💡
基于古代哲学网络电子书,将语录转为:孔子角色是 GPT,其他人是人类的对话数据集
方案调研
数据源

使用 LLM 进行转换
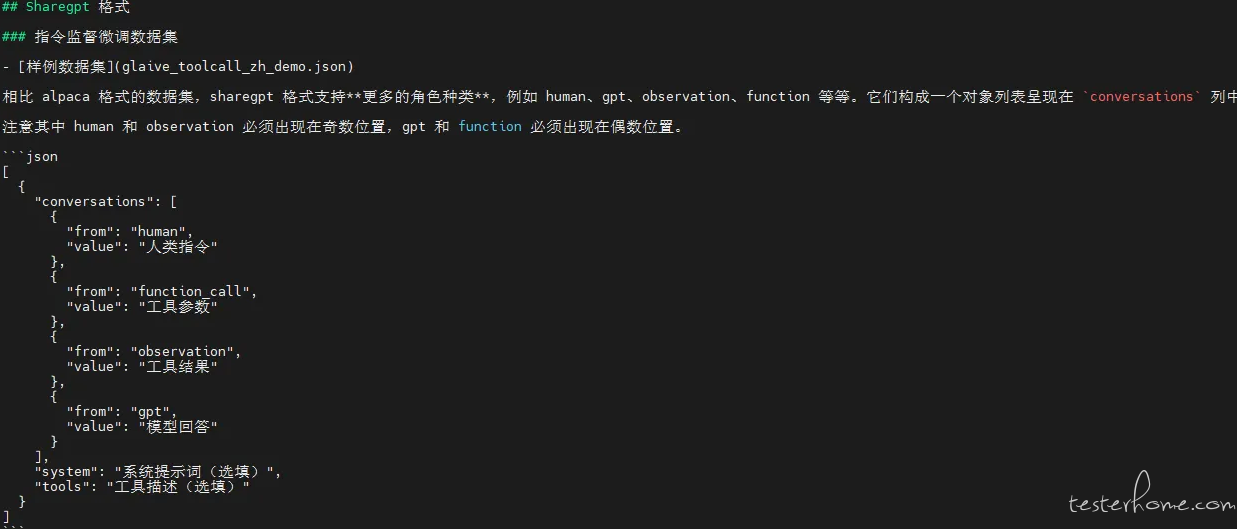
参考这个数据集例子,最终生成的效果如下:

System 提示词
你是一个语言模型助手,需要将输入的内容转换为孔子(GPT)与其他人(human)之间的对话。具体要求如下:
1. human:使用现代汉语表达,并与孔子互动,提出问题,语言多样。
2. gpt:使用古文原文加上现代汉语解释。(gpt即孔子,无需说“子曰”或“孔子说”)
3. 对话简洁明了,并附带现代汉语解释。
请将给定的对话转换为多个`conversations`对象,每个`conversations`对象包含一个`human`和一个`gpt`的对话。具体参考结构如下:
```json
[
{
"conversations": [
{
"from": "human",
"value": "老师,您说过‘为政以德’,这句话是什么意思呢?"
},
{
"from": "gpt",
"value": "为政以德,譬如北辰,居其所而众星共之。\n(大白话解释:以德行来治理国家,就像北极星一样,它固定在自己的位置上,其他的星星都会围绕着它。)"
}
]
},
{
"conversations": [
{
"from": "human",
"value": "老师,《诗经》的核心思想是什么?"
},
{
"from": "gpt",
"value": "诗三百,一言以蔽之,曰‘思无邪’。\n(大白话解释:《诗经》三百篇,可以用一句话概括,那就是‘思想纯正’。)"
}
]
}
]
请注意:
- 输出的 JSON 结构中的键
from必须拼写正确,不能写成fro或其他形式。 - 每个对话条目都必须包含
from和value两个键。 -
from的值只能是human及gpt。 - 必须要返回 gpt 跟 human 的结果 ``` # 第一步.爬取数据
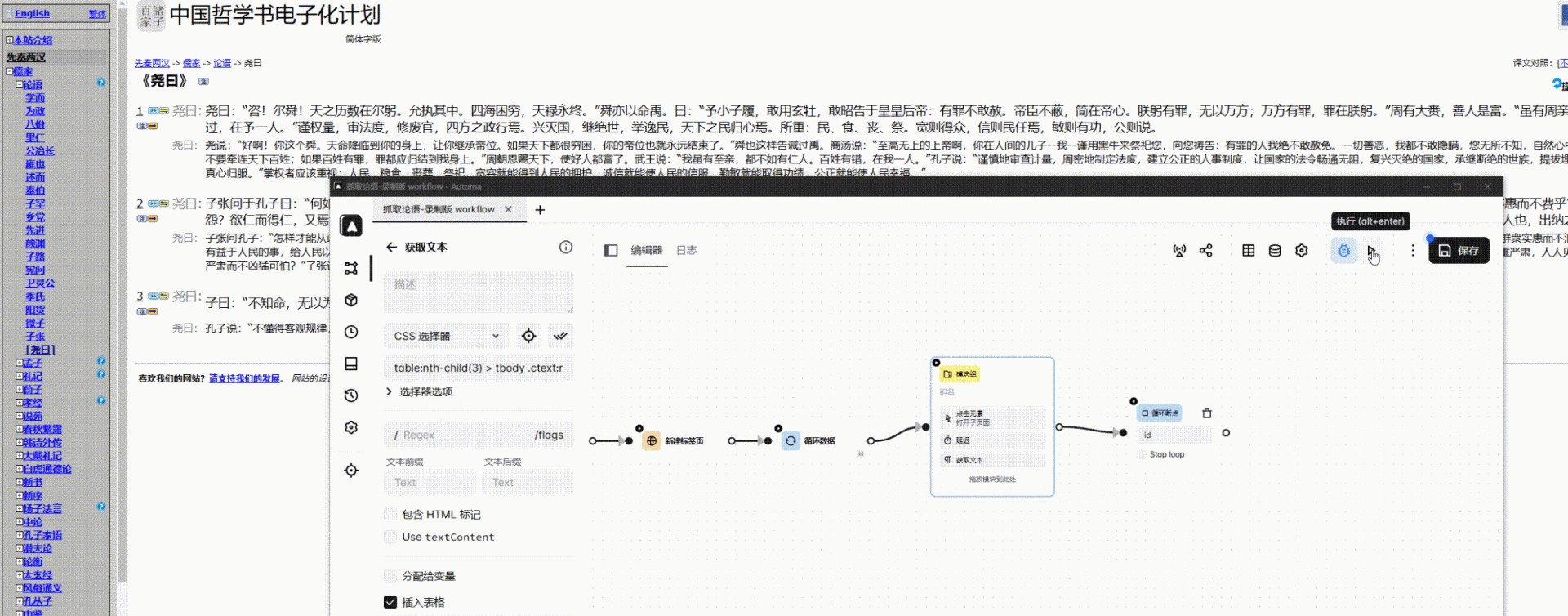
使用 Automa 爬取数据,这工具有很多有意思的工作流,大家可以关注一下
Automa - An extension for browser automation
https://github.com/AutomaApp/automa
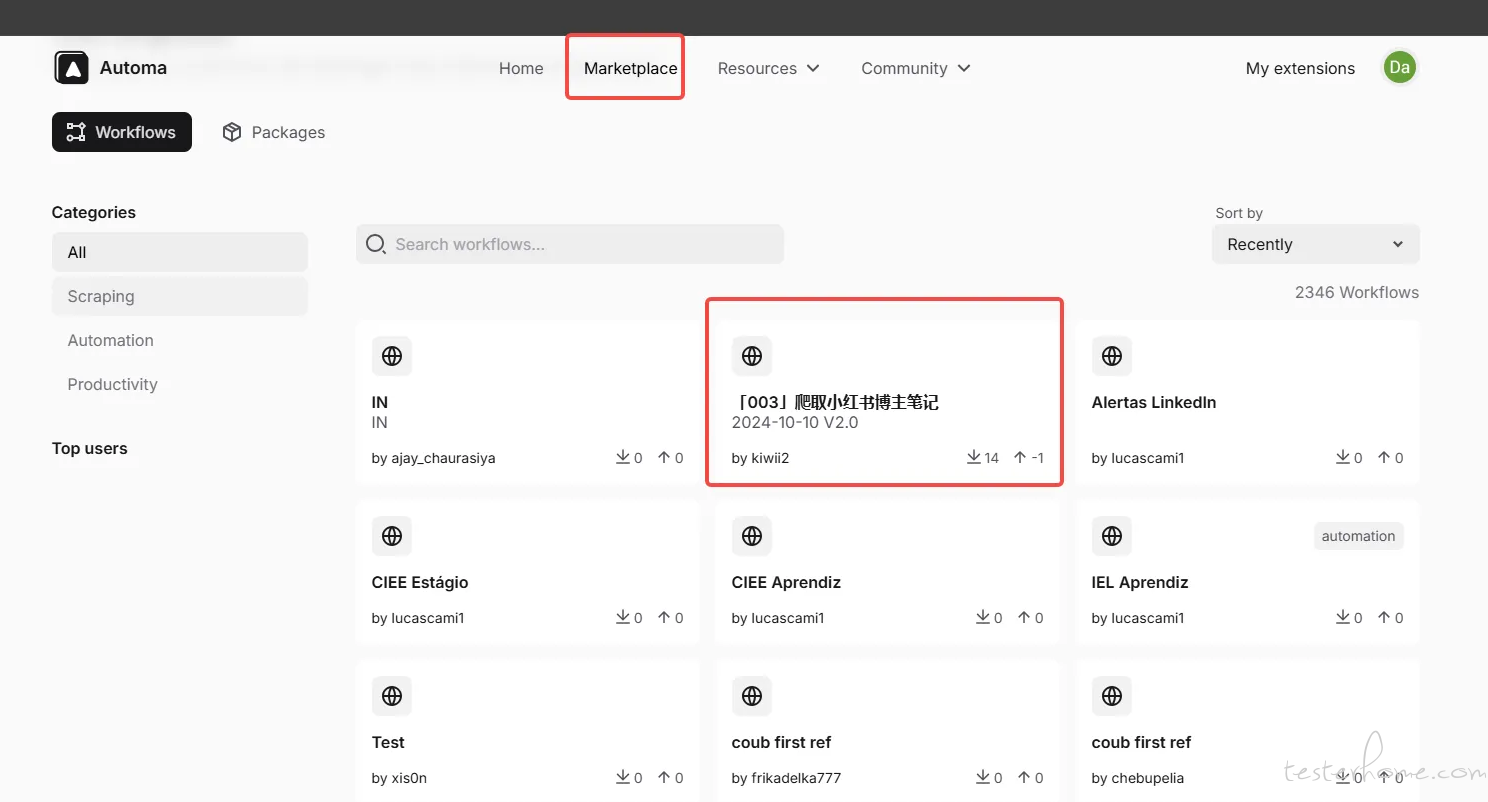
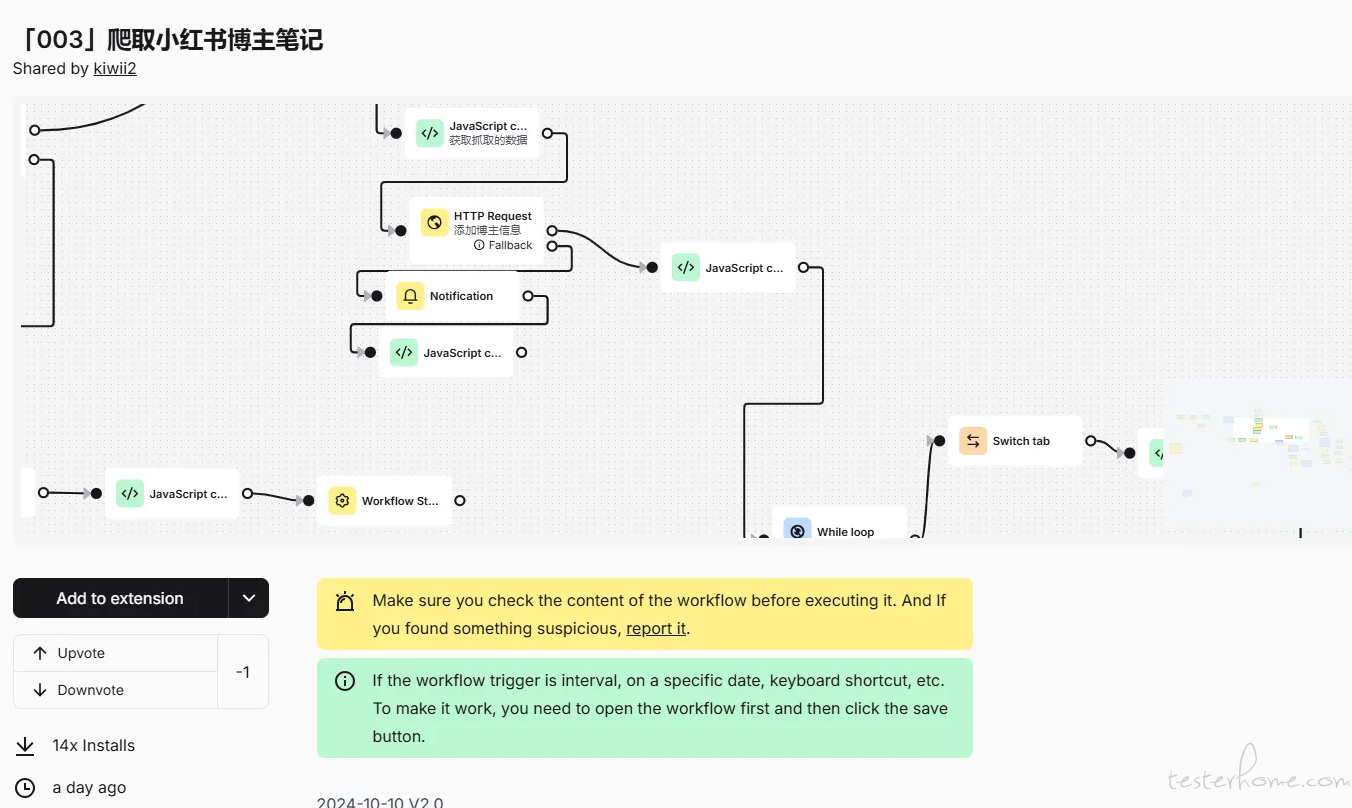
录制并调整工作流
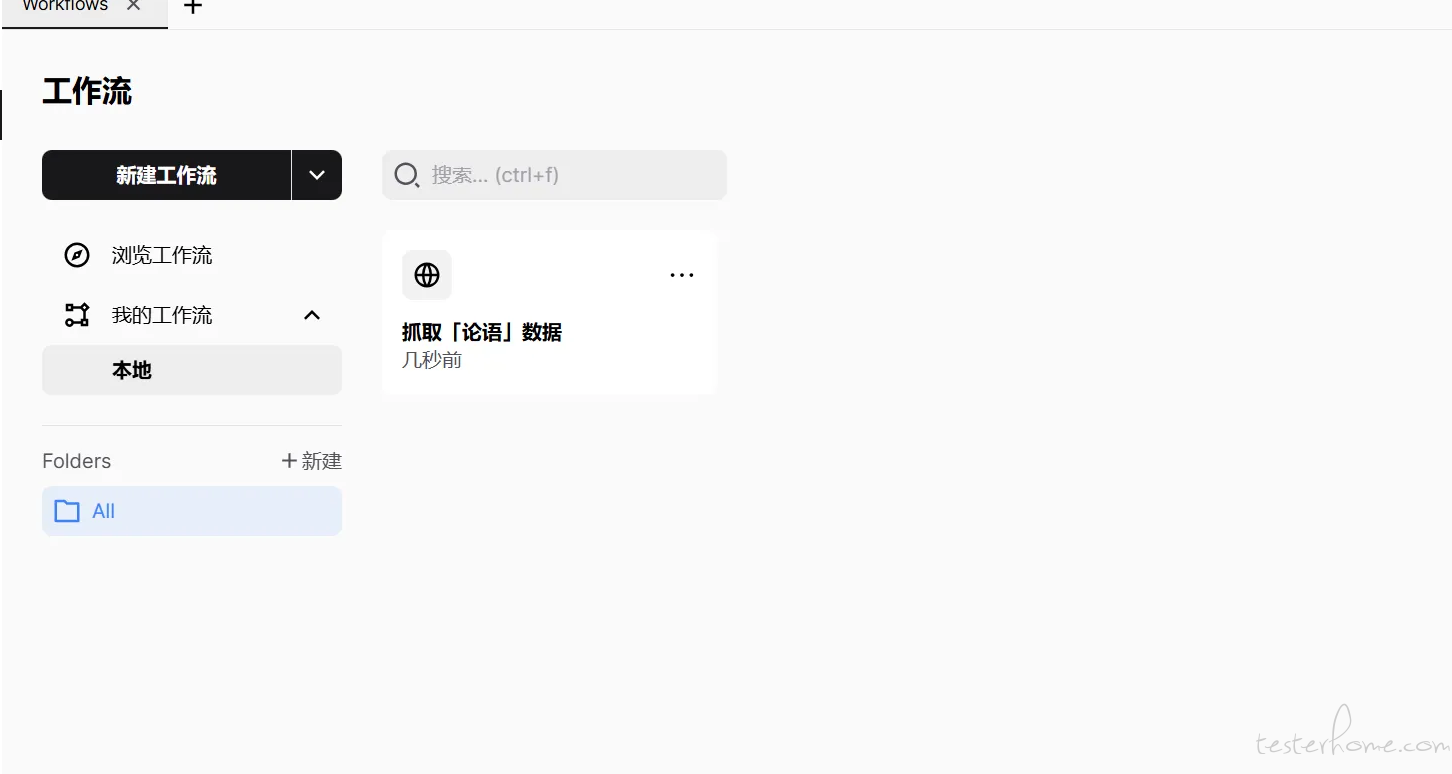
使用 CSS 选择器获取匹配的所有元素
table:nth-child(3) > tbody .ctext:nth-child(3)


测试工作流
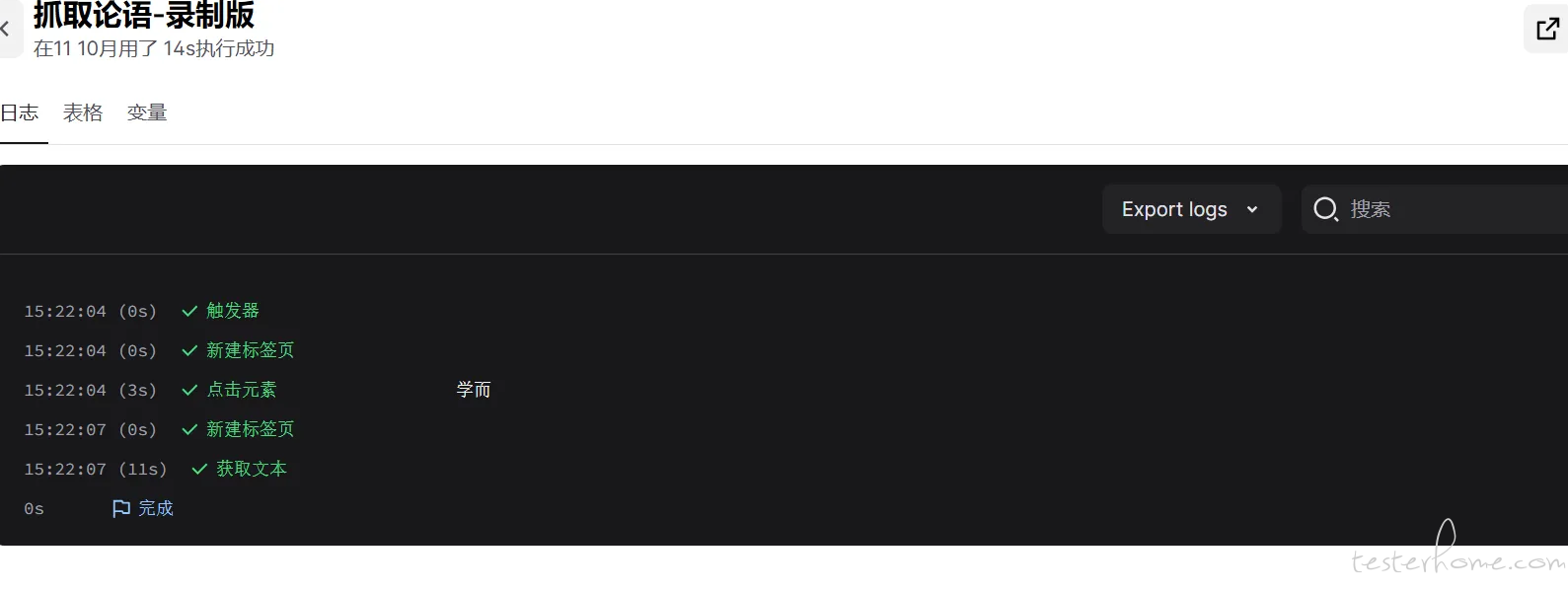
导出抓取数据
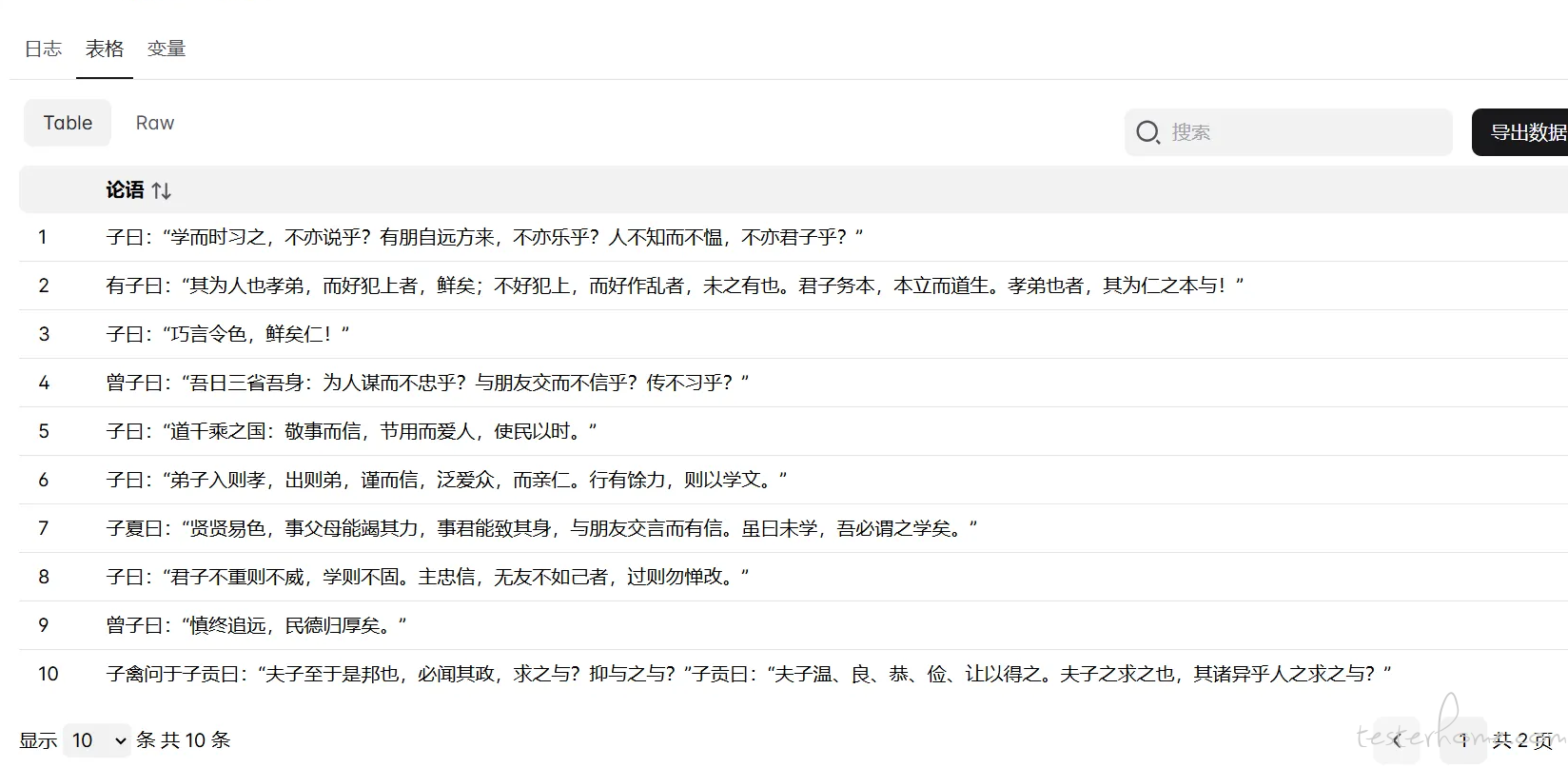

工作流改进
- 加入循环点击 - 同级多元素 - 操作
参考示例
Loop Elements Block | Automa Docs
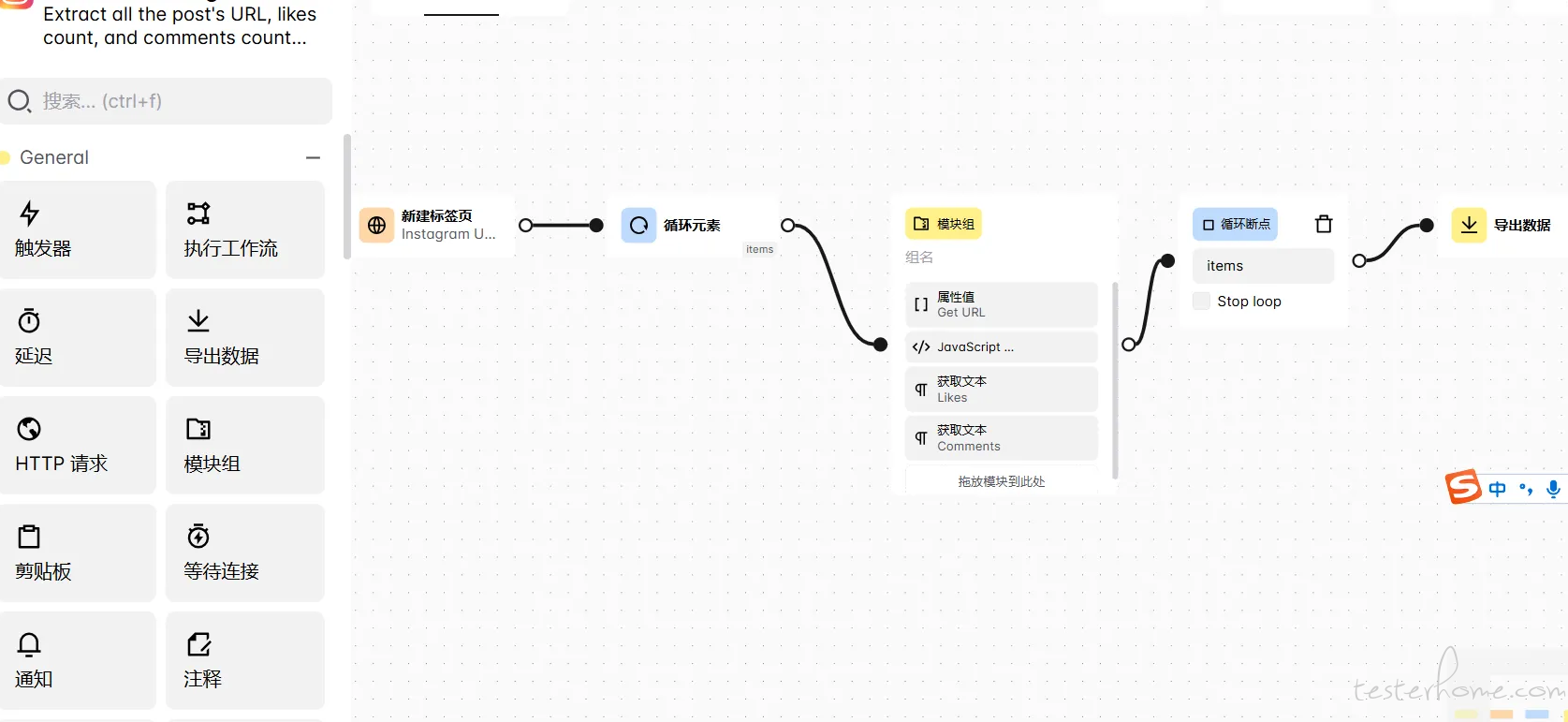
.menuitem:nth-child(2) > .subcontents >a

https://docs.automa.site/workflow/expressions.html
- 获取元素
最终效果
第二步.生成对话数据集
生成了 20 个分类 504 行对话数据,之后将这些数据,分批传给 LLM 转化为格式化数据集
方法一:人工通过与 LLM 对话进行转化
这部分数据集是手工与 LLM 进行沟通输出的,测试了一下,LLM 有上下文 Token 限制,并且不稳定。
提示词:
``
你是一个语言模型助手,需要将输入的内容转换为孔子(GPT)与其他人(human)之间的对话。具体要求如下:
- human:使用现代汉语表达,并与孔子互动,提出问题,语言多样。
- gpt:使用古文原文加上现代汉语解释。(gpt 即孔子,无需说 “子曰” 或 “孔子说”)
- 对话简洁明了,并附带现代汉语解释。
请将给定的对话转换为多个conversations对象,每个conversations对象包含一个human和一个gpt的对话。具体结构如下:
[
{
"conversations": [
{
"from": "human",
"value": "老师,您说过‘为政以德’,这句话是什么意思呢?"
},
{
"from": "gpt",
"value": "为政以德,譬如北辰,居其所而众星共之。\n(大白话解释:以德行来治理国家,就像北极星一样,它固定在自己的位置上,其他的星星都会围绕着它。)"
}
]
},
{
"conversations": [
{
"from": "human",
"value": "老师,《诗经》的核心思想是什么?"
},
{
"from": "gpt",
"value": "诗三百,一言以蔽之,曰‘思无邪’。\n(大白话解释:《诗经》三百篇,可以用一句话概括,那就是‘思想纯正’。)"
}
]
}
]
请注意:
- 输出的 JSON 结构中的键
from必须拼写正确,不能写成fro或其他形式。 - 每个对话条目都必须包含
from和value两个键。 -
from的值只能是human及gpt。 - 必须要返回 gpt 跟 human 的结果
```
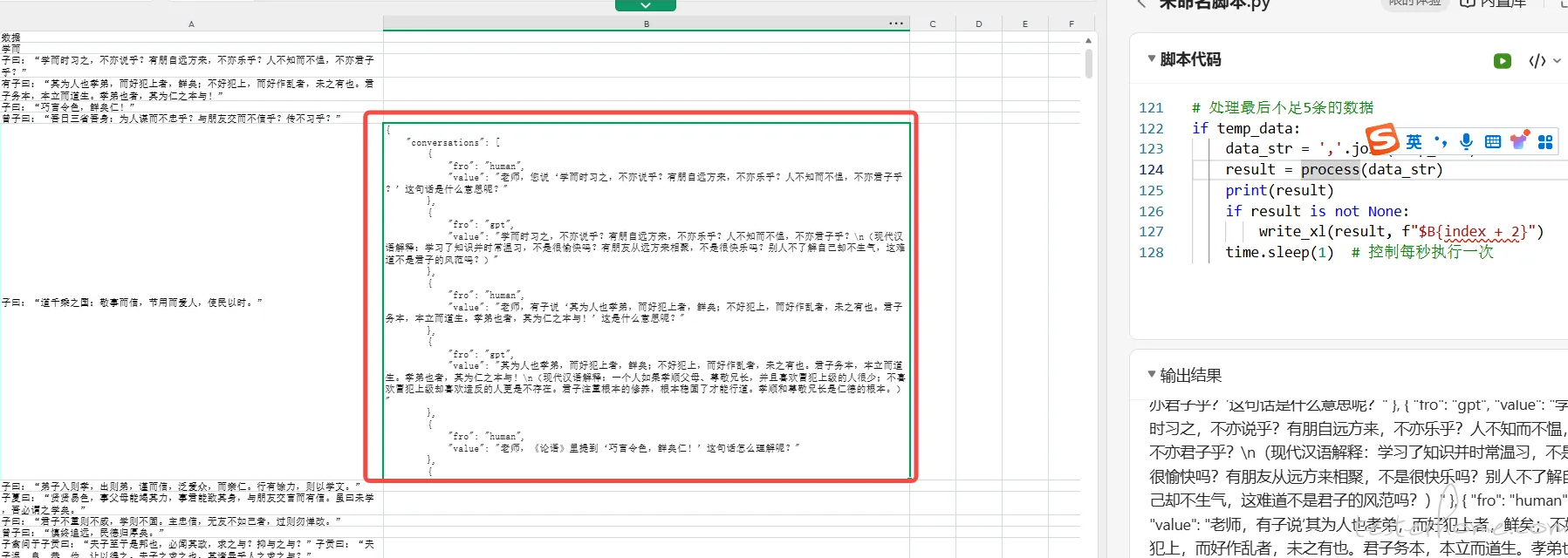
方式二:通过代码调用 LLM-API 实现转化过程
💡 将最终生成的 CSV 文件,每 5 行发给 LLM 进行转化处理,并将结果进行合并使用 WPS 的 Python 脚本编辑器,并调用硅基流动的 LLM 免费额度实现,之前都介绍过这 2 种方式,可查看进行回顾
Cursor 生成 AI 工具函数或脚本 - 实现 Excel 数据批量分析
试了一下代码实现的话,需要考虑模型的能力是否稳定,尝试了一下,模型能力的稳定是一个很麻烦的事情
目前还是建议通过手工的方式进行
import requests
import json
import time
# 定义常量
API_URL = "<https://api.siliconflow.cn/v1/chat/completions>"
AUTH_TOKEN = "Bearer xxxx"
MODEL_NAME = "Qwen/Qwen2.5-72B-Instruct-128K"
MAX_TOKENS = 1024
# 定义提示信息
PROMPT = """
你是一个语言模型助手,需要将输入的内容转换为孔子(GPT)与其他人(human)之间的对话。具体要求如下:
1. human:使用现代汉语表达,并与孔子互动,提出问题,语言多样。
2. gpt:使用古文原文加上现代汉语解释。(gpt即孔子,无需说“子曰”或“孔子说”)
3. 对话简洁明了,并附带现代汉语解释。
输出结果必须是 JSON 结构,并按照以下示例格式:
{
"conversations": [
{
"from": "human",
"value": "老师,现在很多人都追求物质享受,您觉得内心的修养和仁德更重要吗?"
},
{
"from": "gpt",
"value": "君子谋道不谋食。耕也,馁在其中矣;学也,禄在其中矣。君子忧道不忧贫。\n(现代汉语解释:君子追求的是道,而不是物质享受。即使耕作也会有饥饿的风险;而学习则会带来俸禄。君子担忧的是道的缺失,而不是贫穷。)"
}
]
}
请注意:
- 输出的 JSON 结构中的键 `from` 必须拼写正确,不能写成 `fro` 或其他形式。
- 每个对话条目都必须包含 `from` 和 `value` 两个键。
- `from` 的值只能是 `human` 及 `gpt`。
- 必须要返回gpt跟human的结果
"""
def get_answer(input_text):
payload = {
"model": MODEL_NAME,
"messages": [
{
"role": "system",
"content": PROMPT
},
{
"role": "user",
"content": input_text
}
],
"stream": False,
"max_tokens": MAX_TOKENS,
"temperature": 0.7,
"top_p": 0.7,
"top_k": 50,
"frequency_penalty": 0.5,
"n": 1,
"response_format": {"type": "json_object"}
}
headers = {
"Authorization": AUTH_TOKEN,
"Content-Type": "application/json"
}
try:
response = requests.post(API_URL, json=payload, headers=headers)
response.raise_for_status() # 抛出 HTTP 错误
result = response.json()
choices_message_content = result.get("choices", [{}])[0].get("message", {}).get("content")
return choices_message_content
except requests.RequestException as e:
print(f"请求失败: {e}")
return None
def parse_json_string(json_string):
try:
parsed_result = json.loads(json_string)
return parsed_result
except json.JSONDecodeError as e:
print(f"JSON 解析失败: {e}")
return None
def process(input_text):
result = get_answer(input_text)
if result:
parsed_result = parse_json_string(result)
if parsed_result:
return json.dumps(parsed_result, ensure_ascii=False, indent=4)
else:
print("无法解析 JSON 字符串。")
else:
print("请求失败,请检查输入或网络连接。")
# 读取数据
df = xl("$A:$A", headers=True)
# 初始化空列表存储符合条件的数据
temp_data = []
count = 0
for index, row in df.iterrows():
if len(row["数据"]) > 10:
temp_data.append(row["数据"])
count += 1
if count == 5:
data_str = ','.join(temp_data)
result = process(data_str)
print(result)
# 清空临时存储列表并重置计数器
temp_data.clear()
count = 0
if result is not None:
write_xl(result, f"$B{index + 2}")
time.sleep(1) # 控制每秒执行一次
else:
time.sleep(1) # 控制每秒执行一次
# 处理最后不足5条的数据
if temp_data:
data_str = ','.join(temp_data)
result = process(data_str)
print(result)
if result is not None:
write_xl(result, f"$B{index + 2}")
time.sleep(1) # 控制每秒执行一次

