版主
hello2014 (大海)
第 1203 位会员 / 2014-07-03
177 篇帖子 • 677 条回帖
每一天,遇见更好的自己!
1、参与 Appium 文档翻译计划
https://www.kancloud.cn/testerhome/appium_docs_cn
https://github.com/testerhome/appium/commit/8e4810fe335284e3df97ec855b663431232915aa
2、荣获 2 项政府荣誉
3、当选省技术委员会委员
4、入选中山市双领域专家
-
44 个赞 / 37 条回复
-
25 个赞 / 17 条回复
-
19 个赞 / 12 条回复
-
12 个赞 / 6 条回复
-
11 个赞 / 12 条回复
-
10 个赞 / 7 条回复
-
9 个赞 / 1 条回复
-
9 个赞 / 18 条回复
-
8 个赞 / 0 条回复
-
7 个赞 / 0 条回复
-
7 个赞 / 7 条回复
-
6 个赞 / 7 条回复
-
6 个赞 / 2 条回复
-
6 个赞 / 8 条回复
-
6 个赞 / 1 条回复
-
6 个赞 / 3 条回复
-
5 个赞 / 1 条回复
-
4 个赞 / 6 条回复
-
4 个赞 / 0 条回复
-
4 个赞 / 10 条回复
-
4 个赞 / 6 条回复
-
4 个赞 / 0 条回复
-
4 个赞 / 4 条回复
-
4 个赞 / 35 条回复
-
3 个赞 / 0 条回复
-
开工第一天,好困,好累 at 2026年02月25日
真不容易
-
有在回家路上的吗 at 2026年02月12日
明天一大早就出发
-
独立开发,从 0 到 0.5 的开发和运营一个站点案例 at 2026年01月26日
方向没问题,路线也是对的,现在就是等待时机爆发。
-
年薪 50~60 万是什么样的? at 2026年01月12日
年薪 50-60w 并不高,你也可以达到
-
人工智能训练师的含精量 at 2025年12月31日
为啥是自费呢,不应该是企业出钱么?
苏州这边是企业统一申报该工种的技能考试,员工不需要出钱,直接是在企业内部进行考试,前提是所属企业要进行备案资质的申请,通过才可以。

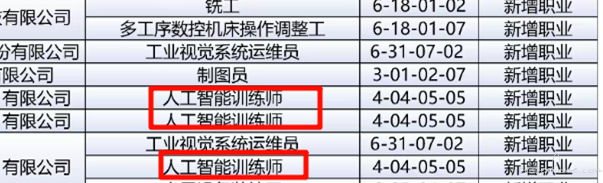
-
我的第一次总结---2025 at 2025年12月03日
牛啊,30 万的粉丝,太强了
-
2025 年度总结 at 2025年12月01日
加油
-
临时邮箱项目挂了,压测复现问题,贴监控数据 at 2025年11月25日
厉害,思路很好
-
你觉得这是机会?还是压榨? at 2025年11月25日
我的看法是不接,做好本职工作,因为做的太多就会错的太多,绩效会很难看,而且,产品不是岗位本职工作,不产生实际的岗位绩效价值。所谓的成长,是一种自我安慰,大环境下,需要聚焦主体。明确拒绝,避免陷入 “既做不好产品,又耽误开发” 的双输局面。
P.S. 很多公司喜欢说 “这是锻炼”,但真正的锻炼是有保护、有反馈、有出口的,而不是把你扔进深水区还说 “游泳很简单”。 -
软测副业 at 2025年11月18日
是的,最起码得有点规模的,有知名度的企业。
1、参与 Appium 文档翻译计划
https://www.kancloud.cn/testerhome/appium_docs_cn
https://github.com/testerhome/appium/commit/8e4810fe335284e3df97ec855b663431232915aa
2、荣获 2 项政府荣誉
3、当选省技术委员会委员
4、入选中山市双领域专家