原文见:在路上的博客
此文主要为科普文章,通过性能测试中常用的功能,来熟悉 Jmeter 和一些性能测试常识。
想更多了解服务端性能知识的,可以阅读:服务端性能测试 - 入门指南 (慎入: 6000 字长文)
俗话说的好:不依赖工具,但要重视工具。压测工具是压测理论的产物,学习好工具,可以帮助更加理解性能测试的基础知识。
性能测试,简而言之,就是模拟大量用户同时访问,测试服务是否满足性能要求。
1、选择合适的工具
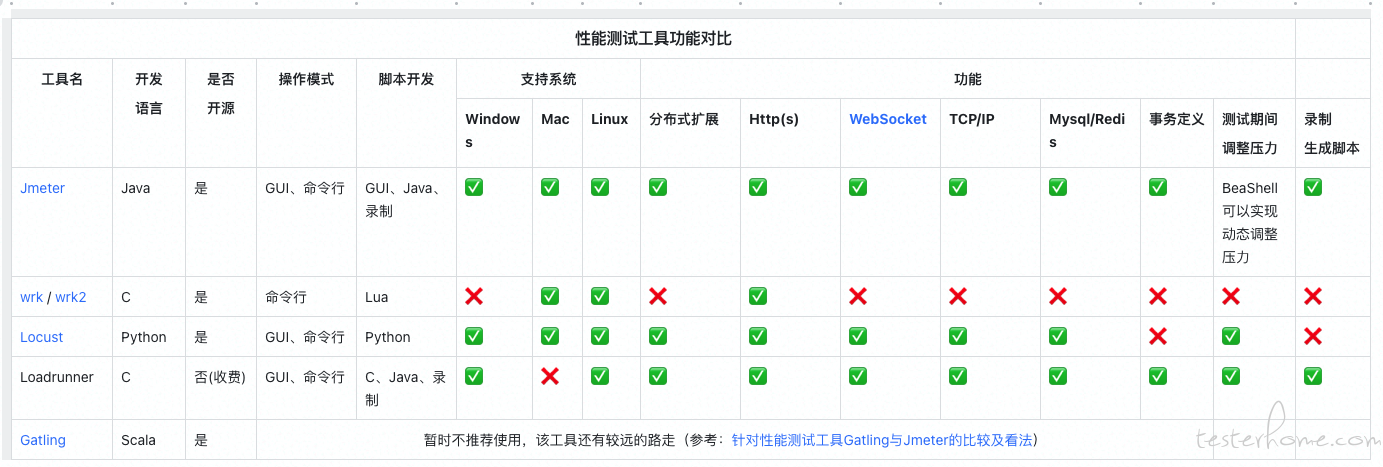
选择工具之前,首先了解一下,我们平常做性能测试,对性能工具的需求有哪些:
- 经常测试的对象:Http(s) 协议、WebSocket (网络通信协议)、TCP/IP(测试 Mysql、Redis)
- 扩展性好:支持分布式部署
- 使用成本低:文档多、支持 UI 界面操作、插件全
下面,我们从工具功能和性能两个角度,来横向对比。
性能测试工具功能对比:
性能测试工具性能对比:
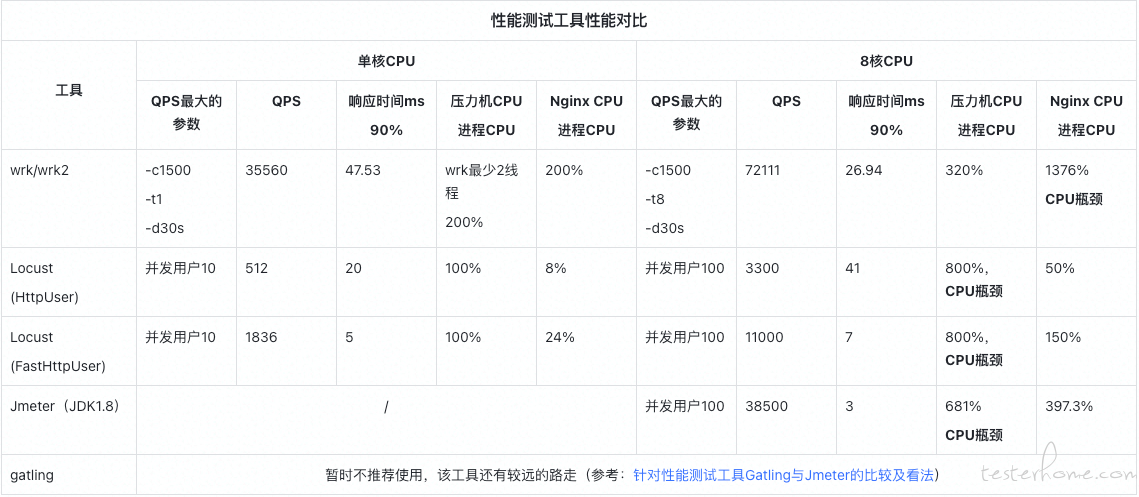
综上,考虑到免费、开源、支持多协议、分布式扩展、脚本开发方式、平台支持和性能表现,选择 Jmeter 作为我们主要的性能测试工具。
2、了解 Jmeter
(1)安装
- Jdk 安装
- Jmeter.zip 下载
- 解压后,运行 Jmeter.bat 或 Jmeter.sh 即可
启动后界面:
这里的线程组,可以理解为一个用户模型。
(2)线程组
线程组可以理解为用户模型。
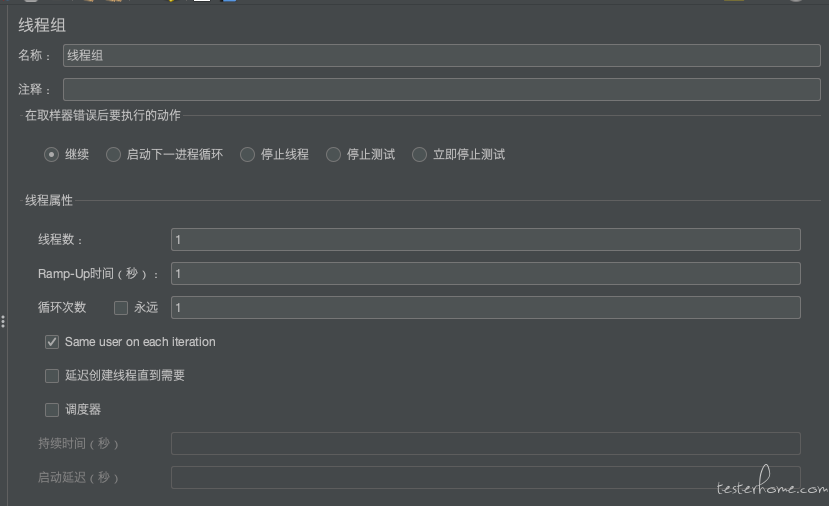
线程组控制面板包括:
- 线程组名称
- 线程数(正在测试的用户数)
- 加速 (Ramp-up) 时间:从 0 增加到线程数的时间
- 循环计数:循环测试的次数
- 调度器:
- 持续时间:表示脚本持续运行的时间,以秒为单位,比如如果你要让用户持续不断登录 1 个小时,你可以在文本框中填写 3600。这样就会在 1 小时内循环执行。
- 启动延迟:表示脚本延迟启动的时间,在点击启动后,如果启动时间已经到达,但是还没有到启动延迟的时间,那么,启动延迟将会覆盖启动时间,等到启动延迟的时间到达后,再运行系统。
(3)测试 Http 服务
下面以开发一个 Http 脚本为例,来熟悉性能测试中常用的功能和插件。
A. http 脚本开发
如图中所示,界面中一目了然,协议、域名、Method、Url、参数分别填到对应位置即可。
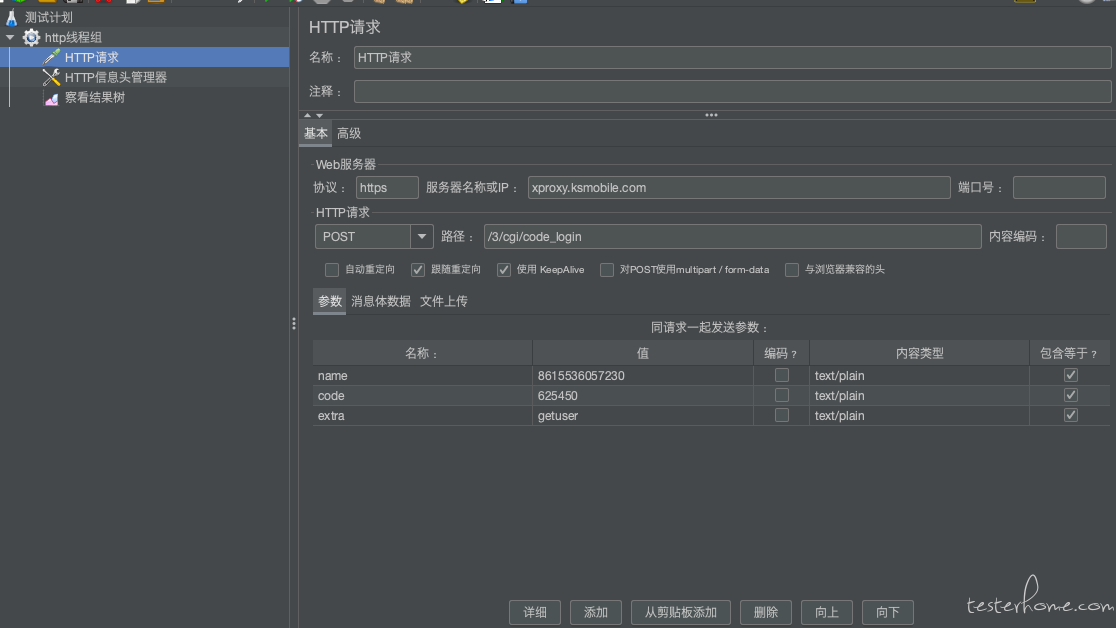
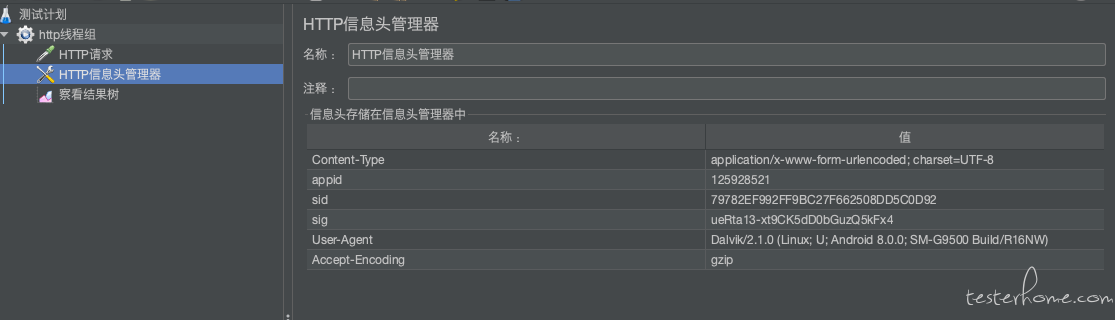
如果请求需要 header,可以添加 Http 信息头管理器,添加 header 信息。
B. 参数化
总所周知,性能测试接口必须进行参数化,如果是固定数据,可能导致所有请求全部访问了缓存,这样就无法评估服务真实性能。
Jmeter 参数化有 3 种常用方法:用户自定义变量、csv 数据文件设置、BeanShell 预处理变量。
用户自定义变量
可以设置一些常量变量。

csv 数据文件设置
可设置参数化数量较多常量。

BeanShell 预处理变量
当有些变量需要加解密处理时,就需要 BeanShell 预处理。
注意:Jmeter 通过 vars.put(“变量名”, “变量值”) 来声明 Jmeter 变量。
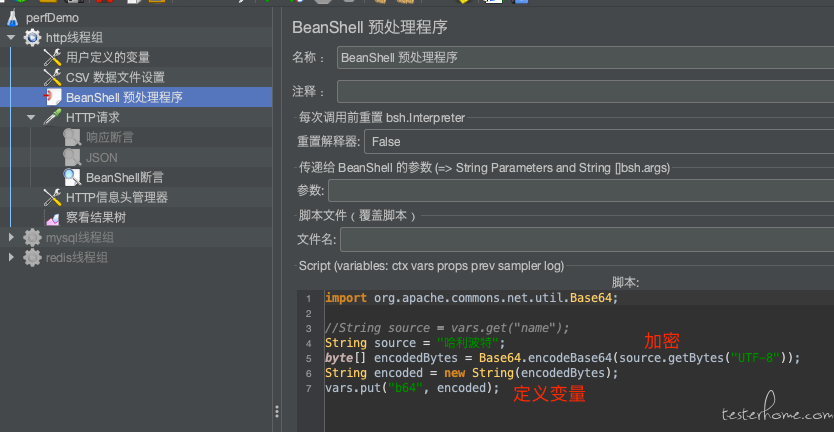
import org.apache.commons.net.util.Base64;
// base64加密
String source = "哈利波特";
byte[] encodedBytes = Base64.encodeBase64(source.getBytes("UTF-8"));
String encoded = new String(encodedBytes);
vars.put("b64", encoded);
C. 断言
断言是用于检查 Http 请求 Response 是否满足预期的手段。
Jmeter 常用的断言方法有 3 种:响应断言、Json 断言、Beanshell 断言。
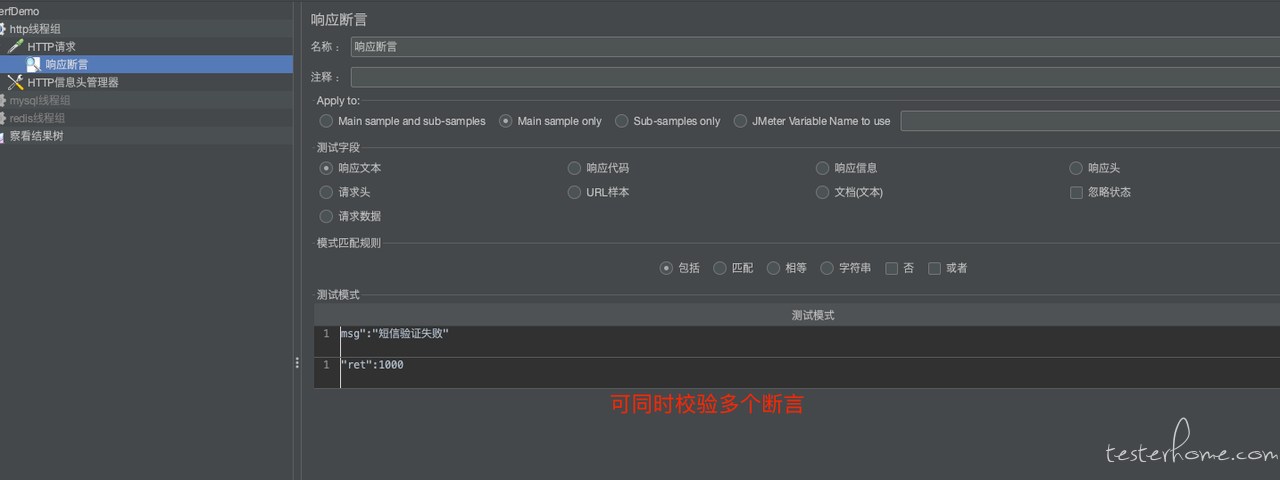
响应断言
如图所示,可以直接判断 Response body 中是否包含期望字符串,方式有包含、匹配、相等…
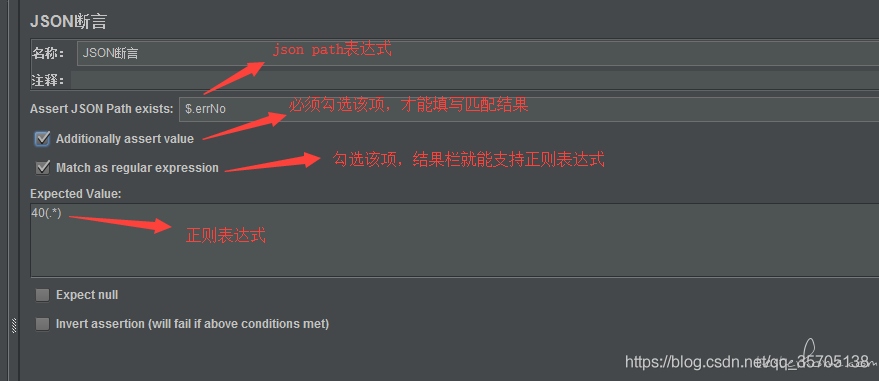
JSON 断言
当 Response Body 为 Json 格式时,可以通过 Json 断言插件,精确断言响应内容。
BeanShell 断言
BeanShell 是 jmeter 的解释型脚本语言,和 java 语法大同小异,并有自己的内置对象和方法可供使用。
vars:操作 jmeter 的变量:vars.get(String parmStr) 获取 jmeter 的变量值;vars.put(String key,String value) 把数据存到 Jmeter 变量中;
prev:获取 sample 返回的信息,prev.getResponseDataAsString() 获取响应信息;prev.getResponseCode() 获取响应状态码;
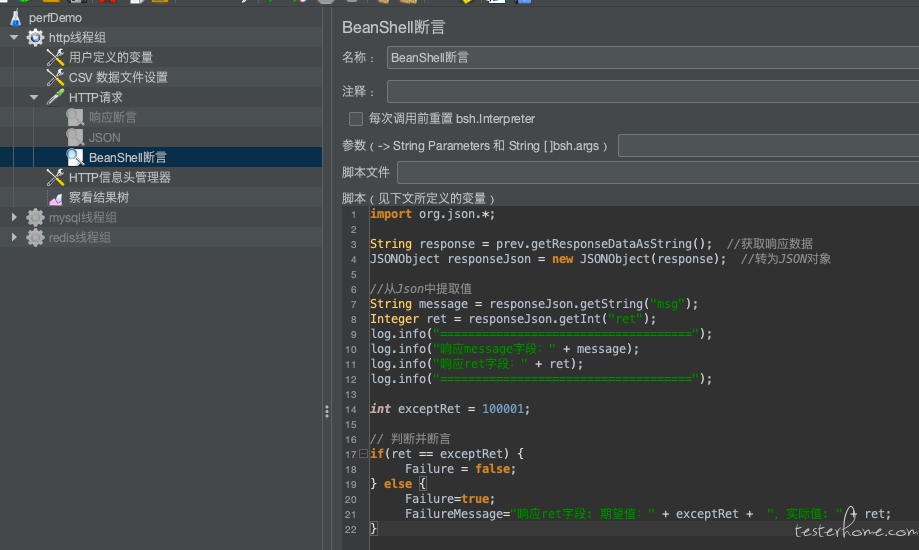
import org.json.*;
String response = prev.getResponseDataAsString(); //获取响应数据
JSONObject responseJson = new JSONObject(response); //转为JSON对象
//从Json中提取值
Integer code = responseJson.getInt("code");
String result = responseJson.getString("result");
log.info("====================================");
log.info("响应code字段:" + code); log.info("响应result字段:" + result);
log.info("===================================="); int exceptCode = 200;
// 判断并断言
if(code == exceptCode)
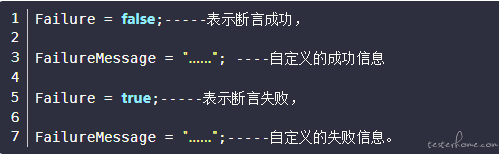
{
Failure = false;
} else {
Failure=true;
FailureMessage="响应code字段: 期望值:" + exceptCode + ",实际值: " + code;
}
##(4)测试 Mysql
配置 mysql 连接(JDBC Connection Configuration)
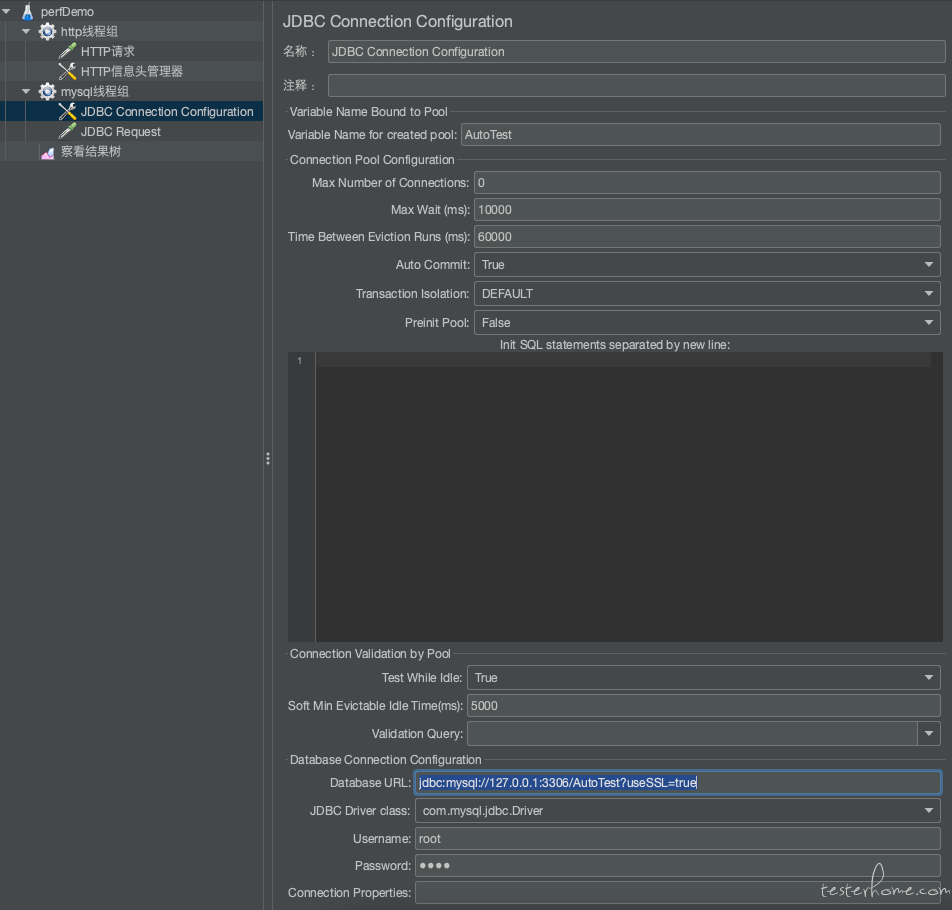
需要设置一些重要的字段,这些字段将决定数据库和 JMeter 之间的正确连接。 这些字段包括:
-
上半部分:
- ariables Name for created pool:变量名,在 JDBC Request 的时候会用同样的名字确定是连接的那个库和进行的配置
- MaxNumber of Connection:数据库最大链接数,通常该值设置为 0
- Max wait:最大的等待时间 ms 毫秒,超出后会抛一个错误
- Time Between Eviction Runs (ms):数据库空闲连接的回收时间间隔
- Auto Commit:自动提交。有三个选项,true、false、编辑,选择 true 后, 每条 sql 语句就是一个事务,执行结束后会自动提交;false、编辑则不会提交,需要自己手动提交
- Transaction Isolation: 数据库事务隔离的级别设置
- TRANSACTION_NONE:不支持的事务
- TRANSACTION_READ_UNCOMMITTED :事务读取未提交内容
- TRANSACTION_READ_COMMITTED: 事务读取已提交读内容
- TRANSACTION_SERIALIZABLE: 事务序列化(一个事务读时,其他事务只能读,不能写)
- DEFAULT:默认
- TRANSACTION_REPEATABLE_READ :事务重复读(一个事务修改数据对另一个事务不会造成影响)
-
下半部分:
- 绑定到池的变量名称 - 它唯一地标识配置。 JDBC Sampler 将进一步使用此名称来标识要使用的配置。这里将其命名为 test。
- 数据库 URL:jdbc:mysql://127.0.0.1:3306/AutoTest?useSSL=true
- JDBC 驱动程序类 - com.mysql.jdbc.Driver。
- 用户名 - root。
- 密码 - root 用户的密码。
- 其他字段保持不变。
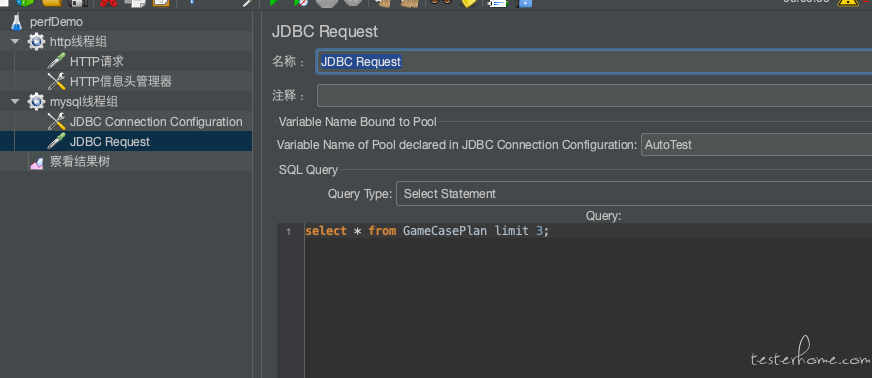
JDBC Request
可直接输入 SQL:
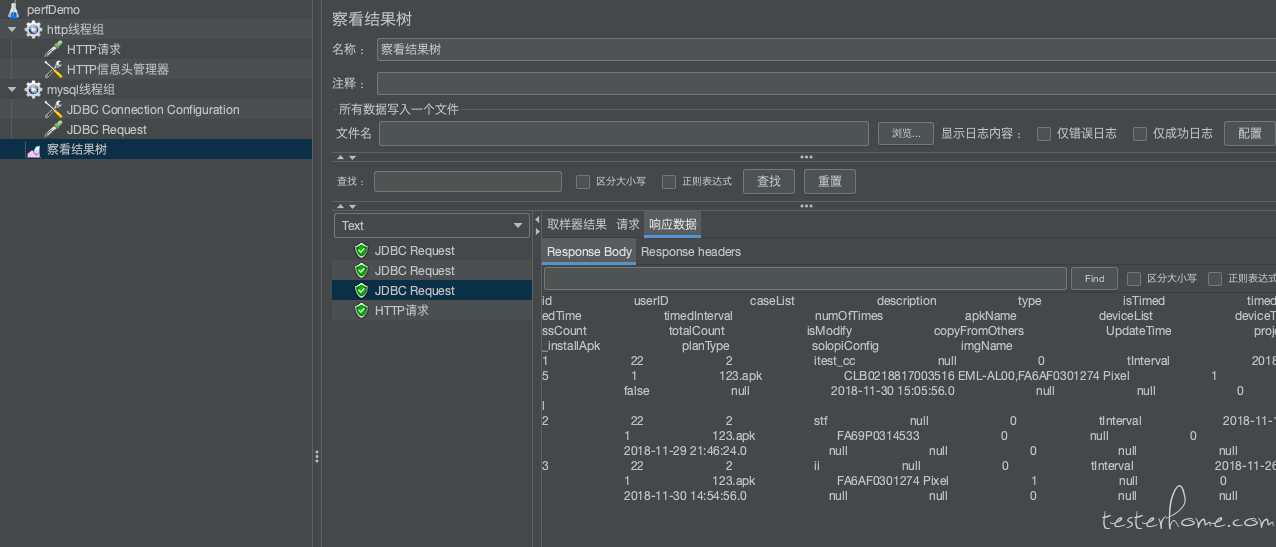
检查 Sql 语言执行结果:
(5)事务定义
将多个接口定义为事务,以便从业务的角度,来评估性能。
比如,完整的手机验证码登录流程,一般包含:(1)获取手机验证码;(2)用手机号和验证码进行登录;
当定义为登录事务时,性能测试的时候,我们就可以更宏观的关注服务端对登录事务的性能评估,而不是只关注到接口层。
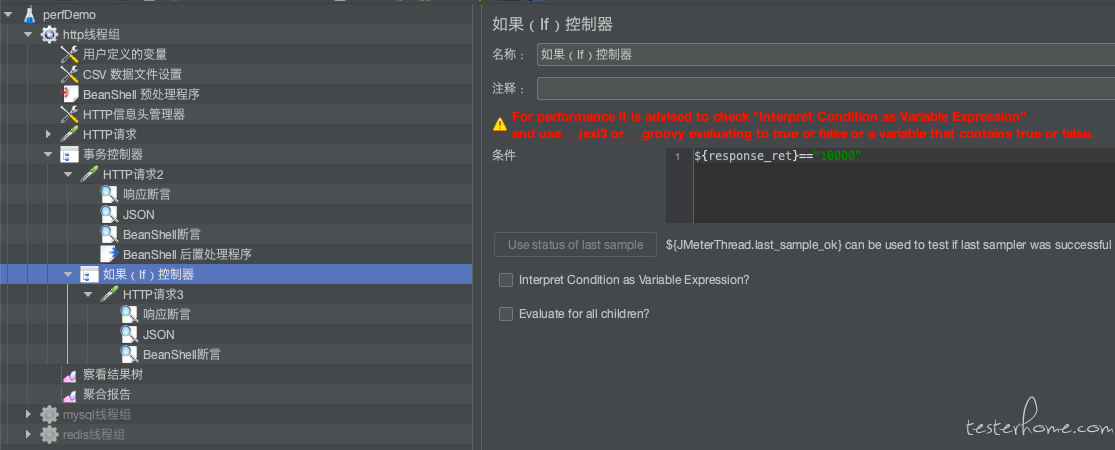
(6)逻辑控制器
当面对复杂业务时,比如涉及到逻辑判断的,就需要添加逻辑控制器。
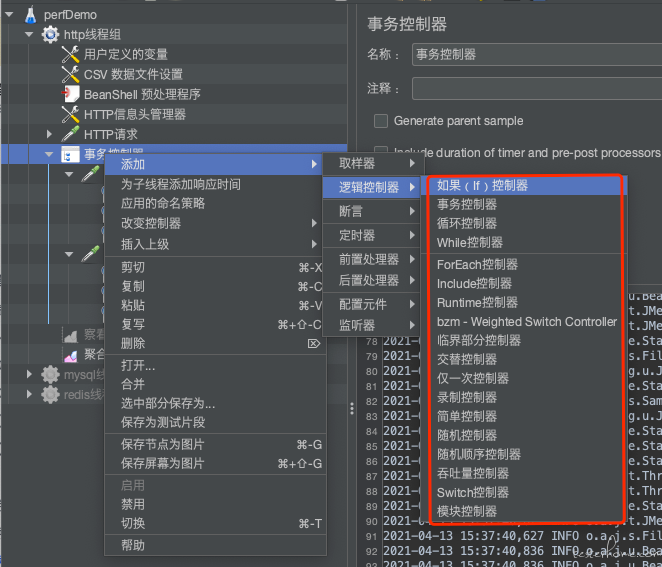
比如,if 控制器:
利用接口 1 的返回信息,进行逻辑判断,决定是否执行接口 2。比如根据用户状态信息,判断用户是否是 VIP 用户,如果不是,则不能购买某商品。
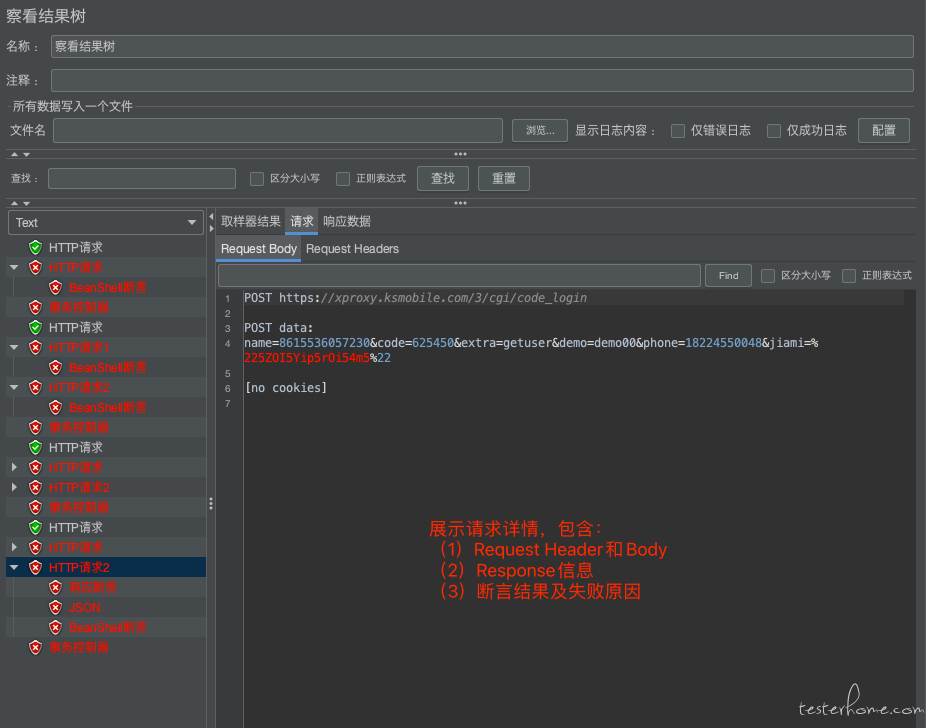
(7)调试插件
查看结果树
调试脚本时,可以利用查看结果树插件来查看 request 和 response 信息,保障脚本的正确。
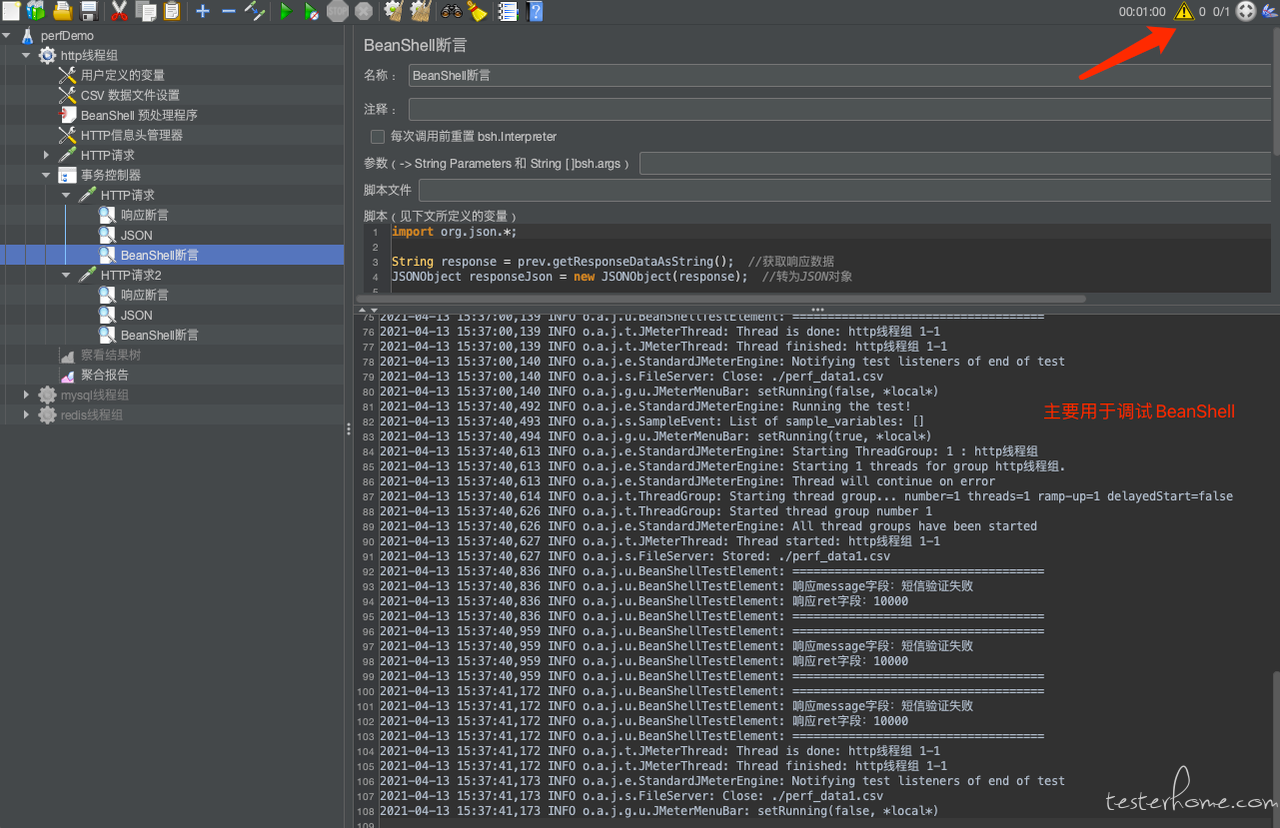
Jmeter 执行 Log
一般是编写 BeanShell 或引入 jar 包时,脚本调试需要看 log,定位脚本开发的问题。
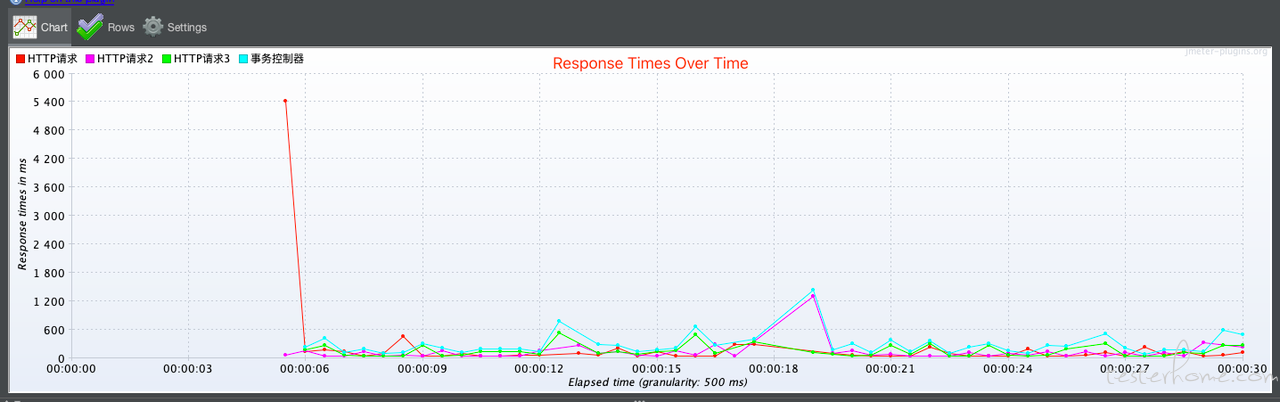
(8)关注的性能指标
- QPS(TPS):每秒请求数
- 成功率:请求成功率
- 95% 响应时间和 99% 响应时间:更真实表现大部分用户承受的响应时间。
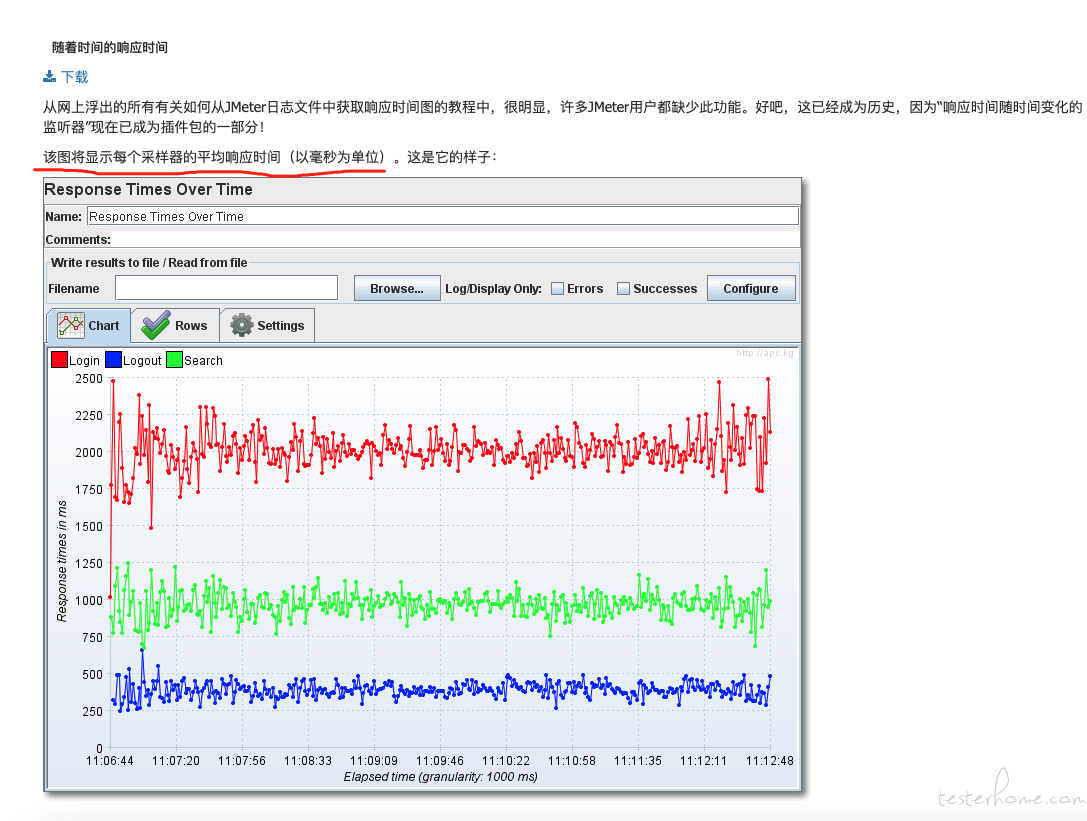
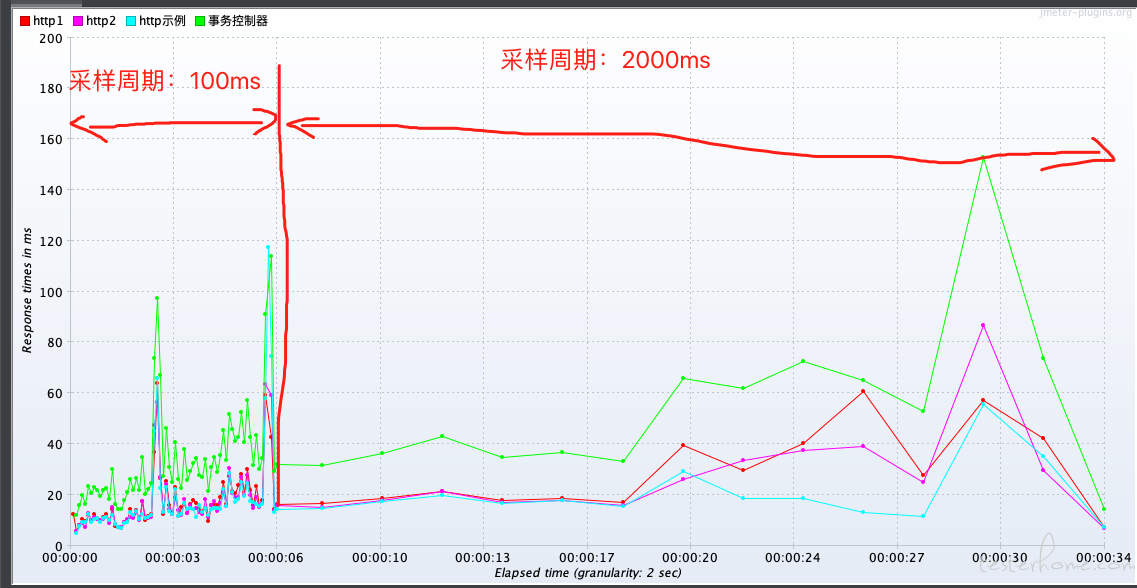
- 响应时间和 QPS 变化曲线:主要看性能测试期间,服务是否稳定。比如 Java 后端,在性能测试期间,不允许出现 Full GC。
3、Jmeter 优化建议
(1)调整 JMeter 堆栈内存大小
在默认情况下现在 JMeter5 版本开辟的内存空间为 1G,这也是它的最大内存。在实际测试的过程中,默认 JMeter 内存配置情况下,开启 3W 个线程来处理 http 的静态访问求基本上就达到了极限。再往上加的可能会报 OOM 的错误。
有两个 JAVA 的参数直接影响着 JMeter 能够使用的系统内存为多少,一个是 “Xms”(代表初始化堆栈内存的大小),一个是 “Xmx(代表最大内存池可以分配的大小)”。如果你的测试机器只跑 JMeter 一个 JAVA 应用程序,那么建议 Xmx 和 Xms 保持一致。Xmx 和 Xms 保持一致是为了减少 JVM 内存伸缩,减少维护伸缩带来的成本。
(2)64 位操作系统内存配置大小
JMeter 内存分配尽量在 32 位的系统上避免分配 4G 以上空间,在 64 位的操作系统尽量避免分配 32G 以上的空间。
(3)垃圾回收机制
在 JAVA 中有大概五类的垃圾回收机制。分为 Serial 收集器,ParNew 收集器,Parallel 收集器,Cms 收集器,G1 收集器。在垃圾回收机制上应该尽量减少垃圾回收器带来的内存和 CPU 的性能损耗。当然这些并不会对开启线程数有着决定性的影响,属于细节性的微调。这里比较推荐使用 G1 垃圾回收器。G1 垃圾回收器的特点如下:
- 支持很大的堆,高吞吐量
- 支持多 CPU 垃圾回收
- 在主线程暂停时,使用并行回收
- 在主线程运行时,使用并发回收。
(4)使用非 GUI 模式
GUI 在一定程度上冻结并消耗资源,这样会更容易产生一些不准确的性能测试结果。
对于 JMeter 来说 GUI 存在的意义主要在于可视化输出结果,编写你的测试计划和 debug 你的测试计划。
jmeter 命令执行:
jmeter -n -t /usr/local/apache-jmeter-4.0/my_threads/sfwl.jmx
参数说明:
-h 帮助 -> 打印出有用的信息并退出
-n 非 GUI 模式 -> 在非 GUI 模式下运行 JMeter
-t 测试文件 -> 要运行的 JMeter 测试脚本文件
-l 日志文件 -> 记录结果的文件
-r 远程执行 -> 启动远程服务
-H 代理主机 -> 设置 JMeter 使用的代理主机
-P 代理端口 -> 设置 JMeter 使用的代理主机的端口号
注意:如果未设置 Jmeter 的环境变量则在执行脚本的时候需要检查当前目录是否是 jmeter 的 bin 目录下
(5)升级 JMeter 与 JAVA 版本
尽可能使用最新版本的 JMeter 来进行性能测试,新版本的 JMeter 会使用新版的 JRE 和 JDK,这样会一定程度上带来性能的提升。
(6)压测过程中禁用监听器
实行压测的过程中尽可能少使用监听器,最好别用。启用监听器会导致额外的内存开销,这会消耗测试中为数不多的内存资源。比较明智的做法是使用非 GUI 模式,将测试结果全部保存到 “.jtl” 的文件中。测试完成之后将 jtl 格式的结果文件导入的 JMeter 中再进行结果分析。
(7)谨慎使用断言
添加到测试计划的每个测试元素都将被处理。这样会占用较多的 CPU 和内存。这种资源的占用适用于所有的断言,尤其是比较断言。比较断言消耗大量资源和内存,所以在压力测试时慎重的使用断言和断言的数量。
(8)利用分布式
分布式部署 Jmeter,利用压力机集群进行压测,提升 Jmeter 的测试能力。