持联网了,插件好强啊 at 2023年05月16日
ChatGPT 真的是个划时代产品,没用过的童学,强烈建议试试。
呜呜呜,求关注一波公众号,目前人数太少了,不到 200 人,连开启广告的资格都没有。 -
我是这样玩转 Linux《二》- ZSH at 2023年05月12日
 舒服
舒服