-
UiAutomator2 原理介绍 + 源码走读 at June 13, 2024
这么优秀都被广进了, 哪家公司这么不长眼啊
-
大家好,希望各位前辈给予新人一些职业发展的建议 at May 29, 2024
飞哥真的优秀,每次想离职的时候,看了你的文章就发现自己还差的远
-
大家买的房子跌了多少了 at May 24, 2024
5 年亏了 130
-
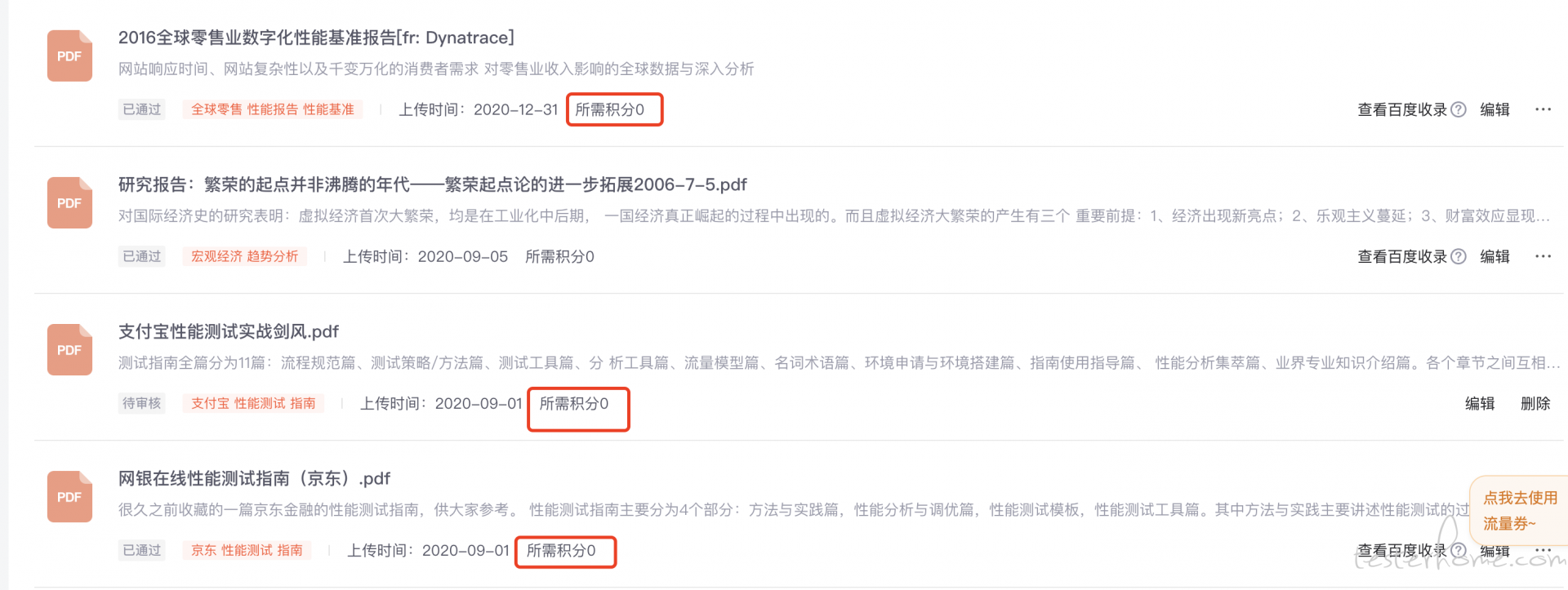
服务端性能测试 - 入门指南 (慎入: 6000 字长文) at March 05, 2024
已设置为免费了
-
Frequency Reduces Difficulty at March 04, 2024
好文
-
服务端性能测试 - 入门指南 (慎入: 6000 字长文) at February 29, 2024
看压测机的 CPU 和内存,没有瓶颈即可。
压测的目标场景不同,对资源消耗不一样的
-
我的 2023 年终总结 -- 一个小小工程师的 15 年 at January 07, 2024
祝福飞哥
-
面临一个转岗产品的机会,有些迷茫,想请教各位经历过转岗的前辈的意见 at December 21, 2023
建议转,测试的职业天花板较低,如果想有好的职业发展,早晚都需要转。
从 0 到 1 负责一个产品及团队管理,是非常难得的好机会。
-
大佬能指点一下方向吗 at November 17, 2023
建议转开发吧,咬咬牙学习一年,转开发
-
1024,你们公司有啥节目? at October 24, 2023
发了点小礼物

-
给自己的书打个广告 -- 云原生测试实战 at August 28, 2023
👍,必须买一本学习
-
服务端性能测试 - 入门指南 (慎入: 6000 字长文) at August 04, 2023
如你引用的文章内容,主要原因为单核 CPU 同一时间其实只能执行一个任务(秒级并发其实就是因为 CPU 速度快,1 秒内通过任务切换,造成了秒级的并发现象)
-
服务端性能测试 - 入门指南 (慎入: 6000 字长文) at July 12, 2023
定时任务归根到底,还是对任务的瞬时压力。
所以就按照常规的性能测试方式,模拟瞬时高并发压力即可。
-
有点感慨 -- 强者越强,弱者越弱 at June 21, 2023
进来大厂后,发现单纯的技术人,竞争力其实非常强。
团队一堆高 P,确实只有 1、2 个人能解决最难的问题,从 0 到 1 开发一整套跨 3 层网络的代理服务及架构,这就是竞争力。
而且年薪远不止百万。
同样的,做到这个程度的技术人,除了技术的硬实力,沟通、协调、项目管理、目标管理能力都很强,对自己的执行力也非常强,并不是单纯的技术
-
Rust、Go 和 Swift 在性能和并发性方面有何差异? at May 08, 2023
建议尽量加入自己的多一些理解,避免直接复制粘贴
-
服务端性能测试 - 入门指南 (慎入: 6000 字长文) at April 20, 2023
1、请求头在测试计划和线程中的区别
可以观察下 真实请求的请求头信息有无区别、响应时间有无变化2、增加线程到 300,500 吞吐量还是在 300 多,不是应该会慢慢降低么
看一下响应时间有无变化3、请在压测时,观察压测机的资源是否有瓶颈
-
你们周围环境里的年龄大点的测试多吗? at April 17, 2023
我 33 了😭
-
年后开工已经一个多星期了,说说你们现在的状态,还有现在行业的现状 at February 06, 2023
向飞哥学习,紧紧跟随飞哥的步伐,也开始计划学习英语,向外企进发
-
风雨中前行的 2022 at January 28, 2023
哇,向你学习,争取润出去
-
虽迟但到,我的 2022 年终总结 at January 28, 2023
楼主优秀
-
花菜の 2022 年终总结 at January 04, 2023
恭喜恭喜,新婚快乐
-
2022 年终总结 at December 23, 2022
😂,鹅友好,大佬就不互道了,快成梗了
-
2022 年终总结 at December 22, 2022
我勒个去,暴露年龄了
-
2022 年终总结 at December 21, 2022
那个转经筒,13 年的时候转过
-
谈一谈今年的 TesterHome at November 29, 2022
卷的不行了,睡觉时间都不多了