-
社区升级后有问题请在此反馈 at 2021年01月17日
一下子不是很习惯~
感觉新版的间距太大了
另外一个问题是看到有消息提醒,但是点击进去,提示为空的
-
社区升级后有问题请在此反馈 at 2021年01月17日
谢谢,搞定~
-
社区升级后有问题请在此反馈 at 2021年01月17日

Mac 16 寸
Chrome 87.0.4280.141
想问一下,怎么切换回去白色主题 -
面试题:你工作中碰到的印象比较深的 bug,你怎么处理的? at 2021年01月12日
记一个自己写的 bug(对全局变量,类变量生命周期不理解导致的)
有个变量叫 today,是格式化后的今天日期,很多地方用到,我就把它封装到了工具类的全局变量中。
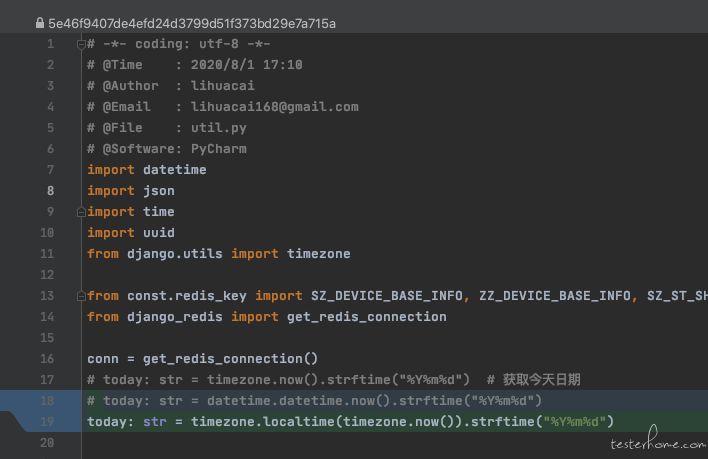
本地调试没问题,结果是正常,在服务端跑也是正常的。可是第二天获取的日期就不对,还是前一天的日期。
难道是缓存的问题?重试服务试试,结果还真的就行了。搞定,笑嘻嘻~
可是到第三天,怎么又是变成了前一天的日期???真的是见鬼了。
本地调试看看,代码没问题啊,能正常获取。这到底是怎么回事啊!
难道 Python 标准库出问题了?不会吧。换 Django 日期工具类试试。
推送代码,重新部署服务,看看获取结果,一切正常。妥妥的。这下应该不会再有问题了吧?
又是一天早上,哦豁,怎么结果又是获取了昨天的日期。
我不信,重启服务。嗯,结果是对的,果然重启能解决 99% 的问题。
就这样,通过定时任务每天重启服务的方式过了几个月。直到有一天,要获取一个当前时间戳的变量,也是很多地方用到。代码大概是这样
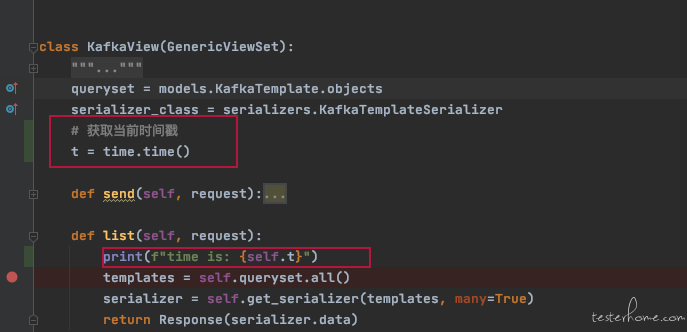
一看日志,恍然大悟[12/Jan/2021 21:17:15] "GET /api/kafka/config/ HTTP/1.1" 200 216 time is: 1610457411.562096 [12/Jan/2021 21:17:26] "GET /api/kafka/template/ HTTP/1.1" 200 5838 time is: 1610457411.562096 [12/Jan/2021 21:17:29] "GET /api/kafka/template/ HTTP/1.1" 200 5838 time is: 1610457411.562096 [12/Jan/2021 21:17:31] "GET /api/kafka/template/ HTTP/1.1" 200 5838可以看到打印的 t 一直是没变化的,但日志时间是不停变化的
t 是类变量,并不会在 list 方法结束后就释放内存,然后下次请求进来重新获取。而是程序重启之后才会重新获取。
之前 today 那个坑不容易看出来,因为是日期,隔天才变化。 -
软件测试基础 (一): 单元测试 at 2021年01月11日
Java 的没有,给个 Go 的~
需求

代码实现
package simple import "strconv" func summaryRanges(nums []int) []string { ans := []string{} n := len(nums) if n == 0 { return ans } for i := 0; i < n; i++ { for j := i; j < n; j++ { cur := nums[j] var next int if j != n-1 { next = nums[j+1] } if j == n-1 || next-cur > 1 { if j == i { ans = append(ans, strconv.Itoa(cur)) } else { ans = append(ans, strconv.Itoa(nums[i])+"->"+strconv.Itoa(cur)) } i = j break } } } return ans }单元测试
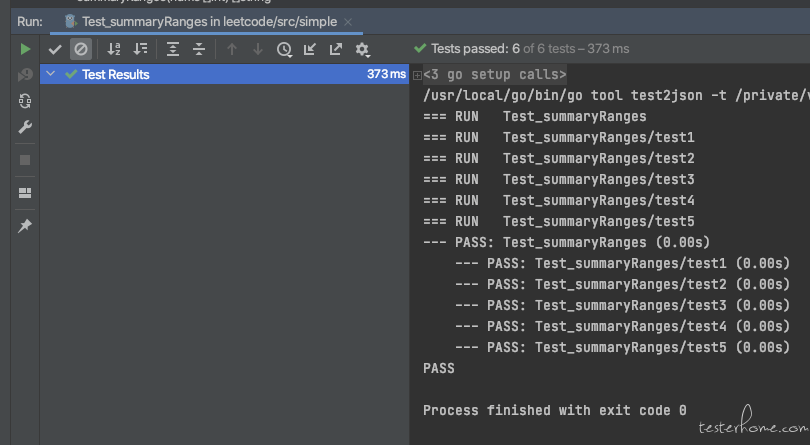
package simple import ( "reflect" "testing" ) func Test_summaryRanges(t *testing.T) { type args struct { nums []int } tests := []struct { name string args args want []string }{ // TODO: Add test cases. {"test1", args{nums: []int{0, 1, 2, 4, 5, 7}}, []string{"0->2", "4->5", "7"}}, {"test2", args{nums: []int{0, 2, 3, 4, 6, 8, 9}}, []string{"0", "2->4", "6", "8->9"}}, {"test3", args{nums: []int{-1}}, []string{"-1"}}, {"test4", args{nums: []int{0}}, []string{"0"}}, {"test5", args{nums: []int{}}, []string{}}, } for _, tt := range tests { t.Run(tt.name, func(t *testing.T) { if got := summaryRanges(tt.args.nums); !reflect.DeepEqual(got, tt.want) { t.Errorf("summaryRanges() = %v, want %v", got, tt.want) } }) } }执行结果
-
HttpRunner v3.x 中文文档 at 2021年01月08日
这也太酷了!
-
用例管理平台 at 2021年01月07日
嗯嗯,搞定了
-
[深圳-南山-科技园] 智看科技 招聘测试开发岗 1 人 at 2021年01月05日
枚举了一下答案,正确邮箱应该是 C 的。
假设 A 是说真话,得 A 的邮箱是假的,B 说假话,得 A 邮箱是假的,C 说假话,得 C 邮箱是真的,D 说假话,得 B 邮箱是假的。成立。 -
在线脑图测试用例管理平台求推荐~ at 2021年01月05日
看了一波,感觉还是 agileTC 比较合适,这个是客户端,我比较期望是 web 模式。
-
在线脑图测试用例管理平台求推荐~ at 2021年01月04日
体验中,后续会小改
-
在线脑图测试用例管理平台求推荐~ at 2021年01月04日
嗯嗯,看到了。也部署好体验一波,agileTC 体验不错
-
在线脑图测试用例管理平台求推荐~ at 2021年01月04日
确实满足的,调用阶段想多看看
-
在线脑图测试用例管理平台求推荐~ at 2021年01月04日
这个不是开源的呀
-
在线脑图测试用例管理平台求推荐~ at 2021年01月04日
已经部署了,不满足需求~
-
在线脑图测试用例管理平台求推荐~ at 2021年01月04日
这个有看到,部署的时候遇到问题,一直起不来。在社区的帖子下面回复了,作者木有回复
-
基于 HttpRunner 的接口自动化测试平台宣讲 (已落地) at 2021年01月04日
没有的,文档有在线 demo
-
求一个开源的自动化测试平台 最好是 vue+python 开发的 at 2021年01月04日
我想这个应该能满足你的需求~
https://www.yuque.com/lihuacai/sggdx7/cn5ncg -
坎坷的 2020 年 at 2021年01月04日
嗯嗯,FasterRunner 本身做得不错,比较简单易用。我另外把优化完的开源出来,阔以一起探讨~
https://www.yuque.com/lihuacai/sggdx7/cn5ncg -
mac 版 jmeter,运行脚本后 cpu 爆满,能耗超高,100% 的电量十几分钟能全部耗完 at 2021年01月04日
需要很高并发的话,安利一波这个https://testerhome.com/topics/24998
-
mac 版 jmeter,运行脚本后 cpu 爆满,能耗超高,100% 的电量十几分钟能全部耗完 at 2021年01月04日
我当时也是测试 mqtt 的,难道是 mqtt 插件的问题..
-
mac 版 jmeter,运行脚本后 cpu 爆满,能耗超高,100% 的电量十几分钟能全部耗完 at 2021年01月04日
Mac 版的 Jmeter GUI 很难用,神烦!莫名其妙的 CPU 就爆满,我还以为只有我自己是这样
-
好消息,社区专栏新功能来啦! at 2021年01月04日
可以增加一些条件来先过滤一波嘛,比如说注册时间满三个月,已发表文章数量大于多少篇之类的。只有满足这些条件的用户先才是申请入口就好了。
-
坎坷的 2020 年 at 2021年01月04日
没错,就是~
-
基于 HttpRunner 的接口自动化测试平台宣讲 (已落地) at 2021年01月04日
不好意思呀,不知道 st 是谁~
-
2020 年 个人总结:35 岁,从阿里到国企 at 2021年01月04日
恭喜大佬成功” 转"