自动化工具 让所有人都能用图像识别做 UI 自动化
前言
好久不见。眼熟我的朋友可能知道,我近期一直在做图像识别相关的一些内容,也陆陆续续写了一点分享:
承蒙大家厚爱,在收获加精的同时,也收获了很多朋友的反馈。根据这些反馈,最近我一直在思考的问题是,这项技术到底应该用什么形式落地才是最优解。
起因
这还要从 fitch 项目(详见基于图像识别的 UI 自动化解决方案)说起。
为了满足我个人的强迫症需求,整个项目采用了彻底的组件化设计,所有的组件都能够独自存在、独立应对各自负责的功能,或被其他项目直接使用。虽然最后完成的结果还算符合预期,但联调的过程非常漫长,工作量不小。然而,这个项目也仅仅满足了 android 端的需要,而 ios 以及后续更多平台因为一些其他原因,一开始并没有在我的计划内;除此之外,还有算法调优、设备兼容等一系列的问题需要解决。相比公司级的成熟开源项目(比如 airtest 吧)的生态与进度,我个人的时间与精力都非常有限,这未免让人感觉有点无力。
非常感谢 @codeskyblue 的 issue,让我重新想起了 findit 这个项目。这个时候我才开始发现,实际上这个东西才是图像识别框架的核心,也是最重要的部分,同时也是阻碍很多人接触与参与这个领域的门槛。而业务框架的形态到底应该是什么样,其实应该交给真正业务的使用者来设计,他们才是更了解也更清楚业务形态的人。在这之后,我重新对这个项目进行了重构与扩展,为它新增了大量的新特性,让它真正成为了一个独立项目,用于为更多开发者提供图像识别的服务。
findit 是什么
早期的 findit 是一个非常小的组件,主要用于支持 fitch 的图像识别功能。通过早期的 commit 记录可以发现,那个时候这个组件仅有 100+ 行代码,也只支持较简单的模板匹配功能。
经过重新设计,目前该工具将主要作为图像识别服务出现,用于在目标图像中寻找模板图片的位置。在当前版本,findit 已经能够以 本地形态或远程形态 出现,适应不同环境的需要,为不同的框架提供图像识别服务。
一个简单的例子
例如你有两张图片,分别是微信图标:

与包含微信图标的手机截图:

那么,你只需要短短几行代码:
import pprint
from findit import FindIt
fi = FindIt()
fi.load_template('wechat_logo', pic_path='pics/wechat_logo.png')
result = fi.find(
target_pic_name='screen',
target_pic_path='pics/screen.png',
)
pprint.pprint(result)
就可以得到:
{'data': { 'wechat_logo': {'FeatureEngine': (524.6688232421875, 364.54248046875),
'TemplateEngine': (505.5, 374.5)}},
'target_name': 'screen',
'target_path': 'pics/screen.png'}
通过上述数据可以知道,微信图标最可能出现的点位:
- Feature Matching 的计算结果是
(524, 364) - Template Matching 的计算结果是
(505, 374)
这一切 findit 都将替你完成。你只需要在你的框架里调用它。
进阶的例子可以参考 demo。
远程部署能力
为了后续更好的应用,findit 的理论形态应该是配置在服务器上。主要有两个问题:
- 图像识别效果更精确势必需要更高的算力。服务化之后,计算部分可以使用局域网内更高配置的机器来执行。
- 顺带解决大量模板图片的管理问题。

通过配置,findit-client 能够连接到本地或者远程的 findit-server,以适应不同的需求。换言之,你可以在其他设备上使用 client 直接调用远程的 findit,而本地无需 opencv 环境。这种做法使得你能够在更低配置的客户机(例如树莓派等)上使用 findit 服务。由于 client 的设计只依赖于 http 请求,你甚至可以使用你喜欢的任何语言来编写 client!
同样的,findit 提供了完善的 docker 与 docker-compose 支持,使得整套部署流程非常非常简单!
使用方法与部署可以参考这里
项目主页
https://github.com/williamfzc/findit
文档
这次的项目真的提供了认真的文档。
https://williamfzc.github.io/findit/#/
相关算法参考
findit 主要用到了 feature matching 与 template matching 。
后续
这个项目将是我的重点维护项目之一。
由于图片识别效果与源图片本身有一定的关联,可能对于个别图片会有问题,欢迎带上图片反馈给我以提高整体质量!
有问题与建议欢迎留言或者 issue 给我,或者你感兴趣的话,欢迎 PR 加入我们。
关键是名字起的好听
 可以,赢在起跑线
可以,赢在起跑线很不错啊!
谢谢大佬分享
鼓励开源,感谢楼主的奉献精神
看起来很赞!想问下有计划支持 java 的 client 吗?看起来 client 是可以不限语言的

如果 logo 不在 screen 里面,也会返回结果吗?
是会的,会返回可能性最高的点位。其实最好是打开 pro_mode :
{'data': {'album_logo': {'FeatureEngine': {'raw': [(258.70574951171875,
57.179443359375),
(284.8610534667969,
129.47080993652344),
(283.2962951660156,
114.9080810546875),
(282.82769775390625,
112.55213928222656),
(281.9783935546875,
112.19770050048828)],
'target_point': (282.70079549153644,
113.21930694580078)},
'TemplateEngine': {'raw': {'max_loc': (301.5, 99.0),
'max_val': 0.9999988079071045,
'min_loc': (108.5, 63.0),
'min_val': 0.8840280771255493},
'target_point': (301.5, 99.0),
'target_sim': 0.9999988079071045}},
......
'target_name': 'screen',
'target_path': 'pics/screen.png'}
会有非常具体的分析结果,可以根据需要去设计自己的逻辑。如,这里的 max_val 就是相似度,可以自己在客户端设定阈值以此判断是否存在该点。


这个 logo 在这个页面,匹配的相似度可以达到 0.98,真正有这个 logo 的时候,也找不到
-
第一个是这个东西跟 matchTemplate 的算法直接相关。为了兼容带有蒙版的模板匹配,所以默认的算法是
cv2.TM_CCORR_NORMED。而这个算法的相似度算出来是比较奇怪的,匹配到的话相似度大概会有 0.99+,而没有匹配到的相似度也不会很低,就像你看到的可能也会有 0.95+。
解决方案也很简单,可以把默认算法换掉:fi = FindIt( pro_mode=True, engine_template_cv_method_name='cv2.TM_CCOEFF_NORMED', )这种算法的表现就正常很多,基本符合人的直觉。但是不兼容蒙版匹配,所以比较纠结。
另一个可能是你的壁纸太过复杂造成了干扰。很多图像识别算法本质上是根据图像纹理来获取特征的,如果你的壁纸特征太过丰富是可能会影响结果的。一般我是会用纯色背景,不过目前来看比较常规的壁纸也是可以的,但是你这个显然太过复杂了。。
-
因为模板匹配与分辨率关联性比较强,所以在匹配时会将你的模板图片进行一定比例的缩放以此寻找最佳匹配点,而默认的缩放比例是 1 倍-3 倍(因为一般来说 icon 都会比较小,而截图分辨率是比较高的)。如果你的模板图片分辨率很高而你的目标图片分辨率低的话,这个 scale 就不是很适用了。我是比较建议用小一点的 icon 搭配大一点的目标图片来检测。如果你一定想要这样检测的话可以这样修改 scale 的值:
fi = FindIt( pro_mode=True, # 默认是1倍-3倍,该范围内10等分 # engine_template_scale=(1, 3, 10), # 这样是0.5倍-3倍,该范围内10等分,可以根据需要自己调节 # 当然,范围更大,颗粒度更细,就会更慢 engine_template_scale=(0.5, 3, 10), )
如果还存在问题,欢迎继续留言。

楼主,我试过这个项目,也想融入现在做的自动化框架(appium+python+unittest )中,但是我试了不存在图片是也是返回坐标参数,没办法判断是否存在图片吗?
我用你发的两个图试了下,貌似可以匹配到呢。。
一般来说默认缩放的 1-3 倍够用了,一般 icon 不会小到太离谱。如果场景很特别,可以根据实际自己算一下看看呢

在 0.4.6 版本之后,非 pro_mode 模式下也会返回相似度了:
{'data': {'wechat_logo': {'FeatureEngine': {'target_point': [524.6688232421875,
364.54248046875]},
'TemplateEngine': {'target_point': [505.5, 374.5],
'target_sim': 0.998754620552063}}},
'target_name': 'screen',
'target_path': 'pics/screen.png'}
或者你也可以开启 pro_mode 来获取更多信息:
fi = FindIt(pro_mode=True)
另外,如果要合入大型的项目其实还是推荐用 findit_client 来解耦:
请问一下楼主 我直接 copy 了实例代码 但是方法找不到
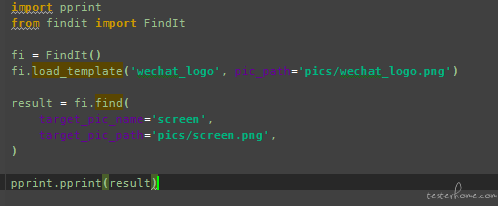
装了 model 还会报 这个错误
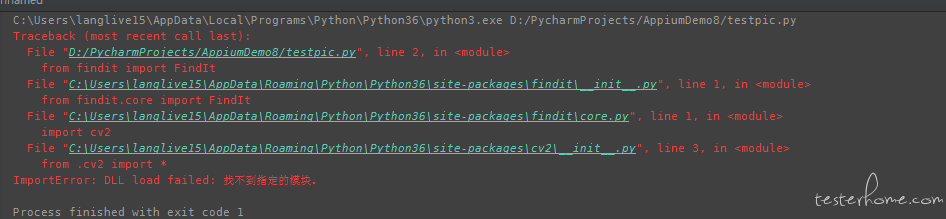
这个是 opencv-python 本身的安装问题,网上有一些解决方案。
https://blog.csdn.net/wuzhouqingcy/article/details/77509454
我还没有遇到过,你可以先按网上的方法试试看哈
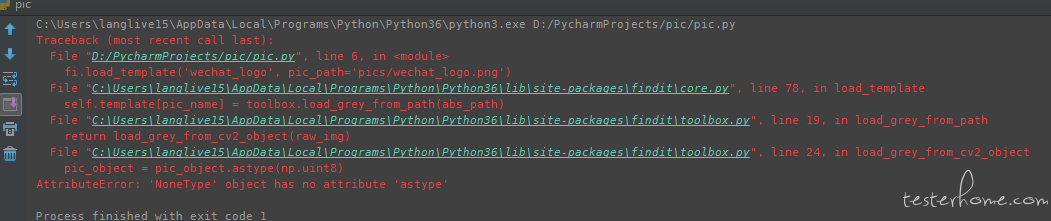
搞的我头大了
我下载了项目代码运行项目里的 demo.py
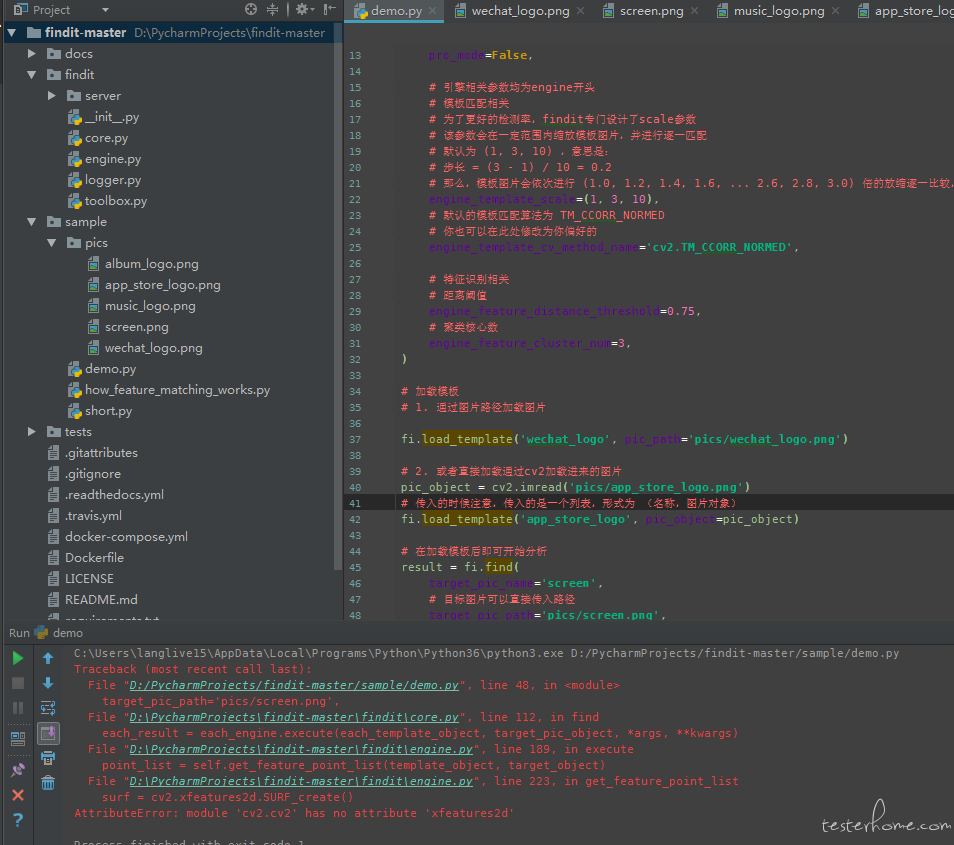
但是将 opencv-python 和 opencv-contrib-python 升级到了 4.1.0.25 会有什么影响吗
opencv-contrib-python 是有影响的,因为特征识别的 SIFT 与 SURF 算法都是有专利的,在新的版本中已经被移除掉了。
按默认版本来应该没什么问题啊,如果你不想用的话可以把特征识别关掉。模板匹配也够了:
fi = FindIt(engine=['template'])
恩 修改为 fi = FindIt(engine=['template']) 后尝试了一下 demo.py 有结果了。
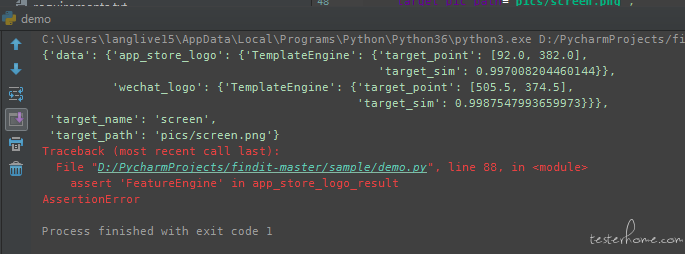
但是我自己写的例子就是跑不起来
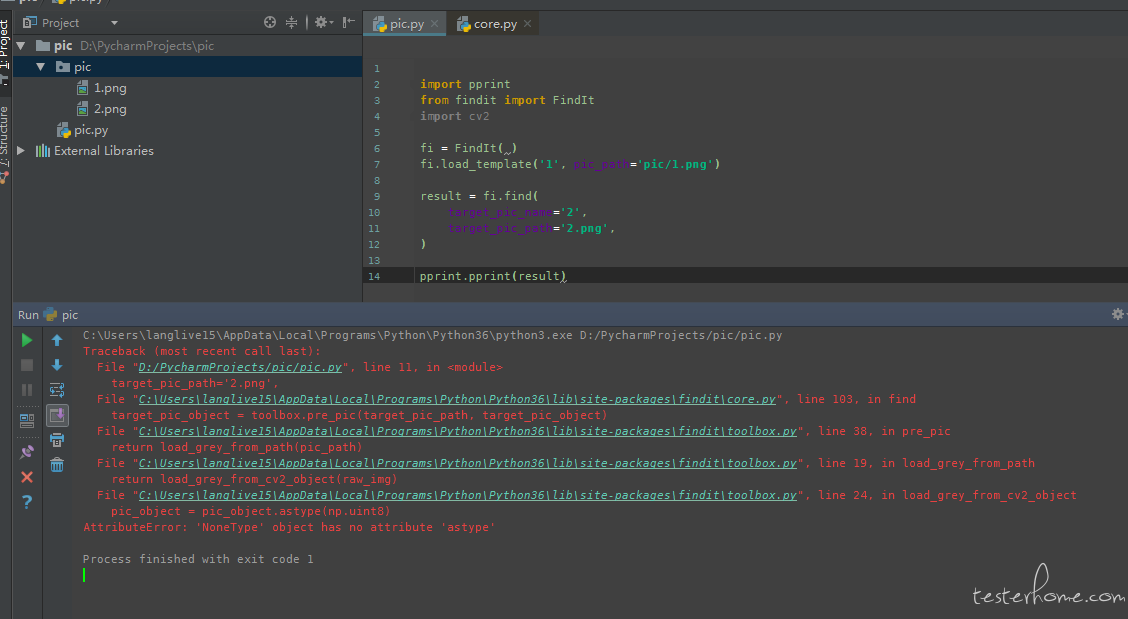
恩 楼主说的对 修改了一下 终于可以看到结果
有时候 我开了 log 发现
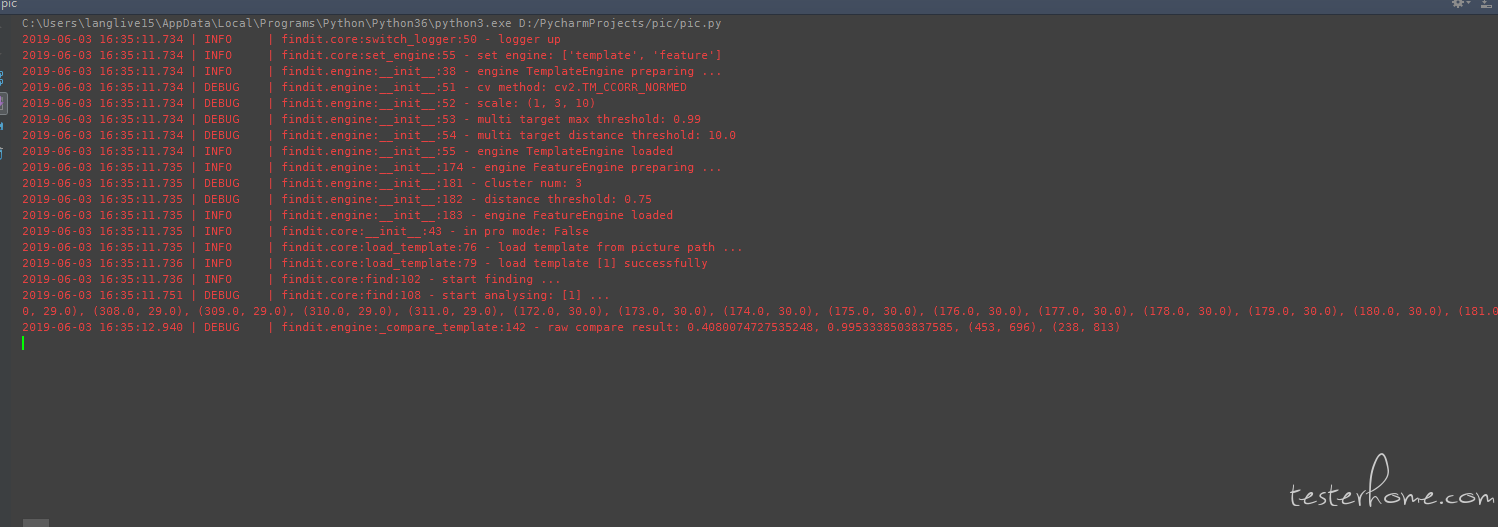
一直不出结果 是因为 template 的图 和 target 图像素差别太大了吗
特征匹配与模板匹配的优点与缺点很明显,优点易用性强,缺点鲁棒性弱,对于游戏与应用都一样,鲁棒性弱的功能价值并不大。推荐了解一下 SIFT(尺度不变特征变换算法)。如果是是应用在游戏上建议还是用 gameObject 的取件方式来做。
模板匹配做了很多适配用来提高鲁棒性,目前面对不同分辨率的识别效果并不差了。
你可以看看这个项目的特征匹配就是用的 SIFT/SURF 来做的,实际上效果不一定比优化后的模板匹配来得更好。
你说的 gameObject 取件需要引擎商配合或提供方法,而我们不可能要求所有引擎商都配合。
提供方法的成本很低啊,就是几个函数的事情,并提供一个 tcp 端口给你提供控件,你不仅可以通过控件执行业务操作,还可以判断它是否存在,这里有很多很多的开源方案可以执行,且是高效稳定的方式。游戏本身的动态粒子效果就算是模板匹配很难做更别说是执行各种行为以及任务了(当然这里看游戏内容以及特征...)。其次就是 SIFT/SURF 是特征提取的方式,所谓鲁棒性不是为了在某个系数下识别成功就算成功了,比如模板匹配中,设定 TM_CCOEFF 的标准来控制图形识别的准确性,但是缺牺牲了图像对比的正确性来执行操作行为,但当你真正做断言的时候,各种各样的粒子效果让你没办法做到完全匹配 ,这里图形识别很难做到两全其美
- 我不觉得很低哈,如果是内部项目做简单适配我觉得没毛病,作为公开项目要适配全引擎我觉得工作量太大。
- 当然做游戏的 UI 自动化当然以操作控件 Object 为上策哈,这个我不反对,也欢迎你把上面提到的开源方案分享出来学习下。但是业界会流行图像识别另一方面的原因是,我们一度怀疑这种 object 断言是否真正能够代表了界面的渲染效果。这是 airtest 一直很火热的原因。另外,这个项目并不只是针对游戏来做的,这里就不再过多地具体讨论游戏细节了。
- 特征提取方面后面会有改动,但是最近没有时间。
- 模板匹配方面并没有牺牲正确性啊,为什么会有这个想法
有一个思路,能否传一个训练过的模型作为 template,返回图片中符合模型的图标的位置
 很好的思路,之前有稍微考虑过但是在选型这一块没决定好,后面再看看吧~
很好的思路,之前有稍微考虑过但是在选型这一块没决定好,后面再看看吧~这个真的是很棒了
楼主,这个返回的坐标,应该是电脑上图片的坐标吧,是不是还要转换成手机坐标?
这个项目没有涉及电脑与手机的概念,只有目标图片与模板图片两种,不太明白你说的转换成手机坐标是指什么?
应用在手机上的话,可以参考这个项目:https://testerhome.com/opensource_projects/https---github-com-williamfzc-fitch
楼主,这个能运用在 web 上使用吗
新的框架么
楼主, response: {'msg': '', 'request': {'extras': {'engine_template_cv_method_name': 'cv2.TM_CCOEFF_NORMED', 'pro_mode': True, 'engine': ['template'], 'engine_template_scale': [0.5, 3, 10]}, 'target_pic_path': '/var/folders/8d/pgp4nng13zbfgtf5dzn5n1p40000gn/T/tmpuie2j1v3.png', 'template_name': 'wechat_logo.png'}, 'response': {'data': {'wechat_logo.png': {'TemplateEngine': {'conf': {'engine_template_cv_method_name': 'cv2.TM_CCOEFF_NORMED', 'engine_template_multi_target_distance_threshold': 10.0, 'engine_template_multi_target_max_threshold': 0.99, 'engine_template_scale': [0.5, 3, 10]}, 'raw': {'all': [[904.0, 1396.5]], 'max_loc': [908.0, 1395.5], 'max_val': 0.15389101207256317, 'min_loc': [499.0, 1259.5], 'min_val': -0.14501774311065674}, 'target_point': [908.0, 1395.5], 'target_sim': 0.15389101207256317}}}, 'target_name': 'DEFAULT_TARGET_NAME', 'target_path': '/var/folders/8d/pgp4nng13zbfgtf5dzn5n1p40000gn/T/tmptynkf2o5.png'}, 'status': 'OK'}
2019-10-21 15:34:55.457 | DEBUG | fitch.detector:detect:67 - Detect result: []
请问大神,ios 可以搞么
你好,我看代码里默认的方法 cv2.TM_CCOEFF_NORMED,但是最后真正使用的是 cv2.TM_CCORR_NORMED,这个和你使用的 mask 这个有什么关系吗?
请问大神,我已经按照 C/S 部署了,我自己写个简单的 Javaclient 用来调用,按照最简单的传参(目标文件和模版路径)调通了。但是我该怎么知道返回值每个字端的具体含义,还有就是 analyse 接口更多的传参含义。
其实 server 只是对库本身的一个封装与合理暴露,所有的参数还是只与库本身相关。
现在来说,接口传的参会被逐步按照层级被库本身解析,也就是说所有库能够接受的参数都可以直接当做接口参数传给他,这也是之所以参数名都起得非常全的原因。
返回值每个字段的具体含义的话,其实取决于你传入的参数。可以举个例子?
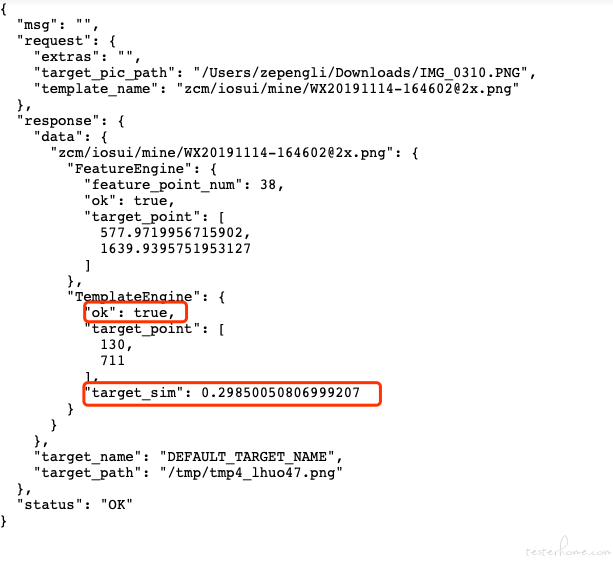
ok 指这个 engine 分析过程正常无报错;
target_sim 就是字面意思,目标相似度;
pytesseract.pytesseract.TesseractError: (1, "'tesseract' \u06b2\u2cbf\ue8ec\u04b2\u01ffе\u0133 \u013c") 跑 ocr 的时候报这个是什么问题了
tesserocr.image_to_text(image) 使用这个的时候中文好像识别不出来了
多半是没装好
属于这个库的问题,https://github.com/sirfz/tesserocr
单纯的过来点个赞
文档挂了
客户端可以在安卓上运行吗?服务器直接与在安卓上的客户端交互
什么初始化参数怎么都报错呢?
提示这种错误怎么处理呢
"""
template picture is larger than your target.
1. pick another template picture.
2. set engine_template_scale in init, see demo.py for details.
"""