-
当了 3 年全职妈妈现在还机会回到职场吗? at 2025年02月11日
我们公司前段时间,刚招了一个之前自己独立创业开测试培训公司的人,所以不要担心,都有可能
-
可上传、下载、预览的 HTTP 文件服务器 ServeFS at 2025年02月11日
点赞,执行力真强

有什么办法不让服务器扫描我这么多文件夹吗?如果 HOME 里面默认啥都没有就好了。
-
可上传、下载、预览的 HTTP 文件服务器 ServeFS at 2025年02月10日
第四点我解释下,我在自己本机部署了,然后发现文件服务器上面把我当前 C 盘下的所有文件夹和文件都展示出来了。我是工作电脑,只有一个 C 盘,所以想了解下,如何让文件服务器不展示当前 C 盘的所有目录信息,比如部署后,希望的结果是,打开文件服务器,应该里面啥都没有,是一个空的目录这种。
-
DeepSeek R1 模型本地化部署 + 个人知识库搭建与使用 at 2025年02月10日
网络不稳定,多试试几次
-
可上传、下载、预览的 HTTP 文件服务器 ServeFS at 2025年02月10日
我正好有个需求要实现:我想部署在公司内部,但是提供给非本公司的外部同事(下游客户和第三方供应商)访问并下载文件进行打印。
有几个问题请教:
1、上传的文件都是存在公司内部的局域网的吗?
2、如果要进行外部客户跨域访问,岂不是要搞一个外部云服务?
3、外部客户只能查看和下载文件,不可以进行删除,现在是否支持啊?
4、我刚试了下,发现服务器上展示了我本机所有的文件夹及文件,能否仅展示空数据呢?并且只能是我自己上传的文件才会展示出来? -
DeepSeek R1 模型本地化部署 + 个人知识库搭建与使用 at 2025年02月06日
随时随地想用就用,也没有个人隐私暴露风险。
-
DeepSeek R1 模型本地化部署 + 个人知识库搭建与使用 at 2025年02月03日
我也来试试,让它给我搞个小工具
-
测试 10 年了 at 2025年01月17日
深圳两套房,厉害了,还没房贷
-
TesterHome「我的 2024 年终总结」有奖征文活动 at 2025年01月02日
需要发在社区上才行
-
null at 2024年12月25日
目前是小电驴通勤,不闯红灯正常行驶的话,单程是 30-40 分钟;闯红灯 40 码,单程大概 20 分钟左右。
周一至周五,不打卡
上午
8:30-11:30
中午
11:30-13:00
下午
13:00-17:00 -
我的 2024 年终总结 at 2024年12月24日
确实不容易,共勉
-
2024 年,存到钱了吗? at 2024年12月24日
人艰不拆
-
「我的 2024 年终总结」 at 2024年12月24日

-
请问选哪个车位比较好 at 2024年12月23日
根据你提供的平面图,以下是一些建议的车位:
L019:靠近入口,方便进出。
L020:靠近电梯,方便上下楼。
L021:同样靠近电梯,且空间较大。
L022:位于边缘,空间较大。
L023:靠近电梯,方便进出。
L024:位于边缘,空间较大。
L025:靠近电梯,方便进出。
L026:位于边缘,空间较大。
L027:靠近电梯,方便进出。基于你提供的信息和一般选择车位的考虑因素,可以考虑以下几个因素:
便利性:靠近电梯或楼梯,方便进出。
安全性:避免靠近柱子或墙面,减少刮擦风险。
空间:选择空间较大的车位,便于停车和开门。基于这些因素,我推荐选择 L020 车位。这个车位靠近电梯,对于携带物品上下楼会非常方便。同时,它位于边缘,空间相对较大,便于停车和开门。此外,它的视野也较为开阔,可以增加安全性。
-
学习笔记:Windows10 系统部署 Sonic 云真机平台 at 2024年12月11日
@Eason 同事反映,在自研 APP 的账号登录过程中,当远程操作手机,进入输入密码的页面,会存在手机黑屏问题,但是手机本身是正常展示的,这个问题是否有办法解决?agent 我升级到 2.7.2 了,也没有解决。
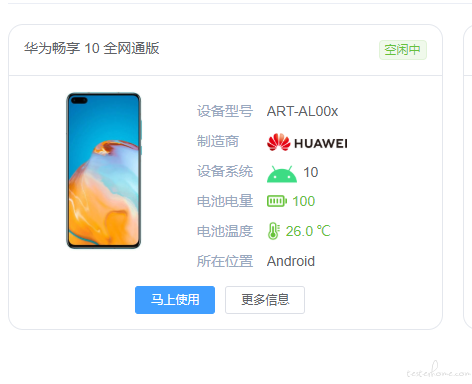
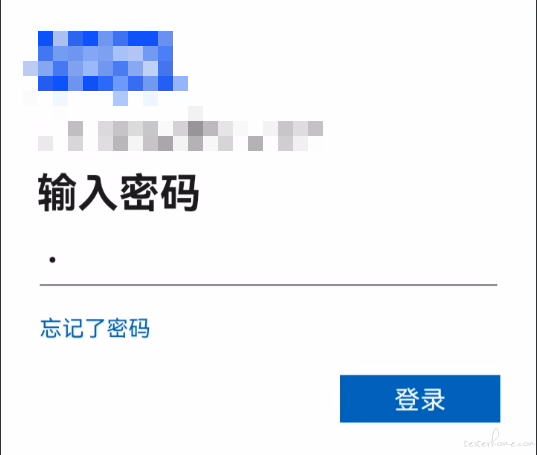
点击输入框,立马黑屏

-
图个乐子,瞎聊 at 2024年11月14日
个人觉得挺不错的
-
好久没面试了,整理并分享一下今天的面试题,明天再接再励。 at 2024年11月14日
-
正则表达式中,什么是贪婪匹配、什么是非贪婪匹配。
- 贪婪匹配:在正则表达式中,默认情况下,量词(如
*、+、?)会尽可能多地匹配字符,这称为贪婪匹配。 - 非贪婪匹配:通过在量词后面加上
?,可以使量词变为非贪婪匹配,即尽可能少地匹配字符。
- 贪婪匹配:在正则表达式中,默认情况下,量词(如
-
示例代码:
import re # 贪婪匹配 greedy_match = re.findall(r'\d+', '123abc456def789') print(greedy_match) # 输出 ['123456789'] # 非贪婪匹配 non_greedy_match = re.findall(r'\d+?', '123abc456def789') print(non_greedy_match) # 输出 ['123', '456', '789']
-
正则表达式中,search() 和 match() 的区别。
-
search():在字符串中搜索正则表达式的第一次出现,并返回一个匹配对象。如果没有找到匹配,则返回None。 -
match():仅从字符串的开始位置匹配正则表达式,如果开始位置没有匹配,则返回None。
-
-
示例代码:
import re # search() 示例 search_result = re.search(r'foo', 'bar foo baz') print(search_result.group()) # 输出 'foo' # match() 示例 match_result = re.match(r'foo', 'bar foo baz') print(match_result) # 输出 None
-
介绍一下 udp 和 tcp 协议。
- UDP(用户数据报协议):无连接的协议,提供快速但不可靠的数据传输,适用于对实时性要求高的应用,如视频会议和在线游戏。
- TCP(传输控制协议):面向连接的协议,提供可靠的数据传输服务,确保数据按顺序、无误地到达目的地,适用于需要可靠传输的应用,如网页浏览和文件传输。
-
get 和 post 的根本区别。(划重点:根本)
- GET:用于请求数据,通常用于获取服务器上的资源,数据附在 URL 后面,对数据长度有限制,不安全(因为数据在 URL 中可见),且可被缓存。
- POST:用于向服务器提交数据,数据包含在请求体中,对数据长度没有限制,相对安全(数据不在 URL 中),且不会被缓存。
-
介绍一下自动化实现的步骤。
- 需求分析:明确自动化测试的目标和范围。
- 测试计划:制定测试策略和计划。
- 环境搭建:准备测试环境和所需的工具。
- 脚本开发:编写自动化测试脚本。
- 脚本执行:运行自动化脚本,执行测试。
- 结果验证:检查测试结果是否符合预期。
- 报告和维护:生成测试报告,并对脚本进行维护和更新。
-
UI 自动化过程中用到哪些定位元素的方法。
- ID 定位
- Name 定位
- Class Name 定位
- Tag Name 定位
- XPath 定位
- CSS Selector 定位
- Link Text 定位
- Partial Link Text 定位
-
UI 自动化中,用到哪些等待方式。
- 显式等待(Explicit Wait):指定等待某个条件成立后再继续执行。
- 隐式等待(Implicit Wait):设置一个超时时间,让 WebDriver 等待某个条件成立。
- 睡眠等待(Sleep):让程序暂停执行一定时间。
-
示例代码(使用 Selenium):
from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC driver = webdriver.Chrome() driver.get("http://example.com") try: element = WebDriverWait(driver, 10).until( EC.presence_of_element_located((By.ID, "myDynamicElement")) ) finally: driver.quit()
- 用 python 操作 excel。
-
使用
openpyxl库操作 Excel 示例代码:from openpyxl import Workbook # 创建一个新的Excel工作簿 wb = Workbook() # 选择默认的工作表 ws = wb.active # 给工作表命名 ws.title = "Sample Sheet" # 写入数据 ws.append(["ID", "Name", "Score"]) ws.append([1, "John", 85]) ws.append([2, "Doe", 90]) # 保存工作簿到文件 wb.save("sample.xlsx")
-
session cookie、token、的区别。
- Session Cookie:服务器生成的唯一识别码,存储在用户的浏览器中,用于识别用户状态。
- Token:一种令牌,通常在用户登录后由服务器生成,用于验证用户身份,可以存储在客户端或服务端。
-
介绍一下自己的优势。
- 这部分是个人自我介绍,可以根据您的个人特点和优势来回答。
判断 ipV4 的合法性。(代码实操)
- 示例代码:
def is_valid_ipv4(ip): # 将输入的IP地址字符串按照点`.`分割成四部分 parts = ip.split(".") # 检查分割后的结果是否正好有四部分,因为IPv4地址必须有四组数字 if len(parts) != 4: return False # 遍历这四部分 for part in parts: # 检查每部分是否都是数字 if not part.isdigit(): return False # 将每部分转换为整数,并检查是否在0到255的范围内 if not 0 <= int(part) <= 255: return False # 如果所有检查都通过,说明IP地址是有效的 return True接下来是两个测试用例:
print(is_valid_ipv4("192.168.1.1")):这个测试用例检查字符串"192.168.1.1"是否是一个有效的 IPv4 地址。每组数字都在 0 到 255 之间,所以这个函数应该返回True。print(is_valid_ipv4("256.100.50.25")):这个测试用例检查字符串"256.100.50.25"是否是一个有效的 IPv4 地址。第一组数字256超出了 0 到 255 的范围,所以这个函数应该返回False。
这个函数通过简单的字符串操作和条件检查来验证 IPv4 地址的有效性,但它不会处理一些边缘情况,比如前导零(例如
"01.0.0.0")或者空字符串(例如".1.2.3")。对于更健壮的 IPv4 地址验证,可能需要更复杂的正则表达式或其他方法。 -
正则表达式中,什么是贪婪匹配、什么是非贪婪匹配。
-
点击登录后弹出窗口提示,元素找不到 no such element,alert 点确定也不行 no such alert at 2024年11月11日
你用这个浏览器插件试试看,edge 就有
-
在这个平台看到过很多大佬的帖子,感受颇深,心里有一个疑问,盼大佬们回复 at 2024年11月11日
你只要不主动走就行,他开了你,就要给赔偿。你做好你份内的事情,其他不要瞎操心。
-
啃爹的滴滴 - 出租车司机 at 2024年11月04日
笑死我了,哈哈哈
-
测试软考中级有必要考吗 at 2024年10月28日
个人觉得有必要,我一直想考信息系统项目管理师,一直都没动起来,惰性。
-
潜水王,总结一下我 30+ 的规划。 at 2024年10月28日
可以考虑去传统制造业试试机会
-
从「百家语录」提取模型 - 指令监督微调数据集 at 2024年10月17日
图全挂了
-
测试最终的归宿是什么? at 2024年08月21日
就去参加所在街道或者当地政府授权的培训机构开设的课程,然后考试通过以后拿到技能等级证书。
-
测试最终的归宿是什么? at 2024年08月21日
拓展一下学习边界,我的意思是说,在做好软件测试的本职工作的前提和基础之上,去主动学习跨行业的技能知识,比如我先后去考了电子商务师,互联网营销师,家庭收纳师等技能等级证书,最起码以后能有个后路,不至于一直在互联网圈子里内卷。