AI测试 AI 赋能测试实践 10:会装 Skill 不牛逼,能写 Skill 才是真本事——从 Anthropic 138K Star 仓库说起
前言
上期 MCP 那篇结尾留了个预告:下一期讲 Skill。这期间 Anthropic 官方的 Agent Skills 仓库 anthropics/skills 已经冲到 138K Star。什么概念?Playwright 87K,Selenium 34K。一个放 SKILL.md 文件的仓库,热度超了一线测试框架。
但测试之家上能找到的 Skill 文章,大多是"有哪些可以装"的清单式盘点。比如狂师那篇10 款 AI Skills 神器,介绍了 Test Master、API Tester 等工具。这种文章能帮你快速上手,问题是你永远在用别人定义好的能力边界。
这篇不列清单。这篇带你从一个空文件夹开始,写一个真正解决测试痛点的 Skill,然后接到 Claude Code 里跑起来。
一、Skill 到底是什么?——既然上期讲过了 MCP
上期把 MCP 讲清楚了:MCP 是通信协议,管"能不能做"。Skill 是行为指令,管"怎么做"。一个不那么精确但好理解的类比:
- MCP = 给 AI 配了一套工具箱(锤子、螺丝刀、电钻)
- Skill = 给 AI 配了一本施工手册("先拆面板、再松螺丝、注意别碰火线")
更精确一点,从 Claude Code 官方文档的角度:
| 组件 | 作用 | 加载时机 |
|---|---|---|
| CLAUDE.md | 存事实——项目约定、背景知识 | 每次对话自动加载 |
| Skill | 存流程——检查清单、多步骤操作指导 | 仅在调用时加载 |
| MCP | 存工具——外部 API / 数据库 / 浏览器的连接能力 | 按需连接 |
这三个加起来,才是完整的 AI Agent 能力体系。上期讲了 MCP,这期讲 Skill。核心区别一句话:CLAUDE.md 是"这个项目是什么样的",Skill 是"这件事该怎么做",MCP 是"我能调用什么外部工具"。
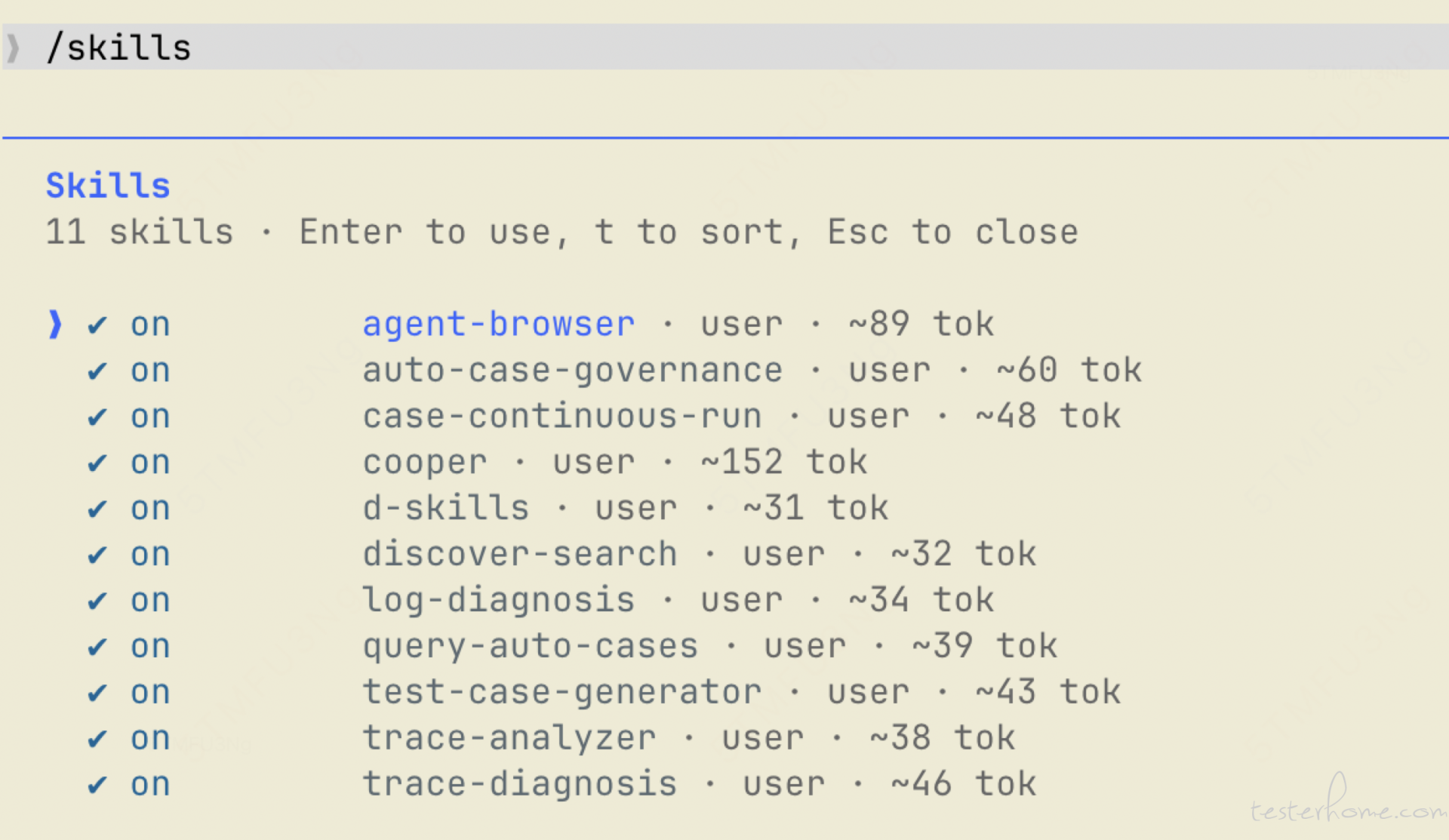
二、一个 Skill 文件到底长什么样?
最简单的情况下,一个 Skill 就一个 SKILL.md。但按照 agentskills.io 规范,完整的目录结构是这样的:
my-custom-skill/
├── SKILL.md # 必需:元数据 + 核心指令
├── scripts/ # 可选:可执行脚本(Shell / Python)
├── references/ # 可选:详细参考文档
├── examples/ # 可选:示例输出
└── assets/ # 可选:模板、图片等资源
这么设计的原因叫"渐进式披露"——Claude 启动时只加载 SKILL.md 的名称和描述,匹配到任务时才读完整正文。如果有 references/、examples/ 等辅助文件,用到的才按需加载。这样即使 Skill 内容很多,也不会白白占着上下文。
SKILL.md 分两部分。YAML 头告诉 AI "什么时候用我":
---
name: my-skill
description: 清晰说明技能用途。当用户提到"XXX"、"YYY"时使用。
allowed-tools: Read, Write, Bash
---
Markdown 正文告诉 AI "具体怎么做"——把你平时需要反复粘贴给 AI 的那段话写进去就行。三个关键规则:
- description 是 Skill 的"门禁"——Claude 靠它决定要不要自动激活。写太模糊永远不会自动触发,写具体到用户会说的触发词才会生效
- allowed-tools 是最小权限声明——不声明的工具 Claude 不会用,防止越权
- SKILL.md 不要写太长——把详细的参考内容放到 references/ 里,正文只保留核心流程和引用链接。正文生效后持续存在整个会话
三、手把手:写一个测试专用的 Skill
光看例子不够,笔者带各位从零写一个真正能用的测试 Skill。
场景选择
写代码的时候你想过这个问题吗:开发用 AI 一天提 20 个 PR,你一个人怎么跟?测试之家上有个帖子,标题是研发 AI 提效很高,代码产出指数级上升,测试压力很大,21 条回复。孙高飞在里面反复提到一个词——"知识库"和"Skill"。他的观点是:同一个模型,不同的人用效果天差地别,差距就在你有没有把测试经验沉淀成 AI 能读懂的东西。
举个真实场景。一个项目每轮回归跑 200 个用例,挂了 30 个。传统做法:你点开 Allure 报告,一个个看错误日志,判断是环境问题还是代码 bug,是偶发还是必现,再写分析邮件发群里。这一套下来,半小时起步。如果一天跑三轮回归,你大半个上午就耗在这上面了。
笔者想用 Skill 解决的就是这件事。我把它叫做 regression-analyst——回归测试分析助手。不管是全部通过还是挂了三分之一,每次回归跑完它都能给你一份分析报告。
第一步:创建完整目录结构
先搭框架:
mkdir -p ~/.claude/skills/regression-analyst/{references,examples}
第二步:写 SKILL.md(精简版,只写核心流程)
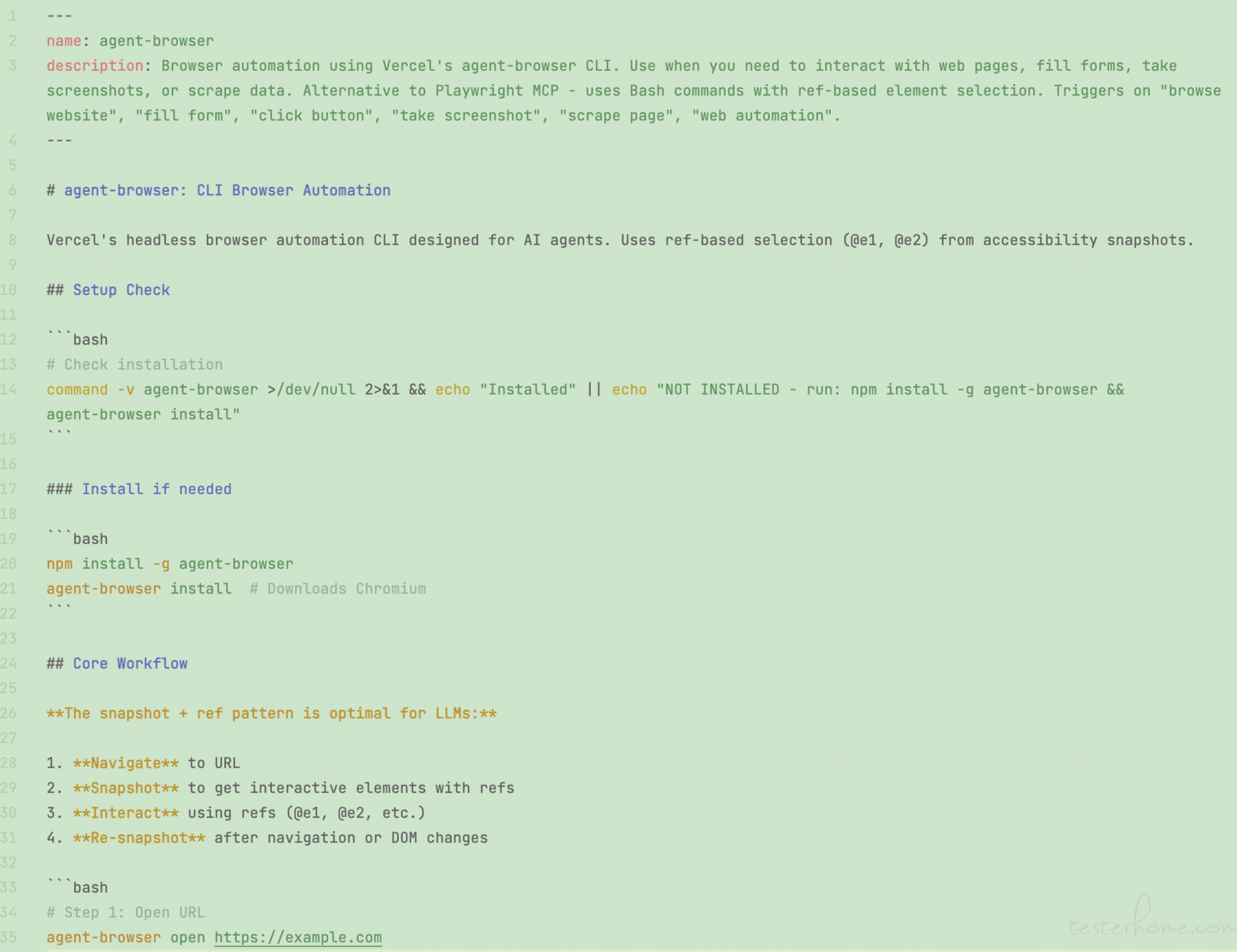
---
name: regression-analyst
description: 分析回归测试结果,自动识别失败根因、检测 flaky test、追踪通过率趋势。当用户提到"回归结果"、"测试报告分析"、"看看最近测试情况"、"有哪些 flaky"、"通过率怎么样"时使用。
allowed-tools: Read, Bash, Grep, Glob
---
这里有两个设计细节值得说一下。一是 description 里故意放了口语化的触发词——"看看最近测试情况"、"通过率怎么样"——这种自然语言正是你日常跟同事说话时会用的。AI 靠这个判断要不要激活 Skill,你写得太官方它反而不识别。
二是 allowed-tools 只声明了 Read/Bash/Grep/Glob,没有 Write——这个 Skill 只分析,不改代码,权限最小化。
正文部分不再塞几十行分类表和模板,改为引用外部文件:
# 回归测试分析助手
你是一个资深测试开发工程师,擅长从 Allure / pytest-html / JUnit XML 报告中进行回归分析。
## 工作流程
1. **读取报告**:用 Glob 定位最新的测试报告文件,用 Read / Bash 获取内容
2. **分类失败**:参考 [references/failure-patterns.md](references/failure-patterns.md) 中的分类规则
3. **检测 flaky**:对比最近 3-5 轮数据,标记交替通过/失败的用例
4. **分析趋势**:提取最近 5 轮通过率,标注下降超过 5% 的轮次
5. **输出报告**:参考 [examples/report-template.md](examples/report-template.md) 的格式
## 输出要求
- 报告用 Markdown 格式,结构参考 examples/ 中的模板
- 偶发超时标注"建议重跑",不标注为代码 bug
- 如果 git log 能追溯到变更,一并引用 commit hash
- 用户只问了其中一项(如"有哪些 flaky"),只输出对应部分
## 参考文件
- 分类规则:[references/failure-patterns.md](references/failure-patterns.md)
- 报告模板:[examples/report-template.md](examples/report-template.md)
第三步:创建 references/ 辅助文件
references/failure-patterns.md 存放分类规则。这样以后要调整分类——比如细分一下哪个边界条件归哪类——只改这个文件,不动 SKILL.md 主逻辑:
# 测试失败分类手册
对每个失败用例,根据错误特征归类为以下五种之一:
| 分类 | 识别特征 | 处理建议 |
|------|---------|---------|
| 环境问题 | Connection refused、timeout、DNS 解析失败 | 检查测试环境,无需改代码 |
| 断言失败 | AssertionError,预期值和实际值不匹配 | 确认是 bug 还是用例需更新 |
| 元素定位失败 | NoSuchElement、stale element | UI 变更导致,需更新定位器 |
| 测试数据问题 | 依赖的外部数据过期、状态变更 | 刷新测试数据或调整预设条件 |
| 代码逻辑变更 | 接口字段变更、返回值结构变化 | 拉相关 git log 找对应 commit |
## 优先级判定
- P0:同一失败原因出现 3 次以上——共性问题,快速修复能清掉大批用例
- P1:关键接口/核心流程的失败
- P2:偶发超时/网络波动
- P3:孤立偶发故障
## Flaky test 判定
- 最近 5 轮中通过/失败交替出现
- 失败原因不固定(排除"每次都同一个原因"的稳定失败)
第四步:创建 examples/ 模板文件
examples/report-template.md 存放报告模板,Claude 按这个格式输出:
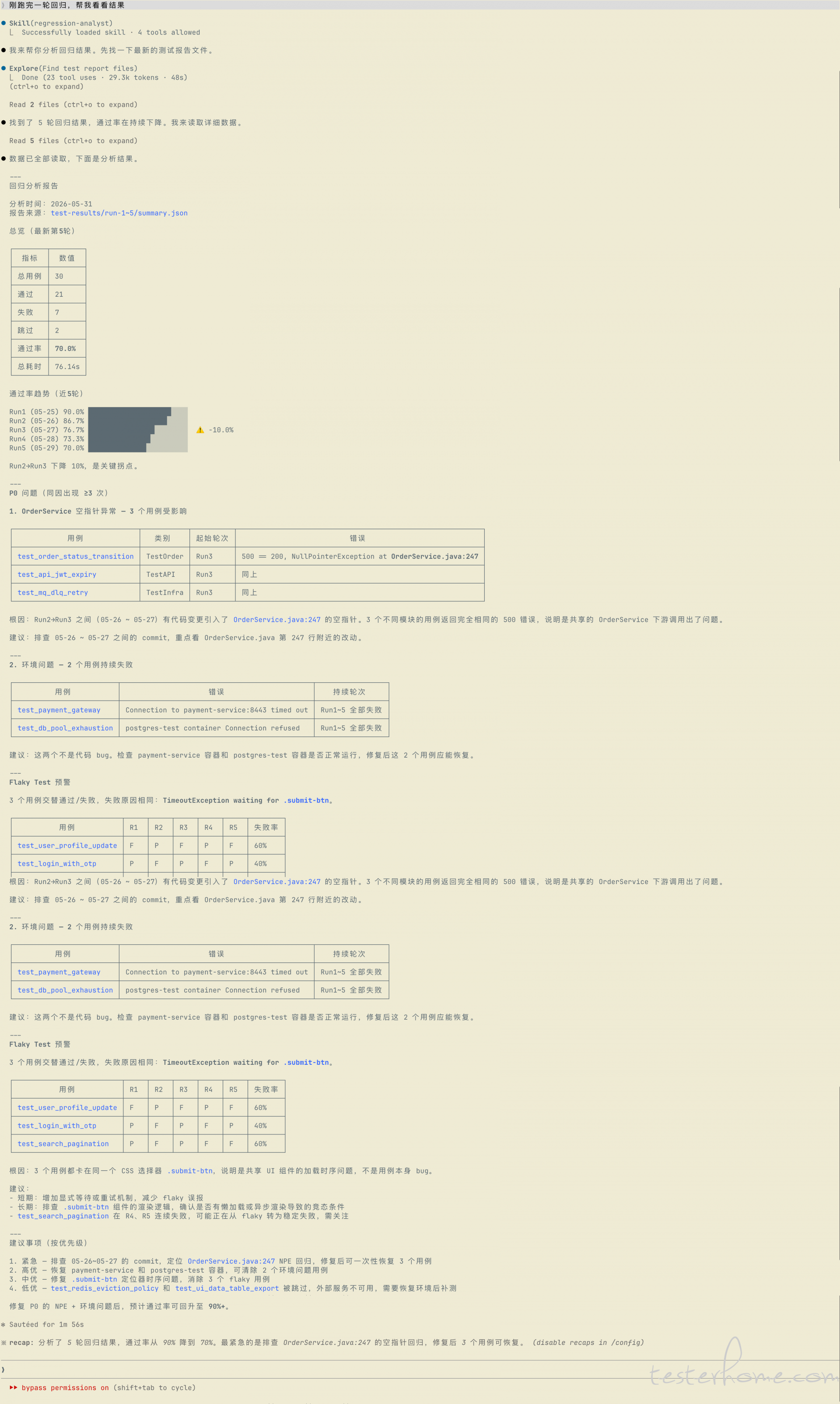
## 回归分析报告
**分析时间**:{当前时间}
**报告来源**:{报告文件路径}
### 总览
| 指标 | 数值 |
|------|------|
| 总用例 | xxx |
| 通过 | xxx |
| 失败 | xxx |
| 跳过 | xxx |
| 通过率 | xx.x% |
| 总耗时 | xxx |
### 通过率趋势(近5轮)
{ASCII 趋势图,标注下降 >5% 的轮次}
### 失败分类
{按 P0→P3 优先级列出,P0 标红}
### P0 问题
{详细分析,含错误信息、根因、相关 commit、修复建议}
### Flaky test 预警
{用例名 + 最近5轮结果 + 失败频率 + 建议}
### 建议事项
{按优先级列出行动项}
第五步:安装和验证
最终目录结构:
regression-analyst/
├── SKILL.md
├── references/
│ └── failure-patterns.md
└── examples/
└── report-template.md
文件写好之后,Claude Code 会实时检测 .claude/skills/ 目录的变更。如果没自动生效,用 5 月底新增的 /reload-skills 命令手动刷新。
试一句实在的:
"刚跑完一轮回归,帮我看看结果"
或者更具体的:
"最近回归的通过率是不是在掉?帮我查一下趋势"
一个彩蛋:5 分钟再搓一个轻量 Skill
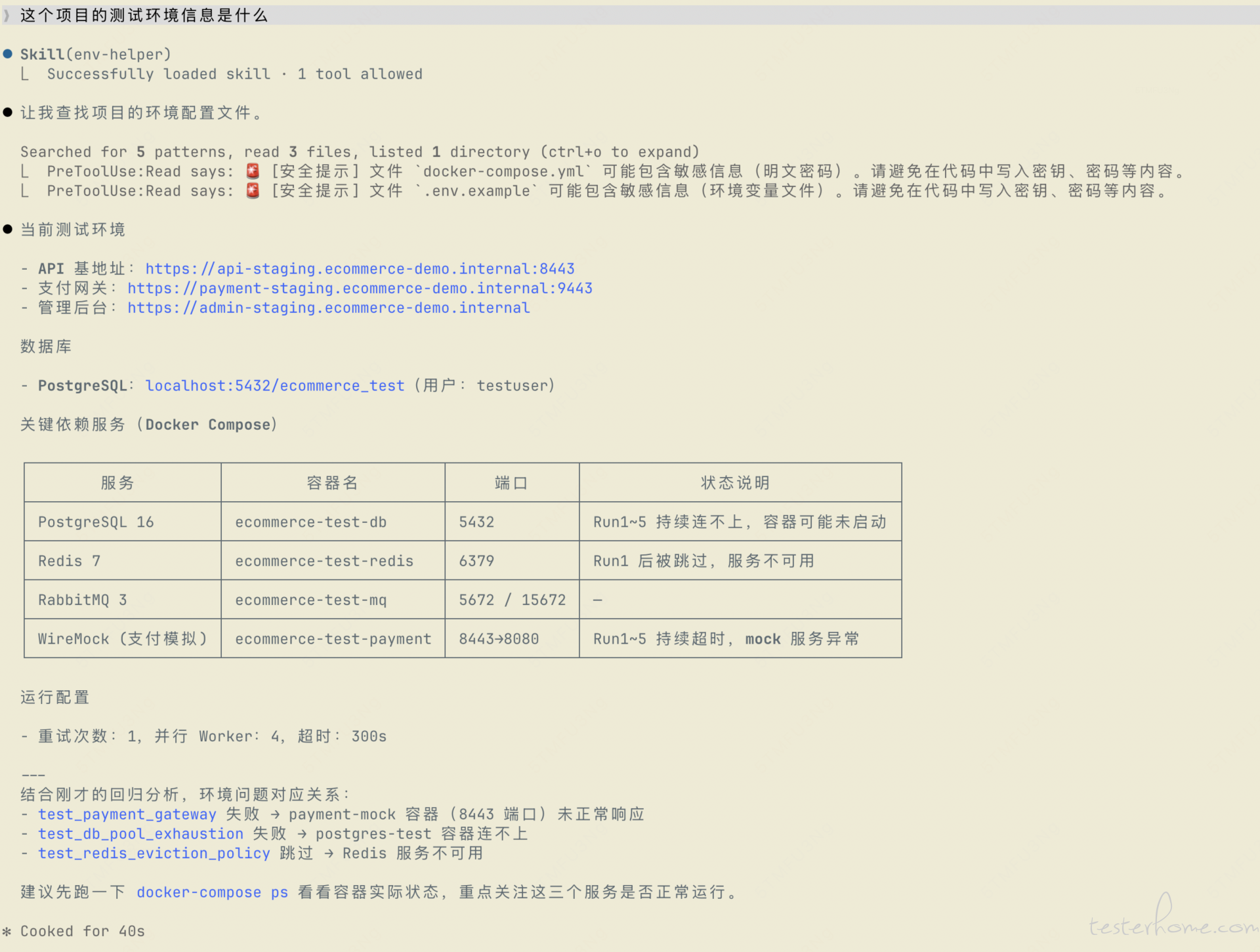
学会方法之后,你会发现很多场景都能用 Skill 搞定。比如团队最近老有人问"这个服务的接口地址是什么",以前你得翻文档或者查配置。现在花 5 分钟写一个——这次不建 references 目录了,就一个 SKILL.md,因为场景足够简单:
---
name: env-helper
description: 查询当前项目的测试环境信息。当用户提到"测试环境"、"接口地址"、"数据库连接"、"环境配置"时使用。
allowed-tools: Read
---
# 环境信息查询
从项目的 README.md、docker-compose.yml 和 .env.example 中提取并整理环境信息。
输出格式:
## 当前测试环境
- API 基地址:{从配置中提取}
- 数据库:{host:port/db}
- 关键依赖服务:{列表}
这就不再是"分析工具"了,而是一个团队共享的知识入口。重点不是这个 Skill 本身有多复杂,是你掌握了套路之后,任何一个重复性的测试工作,你都可以花几分钟把它封装成 Skill。
四、如何测试一个 Skill?
这个问题很有意思——你写了一个 Skill,你怎么知道它"好用不好用"?这就是元测试——测试你用来测试的东西。
4.1 基本功能验证
最直观的方法:跑几轮真实对话,看 Skill 是否按照预期行为执行。笔者自己的验证方法是准备 3 个不同复杂度的场景,依次测:
- 简单场景:"最近一次测试有 3 个失败,帮我看看"——验证 Skill 能否正确触发并定位报告
- 模糊场景:"那个测试好像挂了"——验证 Skill 在缺乏具体信息时是否主动追问
- 复杂场景:"上个月的回归测试有 1500 个用例,帮我分析趋势"——验证 Skill 在大规模场景下是否合理
4.2 检查 Skill 的"副作用"
Skill 是有副作用的——它会修改 AI 的行为模式。测试时注意观察:
- Skill 被激活后,AI 是否过度依赖这个 Skill?(比如所有对话都试图套用"回归分析"框架)
- Skill 的 allowed-tools 是否足够但不过度?(声明了 Bash 但不用,浪费;没声明 Read 却要读文件,报错)
- 多个 Skill 同时激活时,有没有冲突?(比如两个 Skill 对同一工具给了相反的用法指引)
4.3 让另一个 AI 来评估
笔者用一个笨办法:把 Skill 的 SKILL.md 扔给另一个 AI,让它"扮演测试评审员",给出评分:
评估以下 Skill 的质量:
1. 指令清晰度(1-10):描述是否明确、无歧义?
2. 边界完整(1-10):是否说明了什么不该做?
3. 工具声明准确性(1-10):allowed-tools 是否覆盖且不过度?
4. 示例丰富度(1-10):是否包含了正反示例?
只输出 JSON。
这个方法不精确,但能快速发现明显的遗漏。笔者写 regression-analyst 第一版的时候就用这个办法跑了一次,发现忘了声明 Glob 工具,Claude 没法搜文件目录,赶紧补上了。

五、现成资源:不用每次都从零开始
学会了怎么写之后,这些地方能帮你找到灵感或者直接拿来用。
-
Anthropic 官方仓库:github.com/anthropics/skills——四大类数十个 Skill(创意设计、开发技术、企业沟通、文档处理),其中开发技术类里的代码审计和自动化测试套件跟测试直接相关。
/spec目录是官方规范,/template是开发模板,复制即用。 - Awesome Claude Skills:chat2anyllm.github.io/awesome-claude-skills——社区维护的 Skill 合集,按功能分类,有评分和 GitHub Stars。
-
Claude Code 官方文档:code.claude.com/docs/zh-CN/skills——Frontmatter 完整参考(十几个字段,本文只用了核心的 3 个)、动态上下文注入(
!command语法)、Subagent 集成(context: fork)。 - Claude Code Skills 完全指南:www.heyuan110.com——中文圈写得最全的 Skill 教程,包含即用模板和与 CLAUDE.md/Hooks 的协同方式。
- 测试之家上的 10 款 Skills 合集:testerhome.com/topics/43765——狂师盘点,不想自己造的话先从这里挑几个试。
六、Skill 会走到哪?
Anthropic 把 Skill 规范做成了 agentskills.io 开放标准。现在支持这个标准的工具已经超过 40 个——Claude Code、Cursor、VS Code、GitHub Copilot、Gemini CLI,都在列。你写的 Skill 已经不是"Claude 专属",而是一种可以跨平台复用的测试资产。
笔者觉得这是个窗口期。现在测试圈缺的不是"会用 Skill"的人,是能针对测试场景写出高质量 Skill的人。你花两个小时写的 SKILL.md,可能成为一个团队的标准流程。
后记
上期 MCP 那篇发出去之后拿了 16 个赞,说明测试圈对"AI 工具实操"这个方向是有需求的。笔者琢磨了一下,这期不写"Skill 清单"——那种文章网上已经不少了。这期就聚焦一件事:从零开始写完一个 Skill,走通从需求到落地的全流程。
这篇从一个空文件夹开始,走完了"想清楚需求 → 设计指令 → 编写 SKILL.md → 安装测试 → 验证质量"的完整流程。关键不是这个 regression-analyst 本身有多厉害,而是你学会了这个方法论之后,可以给任何测试场景——接口测试、性能测试、安全测试、测试报告分析、测试数据构造——定制专属的 Skill。
荀子说"君子性非异也,善假于物也"——人类本性和猿猴没太大差别,区别在于我们善于借助工具。MCP 是工具,Skill 是工具,Claude Code 是工具。重点不是你手里有多少锤子,是你知道什么时候该用哪一把。