-
昨晚虾皮一面面试官出的一道题:利用随机生成(0,1)方法随机生成 0~1000 的数 at September 10, 2021
哈希值是由前面生成的随机字符串决定的呀。这样才会更加均匀
-
昨晚虾皮一面面试官出的一道题:利用随机生成(0,1)方法随机生成 0~1000 的数 at September 10, 2021
- 生成 n 位随机浮点数 f
- 然后浮点转成字符串
- 字符串取 hash 值,然后再取绝对值
- 最后除 1000,取余
abs(hash(str(f))) % 1000
-
记一次专场面试经历 at September 06, 2021
超过 25
-
记一次专场面试经历 at September 06, 2021
嘿嘿,这个不太方便
-
记一次专场面试经历 at September 06, 2021
offer 合适就离开~
-
记一次专场面试经历 at September 05, 2021
深圳二线厂
-
测试做算法题的意义是什么 at September 03, 2021
学习算法可以锻炼几种能力:
- 对常用的数据结构更了解,知道他们应用的场景,可以更有底气跟开发 battle
- 要考虑非常全面的边界值情况,这点对于设计测试用例来说帮助很大
- 养成写单元测试的习惯
-
Boomer 实战压测 mqtt,2w 并发轻松实现 at September 02, 2021
tps 的时间统计,在代码中有体现,是单个请求维度的。
locust 没有 tps 的概念,是 rps。
另外本次压测最关注的点是消息是否有丢失,和最大并发量。至于响应时间,并不是最重要的。 -
相对可以长期使用的阻止 ios 自动升级方法 at August 31, 2021
每天都有这个弹窗,我明明已经取消了自动更新。
-
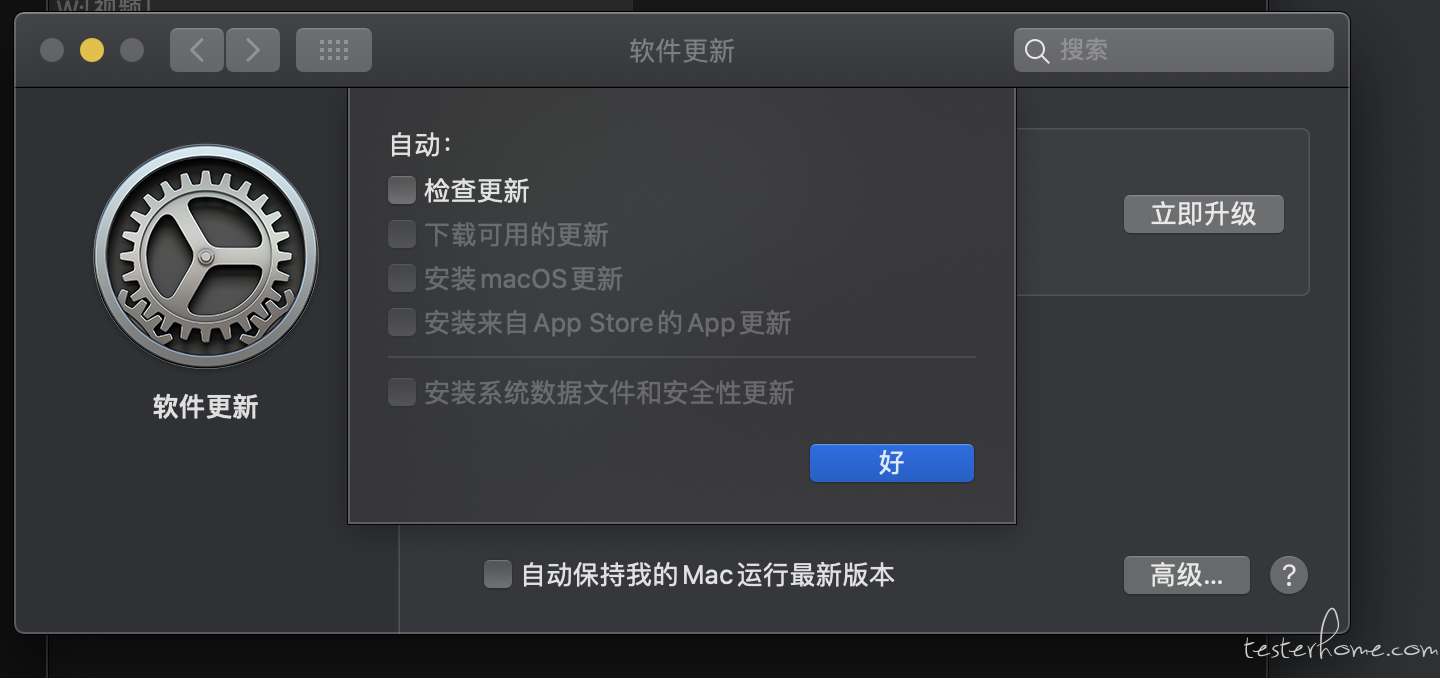
相对可以长期使用的阻止 ios 自动升级方法 at August 26, 2021
有 Mac 阻止升级提示吗?
现在是 10.15.7,不想升级 bigsur,但又天天提醒,挺烦的。 -
【腾讯急招:高级测试专家/工程师,base 深圳/北京/广州/成都】 at August 16, 2021
-
测试平台打通 YAPI 和 Swagger,定时同步接口信息 at August 11, 2021
不支持。
但我想,YAPI 的用例集已经一个成熟的用例,它应该学会自动跑过来才行。 -
大家有什么要吐槽测开或者称赞测开的?欢迎大家来灌水! at August 05, 2021
说说我做的吧
- 目前测试组有二十多个人,日活大概 2/3 的样子。因为有部分是硬件童鞋,用不上,平台主要是 HTTP 接口测试。
- 收益最明显的是那种没有界面,纯接口的项目,有个新项目,近 300 个接口。没用平台之前,每次回归要用 3h 左右,在 postman 一个个发送。用了平台后,回归就 1min,时间大大缩短。
- 其次就是造数据。在大数据实时计算过程中,都是依赖发送 kafka 来生成数据,写 redis 来做基础信息,最后断言就靠消费 kafka 和读 redis。通过测试平台配合数据工厂(提供各种 http 造数接口),可以非常方便的完成这些工作。重点是界面化,比脚本的可读性高很多。并且测试和开发都能用,一个人写完,其他人就能直接使用。不像脚本那样,测试童鞋写好了,开发童鞋想借用一下,结果发现并没有 python 环境,运行不了。
- 打通 YAPI,快速编写接口自动化。因为所有请求相关的参数都已经自动生成,包括登录。支持一个用例在多环境运行,且无需要做任何用例改动,通过切换配置实现。
- 打通 Gitlab-CI,构建就自动跑用例,且支持不同环境对应不同任务。
- 历史数据持久化,可以统计出各种各样维度的数据,这对于写 PPT 很有帮助,嘻嘻
-
接口测试如何实现重复执行还能保持结果一致 at August 01, 2021
自动化产生的数据是要清理,但立刻清理的做法我认为不妥。定期清理可能会更好。
-
接口测试如何实现重复执行还能保持结果一致 at July 30, 2021
新数据我觉得不算偏门,我们也是这么做。
teardown 删除我觉得并不是很好,不利于排查问题。 -
测试开发进阶:一文教你从 0 到 1 搞懂大数据测试! at July 12, 2021
好东西,还差一个 Flink
-
postman 介绍 at July 03, 2021
可以讲一下 postman 的 mock
-
坎坷的 2020 年 at June 22, 2021
懂大数据常用的组件 hbase hive kafka es redis 这些就差不多啦,再高级的就是理解 Flink Spark 这些程序原理,遇到问题能够看代码定位,再再高级可能就是对 Flink 算子进行分析,提出优化建议等等
-
坎坷的 2020 年 at June 21, 2021
大数据可以分为两种,实时计算和离线计算,你用到这两个组件是大数据很常用的。
具体算不算,我也不知道怎么定义比较好。 -
学习下 MQ at June 17, 2021
不一致性真的是生产者生产了消息,但是由于一些原因,比如说网络波动,导致消费者消费不到吗,也就说消息丢失了?
如果是这样的话,拿 kafka 举例,生产者发送消息到 Brooker,可以设置等待所有副本都全部确认了,才认为是消息发送成功。这样就算是 master 挂掉,有副本的保障,也不会出现丢失消息。最后消费者也就能正常的消费到消息。 -
Seldom 2.0 - 让接口自动化测试更简单 at June 16, 2021
前置和后置有例子吗~~
-
邀请码功能全面开放! at June 10, 2021
我几乎天天都有登录耶,还不够活跃呀
-
邀请码功能全面开放! at June 10, 2021
怎么样才能成为高级会员

-
一个 yaml 中用例中读取其他用例依赖实现方法的问题 at June 08, 2021
可以参考 httprunner 的实现
先遍历所有的 step,把变量和函数全部提取出来,去 build_in 里面匹配,
然后运行的时候,再维护一个 run_time_varable_function 的映射 -
[精彩盘点] 2020 年度精华帖 TesterHome 社区 —— 前 5 名将获得 MTSC2021 上海站门票一张! at June 02, 2021
大佬辛苦了!