-
开工第一天,好困,好累 at 2026年02月25日
真不容易
-
有在回家路上的吗 at 2026年02月12日
明天一大早就出发
-
独立开发,从 0 到 0.5 的开发和运营一个站点案例 at 2026年01月26日
方向没问题,路线也是对的,现在就是等待时机爆发。
-
年薪 50~60 万是什么样的? at 2026年01月12日
年薪 50-60w 并不高,你也可以达到
-
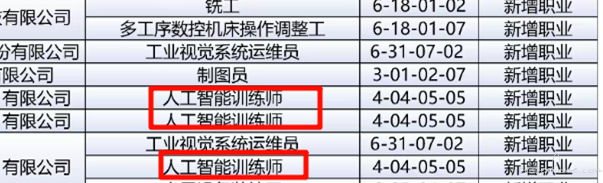
人工智能训练师的含精量 at 2025年12月31日
为啥是自费呢,不应该是企业出钱么?
苏州这边是企业统一申报该工种的技能考试,员工不需要出钱,直接是在企业内部进行考试,前提是所属企业要进行备案资质的申请,通过才可以。

-
我的第一次总结---2025 at 2025年12月03日
牛啊,30 万的粉丝,太强了
-
2025 年度总结 at 2025年12月01日
加油
-
临时邮箱项目挂了,压测复现问题,贴监控数据 at 2025年11月25日
厉害,思路很好
-
你觉得这是机会?还是压榨? at 2025年11月25日
我的看法是不接,做好本职工作,因为做的太多就会错的太多,绩效会很难看,而且,产品不是岗位本职工作,不产生实际的岗位绩效价值。所谓的成长,是一种自我安慰,大环境下,需要聚焦主体。明确拒绝,避免陷入 “既做不好产品,又耽误开发” 的双输局面。
P.S. 很多公司喜欢说 “这是锻炼”,但真正的锻炼是有保护、有反馈、有出口的,而不是把你扔进深水区还说 “游泳很简单”。 -
软测副业 at 2025年11月18日
是的,最起码得有点规模的,有知名度的企业。
-
软测副业 at 2025年11月10日
需要先单位推荐你去申报,盖公章。
-
工作笔记:AIRTEST 批量执行用例,并生成聚合报告 at 2025年11月04日
还真被我找到了,我百度网盘发给你。
通过网盘分享的文件:QCC_AIRTEST_PROJECTS.rar
链接: https://pan.baidu.com/s/1OzuWTyA5Rg22pQYy9o-FIg?pwd=nssf 提取码: nssf,你尽快下载,1 天有效期。 -
# 🚀 测试效能工具:一键扫码上传文件,让测试机与 PC 高效互通! at 2025年11月03日
python: 更新版
# smart_scan_upload.py —— 扫码上传助手 import os, socket, qrcode, cgi, urllib.parse, shutil, datetime from http.server import HTTPServer, BaseHTTPRequestHandler from pathlib import Path UPLOAD_DIR = "uploads" DOWNLOAD_DIR = "to_phone" os.makedirs(UPLOAD_DIR, exist_ok=True) os.makedirs(DOWNLOAD_DIR, exist_ok=True) class Handler(BaseHTTPRequestHandler): def log_message(self, *args): pass def send_html(self, html, status=200): self.send_response(status) self.send_header("Content-type", "text/html; charset=utf-8") self.end_headers() self.wfile.write(html.encode('utf-8')) def do_GET(self): if self.path == '/': self.send_html(''' <meta name="viewport" content="width=device-width"> <h2>🚀 扫码助手</h2> <a href="/upload" style="display:block;margin:15px;padding:12px;background:#007AFF;color:white;text-decoration:none;border-radius:8px;">📤 上传文件</a> <a href="/download" style="display:block;margin:15px;padding:12px;background:#34C759;color:white;text-decoration:none;border-radius:8px;">📥 下载PC文件</a> <button onclick="let m=prompt('输入文字消息');m&&fetch('/text',{method:'POST',headers:{'Content-Type':'application/x-www-form-urlencoded'},body:'c='+encodeURIComponent(m)}).then(()=>alert('✅ 已发送'))" style="margin:15px;padding:12px;background:#FF9500;color:white;border:none;border-radius:8px;">💬 发文字</button> ''') elif self.path == '/upload': self.send_html(f''' <meta name="viewport" content="width=device-width"> <h2>📤 上传文件</h2> <form method="post" enctype="multipart/form-data" action="/upload"> <input type="file" name="files" multiple required><br><br> <button type="submit" style="padding:10px 20px;background:#007AFF;color:white;border:none;border-radius:6px;">上传</button> </form> <a href="/">← 返回</a> ''') elif self.path == '/download': files = [f.name for f in Path(DOWNLOAD_DIR).iterdir() if f.is_file()] links = ''.join(f'<li><a href="/f/{urllib.parse.quote(f)}">{f}</a></li>' for f in sorted(files)) self.send_html(f''' <meta name="viewport" content="width=device-width"> <h2>📥 下载文件</h2> <p>把文件放进电脑的 <code>{DOWNLOAD_DIR}</code> 文件夹即可下载。</p> <ul>{links or "<li>暂无文件</li>"}</ul> <a href="/">← 返回</a> ''') elif self.path.startswith('/f/'): fname = urllib.parse.unquote(self.path[3:]) path = os.path.join(DOWNLOAD_DIR, os.path.basename(fname)) if os.path.exists(path): self.send_response(200) self.send_header("Content-Disposition", f'attachment; filename="{os.path.basename(path)}"') self.end_headers() with open(path, 'rb') as f: shutil.copyfileobj(f, self.wfile) else: self.send_error(404) else: self.send_error(404) def do_POST(self): if self.path == '/upload': form = cgi.FieldStorage(fp=self.rfile, headers=self.headers, environ={'REQUEST_METHOD': 'POST'}) files = form['files'] if not isinstance(files, list): files = [files] for f in files: if f.filename: name = os.path.basename(f.filename) base, ext = os.path.splitext(name) counter = 1 save_path = os.path.join(UPLOAD_DIR, name) while os.path.exists(save_path): save_path = os.path.join(UPLOAD_DIR, f"{base}_{counter}{ext}") counter += 1 with open(save_path, 'wb') as out: out.write(f.file.read()) print(f"📥 已保存: {save_path}") self.send_html('<h3 style="color:green">✅ 上传成功!</h3><script>setTimeout(()=>location="/",2000)</script>') elif self.path == '/text': length = int(self.headers.get('Content-Length', 0)) body = self.rfile.read(length).decode() msg = urllib.parse.parse_qs(body).get('c', [''])[0] if msg.strip(): with open(os.path.join(UPLOAD_DIR, "messages.txt"), "a", encoding="utf-8") as log: log.write(f"[{datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')}] {msg}\n") print(f"💬 收到文字: {msg}") self.send_html('<h3>✅ 文字已接收!</h3>') else: self.send_error(400) def get_ip(): try: s = socket.socket(socket.AF_INET, socket.SOCK_DGRAM) s.connect(("8.8.8.8", 80)) ip = s.getsockname()[0] s.close() return ip except: return "127.0.0.1" if __name__ == "__main__": import sys port = 8081 ip = get_ip() url = f"http://{ip}:{port}" print("🚀 扫码上传助手已启动!") print(f"📁 文件保存在当前目录的 'uploads' 文件夹") print(f"📤 想让手机下载PC文件?把文件放进 'to_phone' 文件夹\n") qr = qrcode.QRCode(); qr.add_data(url); qr.print_ascii(invert=True) print(f"\n🌐 手机扫码地址: {url}\n") print("⏳ 等待上传...(按 Ctrl+C 停止)\n") HTTPServer(('', port), Handler).serve_forever() -
工作笔记:AIRTEST 批量执行用例,并生成聚合报告 at 2025年10月29日
已经好久不用了,等以后工作上需要我再单独写吧。
-
软测副业 at 2025年10月20日
我说一个副业,做政府项目评审。
正常去评审一个政府项目,是半天时间,劳务费是 500 块钱,如果是稍微复杂的大型的项目,需要评审一天,劳务费 1000 快。
如何做:进入政府专家库,成为评审专家,系统会自动抽取,抽到你就可以去参加评审了。 -
工作笔记:XMind to JIRA Converter at 2025年09月25日
不一样,经过我的逻辑处理,类似用 excel 写测试用例那样的形式
-
学习笔记:Windows10 系统部署 Sonic 云真机平台 at 2025年08月19日
-
搭建一个简易 Mock Server 服务 at 2025年08月18日
感谢你的建议!Flask 确实是一个非常优秀的 Web 框架,用它来构建有具体业务逻辑的 API 非常方便快捷。
不过,我们的具体需求场景略有不同。我们主要是需要一个 “挡板” 服务(Mock Server),它的核心作用是被动接收来自外部系统持续推送的各种数据,并能够记录和展示这些接收到的信息,而不是提供预设好的、固定的接口响应。这个服务本身不包含任何特定的具体业务逻辑,只是作为一个数据接收器和日志记录器。
-
大龄裸辞一年后在纽村继续当牛马 at 2025年07月07日
执行力太强了
-
信息系统项目管理师过了 at 2025年06月27日
恭喜恭喜,我还没考
-
已删除 at 2025年04月09日
如果你对这些问题感到没有思路,这很正常,尤其是在面对算法问题或者编程问题时。这些问题需要一定的逻辑思维和对编程语言的熟悉度。以下是一些可能的原因和建议,希望能帮助你更好地理解和解决这些问题:
1. 基础知识不够扎实
- 问题:如果你对编程语言的基本语法、数据结构(如数组、列表、集合等)或者常见算法(如排序、查找等)不够熟悉,可能会感到无从下手。
-
建议:
- 复习基础知识:花时间复习编程语言的基本语法和常用数据结构。例如,Python 的列表操作、集合的特性等。
- 学习常见算法:了解一些常见的算法,如排序算法(快速排序、冒泡排序等)、查找算法(二分查找等)。
2. 缺乏解题思路
- 问题:面对问题时,不知道从哪里开始,或者不知道如何将问题分解成更小的部分。
-
建议:
- 分解问题:将问题分解成更小的子问题。例如,对于 “最长公共前缀” 问题,可以先考虑如何比较两个字符串的公共前缀,然后再扩展到多个字符串。
- 逐步思考:不要急于写出完整的代码,先在纸上或脑海中逐步思考每一步的逻辑。例如,对于 “和为 100 的数字对” 问题,可以先思考如何找到一个数字的补数,然后再考虑如何避免重复计算。
- 多做练习:通过大量的练习来积累解题思路。可以从简单的题目开始,逐步提高难度。
3. 缺乏信心
- 问题:有时候,缺乏信心会导致你在面对问题时感到无从下手。
-
建议:
- 从小问题入手:先解决一些简单的、类似的小问题,逐步建立信心。
- 不要害怕犯错:犯错是学习过程中的一部分。即使你的第一种方法不正确,也不要气馁,尝试另一种方法。
4. 缺乏实践
- 问题:理论知识和实际操作之间存在差距。如果你没有足够的实践,可能会感到难以将理论应用到实际问题中。
-
建议:
- 多写代码:通过实际编写代码来加深对问题的理解。可以从简单的代码片段开始,逐步扩展到完整的程序。
- 参加编程竞赛或练习平台:例如 LeetCode、Codeforces 等平台,提供大量不同难度的编程题目,可以帮助你提高解题能力。
5. 缺乏系统的学习方法
- 问题:如果没有一个系统的学习方法,可能会感到学习效率低下,难以掌握知识。
-
建议:
- 制定学习计划:根据自己的时间安排,制定一个合理的学习计划,逐步学习基础知识和解题技巧。
- 总结和回顾:在学习过程中,及时总结和回顾所学的知识和解题方法,避免遗忘。
具体问题的逐步思考方法
问题 1:最长公共前缀
- 理解问题:你需要找到一个字符串数组中所有字符串的最长公共前缀。
-
分解问题:
- 先考虑如何找到两个字符串的公共前缀。
- 再考虑如何将这个方法扩展到多个字符串。
-
逐步实现:
- 从第一个字符串开始,逐个字符比较,直到找到一个不匹配的字符。
- 将这个公共前缀与下一个字符串进行比较,重复上述步骤。
- 如果在某个步骤中公共前缀为空,则直接返回空字符串。
问题 2:和为 100 的数字对
- 理解问题:你需要找到数组中所有和为 100 的数字对。
-
分解问题:
- 先考虑如何找到一个数字的补数(即
target_sum - num)。 - 再考虑如何避免重复计算。
- 先考虑如何找到一个数字的补数(即
-
逐步实现:
- 使用一个集合来存储已经遍历过的数字。
- 对于每个数字,检查它的补数是否在集合中。
- 如果在集合中,则找到一个符合条件的数字对。
问题 3:不重复的三位数
- 理解问题:你需要用给定的数字组成所有可能的互不相同的三位数。
-
分解问题:
- 先考虑如何生成所有可能的三位数。
- 再考虑如何避免重复。
-
逐步实现:
- 使用排列的方法生成所有可能的三位数。
- 将生成的三位数存储到一个集合中,自动去重。
总结
- 基础知识:复习编程语言和数据结构。
- 解题思路:分解问题,逐步思考。
- 实践:多写代码,多做练习。
- 信心:从小问题入手,不要害怕犯错。
- 系统学习:制定学习计划,总结和回顾。
-
已删除 at 2025年04月09日
以下是对这三个问题的解答:
问题 1:最长公共前缀
def longest_common_prefix(strs): if not strs: return "" # 按照字典序对字符串数组进行排序 strs.sort() # 只需比较第一个字符串和最后一个字符串的公共前缀 first_str = strs[0] last_str = strs[-1] common_prefix = [] for i in range(min(len(first_str), len(last_str))): if first_str[i] == last_str[i]: common_prefix.append(first_str[i]) else: break return "".join(common_prefix) # 测试示例 strs = ["flower", "flow", "flight"] print(longest_common_prefix(strs)) # 输出:fl问题 2:找出和为 100 的数字对
def count_pairs_with_sum(numbers, target_sum): count = 0 seen = set() for num in numbers: complement = target_sum - num if complement in seen: count += 1 seen.add(num) return count # 测试示例 numbers = [1, 15, 35, 55, 65, 85, 99] target_sum = 100 print(count_pairs_with_sum(numbers, target_sum)) # 输出:2问题 3:不重复的三位数
import itertools def count_unique_three_digit_numbers(digits): # 使用排列生成所有可能的三位数 permutations = itertools.permutations(digits, 3) unique_numbers = set() for perm in permutations: # 将排列的数字拼接成三位数 number = int("".join(map(str, perm))) unique_numbers.add(number) return len(unique_numbers) # 测试示例 digits = [1, 8, 0, 3] print(count_unique_three_digit_numbers(digits)) # 输出:18 -
一个有意思的小事 at 2025年04月09日
开眼界了
-
TesterHome「我的 2024 年终总结」有奖征文活动 at 2025年03月24日
以下是本次有奖征文活动的帖子列表,按照符合征文格式要求和不符合征文格式要求两类进行,点赞数降序排列,前三名已用加粗突出显示。
符合征文格式要求的全部帖子列表
前三名的作者 :@Miangliang2610 @jideluo @varqiao
不符合征文格式要求,但是点赞数较多的帖子
前三名的作者 :@ShaoNianyr @kangaroo @JHY
点赞数 帖子链接 25 https://testerhome.com/topics/41210 9 https://testerhome.com/topics/41259 4 https://testerhome.com/topics/41415 -
DeepSeek R1 模型本地化部署 + 个人知识库搭建与使用 at 2025年02月24日
应该差不多的,你可以网上看看其他人写的,现在应该有很多了。