性能测试工具 图像分类、AI 与全自动性能测试
项目地址:https://github.com/williamfzc/stagesepx
官方文档:https://williamfzc.github.io/stagesepx/#/
使用指引:https://github.com/williamfzc/work_with_stagesepx
前言
我又来啦。
在之前一年里,我陆陆续续分享了一些图像识别在测试领域内的应用实践,功能测试与性能测试都有涉及。前段时间写了 让所有人都能用图像识别做 UI 自动化 与 基于图像识别的 UI 自动化解决方案 之后 ,随着他逐渐稳定下来,在功能测试的这一块的个人目标终于基本算是完成了。
在性能测试方向,近期也有不少同学一直很关注这项技术在性能测试上的应用。这是之前陆陆续续做的两个版本:
尽管后来的版本已经基本可用(后来随着迭代,效率变得太低了,又变得不太可用了),但总感觉,这不是一个最理想的版本。
经过这段时间,我终于做好了一个更加符合我预期的方案: stagesep-x。
为什么又开新坑
与之前的版本相比,它原理完全不同,使用场景也不完全一致。所以我选择另外开一个项目而不是继续迭代。
stagesepx 能做什么
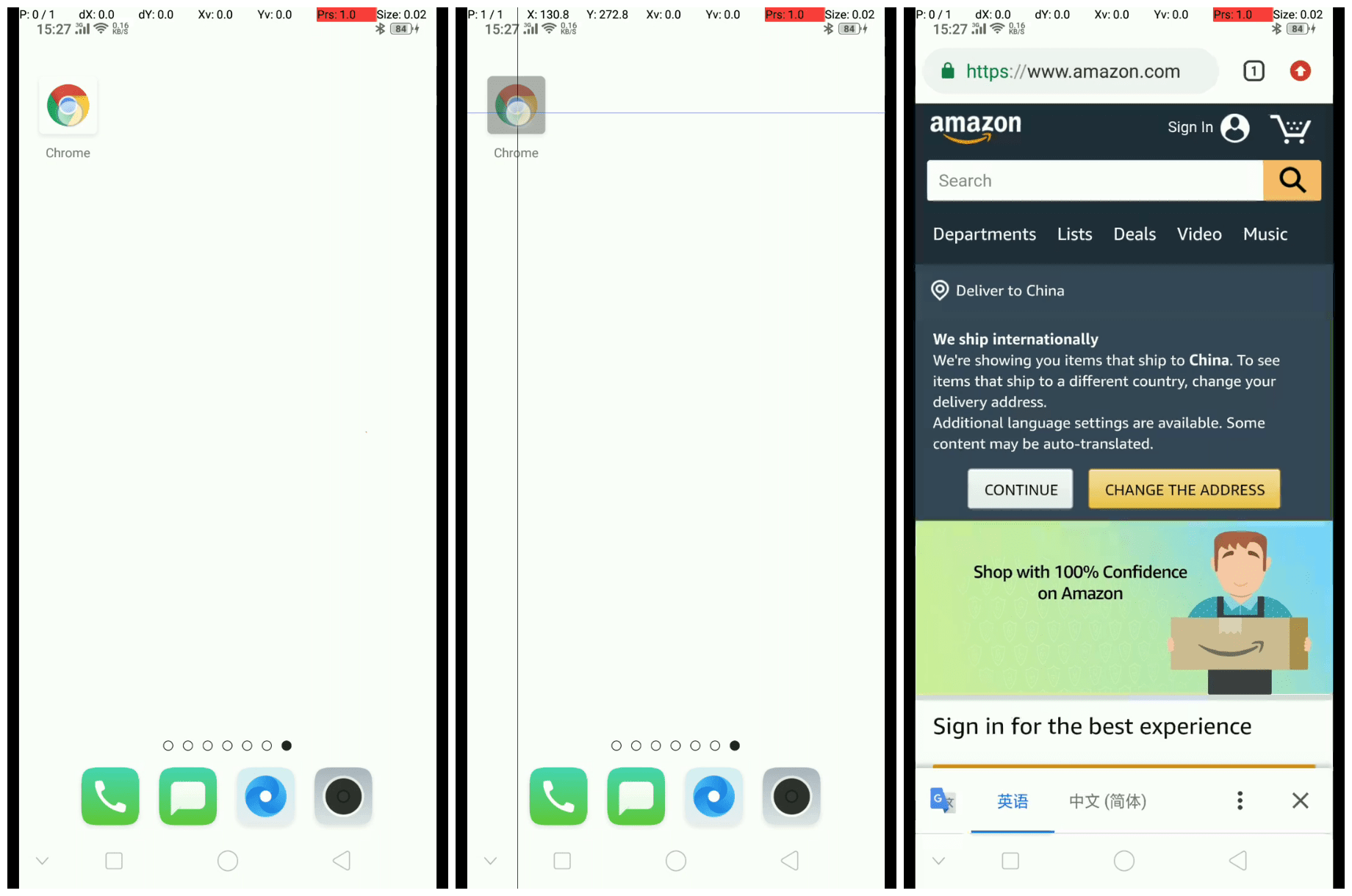
在软件工程领域,视频是一种较为通用的 UI(现象)描述方法。它能够记录下用户到底做了哪些操作,以及界面发生了什么事情。例如,下面的例子描述了从桌面打开 chrome 进入 amazon 主页的过程:

stagesepx 能够自动侦测并提取视频中的稳定或不稳定的阶段(例子中,stagesepx 认为视频中包含三个稳定的阶段,分别是点击前、点击时与页面加载完成后):
然后,自动得到每个阶段对应的时间区间:
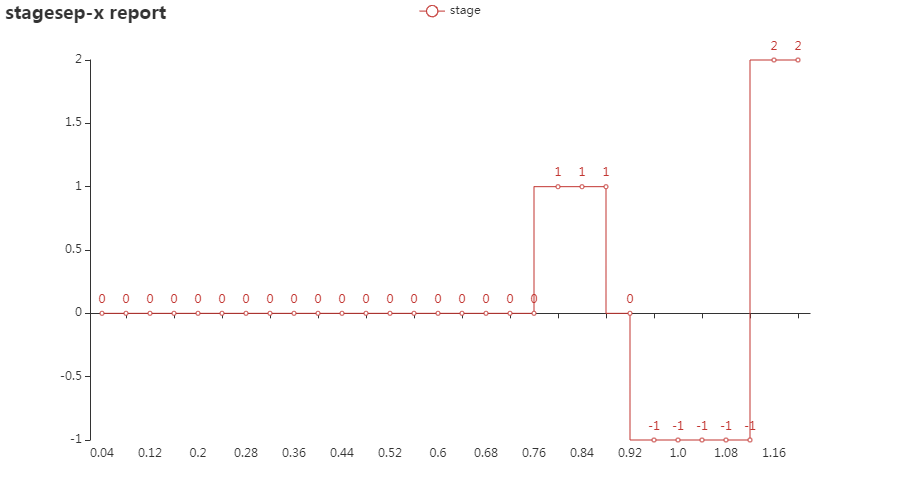
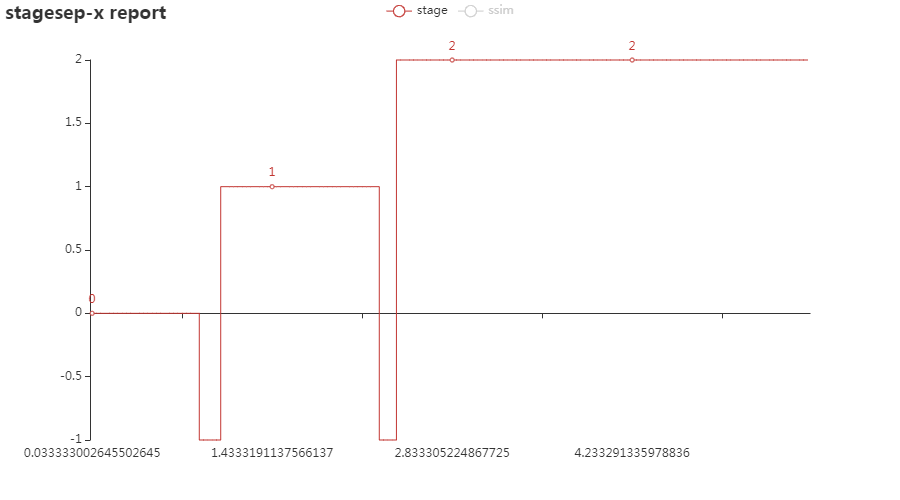
例如,从图中可以看出:
- 视频开始直到 0.76s 时维持在阶段 0
- 在 0.76s 时从阶段 0 切换到阶段 1
- 在 0.92s 时从阶段 1 切换到阶段 0,随后进入变化状态(当 stagesepx 无法将帧分为某特定类别、或帧不在待分析范围内时,会被标记为 -1,一般会在页面发生变化的过程中出现)
- 在 1.16s 时到达阶段 2
- ...
以此类推,我们能够对视频的每个阶段进行非常细致的评估。通过观察视频也可以发现,识别效果与实际完全一致。
在运行过程中,stagesepx 强大的快照功能能够让你很轻松地知道每个阶段到底发生了什么:
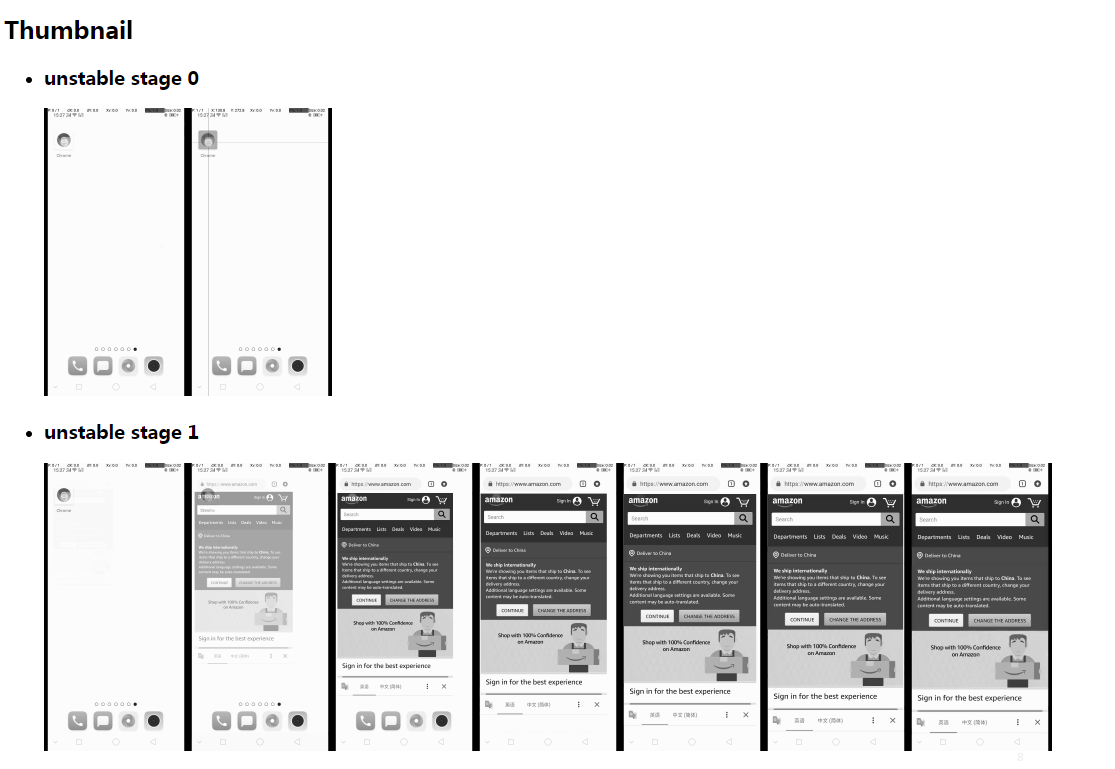
而所有的一切只需要一个视频,无需前置模板、无需提前学习。
应用举例
所有 stagesepx 需要的只是一个视频,而且它本质上只跟视频有关联,并没有任何特定的使用场景!所以,你可以尽情发挥你的想象力,用它帮助你实现更多的功能。
APP
- 前面提到的应用启动速度计算
- 那么同理,页面切换速度等方面都可以应用
- 除了性能,你可以使用切割器对视频切割后,用诸如findit等图像识别方案对功能性进行校验
- 除了应用,游戏这种无法用传统测试方法的场景更是它的主场
- ...
除了 APP?
- 除了移动端,当然 PC、网页也可以同理计算出结果
- 甚至任何视频?
[
[
Do whatever you want:)
使用
安装
Python >= 3.6
pip install stagesepx
例子
还想要更多功能?
当然,stagesepx 不仅如此。但在开始下面的阅读之前,你需要了解 切割器(cutter)与 分类器(classifier)。stagesepx 主要由这两个概念组成。
切割器
顾名思义,切割器的功能是将一个视频按照一定的规律切割成多个部分。他负责视频阶段划分与采样,作为数据采集者为其他工具(例如 AI 模型)提供自动化的数据支持。它应该提供友好的接口或其他形式为外部(包括分类器)提供支持。例如,pick_and_save方法完全是为了能够使数据直接被 keras 利用而设计的。
切割器的定位是预处理,降低其他模块的运作成本及重复度。得到稳定区间之后,我们可以知道视频中有几个稳定阶段、提取稳定阶段对应的帧等等。在此基础上,你可以很轻松地对阶段进行图片采样(例子中为每个阶段采集 3 张图片,一共有 3 个稳定阶段,分别名为 0、1、2)后保存起来,以备他用(例如 AI 训练、功能检测等等):
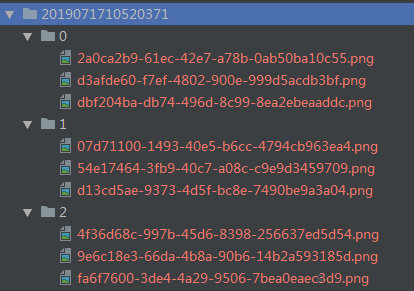
分类器
针对上面的例子,分类器应运而生。它主要是加载(在 AI 分类器上可能是学习)一些分类好的图片,并据此对帧(图片)进行分类。
例如,当加载上述例子中稳定阶段对应的帧后,分类器即可将视频进行帧级别的分类,得到每个阶段的准确耗时。
分类器的定位是对视频进行帧级别、高准确度的图片分类,并能够利用采样结果。它应该有不同的存在形态(例如机器学习模型)、以达到不同的分类效果。例如,你可以在前几次视频中用采样得到的数据训练你的 AI 模型,当它收敛之后在你未来的分析中你就可以直接利用训练好的模型进行分类,而不需要前置的采样过程了。stagesep2本质上是一个分类器。
不同形态的分类器
stagesepx 提供了两种不同类型的分类器,用于处理切割后的结果:
- 传统的 SSIM 分类器无需训练且较为轻量化,多用于阶段较少、较为简单的视频;
- SVM + HoG 分类器在阶段复杂的视频上表现较好,你可以用不同的视频对它进行训练逐步提高它的识别效果,使其足够被用于生产环境;
目前基于 CNN 的分类器已经初步完成,在稳定后会加入 :)但目前来看,前两个分类器在较短视频上的应用已经足够了(可能需要调优,但原理上是够用的)。
事实上,stagesepx 在设计上更加鼓励开发者根据自己的实际需要设计并使用自己的分类器,以达到最好的效果。
丰富的图表
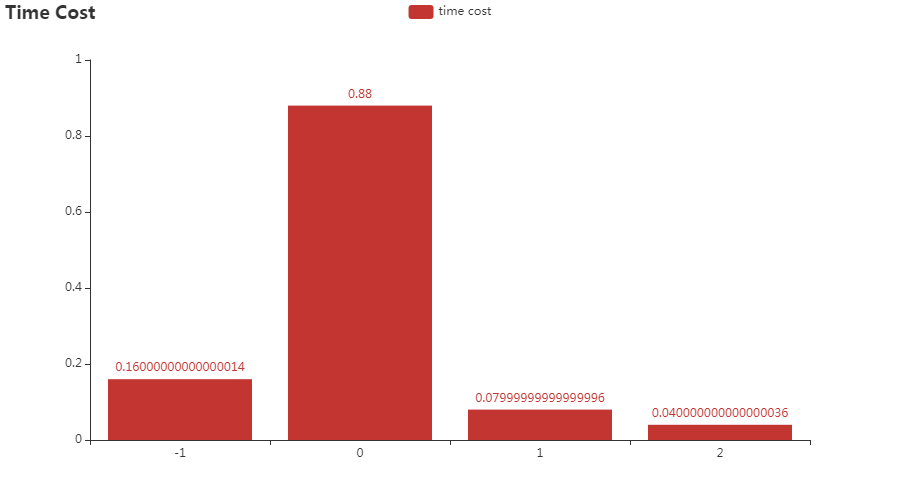
想得到耗时?stagesepx 已经帮你计算好了:
快照功能能够让你很直观地知道每个阶段的情况:
...
优异的性能表现
在效率方面,吸取了 stagesep2 的教训(他真的很慢,而这一点让他很难被用于生产环境),在项目规划期我们就将性能的优先级提高。对于该视频而言,可以从日志中看到,它的耗时在惊人的 300 毫秒左右(windows7 i7-6700 3.4GHz 16G):
2019-07-17 10:52:03.429 | INFO | stagesepx.cutter:cut:200 - start cutting: test.mp4
...
2019-07-17 10:52:03.792 | INFO | stagesepx.cutter:cut:203 - cut finished: test.mp4
除了常规的基于图像本身的优化手段,stagesepx 主要利用采样机制进行性能优化,它指把时间域或空间域的连续量转化成离散量的过程。由于分类器的精确度要求较高,该机制更多被用于切割器部分,用于加速切割过程。它在计算量方面优化幅度是非常可观的,以 5 帧的步长为例,它相比优化前节省了 80% 的计算量。
当然,采样相比连续计算会存在一定的误差,如果你的视频变化较为激烈或者你希望有较高的准确度,你也可以关闭采样功能。
更强的稳定性
stagesep2 存在的另一个问题是,对视频本身的要求较高,抗干扰能力不强。这主要是它本身使用的模块(template matching、OCR 等)导致的,旋转、分辨率、光照都会对识别效果造成影响;由于它强依赖预先准备好的模板图片,如果模板图片的录制环境与视频有所差异,很容易导致误判的发生。
而 SSIM 本身的抗干扰能力相对较强。如果使用默认的 SSIM 分类器,所有的数据(训练集与测试集)都来源于同一个视频,保证了环境的一致性,规避了不同环境(例如旋转、光照、分辨率等)带来的影响,大幅度降低了误判的发生。
Bug Report
可想而知的,要考虑到所有的场景是非常困难的,在项目前期很难做到。
有什么建议或者遇到问题可以通过 issue 反馈给我 :)
项目地址
这个很有意思
你的分类器模型训练 用 GPU 训练用例多久的时间
这完全取决于训练集的大小跟你选择的特征。
现在的 SVM 分类器用的是 sklearn 的版本,理论上性能与 sklearn 是一致的,我没有测过 GPU 的(对于单视频来说训练速度已经很快了,感觉没有测的必要),你可以试试看呢。https://scikit-learn.org/stable/modules/classes.html#module-sklearn.svm
来了,老哥~
我试试看好用不
应用页本身有动画,有办法区分么
动画是个比较难解决的问题,现在的容错机制可以满足一些比较常规的动画(例如跑马灯)。
如果应用页带有比较复杂的动画(例如有视频插入),最佳方案还是手动采集一些图片去训练模型,然后再用模型来分析视频。
慢慢读完了这篇帖子,内容非常的新颖,也有一些新的启发,做新的东西都是很了不起的。 首先说一下优点,只由视频来确定表层的性能因素,我可以理解为跨平台了,因为无论哪个平台记录的表象,都可以最终由视频来输出确立。 然后 我想说一下我的疑惑,视频算是一种介质,但如果我作为测试,我可能会更想确立内因,比如在 Android 上,我确立某个场景发生了 Jank,可以分析 SufaceFlinger 去得到这类信息(app 开始绘制时间, Sync 把帧给至硬件时间,显示到屏幕上的时间),这里跟你的<点击前、点击时与页面加载完成后>这个概念是不相同的。那么这个工具的主要用途我可以认为是:可以从导出的视频中,找到哪里可能存在性能问题吗?
既然所有的信息都来自于视频,那么这个工具自然是不可能得到超出这个视频的信息。所以你提到的内因确立不属于这个工具的范畴内了。当然,以 android 为例,你可以在录制过程中同步记录日志去进一步定位问题所在,或者别的你喜欢的方式。
可以从导出的视频中,找到哪里可能存在性能问题吗?
用途的话,在上面的应用举例应该说得挺清楚的,这取决于你怎么使用了。性能方向的话我觉得比较适合做性能数据采集跟 benchmark,定位问题的话光视频不是很够。最好是跟 app 自身的埋点或者日志结合起来用。
这种方案针对一些动态加载场景如果有效的检测结束帧?
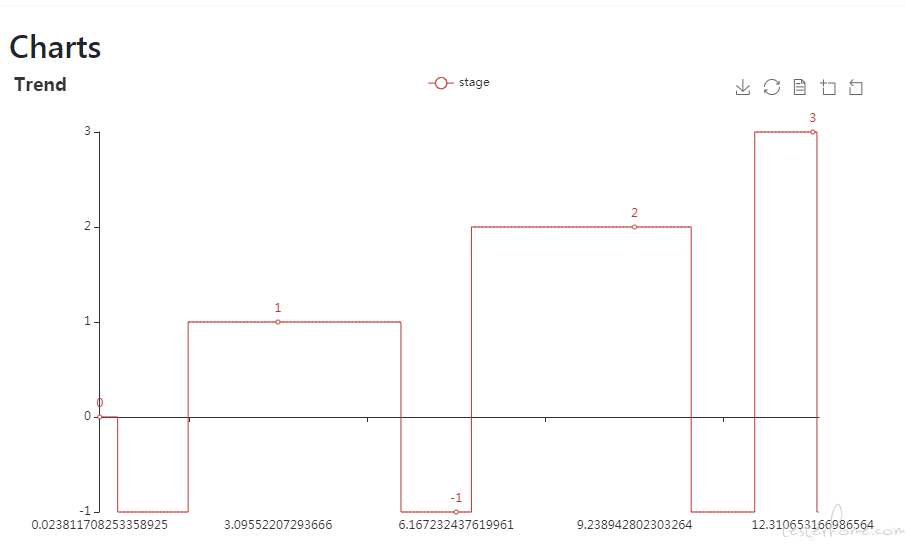

首先呢,设计的初衷是希望能尽可能找出所有分类的,因为需求不唯一,例如有些人的测试主体就是轮播图。在此基础上,开发者可以通过修改配置来定制自己的功能。
如果要拟合的话,有两种方式:
- 降低阈值,使得轮播过程不被认为处于变化中。但这种方式会影响其他阶段的识别,并不推荐
- 手动调整切割结果,重新训练模型。
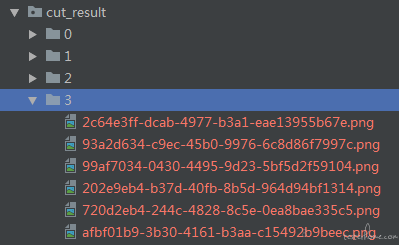
正常切割之后会生成一系列分类好的图片,如果你希望将 2 阶段与 3 阶段拟合,你可以将 3 中的图片丢到 2 中,然后将 3 文件夹删除。这样做之后分类器会将他们分为同一类。
当然,这个过程显得很不智能。但是在训练完成后,你大可以将训练好的模型保存下来。以后你可以直接用这个模型来分析视频,而无需前置的切割过程。
额,我的意思其实复杂场景下依靠全局样式去做聚类会有局限性,一旦页面持续变化区域较大分类算法精度就不够准确,就类似前后帧的对比算法一样控制阀值也不靠谱。
我个人认为要做这一类的加载过程的判断,真正核心要解决的是通过算法感知页面内容的变化, 不仅是全局且要细化到局部。
不要把算法想的多万能啊。
传统算法就模板匹配在固定场景下还凑合,泛化能力呵呵哒。
从源拉下来图片然后做模板匹配,不断迭代试试看呢?
山无陵天地合我都要点这个赞。
之前基于 opencv 读取过视频每帧的相对时间,用的 CAP_PROP_POS_MSEC 发现不准,和一些商用软件采集每帧的相对时间不一样,楼主有遇到这个问题么
我用一个软件录制的视频,用 opencvCAP_PROP_POS_MSEC 取的时间不对,所以算不稳定两帧之间的时间差就是错的。。。
试验了下 手机拍摄的 opencv 获取的帧时间和软件获取是一样的,看来这类自动化场景最好不要用第三方录屏软件
嗯 导致这个问题根本原因还是软件录制的帧不稳定,每一帧的时长其实不恒定。但是有的商业软件搞定了这种情况,用 opencv 一直找不到解决方法,实在不行,视频源只能是外部拍摄了
请教下这个跟机器学习结合的话,是用的 sklearn 么
内置的话是的。如果要对 cutter 保存的图片进行图像分类,你也可以用其他你喜欢的(例如 keras)。
想了解下训练到后期,识别一个视频出结果需要多长时间。我试着跑了下,分析完一个视频也要半个钟,所以好奇训练好后会到什么程度

以前试过,把视频换成帧数然后图片比对,算响应时间,总会有点误差
good job, 那怎么判断是启动场景?
如果我手动采集图片进行分类之后拿去训练模型,需要对图片做预处理么?
不用,但是你手动采集的图片尺寸需要跟你的视频保持一致
可以参考:https://github.com/williamfzc/stagesepx/tree/master/example/train_and_predict
视频截取的图片对比和预制图片分辨率如果不一样,是可以比较的么
运行 “stagesepx one_step demo.mp4” 分析一个 20 秒的视频,3 个小时还没结束?
是最新版本吗?最新版本是 0.8.0
- 如果不是,可以用
pip install --upgrade stagesepx更新下再试试 - 如果是,方便把视频发我一下吗:fengzc@vip.qq.com
很好的开源项目
亲自测试了一下对稳定阶段的视频分析,误差确实在 100ms 以内,感觉很棒
感觉可以对简单的启动类响应速度进行测试,有时间试试
赞一个
请教大家,CropHook 配置了怎么不起作用啊?
传送门的例子打不开啊
可以的,不知道你指哪一个?
https://github.com/williamfzc/work_with_stagesepx
能讲一下判断参数的意思吗比如上方图里面的-1 0 1 2 是类似于高低电位的那种东西?
mark
有时间学习下
借楼请教下大佬,关于 APP 性能测试中的启动时间,录屏分帧时,一直对计时截止时间标准存在疑惑,还请帮忙指点,谢谢!!
1.如下图淘宝,可见这个界面控件已经加载出来,部分内容也加载出来,但是部分图片尚未显示出来,因为淘宝这类产品首页图片非常之多,加载耗时在所难免,如果计时到所有图片都加载出来,得出的启动时间会比较难看,所以想参考下,阿里计时确实是等待所有图片都加载完才叫启动结束吗,还是计时到控件 框架加载完毕,部分图片加载完毕,大致显示 ok 即可?
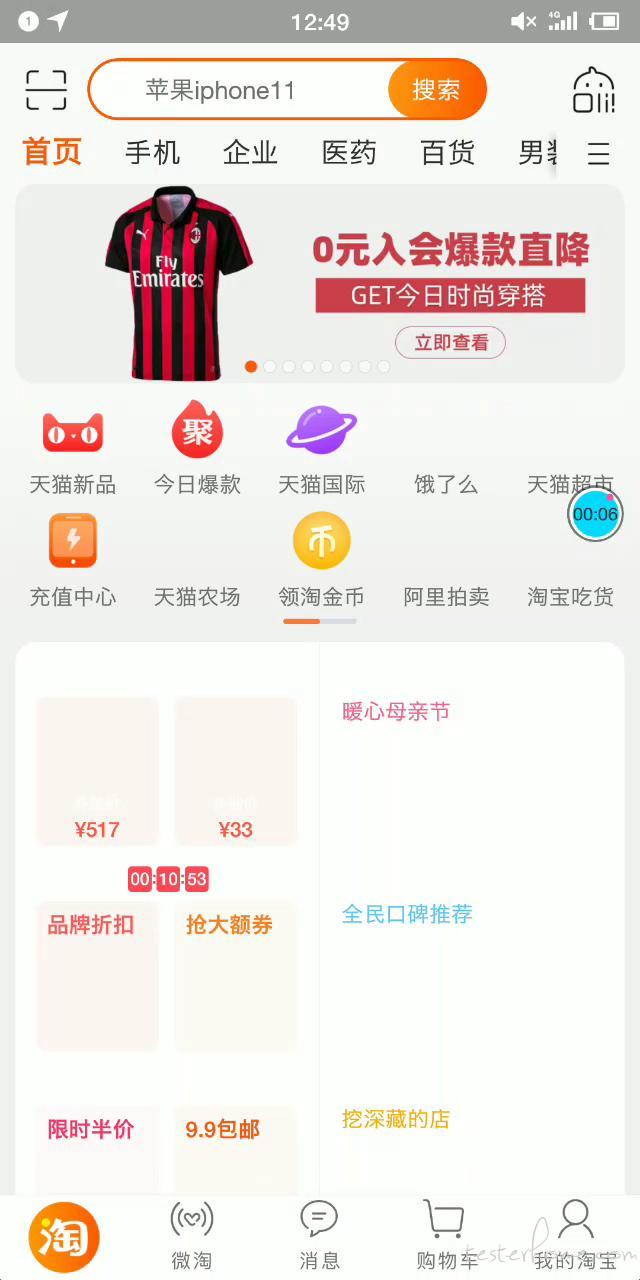
2.如下图 1 与 2,二者的不同的就是第一个群与第二群位置变换,原因是第一张图上为启动过程中加载完所有群,但是需求还有一个逻辑,就是东方时尚那个群符合某个特殊条件,在排序中优先于第二个群,这个特殊条件是从接口获取的,等于是加载完首页群,又获取到一个接口数据,进行再排序,东方时尚就有第二位调整到第一位,整个过程给人的体感是,未重新排序之前页面已经很完整了,或许一些用户认为启动已经完成,但是之后确实又有了一个变动,二者位置调换,所以想请教下,像这种加载完之后的基于接口的逻辑再处理要不要计入启动过程
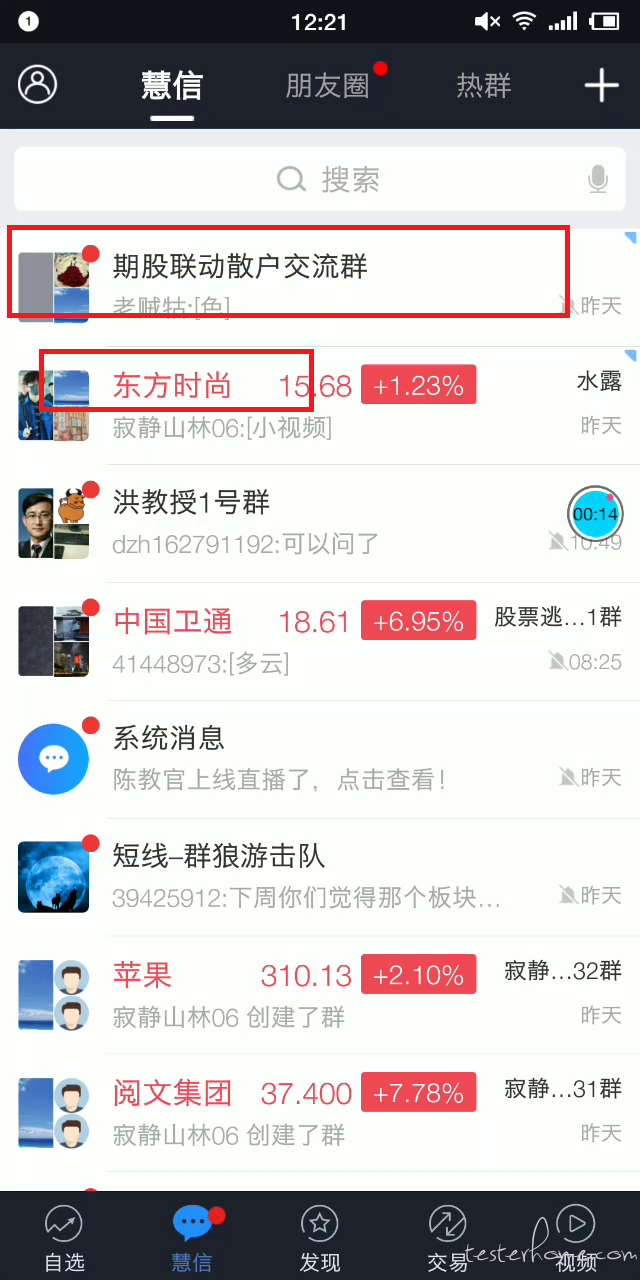
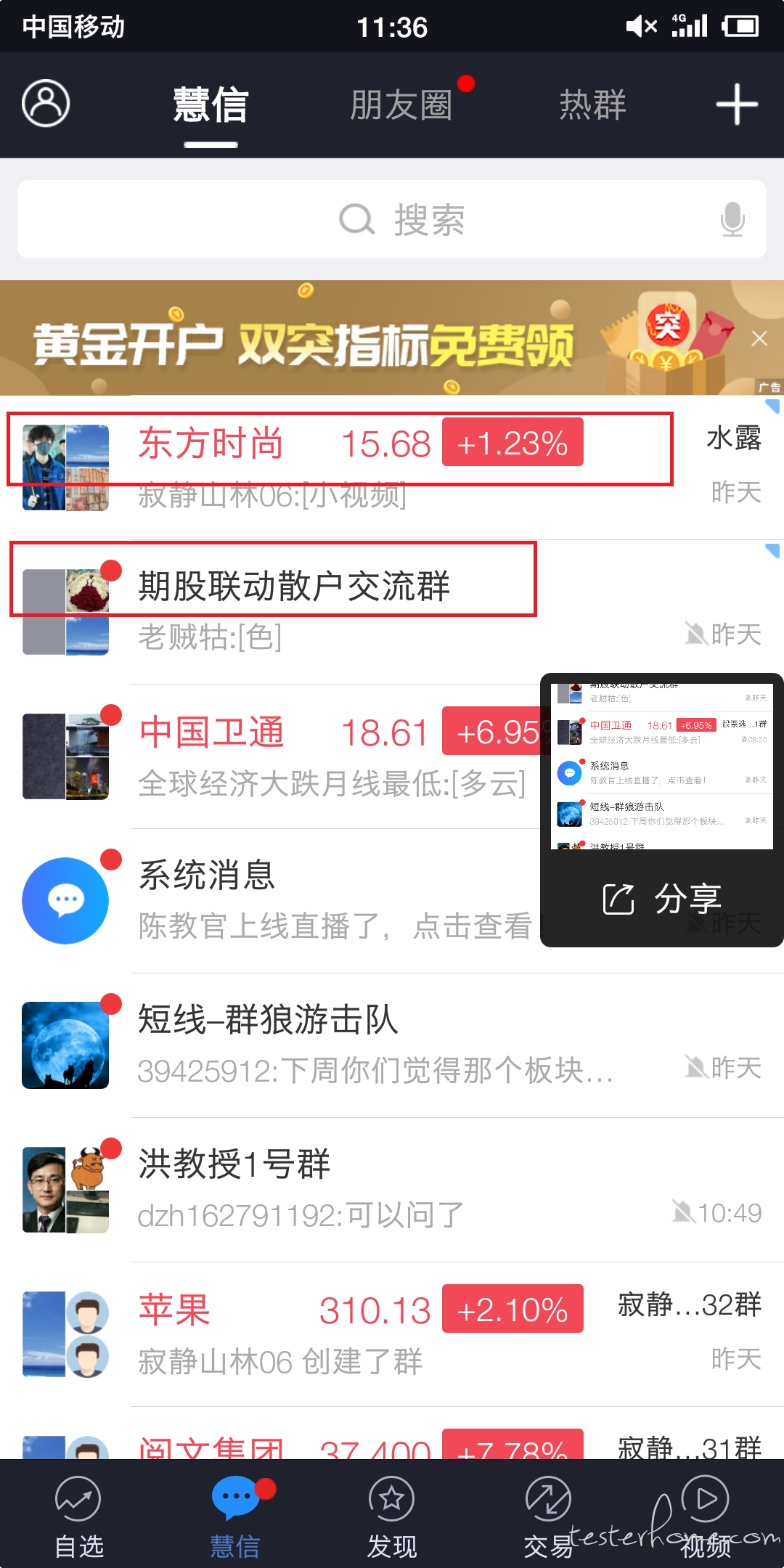
3.如下图,控件与图片,业务内容基本全部加载出来了,但是仍然要刷新,理由是智能推荐每次启动都会更新一批,然而这个更新的数据内容是在第一页的最底部,用户能看到的部分都没变,这种计时到'加载完'三个字消失,还是看到大部分页面内容没有变化,不用等 ‘加载完’ 消失呢,谢谢!!
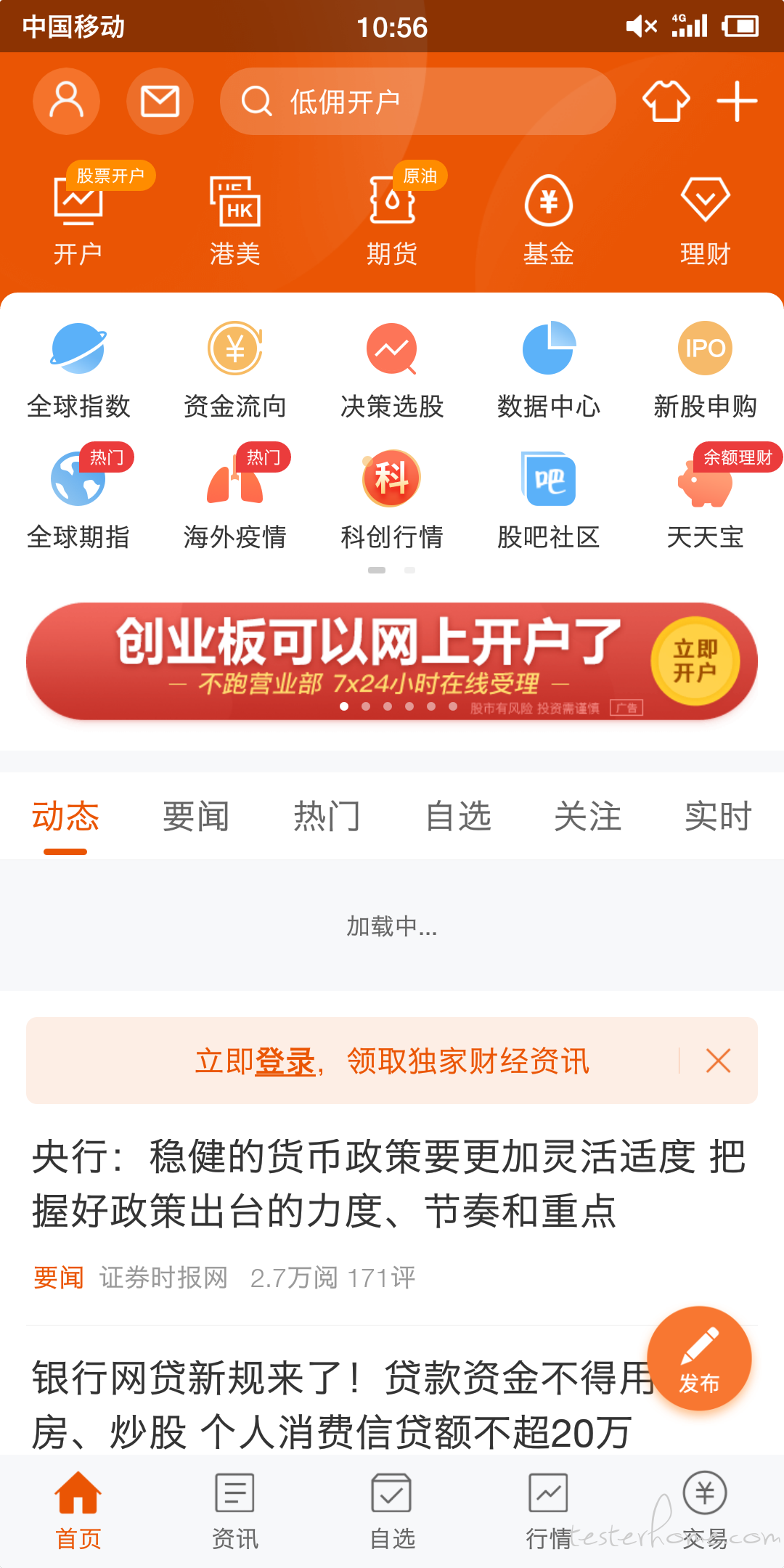
用 iOS 自动录屏录得视频,分析就报错了,不知道为啥,大佬求助!
pip install stagesepx 报错
python 版本:3.7/3.8
报错信息:
Using legacy 'setup.py install' for stagesepx, since package 'wheel' is not installed.
Building wheels for collected packages: h5py
Building wheel for h5py (PEP 517) ... error
ERROR: Command errored out with exit status 1:
command: 'c:\users\lin\appdata\local\programs\python\python37-32\python.exe' 'C:\Users\lin\AppData\Roaming\Python\Python37\site-packages\pip_vendor\pep517_in_process.py' build_wheel 'C:\Users\lin\AppData\Local\Temp\tmpcy6rz
b8h'
cwd: C:\Users\lin\AppData\Local\Temp\pip-install-hhhxxz50\h5py_4f4d169fc2ea41e3a46f8fb55a7cebcb
Complete output (71 lines):
running bdist_wheel
running build
running build_py
creating build
creating build\lib.win32-3.7
creating build\lib.win32-3.7\h5py
copying h5py\h5py_warnings.py -> build\lib.win32-3.7\h5py
copying h5py\ipy_completer.py -> build\lib.win32-3.7\h5py
copying h5py\version.py -> build\lib.win32-3.7\h5py
copying h5py_init.py -> build\lib.win32-3.7\h5py
creating build\lib.win32-3.7\h5py_hl
copying h5py_hl\attrs.py -> build\lib.win32-3.7\h5py_hl
copying h5py_hl\base.py -> build\lib.win32-3.7\h5py_hl
copying h5py_hl\compat.py -> build\lib.win32-3.7\h5py_hl
copying h5py_hl\dataset.py -> build\lib.win32-3.7\h5py_hl
copying h5py_hl\datatype.py -> build\lib.win32-3.7\h5py_hl
copying h5py_hl\dims.py -> build\lib.win32-3.7\h5py_hl
copying h5py_hl\files.py -> build\lib.win32-3.7\h5py_hl
copying h5py_hl\filters.py -> build\lib.win32-3.7\h5py_hl
copying h5py_hl\group.py -> build\lib.win32-3.7\h5py_hl
copying h5py_hl\selections.py -> build\lib.win32-3.7\h5py_hl
copying h5py_hl\selections2.py -> build\lib.win32-3.7\h5py_hl
copying h5py_hl\vds.py -> build\lib.win32-3.7\h5py_hl
copying h5py_hl__init.py -> build\lib.win32-3.7\h5py_hl
creating build\lib.win32-3.7\h5py\tests
copying h5py\tests\common.py -> build\lib.win32-3.7\h5py\tests
copying h5py\tests\conftest.py -> build\lib.win32-3.7\h5py\tests
copying h5py\tests\test_attribute_create.py -> build\lib.win32-3.7\h5py\tests
copying h5py\tests\test_attrs.py -> build\lib.win32-3.7\h5py\tests
copying h5py\tests\test_attrs_data.py -> build\lib.win32-3.7\h5py\tests
copying h5py\tests\test_base.py -> build\lib.win32-3.7\h5py\tests
copying h5py\tests\test_big_endian_file.py -> build\lib.win32-3.7\h5py\tests
copying h5py\tests\test_completions.py -> build\lib.win32-3.7\h5py\tests
copying h5py\tests\test_dataset.py -> build\lib.win32-3.7\h5py\tests
copying h5py\tests\test_dataset_getitem.py -> build\lib.win32-3.7\h5py\tests
copying h5py\tests\test_dataset_swmr.py -> build\lib.win32-3.7\h5py\tests
copying h5py\tests\test_datatype.py -> build\lib.win32-3.7\h5py\tests
copying h5py\tests\test_dimension_scales.py -> build\lib.win32-3.7\h5py\tests
copying h5py\tests\test_dims_dimensionproxy.py -> build\lib.win32-3.7\h5py\tests
copying h5py\tests\test_dtype.py -> build\lib.win32-3.7\h5py\tests
copying h5py\tests\test_errors.py -> build\lib.win32-3.7\h5py\tests
copying h5py\tests\test_file.py -> build\lib.win32-3.7\h5py\tests
copying h5py\tests\test_file2.py -> build\lib.win32-3.7\h5py\tests
copying h5py\tests\test_file_image.py -> build\lib.win32-3.7\h5py\tests
copying h5py\tests\test_filters.py -> build\lib.win32-3.7\h5py\tests
copying h5py\tests\test_group.py -> build\lib.win32-3.7\h5py\tests
copying h5py\tests\test_h5.py -> build\lib.win32-3.7\h5py\tests
copying h5py\tests\test_h5d_direct_chunk.py -> build\lib.win32-3.7\h5py\tests
copying h5py\tests\test_h5f.py -> build\lib.win32-3.7\h5py\tests
copying h5py\tests\test_h5o.py -> build\lib.win32-3.7\h5py\tests
copying h5py\tests\test_h5p.py -> build\lib.win32-3.7\h5py\tests
copying h5py\tests\test_h5pl.py -> build\lib.win32-3.7\h5py\tests
copying h5py\tests\test_h5t.py -> build\lib.win32-3.7\h5py\tests
copying h5py\tests\test_objects.py -> build\lib.win32-3.7\h5py\tests
copying h5py\tests\test_selections.py -> build\lib.win32-3.7\h5py\tests
copying h5py\tests\test_slicing.py -> build\lib.win32-3.7\h5py\tests
copying h5py\tests__init.py -> build\lib.win32-3.7\h5py\tests
creating build\lib.win32-3.7\h5py\tests\data_files
copying h5py\tests\data_files__init.py -> build\lib.win32-3.7\h5py\tests\data_files
creating build\lib.win32-3.7\h5py\tests\test_vds
copying h5py\tests\test_vds\test_highlevel_vds.py -> build\lib.win32-3.7\h5py\tests\test_vds
copying h5py\tests\test_vds\test_lowlevel_vds.py -> build\lib.win32-3.7\h5py\tests\test_vds
copying h5py\tests\test_vds\test_virtual_source.py -> build\lib.win32-3.7\h5py\tests\test_vds
copying h5py\tests\test_vds__init_.py -> build\lib.win32-3.7\h5py\tests\test_vds
copying h5py\tests\data_files\vlen_string_dset.h5 -> build\lib.win32-3.7\h5py\tests\data_files
copying h5py\tests\data_files\vlen_string_dset_utc.h5 -> build\lib.win32-3.7\h5py\tests\data_files
copying h5py\tests\data_files\vlen_string_s390x.h5 -> build\lib.win32-3.7\h5py\tests\data_files
running build_ext
Loading library to get build settings and version: hdf5.dll
error: Unable to load dependency HDF5, make sure HDF5 is installed properly
error: [WinError 126] 找不到指定的模块。
ERROR: Failed building wheel for h5py
Failed to build h5py
ERROR: Could not build wheels for h5py which use PEP 517 and cannot be installed directly
大佬,安装好库后运行报错:
--- End of logging error ---
--- Logging error in Loguru Handler #0 ---
Record was: {'elapsed': datetime.timedelta(seconds=29, microseconds=921314), 'exception': None, 'extra': {}, 'file': (name='video.py', path='C:\\Program Files (x86)\\testerq\\Python\\lib\\site-packages\\stagesepx\\video.py'), 'function': 'init', 'level': (name='DEBUG', no=10, icon='🐞'), 'line': 31, 'message': 'new a frame: 53(nan)', 'module': 'video', 'name': 'stagesepx.video', 'process': (id=10692, name='MainProcess'), 'thread': (id=11108, name='MainThread'), 'time': datetime(2024, 6, 17, 23, 5, 10, 108271, tzinfo=datetime.timezone(datetime.timedelta(seconds=28800), '?D1¨²¡À¨º¡Á?¨º¡À??'))}
Traceback (most recent call last):
File "C:\Program Files (x86)\testerq\Python\lib\site-packages\loguru\_handler.py", line 184, in emit
formatted = precomputed_format.format_map(formatter_record)
File "C:\Program Files (x86)\testerq\Python\lib\site-packages\loguru\_datetime.py", line 75, in __format__
"X": "%d" % timestamp,
ValueError: cannot convert float NaN to integer