服务端性能测试系列下一篇:工具篇 (Jmeter),从性能测试常用功能角度,熟悉 Jemter。
从 14 年 11 月到 18 年 6 月,一直专注于服务端性能测试,发现有些同学经常对一些基础概念和指标有异议,故写本文,希望对大家认识性能测试有一定帮助。也欢迎大家多多指正。
因性能测试知识跟自己的从业经历强相关,但性能知识范围甚广,不同的业务、不同的技术架构,我们的关注点和指标要求可能会区别较大,欢迎大家指正文中不足或错误之处,并附上相关资料链接,方便大家传阅。
全文包括:
1、前言
随着 5G 时代的到来,以及万物互联时代的到来,云应用和云服务会越来越多,数据量会指数级增长。尤其是 2020 年全球疫情的时代意义,会导致各行各业开始上云。从而会催生出极具个性化的各类产品的诞生。
所有行业的生态会像鲸落效应一样,围绕若干个巨无霸公司衍生出满足人们各种需求的中小型产品。大部分产品的形态可能会变成重服务端、轻客户端。
所以,服务端性能测试的需求也有可能会出现井喷式增长。但是服务端性能测试需求对于中小型公司,尤其是大部分不关注用户体验的公司来说,性能测试需求特点是周期短、时间紧。
因此,对于大部分测试从业人员来说,了解并掌握常见的性能测试知识是必不可少的,虽然不会经常用到。
2、什么是性能
不同角色关注的性能是不一样的,性能测试这项系统工程,需要各角色在其关注的纬度提供信息或帮助。
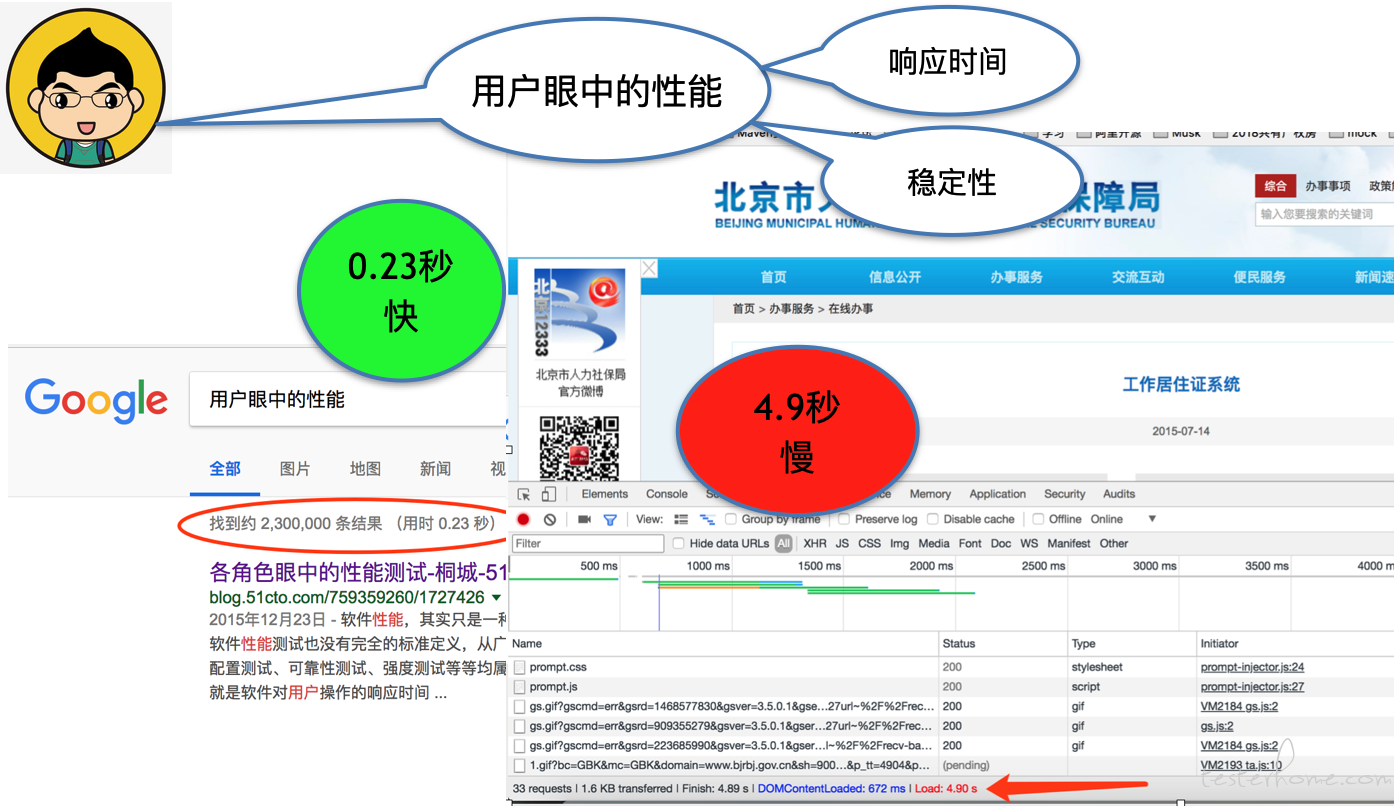
用户眼中的性能
性能对于用户来说,就是操作的响应速度、产品的崩溃是否影响自己的生活。比如滴滴之前在情人节当天打车服务的性能事故。
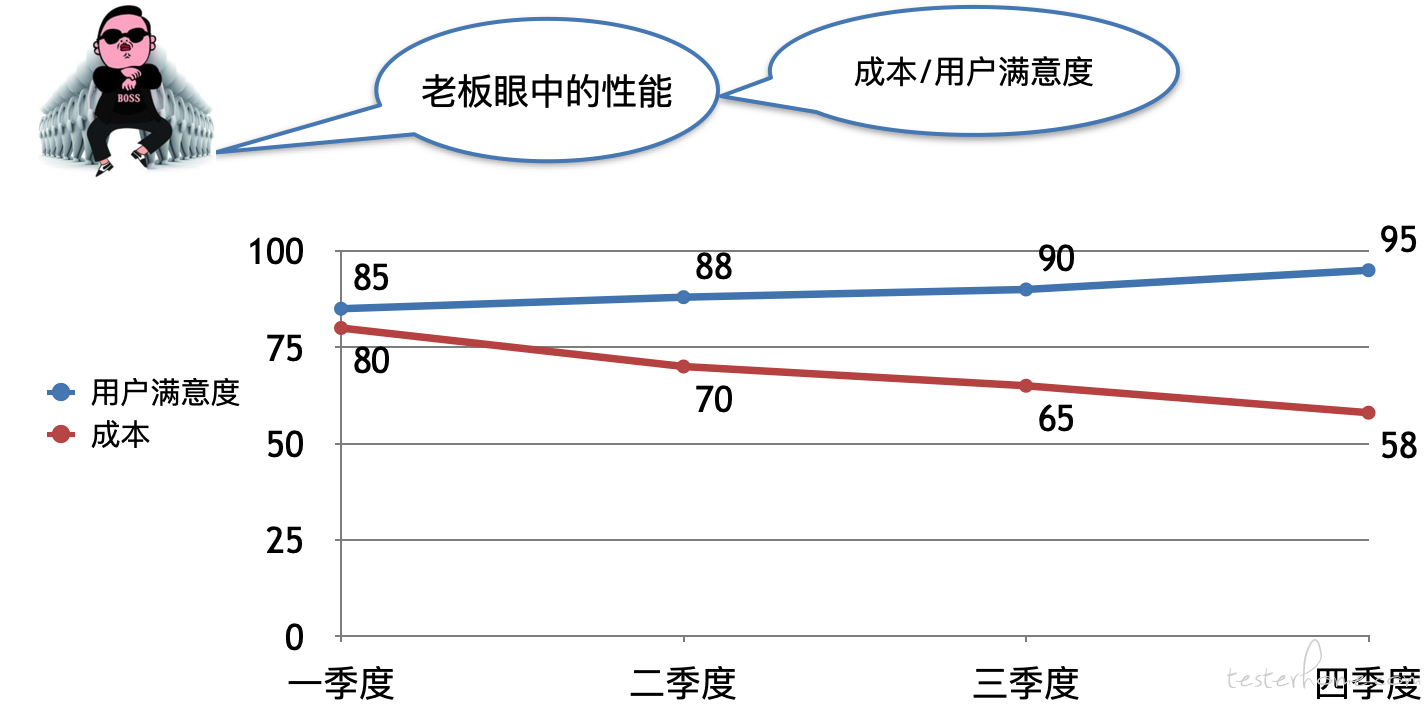
老板眼中的性能
老板主要关心产品的收入、成本(用了多少钱服务了多少用户)、用户满意度(用户对产品是否满意)。
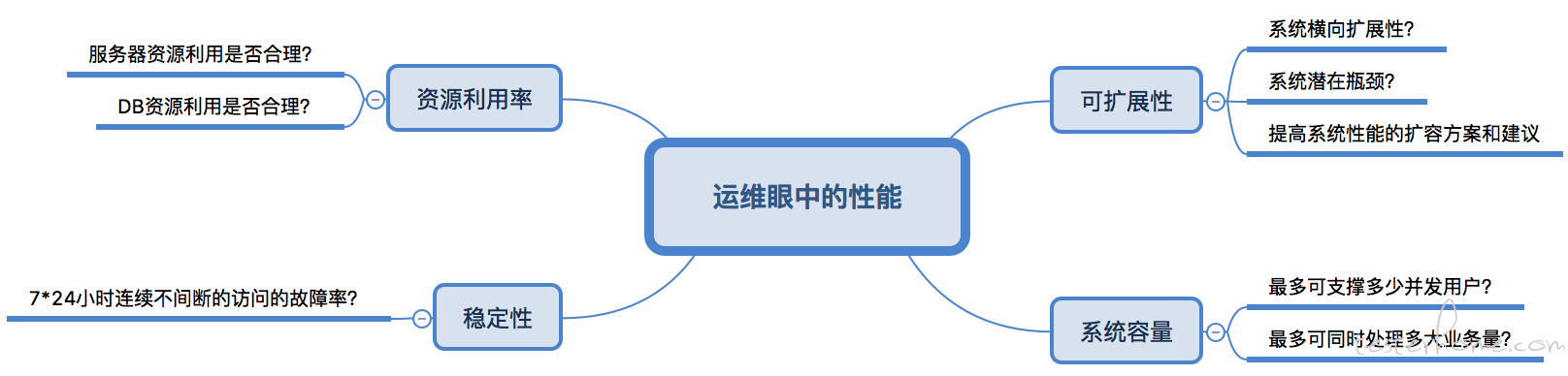
运维眼中的性能
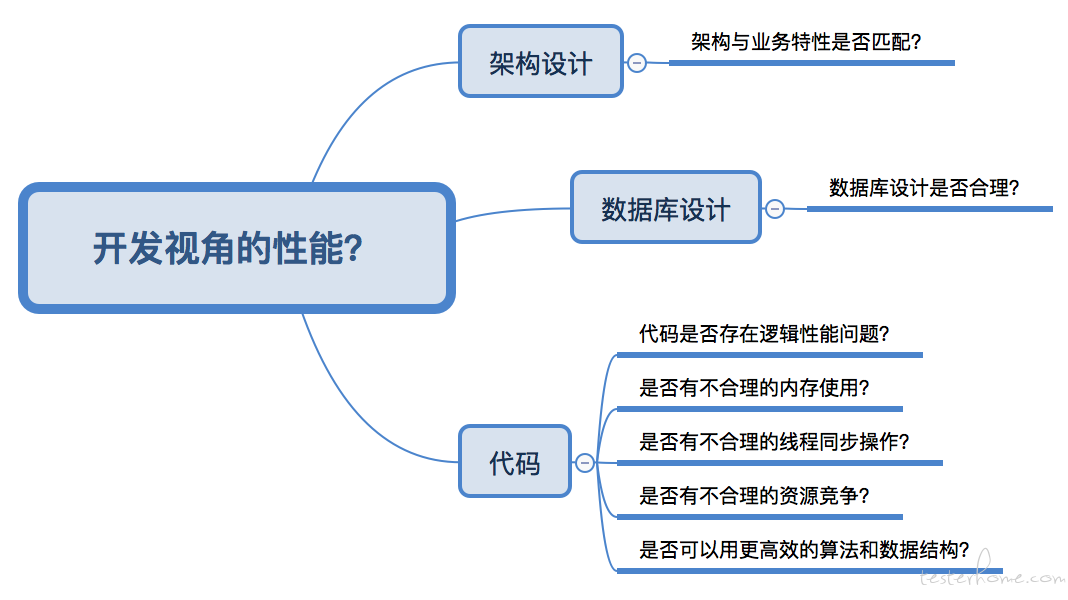
开发眼中的性能
测试眼中的性能
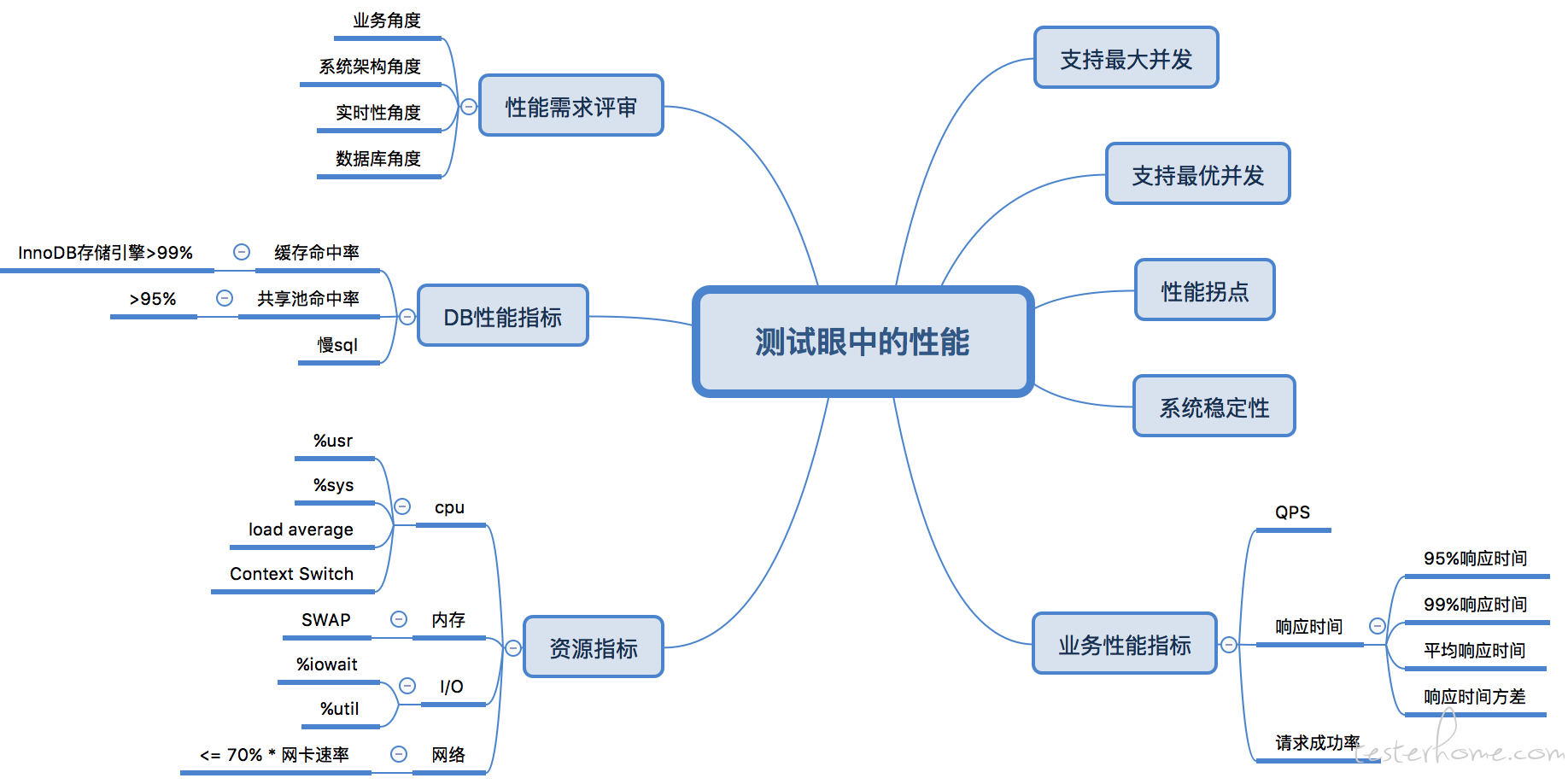
3、性能的影响
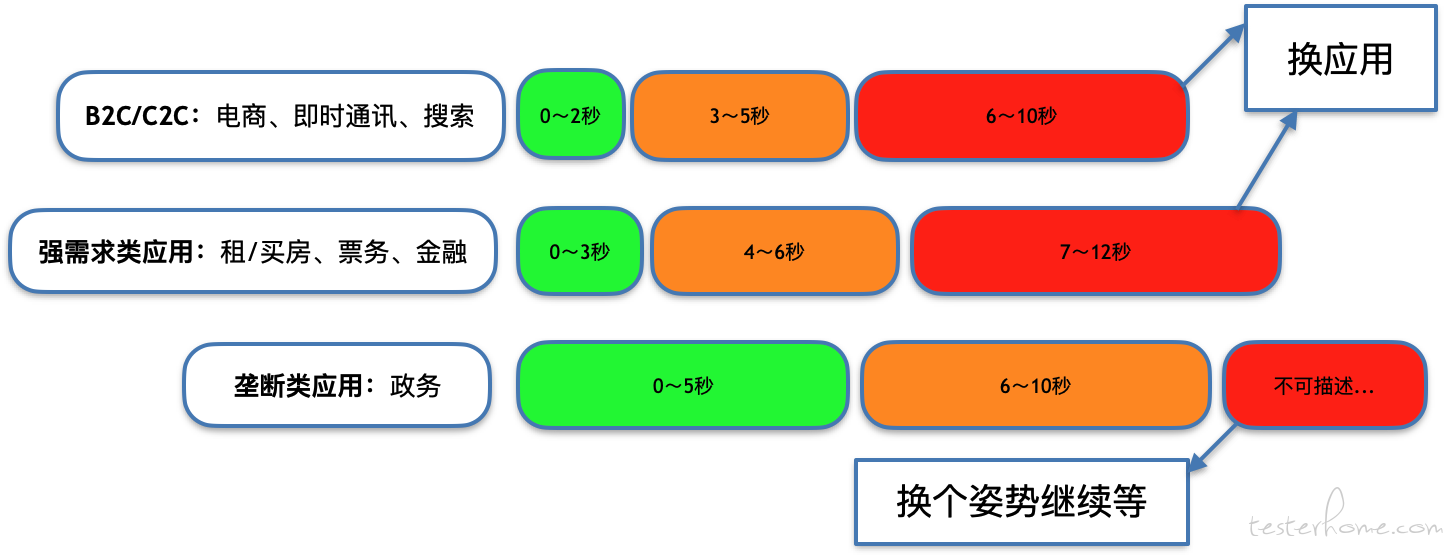
3.1 性能对用户的影响
对于大部分商业公司的 ToC 产品,性能关乎产品命运和增长。如下图所示,虽然现在阿里京东垄断不太容易更换应用,但是遇到性能很差的时候,心里还是忍不住问候几句。
3.2 性能对收入的影响
大家都知道性能对产品收入有非常大的影响,但是很少公司有全面的运营分析来证明这件事。
以下是《2016 全球零售业数字化性能基准报告》中关于性能对收入影响的数据。
从图中可以看到,响应时间对转化率的影响非常大,比如沃尔玛够硬核了吧,沃尔玛的响应时间降低 0.1 秒,收入即可增加 1%,是非常大的收入提升。

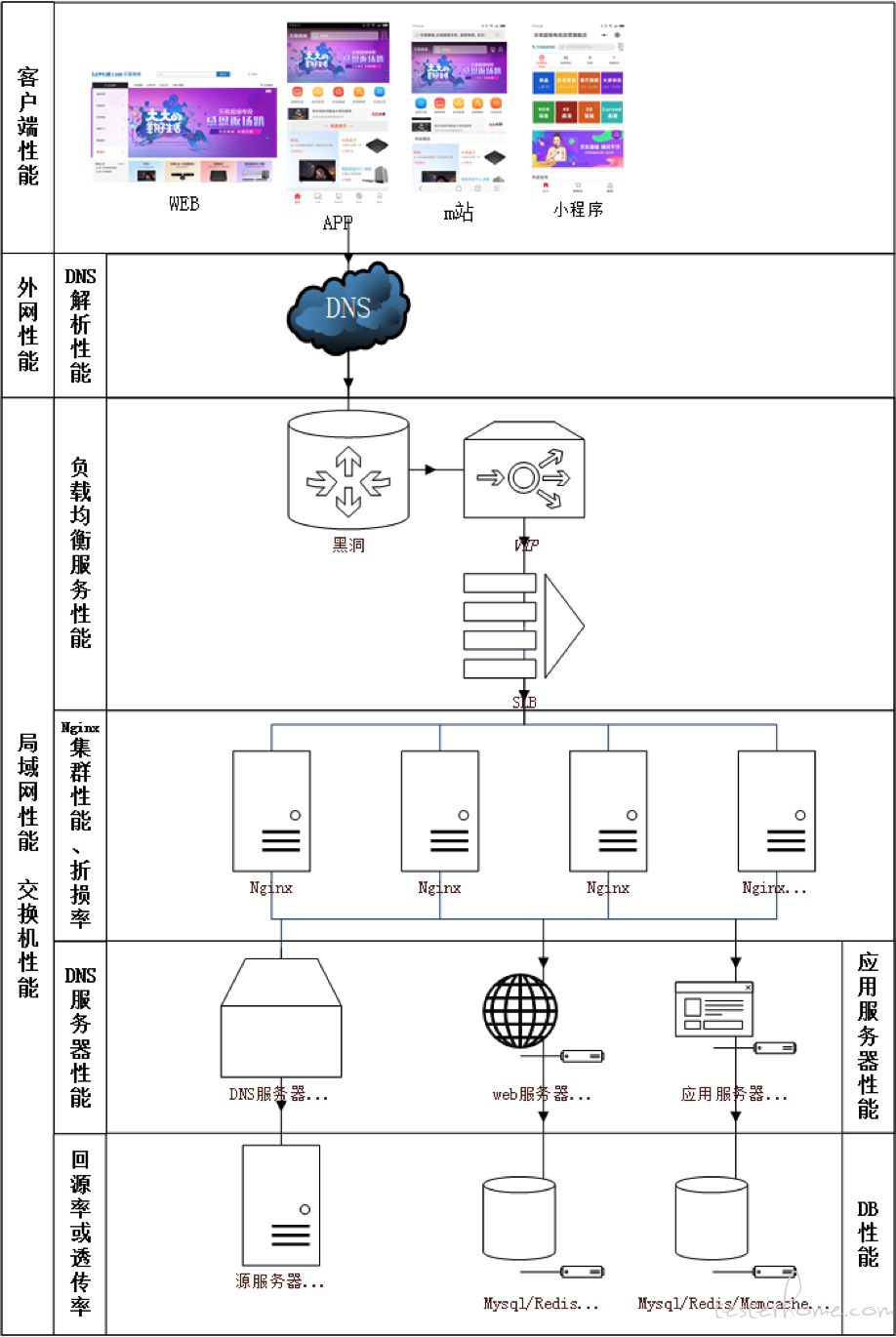
4、性能的组成
以中小型电商网站为例,如下图所示,性能基本组成:
- 客户端 (Web、移动端、小程序) 性能
- DNS 性能
- 负载均衡服务性能
- Nginx 集群性能、折损率
- CDN 缓存性能(回源率、穿透率)
- 应用服务器性能
- DB 性能(Mysql/Redis/Memcache)
由此可见,中大型项目的性能测试,从来都是一项系统工程,需要非常多人跨部门合作,且持续时间长,耗费资源大。
5、性能测试基础知识和注意事项
熟悉性能测试之前,首先了解性能测试的目标是什么。带着目标去思考会更有利于理解下面的内容。
5.1 性能测试目的
性能测试的最终目的是为了最大限度的满足用户的需求,通常要达成以下目标:
(1)性能评估:测试中评估系统的 QPS、响应时间、成功率等;
(2)寻找系统瓶颈,进行系统调优;
(3)检测软件中的问题;
(4)验证稳定性和可靠性;
5.2 性能应该关注的指标
一般来说,性能测试要统一考虑这么几个因素:Thoughput 吞吐量,Latency 响应时间,资源利用(CPU/MEM/IO/Bandwidth…),成功率,系统稳定性。
(1)响应时间:你得定义一个系统的响应时间 latency,建议是 TP95 或以上。响应时间具体要求多少,一般读不超过 200ms,写不超过 500ms。要是实在不知道,对标同行业竞品。
(2)最高吞吐量:TPS(每秒事务请求数)或 QPS(每秒请求量),在目标响应时间要求下,系统可支撑的最高吞吐量。
(3)成功率:在关注 QPS 和响应时间的同时,还要关注成功率。如果 QPS 和响应时间都满足性能要求时,请求成功率只有 50%,用户也是不会接受的。
(4)性能拐点:一般服务都有性能临界点。当超过临界点时,吞吐量非线性下降,响应时间指数级增加,成功率降低。
找到出现性能拐点的主要原因:
基于性能拐点主要原因设置高危性能报警线。此为高风险注意事项,因为一旦达到性能拐点,有可能会出现雪崩现象,造成极其严重的事故。
观察超过性能拐点后,系统是否会出现假死、崩溃等高风险事件。
(5)系统稳定性:保持最高吞吐量(目标响应时间下的最高吞吐量),持续运行 7*24 小时。然后收集 CPU,内存,硬盘/网络 IO,等指标,查看系统是否稳定,比如,CPU 是平稳的,内存使用也是平稳的。那么,这个值就是系统的性能。
(6)极限吞吐量:阶梯式增加并发压力,找到系统的极限值。比如:在成功率 100% 的情况下(不考虑响应时间的长短),系统能坚持 10 分钟的吞吐量。
(7)系统健壮性:做 Burst Test。用第二步得到的吞吐量执行 5 分钟,然后在第四步得到的极限值执行 1 分钟,再回到第二步的吞吐量执行 5 钟,再到第四步的权限值执行 1 分钟,如此往复个一段时间,比如 2 天。收集系统数据:CPU、内存、硬盘/网络 IO 等,观察他们的曲线,以及相应的响应时间,确保系统是稳定的。
(8)低吞吐量和网络小包的测试:有时候,在低吞吐量的时候,可能会导致 latency 上升,比如 TCP_NODELAY 的参数没有开启会导致 latency 上升(详见 TCP 的那些事),而网络小包会导致带宽用不满也会导致性能上不去,所以,性能测试还需要根据实际情况有选择的测试一下这两咱场景。
5.3 性能测试类型
首先简单分析性能测试的压力模型。
如下图所示,随着单位时间压力的不断增长,被测系统和服务器的压力不断增加,TPS 会因为这些因素而发生变化,而且通常符合一下规律。
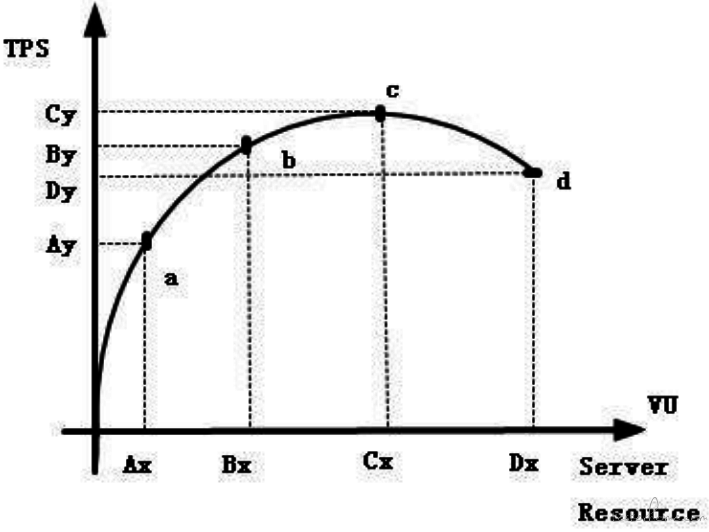
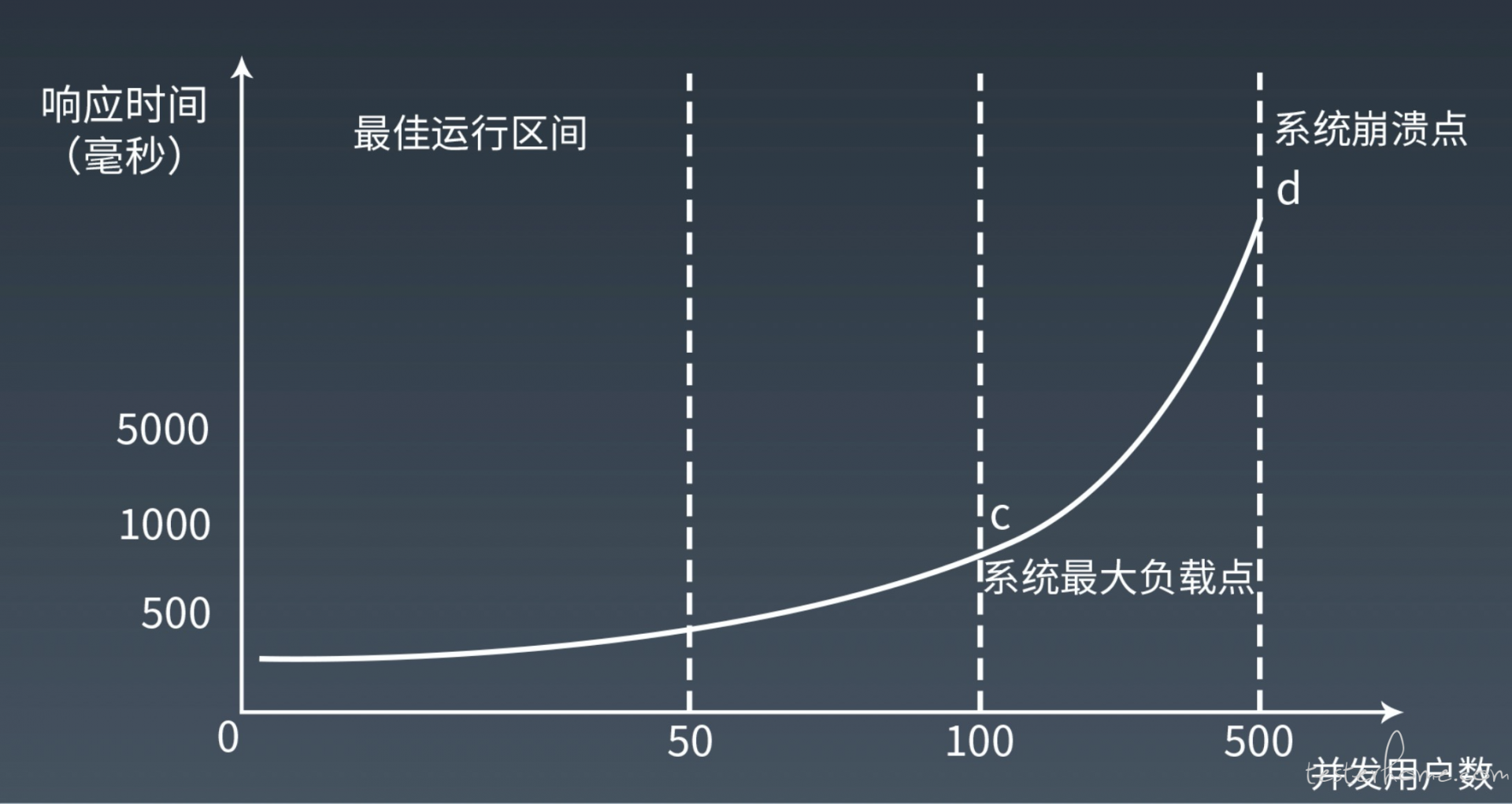
为得到性能关注的指标,基本分为以下性能测试类型:
-
性能测试(狭义)
- 说明:性能测试方法是通过模拟生产运行的业务压力量和使用场景组合,测试系统的性能是否满足生产性能要求。通俗地说,这种方法就是要在特定的运行条件下验证系统的能力状态。
- 特点: 1、这种方法的主要目的是验证系统是否有系统宣称具有的能力。 2、这种方法要事先了解被测试系统经典场景,并具有确定的性能目标。 3、这种方法要求在已经确定的环境下运行。 也就是说,这种方法是对系统性能已经有了解的前提,并对需求有明确的目标,并在已经确定的环境下进行的。
-
负载测试 (Load Test)
- 说明:通过在被测系统上不断加压,直到性能指标达到极限(例如 “响应时间”)超过预定指标或都某种资源已经达到饱和状态。
- 特点: 1、这种性能测试方法的主要目的是找到系统处理能力的极限。 2、这种性能测试方法需要在给定的测试环境下进行,通常也需要考虑被测试系统的业务压力量和典型场景、使得测试结果具有业务上的意义。 3、这种性能测试方法一般用来了解系统的性能容量,或是配合性能调优来使用。 也就是说,这种方法是对一个系统持续不段的加压,看你在什么时候已经超出 “我的要求” 或系统崩溃。
-
压力测试(强度测试)(Stress Test)
- 说明:压力测试方法测试系统在一定饱和状态下,例如 cpu、内存在饱和使用情况下,系统能够处理的会话能力,以及系统是否会出现错误
- 特点: 1、这种性能测试方法的主要目的是检查系统处于压力性能下时应用的表现。 2、这种性能测试一般通过模拟负载等方法,使得系统的资源使用达到较高的水平。 3、这种性能测试方法一般用于测试系统的稳定性。 也就是说,这种测试是让系统处在很大强度的压力之下,看系统是否稳定,哪里会出问题。
-
并发测试(Concurrency Testing)
- 说明:并发测试方法通过模拟用户并发访问,测试多用户并发访问同一个应用、同一个模块或者数据记录时是否存在死锁或其者他性能问题。
- 特点: 1、这种性能测试方法的主要目的是发现系统中可能隐藏的并发访问时的问题。 2、这种性能测试方法主要关注系统可能存在的并发问题,例如系统中的内存泄漏、线程锁和资源争用方面的问题。 3、这种性能测试方法可以在开发的各个阶段使用需要相关的测试工具的配合和支持。 也就是说,这种测试关注点是多个用户同时(并发)对一个模块或操作进行加压。
-
配置测试(Configuration Testing)
- 说明:配置测试方法通过对被测系统的软\硬件环境的调整,了解各种不同对系统的性能影响的程度,从而找到系统各项资源的最优分配原则。
- 特点: 1、这种性能测试方法的主要目的是了解各种不同因素对系统性能影响的程度,从而判断出最值得进行的调优操作。 2、这种性能测试方法一般在对系统性能状况有初步了解后进行。 3、这种性能测试方法一般用于性能调优和规划能力。 也就是说,这种测试关注点是 “微调”,通过对软硬件的不段调整,找出这他们的最佳状态,使系统达到一个最强的状态。
-
可靠性测试
- 说明:通过给系统加载一定业务压力(例如资源在 70%-90% 的使用率),使系统运行一段时间,以此检测系统是否稳定运行。
- 特点: 1、这种性能测试方法的主要目的是验证是否支持长期稳定的运行。 2、这种性能测试方法需要在压力下持续一段时间的运行。(2~3 天)3、测试过程中需要关注系统的运行状况。 如果测试过程中发现,随着时间的推移,响应时间有明显的变化,或是系统资源使用率有明显波动,都可能是系统不稳定的征兆。 也就是说,这种测试的关注点是 “稳定”,不需要给系统太大的压力,只要系统能够长期处于一个稳定的状态。
-
失效恢复测试
- 说明:如果系统局部发生故障,用户是否能够继续使用系统,以及如果这种情况发生,用户将受到多大程度的影响。
- 特点: 1.这种性能测试方法的主要目的是验证在局部故障情况下,系统能否继续使用。 2.这种性能测试方法还需要指出,当问题发生时,“能支持多少用户访问” 的结论和 “采取何种应急措施” 的方案。 3.一般来说,只有对系统持续运行指标有明确要求的系统才需要进行这种类型的测试。
大数据量测试:针对某些系统存储、传输、统计查询等业务进行大数据量的测试。
注意:在做性能测试时请忘掉分类。例如,运行 8 个小时来测试系统是否可靠,而这个测试极有可能包含了可靠性能测、强度测试、并发测试、负载测试,等等。因此,在实施性能测试时决不能割裂它们的内部联系去进行,而应该基于测试目标,分析它们之间的关系,以一种高效率的方式来设计性能测试。
5.4 性能测试流程
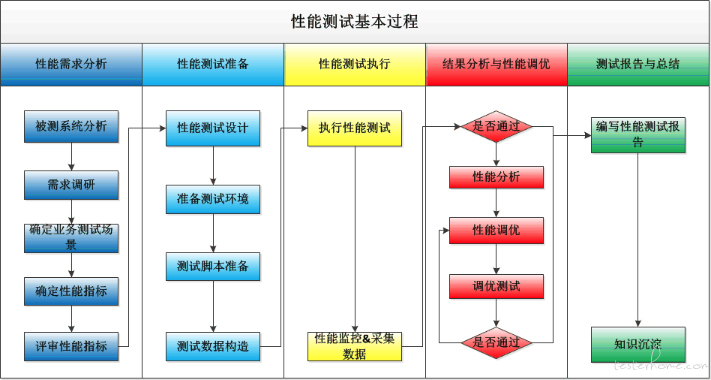
(1)性能需求分析
性能需求分析是整个性能测试工作开展的基础,如果连性能的需求都没弄清楚,后面的性能测试工具以及执行就无从谈起了。
在这一阶段,性能测试人员需要与 PM、DEV 及项目相关的人员进行沟通,同时收集各种项目资料,对系统进行分析,确认测试的目标。并将其转化为可衡量的具体性能指标。
测试需求分析阶段的主要任务是分析被测系统及其性能需求,建立性能测试数据模型,分析性能需求,确定合理性能目标,并进行评审;
(2)性能测试准备
主要包括:设计场景,根据场景编写程序、编写脚本、准备测试环境,构造测试数据,环境预调优等;
设计场景:针对系统的特点设计出合理的测试场景。为了让测试结果更加准确,这里需要很细致的工作。如建立用户模型,只有知道真实的用户是如何对系统产生压力,才可以设计出有代表性的压力测试场景。这就涉及到很多信息,如用户群的分布、各类型用户用到的功能、用户的使用习惯、工作时间段、系统各模块压力分布等等。只有从多方面不断的积累这种数据,才会让压力场景更有意义。最后将设计场景转换成具体的用例。
测试数据:测试数据的设计也是一个重点且容易出问题的地方。生成测试数据量达到未来预期数量只是最基础的一步,更需要考虑的是数据的分布是否合理,需要仔细的确认程序中使用到的各种查询条件,这些重点列的数值要尽可能的模拟真实的数据分布, 否则测试的结果可能是无效的。测试数据最好使用线上脱敏后的数据,尽可能接近真实用户行为。
预调优:指根据系统的特点和团队的经验,提前对系统的各个方面做一些优化调整,避免测试执行过程中的无谓返工。比如一个高并发的系统,10000 人在线,连接池和线程池的配置还用默认的,显然是会测出问题的。
(3)执行性能测试
执行阶段工作主要包含两个方面的内容:一是执行测试用例模型,包括执行脚本和场景;其次测试过程监控,包括测试结果、记录性能指标和性能计数器的值
(4)结果分析与性能调优
发现问题或者性能指标达不到预期,及时的分析定位,处理后重复测试过程。
性能问题通常是相互关联相互影响的,表面上看到的现象很可能不是根本问题,而是另一处出现问题后引起的反应。这就要求监控收集数据时要全面,从多方面多个角度去判断定位。调优的过程其实也是一种平衡的过程,在系统的多个方面达到一个平衡即可。
(5)性能报告与总结
编写性能测试报告,阐明性能测试目标、性能结果、测试环境、数据构造规则、遇到的问题和解决办法等。并对此次性能测试经验进行总结与沉淀。具体性能测试报告的编写可以参考《性能测试报告模板》。
上面所有内容中,如果排除技术上的问题,性能测试中最难做好的,就是用户模型的分析。它直接决定了压力测试场景是否能够有效的模拟真实世界压力,而正是这种对真实压力的模拟,才使性能测试有了更大的意义。可以说,性能测试做到一定程度,差距就体现在了模型建立上。
至于性能问题的分析、定位或者调优,很大程度是一种技术问题,需要多方面的专业知识。数据库、操作系统、网络、开发都是一个合格的性能测试人员需要拥有的技能,只有这样,才能从多角度全方位的去考虑分析问题。
6、性能工具性能对比
基于目前市场上主流的性能工具,进行横向对比测试,以帮助我们在不同的环境灵活选择不同的测试工具。
6.1 性能工具对比结果
测试对象:Nginx index.html(612Byte),CPU:16 核 / 内存:16GB / 磁盘:500GB
压力机:Ubuntu18.04, CPU: 8 核 / 内存:8G / 磁盘: 500GB
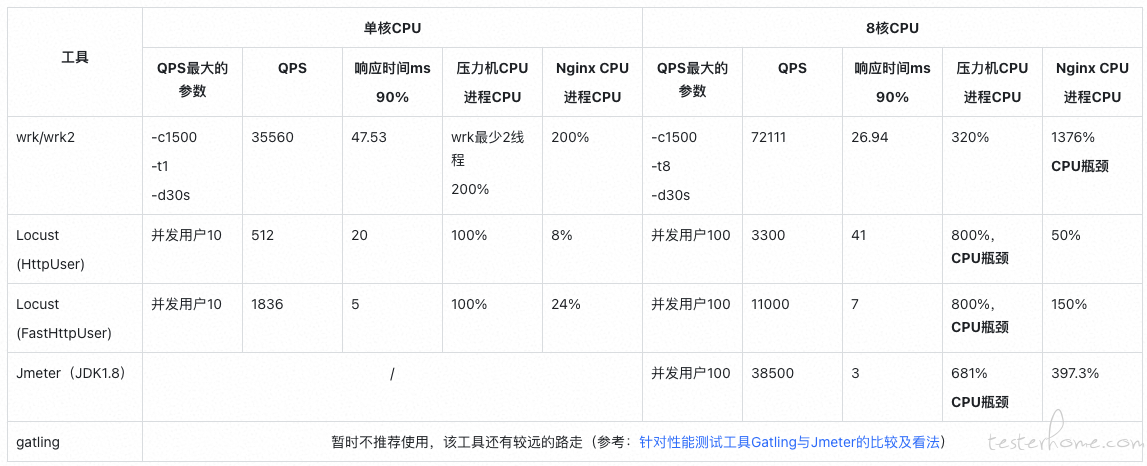
在此只进行了最基础的性能对比测试,仅供基本的工具选择判断。
6.2 性能工具介绍
ngrinder(待补充)
阿里京东也在用,天生为分布式开发的,易用性很好
(1)wrk / wrk2
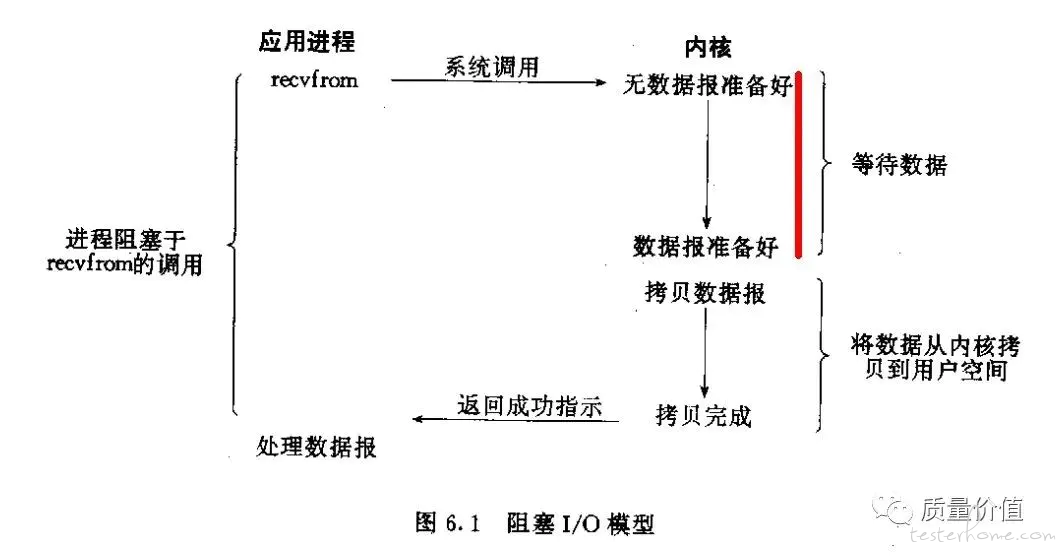
wrk 是一款针对 Http 协议的基准测试工具,它能够在单机多核 CPU 的条件下,使用系统自带的高性能 I/O 机制,如 epoll,kqueue 等,通过多线程和事件模式,对目标机器产生大量的负载。
PS: 其实,wrk 是复用了 redis 的 ae 异步事件驱动框架,准确来说 ae 事件驱动框架并不是 redis 发明的, 它来至于 Tcl 的解释器 jim, 这个小巧高效的框架, 因为被 redis 采用而被大家所熟知。
优势:
轻量级性能测试工具;
安装简单(相对 Apache ab 来说);
学习曲线基本为零,几分钟就能学会咋用了;
基于系统自带的高性能 I/O 机制,如 epoll, kqueue, 利用异步的事件驱动框架,通过很少的线程就可以压出很大的并发量;
劣势:
wrk 目前仅支持单机压测,后续也不太可能支持多机器对目标机压测,因为它本身的定位,并不是用来取代 JMeter, LoadRunner 等专业的测试工具,wrk 提供的功能,对后端开发人员来说,应付日常接口性能验证还是比较友好的。
之前在乐视我们的测试架构师基于 wrk2 主导开发并支持了分布式,开发成本还是略高的。
基础使用:
子命令参数说明:
使用方法: wrk <选项> <被测HTTP服务的URL>
Options:
-c, --connections <N> 跟服务器建立并保持的TCP连接数量
-d, --duration <T> 压测时间
-t, --threads <N> 使用多少个线程进行压测(为了减少现成的上下文切换,官方建议thread数量等同CPU核数)
-s, --script <S> 指定Lua脚本路径
-H, --header <H> 为每一个HTTP请求添加HTTP头
--latency 在压测结束后,打印延迟统计信息
--timeout <T> 超时时间
-v, --version 打印正在使用的wrk的详细版本信息
<N>代表数字参数,支持国际单位 (1k, 1M, 1G)
<T>代表时间参数,支持时间单位 (2s, 2m, 2h)
PS: 关于线程数,并不是设置的越大,压测效果越好,线程设置过大,反而会导致线程切换过于频繁,效果降低,一般来说,推荐设置成压测机器 CPU 核心数的 2 倍到 4 倍就行了。
# 示例
wrk -c400 -t24 -d30s --latency http://10.60.82.91/
报告解析:
Running 30s test @ http://www.baidu.com (压测时间30s)
12 threads and 400 connections (共12个测试线程,400个连接)
(平均值) (标准差) (最大值)(正负一个标准差所占比例)
Thread Stats Avg Stdev Max +/- Stdev
(延迟)
Latency 386.32ms 380.75ms 2.00s 86.66%
(每秒请求数)
Req/Sec 17.06 13.91 252.00 87.89%
Latency Distribution (延迟分布)
50% 218.31ms
75% 520.60ms
90% 955.08ms
99% 1.93s
4922 requests in 30.06s, 73.86MB read (30.06s内处理了4922个请求,耗费流量73.86MB)
Socket errors: connect 0, read 0, write 0, timeout 311 (发生错误数)
Requests/sec: 163.76 (QPS 163.76,即平均每秒处理请求数为163.76)
Transfer/sec: 2.46MB (平均每秒流量2.46MB)
Running 30s test @ http://10.60.82.91/ (压测时间30s)
32 threads and 400 connections (共32个测试线程,400个连接)
(平均值) (标准差) (最大值)(正负一个标准差所占比例)
Thread Stats Avg Stdev Max +/- Stdev
Latency(延迟) 10.31ms 40.13ms 690.32ms 98.33%
Req/Sec(每秒请求数) 2.14k 482.15 6.36k 77.39%
Latency Distribution
50% 5.11ms
75% 7.00ms
90% 9.65ms
99% 212.68ms
(30.10s内处理了2022092个请求,耗费流量1.62GB)
2022092 requests in 30.10s, 1.62GB read
Requests/sec: 67183.02 (QPS 67183.02,即平均每秒处理请求数为67183.02)
Transfer/sec: 55.03MB (平均每秒流量55.03MB)
(2)Jmeter
Jmeter 是 Java 开发的、基于多线程并发模型的压测工具,也是目前最流行的开源压测工具,工作原理类似,如下图:
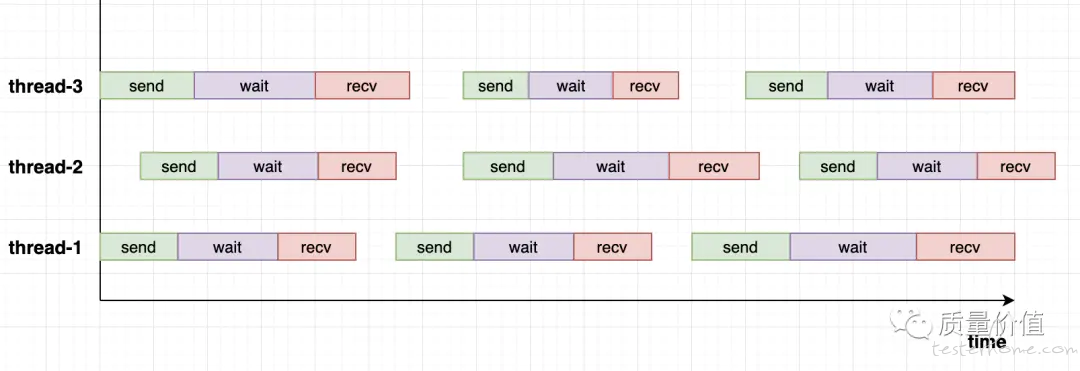
- 其所谓的虚拟用户 (vuser) 就是对应一个线程
- 在单个线程中,每个请求(query)都是同步调用的,下一个请求要等待前一个请求完成才能进行
- 一个请求(query)分成三部分:
- send - 施压端发送开始,直到承压端接收完成
- wait - 承压端接收完成开始,直至业务处理结束
- recv - 承压端返回数据,直至施压端接收完成
- 同一线程中连续的两个请求之间存在等待时间这种概念,即图中的空白处
在多线程并发模型下,是不是可以通过不断增加线程数量生产出更大的压力?
答案是否定的。
事实上一个进程在一个时间点只能执行一个线程,而所谓的并发是指在进程里不断切换线程实现了看上去的多个任务的并发,但是线程上下文切换有很高的成本,过多的线程数反而会造成性能的严重下滑。
从应用角度来看,基于多线程的并发模型,往往需要设置最大并发数参数,而如果压测场景需要不断往上加压,那这类工具其实挺难应付的。
(3)Locust
Locust 是用 Python 开发的分布式压测工具,近年来在国内比较流行。Locust 并不是基于 Python 的多线程,而是 coroutine(协程,gevent 提供),gevent 使用了 libev 或者 libuv 作为 eventloop。
Locust 响应时间失真问题:
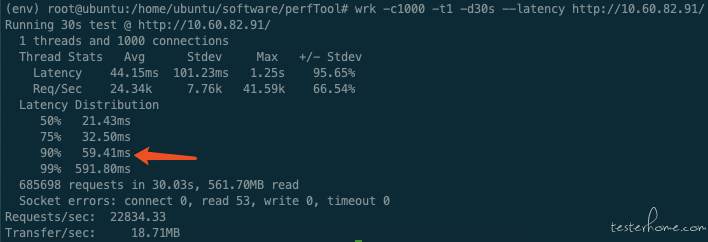
Locust 当压力机 CPU 达到瓶颈后,响应时间会严重失真。
比如当 Locust normal 模式下,8 进程,CPU 瓶颈后,90% 响应时间为 340ms。同时 wrk 获取的响应时间为 59.41ms.

基本使用介绍:
装饰器 task 可以设置压力比例
- HttpUser 示例:
from locust import HttpUser, task
class QuickstartUser(HttpUser):
# task为每个正在运行的用户创建一个greenlet(微线程)
@task(1)
def detail(self):
self.client.get("http://10.60.82.91/")
def on_start(self):
pass
- FastHttpUser 示例
from locust import task
from locust.contrib.fasthttp import FastHttpUser
class QuickstartUser(FastHttpUser):
# task为每个正在运行的用户创建一个greenlet(微线程)
@task(1)
def detail(self):
self.client.get("http://10.60.82.91/")
def on_start(self):
pass
- 启动及分布式
# -c 并发用户数
# -r 每秒启动用户数
# -t 持续运行时间
locust -f load_test.py --host=http://10.60.82.91 --no-web -c 10 -r 10 -t 1m
# 分布式
nohup locust -f locust_files/fast_http_user.py --master &
nohup locust -f locust_files/fast_http_user.py --worker --master-host=10.60.82.90 &
6.3 测试记录
(1)wrk 测试记录
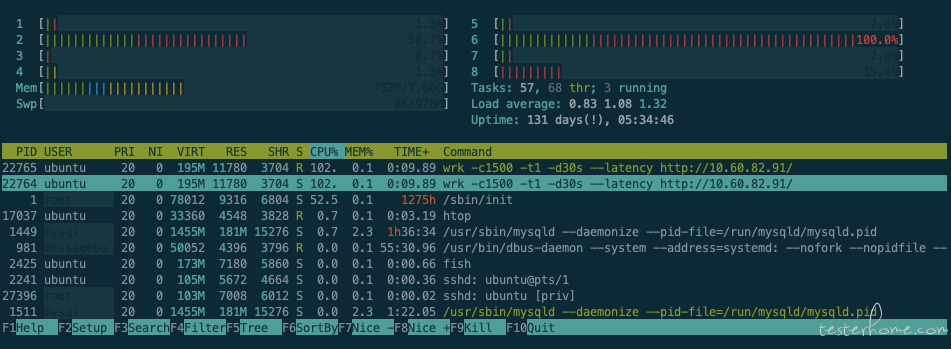
2 线程: -c1000 -t1(因最少 2 线程)QPS: 35560.79
wrk -c1000 -t1 -d30s --latency http://10.60.82.91/
3 线程:( -c1000 -t2 QPS: 66941.77 )
wrk -c1000 -t2 -d30s --latency http://10.60.82.91/
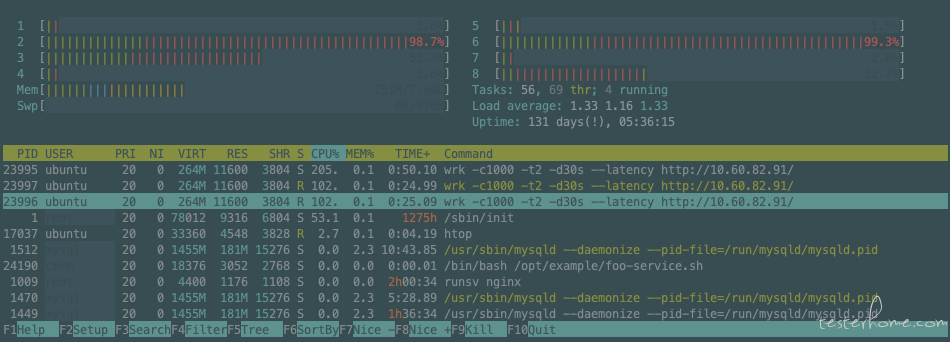
8 线程: ( -c1000 -t8 QPS: 75579.30 )
wrk -c1000 -t8 -d30s --latency http://10.60.82.91/
Nginx: 86% * 16 = 1376% , 达到 CPU 瓶颈
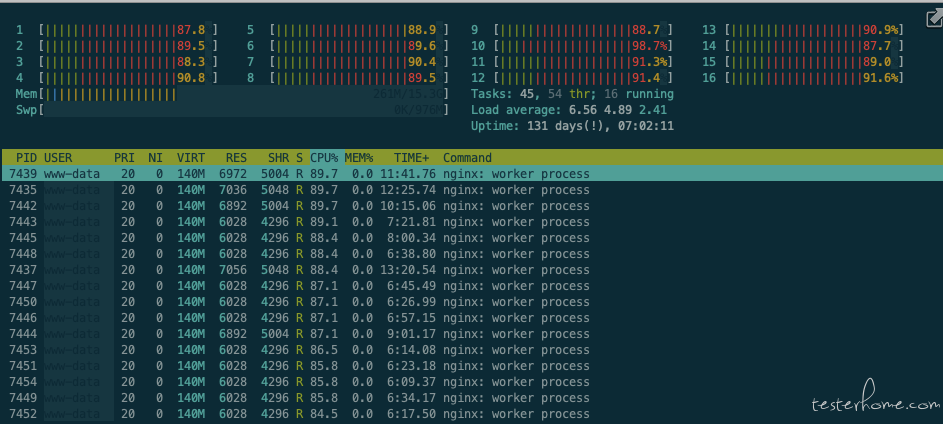
Wrk: CPU = 40% * 8 = 320%
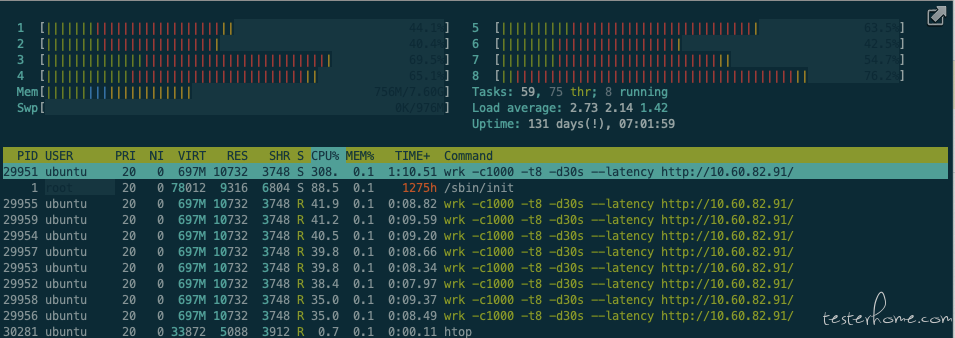
(2)Locust HttpUser 记录
1 进程:(10 并发,QPS:512)

Nginx:(CPU:8.6%)
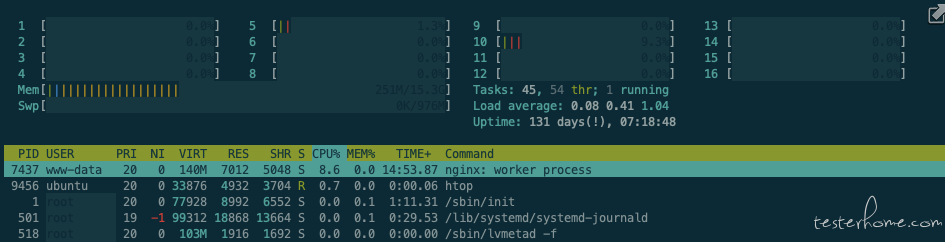
Locust:(CPU:100%, 单核 CPU 达到瓶颈)

8 进程:(100 并发,QPS:3300)

Nginx: (CPU:50%)
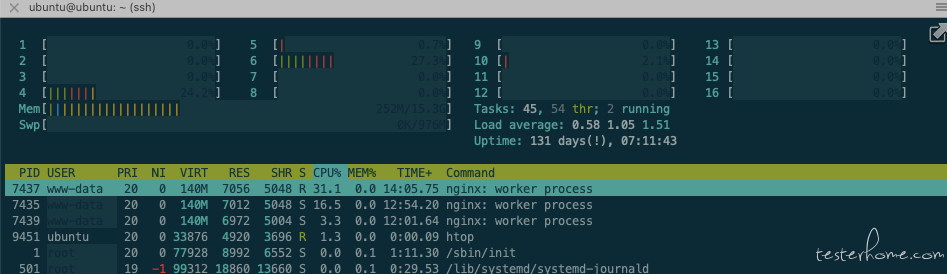
locust:(CPU:800%, CPU 达到瓶颈)

(3)Locust FastHttpUser 记录
1 进程:(10 并发,QPS:1836, 90%RT: 5ms)

Nginx:(CPU:24%)
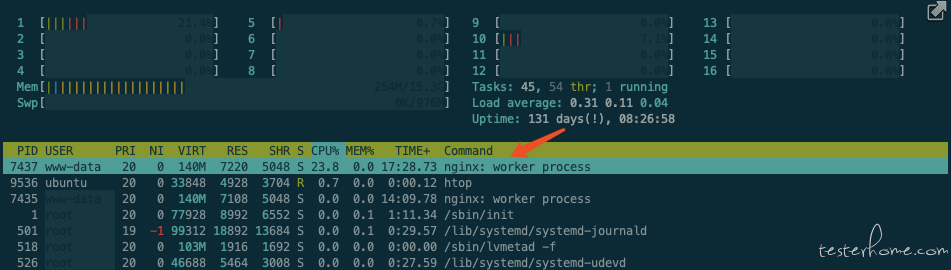
Locust:(CPU:100%, 单核 CPU 达到瓶颈)
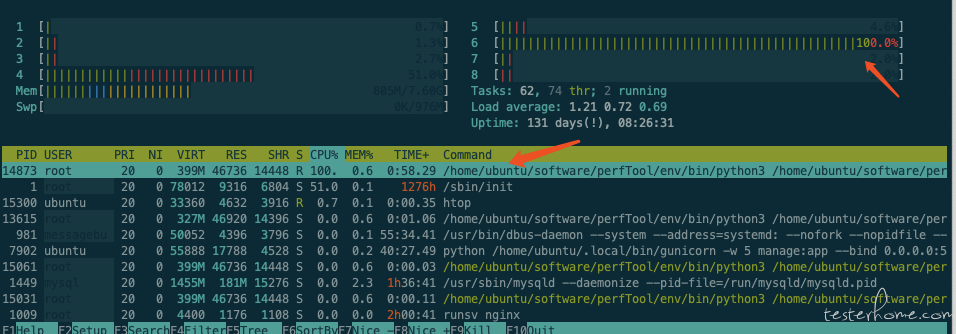
8 进程:(100 并发,QPS:11000, 90%RT: 7ms)

Nginx:(CPU:150%)
locust:(CPU:800%, CPU 达到瓶颈)

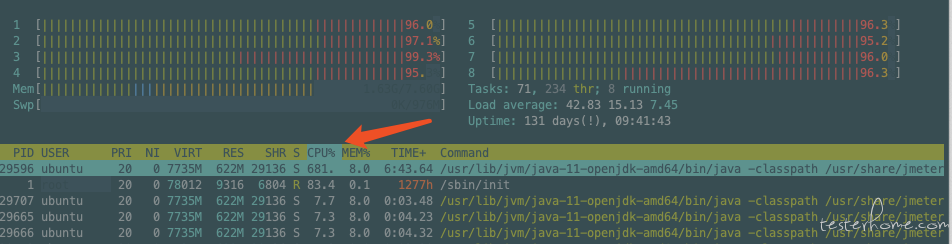
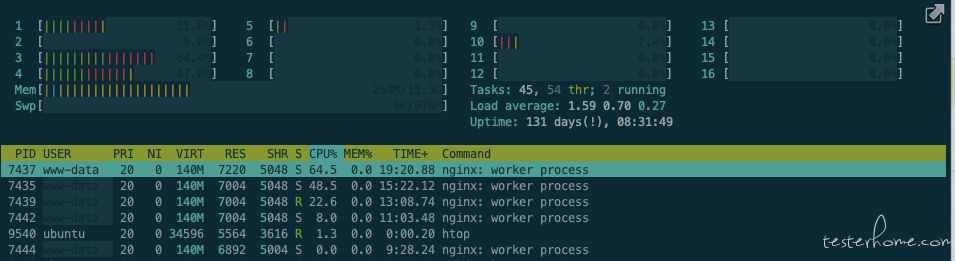
(4)Jmeter 测试记录
8 核 (100 并发,QPS:38500)
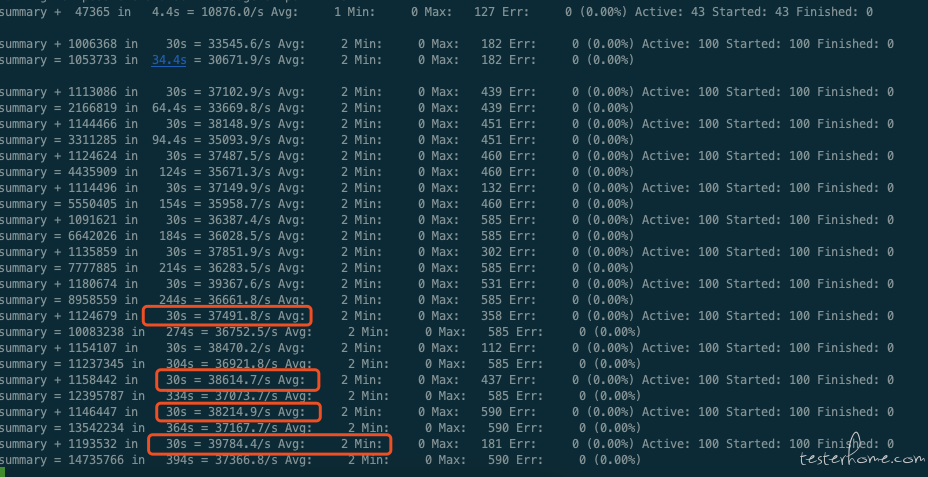
Nginx:(CPU:397.3%)
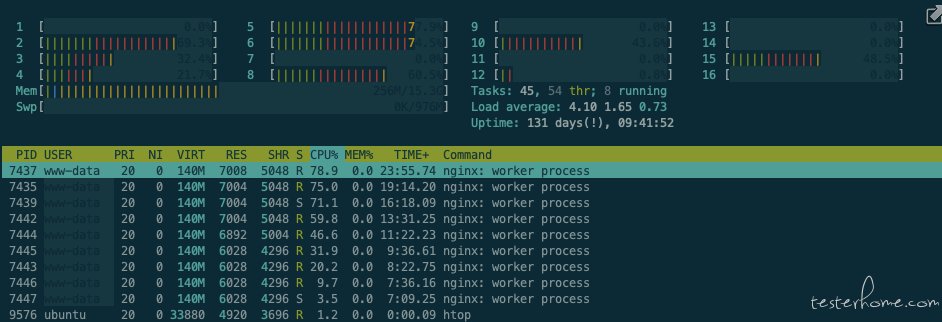
Jmeter:(CPU:681%)