-
AI 自动化测试的方案 at 2026年07月28日
可以分享一下思路嘛,有相关开源项目不?
-
初创小团队应该如何建立自动化测试体系 at 2026年07月23日
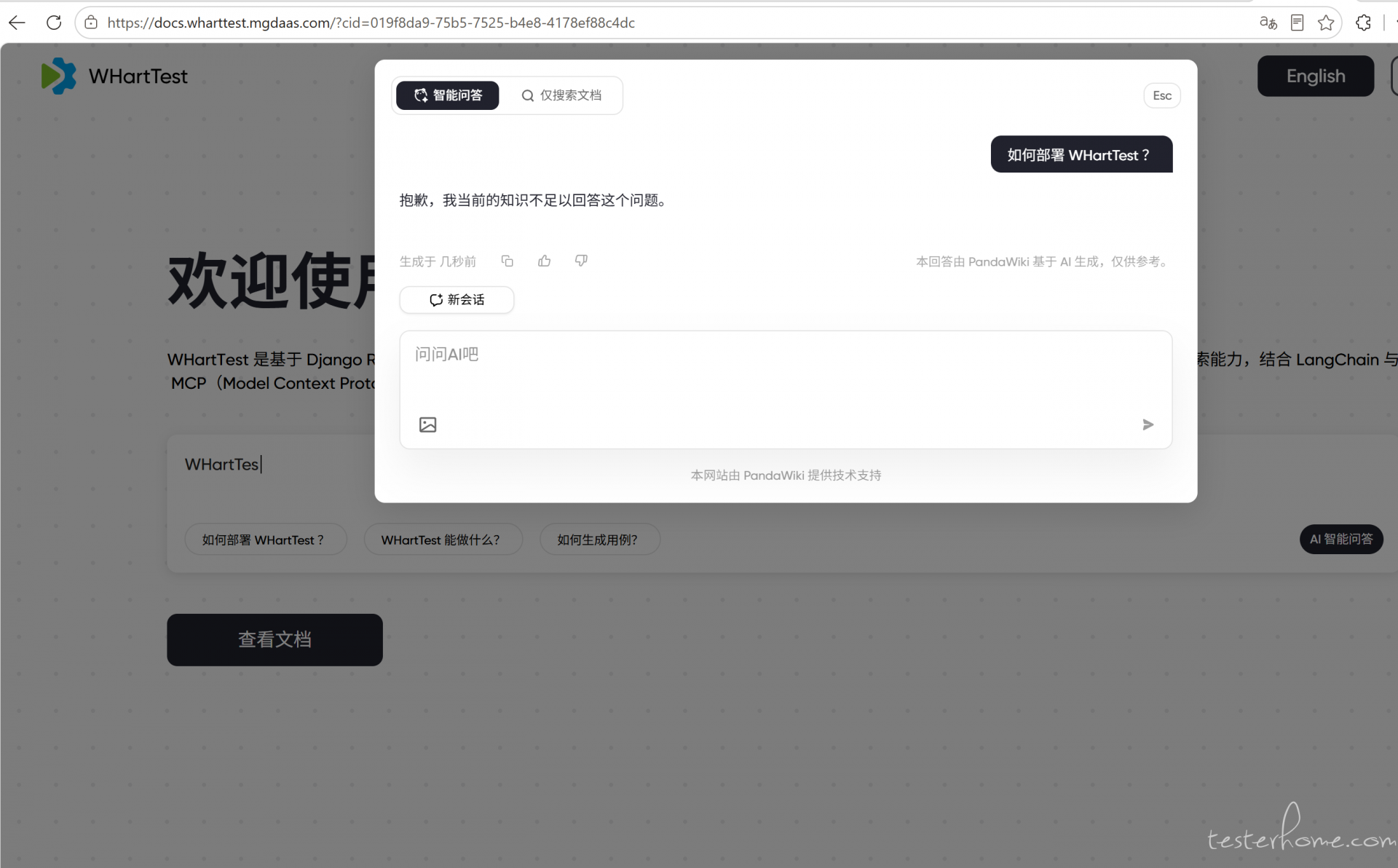
认真的嘛?连官网都有问题。 -
初创小团队应该如何建立自动化测试体系 at 2026年07月23日
那需求设计与实际开发和最终结果怎么都会有点差别,后端仓库搭建知识库相对准确一点。而且有些团队的产品需求设计文档是不全的。那大佬有没有什么好方案想根据产品需求设计来生成测试用例。
-
初创小团队应该如何建立自动化测试体系 at 2026年07月22日
如果有后端仓库可以连接的话,其实拿后端仓库搭建知识库,用来生成测试用例也不错。
-
AI 赋能测试实践 11:别把 Claude Code 当聊天框用了——三层改造,驯成你的测试专属智能体 at 2026年07月17日
多谢大佬明白了
-
AI 赋能测试实践 11:别把 Claude Code 当聊天框用了——三层改造,驯成你的测试专属智能体 at 2026年07月16日
大佬有没有测过 token usage,token 消耗的相关功能,这玩意怎么测他计算消耗的 token 的数量是对的。
-
AI 赋能测试实践 11:别把 Claude Code 当聊天框用了——三层改造,驯成你的测试专属智能体 at 2026年07月10日
大佬,给老项目做知识库搭建做测试用例生成,有没有好方案不。
-
测试工程师常用的 5 个 AI 提示词模板 at 2026年07月09日
学到了
-
AI 赋能测试实践 11:别把 Claude Code 当聊天框用了——三层改造,驯成你的测试专属智能体 at 2026年07月07日
蹲到最新的文章。现在这环境,测试 qa 还有得玩不。
-
测试开发是不是已经是最没用的岗位 at 2026年06月22日
不是测开凉了,而是测开的标准高了,但凡公司引入过 ai 上项目的人就知道有多少坑的了。没有那么简单的。测试也没有凉,大厂测试合并到开发,只不过是降本增效手段而已,又不是凉了,其他公司也有专门的测试在做,比如 agent 测试,算法测试等。
-
评估、测试 skill 的方法和 llm as a judge 方法很相似,都是拿另外一个更好的去评估现有的。
-
蹲到 skill 了。
-
AI 驱动 UI 自动化的完整 DEOM 工程 at 2026年05月27日
有直播回放?
-
Prompt 不够了,AI 产品更需要测试思维 at 2026年05月27日
那评测工程化的方法论还有相关项目有不,有具体的案例不?
-
AI 赋能测试实践 08:当 51 万行源码裸奔,我们该如何给最强 AI 智能体做测试(下) at 2026年05月12日
牛啊,谢谢佬,我先试一试。
-
AI 赋能测试实践 08:当 51 万行源码裸奔,我们该如何给最强 AI 智能体做测试(下) at 2026年05月11日
谢谢佬
-
AI 赋能测试实践 08:当 51 万行源码裸奔,我们该如何给最强 AI 智能体做测试(下) at 2026年05月11日
有没有通用的解决方案,针对各种自研的 agent 平台。
-
AI 赋能测试实践 08:当 51 万行源码裸奔,我们该如何给最强 AI 智能体做测试(下) at 2026年05月11日
对了那个轨迹判断,每一次发送 prompt 给 llm,llm 决定调用哪些 tool,而且每次他的轨迹都不一样,那么怎么做质量评估,甚至有时候直接用大模型里面的内容进行返回, 没有使用 tool,这样的话怎么做评估。
-
AI 赋能测试实践 08:当 51 万行源码裸奔,我们该如何给最强 AI 智能体做测试(下) at 2026年05月11日
抱紧大佬的大腿
-
AI 赋能测试实践 08:当 51 万行源码裸奔,我们该如何给最强 AI 智能体做测试(下) at 2026年05月11日
蹲,DeepEval 框架做 agent 工具链质量评估,有试过嘛,能出一期嘛。
-
AI 赋能测试实践 07:当 51 万行源码裸奔,我们该如何给最强 AI 智能体 Claude Code 做测试(中) at 2026年05月07日
蹲,期待一下。
-
AI 赋能测试实践 07:当 51 万行源码裸奔,我们该如何给最强 AI 智能体 Claude Code 做测试(中) at 2026年05月06日
蹲能否出一个测试 mcp 还有 skill 的测试方法论或者测试方法。
-
AI 赋能测试实践 06:当 51 万行源码裸奔,我们该如何给最强 AI 智能体 Claude Code 做测试(上) at 2026年04月22日
蹲
-
AI 赋能测试实践 06:当 51 万行源码裸奔,我们该如何给最强 AI 智能体 Claude Code 做测试(上) at 2026年04月21日
蹲剩下的两篇
-
寒冬了么 at 2026年01月27日
忙着年终总结呢