组了个队想用 AI 搭建一个 AI 知识库问答系统,通过上传工单,资料的方式让 AI 直接给答案,有什么好的推荐吗?目前了解了 Ollama,Chatchat,AnythingLLM,vLLM(这几个应该是开源的,我们可能只需要接口,页面自己开发,这些开源平台可能接口不全或者不支持),飞致云的 MaxKB,字节的 coze 这些倒是很好,就是社区版 api 有次数限制,看了下图实现原理,通过自己用 MML 搭建不现实,只能用现成的了,各位大佬有什么好的推荐吗?
方案不是问题,难得是数据。
大部分公司做的都是用开源模型,写写 if sels ,微调下参数,配一配意图,丰富一下知识库,调整一下话术,
然后一天到晚鞭策测试让他们想话术,维护意图。最后公司宣传说我们有 AI,只有他们知道,你想要机器人回你什么,我帮你配一个
做业务敏感私密的 RAG,没有足够的 GPU 跑一个参数量足够大的本地私有模型,效果可能是差上加差
不懂 AI,但是通过使用 gpt 能有些感受,首先你训练数据咋来? 还有生成的准确率怎么纠正,这两个已经可以花去大量人力物力了吧,得有 gpt 这种名气才能引来大量的使用者
目前已经都有现成的方案了, 你去百川也好, 百度的 appbuilder 也好, 阿里的千问也好, 都有大模型 + 知识库构建的能力了。 你需要做的就是整理好专业的文档上传到他们的知识库里,然后付费使用就行了,这玩意也不贵。 为啥要自己撸一套。 你要知道这东西它不是攒 3,5 个人就能搞定的。
主要想解决的问题是帮助技术支持处理工单,客户用我们的产品会有很多问题就会提 jira 工单给技术支持,技术支持处理不了就流转到测试和开发这里,我们发现很多简单问题,重复问题,相似问题技术支持也来找测试和开发,所以想把 jira 里面的历史问题导出来喂给知识库,通过问答的交互方式,给出推荐方案,所以数据是有的。
老兄说的是,我们也考虑需要本地部署,得考虑数据安全,开源的知识库平台大多都支持 Llama 3.1,只需要 4C8G 就能跑起来。
现在都有成熟的商业化的知识库问答平台了,你可以试试 coze,只需要上传 excel,PDF 这些,ai 就可以根据你上传的文件,回答你的问题了,不需要训练。
是的,自己做肯定不现实,现在就在找现成的知识库平台,再用提供的 api 二次开发一下更贴近业务,现在遇到的问题就是开源的有没有好用的,还在找,商业化的平台,我看了直接在页面上传文件就行,还可以嵌入到任何 web 页面,api 提供的也很全,二开也很友好,唯一缺点就是收费,就得好好对比一下。
主要困难点还是在洗数据上面,主要是他多,每个都需要人工过,答复的答案也需要人工一点点矫正,真的是多一点人工多一点 AI,想看有没有大佬能答复
FastGPT。RAG 方案其实对数据质量、数据处理和 embedding 模型挺有要求的。。。
你描述的是经典的 RAG 应用场景,有很多开源的方案,比如 RAGflow,自己裸写成本也不高,比如快速用 langchain 实现一个 demo(虽然 langchain 有些过度封装,灵活性差)。需要的资源一是大模型 API、一是向量数据库,可以去百度云、阿里云看看价格。RAG 要做一个 60 分的产品很容易,要做到 80 分以上还挺难的,涉及到你现有数据的规整,也涉及到很多技术细节(比如 chunk 分隔、rerank 等等)。
1、先让公司基于羊驼 3 模型,训练一下,变成自己的 api
https://github.com/ymcui/Chinese-LLaMA-Alpaca-3/wiki/text-generation-webui_zh
2、剩下的不就是架构师该做的事情么。。。
那方案到处都有,随便搞搞,然后推理 1 块 a10 足够了。数据的话,就看你训练的 pair 对是不是足够了。另外 rag 本身的测试,你得看看。你底模用什么?qianwen72b?
如果要验证的话,还得找个更强大的模型去测试。
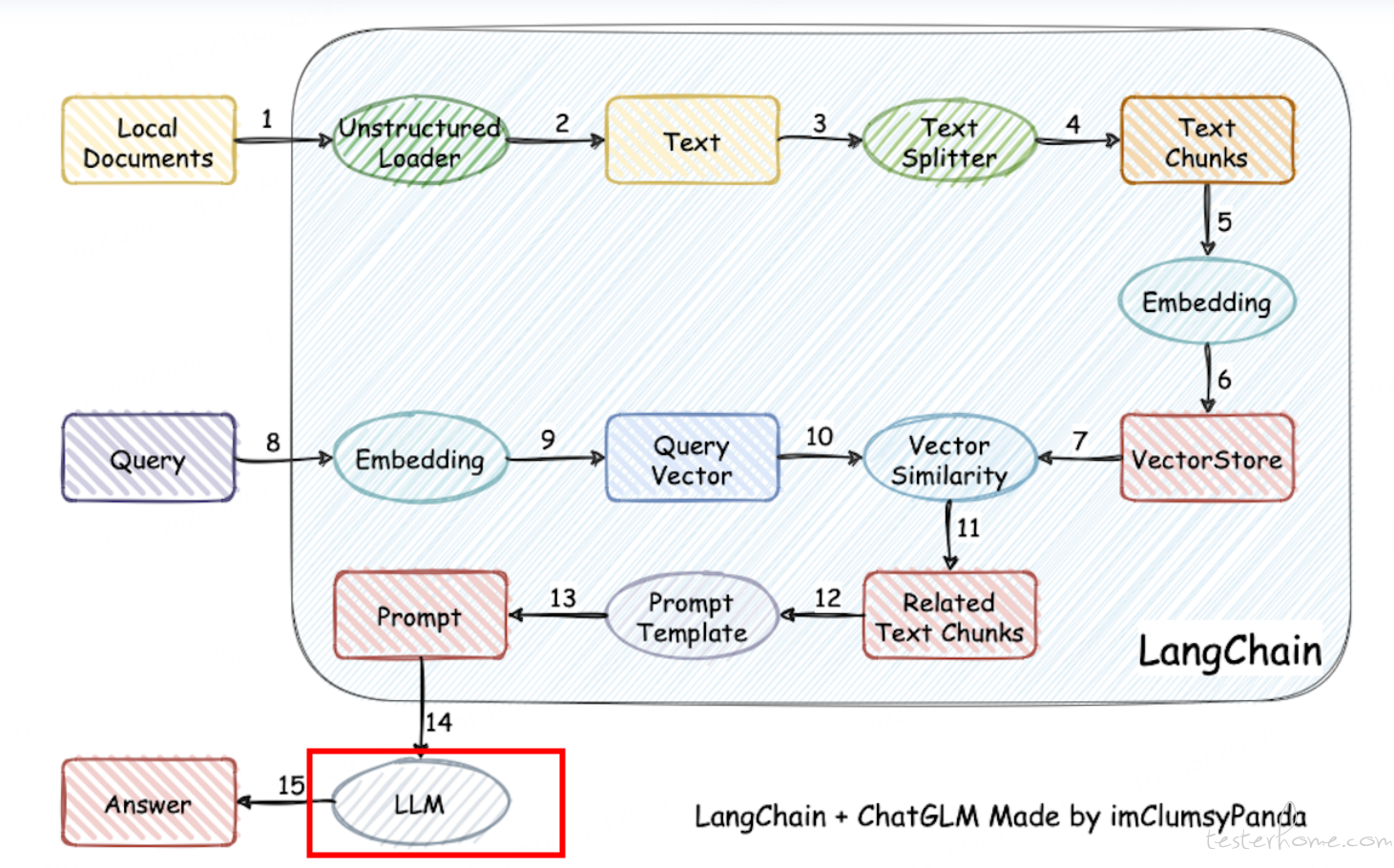
虽然现在也有 RAG+ 微调的研究,但楼主这种 RAG 的场景,是不用再训练模型本身的,无论是用 chatgpt、文心一言之类的开放的 openapi,还是自己私有化部署开源的 chatglm 之类,都不用重新训练模型。楼主要做的,就是把数据规整好,存到向量数据库,真正用的时候,就是先把 query 做向量检索出 top n 的信息,然后用大模型提炼总结一下。 网上直接上传文档就能使用的那些,不过是把规整数据&存入向量数据库&对 query 进行 embedding 和向量检索这些事都做了,也就是楼主图中的 1-11 这些步骤,全部自己搞的话,就是需要把这些步骤自己实现一下。
rag flow 这些挺好的呀,改动一下调大语言模型的部分,其他无脑用就行了。文档解析,如果 ragflow 不是很好,可以用 omniparser,串个 api,分分钟就搞好了。对了,大语言模型的部分,建议国内就使用 deepseek2,感觉质量非常不错。我们的内部问答已经切换到 deepseek2;
不要尝试微调开源模型,这个对于数据质量要求非常高,都已经用 rag 了,还可以看看现在微软开源的 graphrag,这个和上面的思路已经不一样了,是用知识图谱的方式结构化存储数据;