-
聊聊工程师的专业职级晋升之道 at October 19, 2021
挺中肯的文章,受教了。
-
使用 gitlab 的 webhooks 触发 jenkins 总是报错,但本地用 postman 直接调用 gitlab 的请求参数则可以成功触发 at October 19, 2021
-
微信小程序 UI 自动话 执行脚本 appium 报错 JSONWP error code 13 to UnknownError at October 19, 2021
我看日志,应该后面重试后成功了,现在这日志也看不出错误原因,建议再持续执行多几次,采集更多数据再分析定位吧。
-
Sonic 开源云真机测试平台开源啦! - 设计思路与背景(一) at October 19, 2021
加精了,期望后面更详细的分享。
-
「求助」Appium 通过命令行起两个服务,连两个 android,但有一个终端会连接失败,请问应该怎么解决? at October 19, 2021
error: more than one device/emulator
这个报错一般出现在连接了多于一台 android 设备上,运行 adb 命令时未明确设定设备的 udid 时。你看下你自动化脚本是不是没有指定 udid 给 appium ?
-
做测试工程师需要对 python 掌握到什么程度? at October 19, 2021
熟练这个定义确实比较虚,个人理解一般是能把变成思路直接转化成对应的代码,并且里面用什么函数之类的都清楚,不用各种搜索引擎辅助为佳。
放到面试考察这个场景:
如果是为了面试回答问题,可以去看看常见 python 面试题,把答案都弄懂。
如果是为了笔试,leetcode 选几个难度为低的,用 python 手写代码(不用 idea 辅助,也不搜索引擎查函数用法)试试,能做到手写出没 bug 能运行的代码应该也算。 -
Sonic 开源云真机测试平台开源啦! - 设计思路与背景(一) at October 19, 2021
http://testerhome.com/opensource_projects/sonic
这个我这边收到的你提交项目的地址,你看下是否有权限可以改?默认审核未通过前,是不会出现在列表中的。
-
原生态中 apk 如何定位下拉框的元素 at October 19, 2021
1、你看下评论框右下角的 排版说明 ,你的 markdown 排版格式不对,所以内容展示不了。
2、请按照 下拉框非下拉截图、下拉框非下拉状态的 xml 控件树、下拉框下拉截图、下拉框下拉状态的 xml 控件树 四个顺序来发吧,现在只有一个 xml 片段,一头雾水。 -
目前这样该不该离职呢?出去外面的世界看看? at October 18, 2021
1、匿名专区,所有发帖人 + 评论人,都是用的匿名账户,非真实账户。只是为了便于区分,避免大家误以为是同一个人在自问自答,所以从以前统一都显示为 匿名用户 ,改为了系统自动生成随机用户名。
2、如果想要非匿名,也可以勾选评论框的 “显示名字” ,这样系统就不会进行匿名处理。比如我这个评论,就是非匿名状态。 -
不同型号的 Android 机在同一界面获取到的节点元素问题 at October 18, 2021
还是没懂你这个场景。如果是做爬虫或者机器人点赞评论这类路径比较固定的自动化,完全可以走接口,没必要走 app?就算由于接口加密或者自研传输协议导致你无法走接口,那是否可以考虑按键精灵之类的直接录制脚本?分辨率不同布局不同,那就不同分辨率分别录一遍就可以了,安卓主流分辨率也就那几个,没多少成本。
UI 自动化的所有优化设计,都是围绕着 “控件操作” 来的,之所以要围绕这个,原因是为了降低多操作路径情况下的长期维护成本,提高控件的复用性。如果你本身操作路径就不多,直接录制回放投入产出比更高。
然后关于第三方 app 控件在不同设备上 id 不一样的,你确定用 resourceId 无法满足么?前面已经提了,你的 nid 本身不靠谱是根本原因,不要基于这个现象下 “同一个 app 在不同设备控件定位方式不通用” 这个结论。
-
刚入测试,在一家自研公司,主要是点点点,工作一年后是否可以跳槽? at October 18, 2021
只有你一个测试,意味着你对测试的认知很多都是来自于非测试的同学,这个会有点危险,会导致你容易存在 “你以为需要这个经验/技能,因此花大量时间准备学习,但实际大家需要的并不是这个” 这种思想误区,导致努力方向错误。
建议你不用等明年,现在立马就可以开始投简历面试下,能不能面到另说,但至少让你清晰你离自己心仪的工作还缺什么,方便自己做针对性提升,确保方向正确。
PS:如果能拿到 offer,建议去至少 30 人以上的测试团队,这样规模的团队一般都有人才梯队建设,对没经验的应届生更友好。不过对应的这类团队的招聘标准也比较高,面之前要好好做好准备。
-
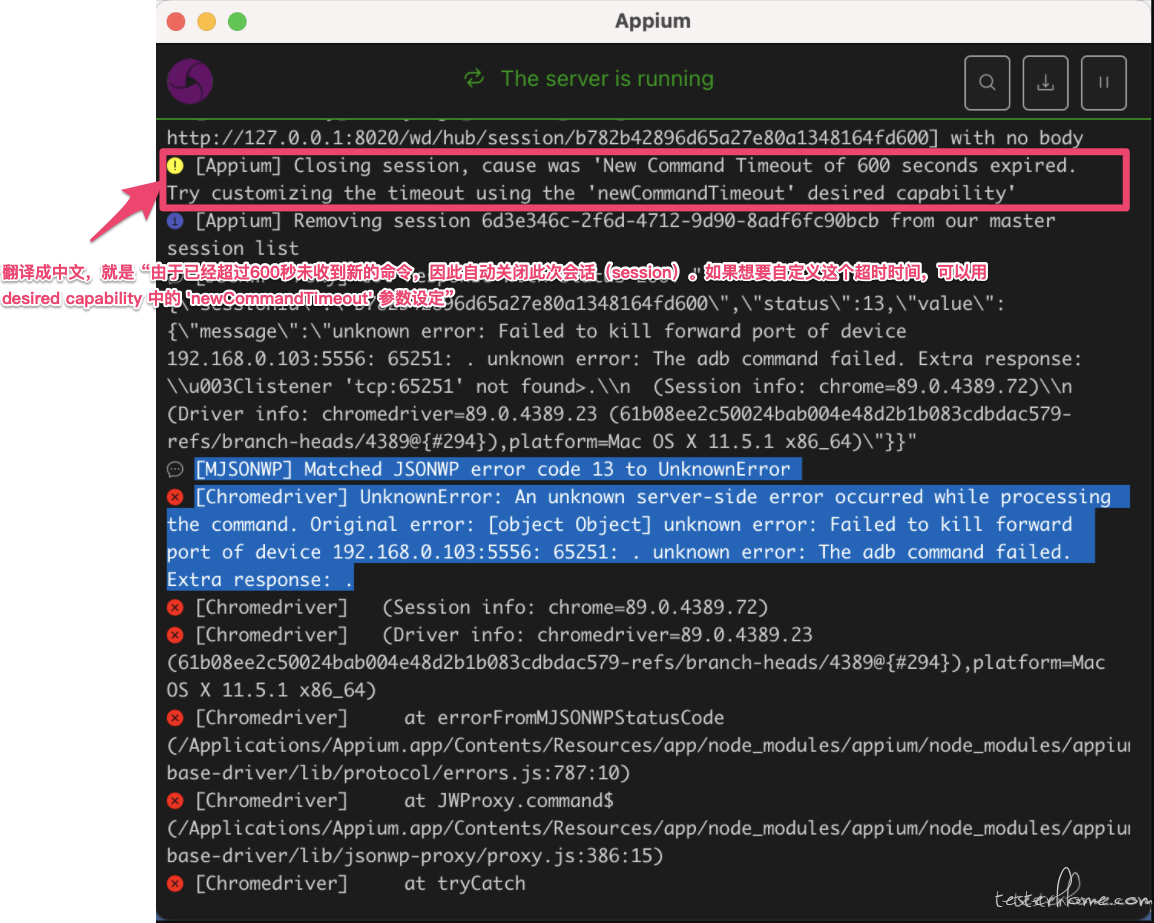
微信小程序 UI 自动话 执行脚本 appium 报错 JSONWP error code 13 to UnknownError at October 18, 2021
麻烦发下完整的 appium log 内容?你截图里的报错是 session 长时间没有收到新命令后,appium 服务自动关闭 session 时的报错,对应的并不是你第一个截图里的脚本操作,所以这个错和你那个脚本对应的执行内容没有关系。
-
接口做压测应该怎么判断? at October 18, 2021
测试人员应该有自己的判断,但这个判断是否可以变成团队决策进行执行,取决于整个团队的沟通结果。至于哪些做哪些不做,核心就是看出性能问题的风险和测试成本对比,同样是测试先判断,项目团队沟通决策后执行。
你这个例子里,你做出了你的判断,这个是好事。但只是一个开发人员说不用,你就放弃了,没有把你的判断推动到整个项目团队决策(产品 + 开发 + 测试),所以你这个放弃有点太轻易了。
-
不同型号的 Android 机在同一界面获取到的节点元素问题 at October 18, 2021
不知道你这个 nid 是怎么来的,但从截图里的值看,末尾的那个 6 位数字应该是内存地址的 hash 值,这个值不要说换设备,重启 app 都会变(只要重新 new 对象,内存地址就会变),所以不可能用来做控件定位。
然后你没有提你这里到底测试的,是自家 app 还是第三方的。如果是自家的,android 本身就提供给了 accessibility id 这个属性值供自动化专用(应该对应你截图里的 desc 属性值),和你的自定义 id 是一样的作用。如果是第三方的,个人想到的招只有先逐个适配,再找共通点尽量简化代码。参照 airtest 通过图像识别找控件也是一种方式,appium 也支持的。
同样你也没提到你的用途是做什么,如果是用于自动遍历,android 的返回完全可以直接用返回键,压根不用找控件。而其它控件,只要找到可点击的都去点一下,也可以满足?
-
根据业务说下项目的数据流程或者数据流向 这种面试题怎么回答? at October 18, 2021
我一般考的是某个核心接口背后的处理逻辑,比较期望的是看到用时序图来表达,用户的输入在各个模块之间具体是怎么处理和流转的。大部分情况下,时序图可以比较清晰表达各个模块/服务是怎么串起来完成完整业务逻辑的。如果发现本身被面试者没 get 到时序图这个,我会明确提一下建议用 uml 时序图。但如果明确说了时序图还是不知道怎么画,那就不强求用时序图了,能说到我能听明白也成,只是实际上大部分不会画时序图的,也很难给我讲明白逻辑。
不过楼主说的是 数据流程、数据流向 ,这个我就不大清楚了,比较少弄这个,但我估计应该也有对应的专业图类型的。个人经验,这种面试题,主要考察被面试者对自己测试系统背后逻辑的梳理归纳能力和经验,梳理归纳比较多的,一般也会需要用上相关的图便于清晰表述,因此也应该知道相关的图怎么画的,只是实际面试看,日常会做这种归纳的确实很少。
-
原生态中 apk 如何定位下拉框的元素 at October 18, 2021
先问下开发这个下拉框用的啥控件实现的?然后完整的下拉框下拉/非下拉状态对应的截图、xml 控件树都发上来?如果下拉和非下拉有差异,那基本上差异点应该就是你那个下拉框控件带来的了。
你现在提供的信息只足够说明有什么问题,提给手里有源码、可以调试应用获取更丰富信息的开发或者同团队测试专家是足够的。但对于我们这些对你的应用一无所知的外部同学,这些信息不足够定位和解决问题。
-
想请教大佬们,appium 能做 mac 客户端自动化吗? at October 18, 2021
目前看有支持,但还在 beta 版本:
https://appium.io/docs/en/drivers/mac/你可以试试?
-
测试部门技术分享 at October 18, 2021
是不是可以先列举下你们有什么课题可以分享的?以及你们对于这次分享,除了让这些同学听懂外,还有什么额外的目的么(比如期望推动大家 “质量不只是测试的事情” 这类思想上的转变)
这么问很难给到合适的建议,毕竟每个人能分享的课题都不一样。而要让大家看懂,关键不是课题本身,而是讲述者的水平。只有真正掌握到位,才能把一个内容讲得通俗易懂。
-
不同型号的 Android 机在同一界面获取到的节点元素问题 at October 17, 2021
对楼主说的这个现象,特别是现象 2,我只能想到研发是不同分辨率、不同设备用了不同的布局代码,但这个我觉得可能想很小(但凡对兼容多设备的布局有一些了解,都不会用这种维护成本这么高的方案),所以可以先去找研发沟通了解下,他们是怎么去做不同设备、不同分辨率下的布局兼容的?
另外,也希望楼主可以提供更多的信息,比如界面截图及布局信息之类的,这里信息脱敏太厉害,有点没看懂。
-
求推笔记本电脑,预算 6k-8k at October 17, 2021
需求不够全面吧,只有价格区间一个要求,电商网站按价格筛选就可以了,没必要问,所以应该背后还有隐藏需求。
楼主可以说下你电脑的主要用途(越具体越好,比如 android 开发,比单纯 写代码 要具体),和比较看重的一些指标(如续航、性能等)?
-
undo 问题修复思考 at October 16, 2021
很清晰的问题分析和技术方案选型说明你。好奇问下,最终选择了哪个方案?
-
关于 H5 测试的问题求助 at October 16, 2021
听楼主的说明,本质问题是 “改动点的影响开发也不是能评估到” ,即代码质量失控。本质问题不解决,你能做的只是把兜底做得更完善(比如用更多的回归用例兜底,最多加点自动化减少下人力成本),没办法真正减少工作量,而且也只会越做越累。
这类问题背后有可能是因为开发新接手不熟悉,也可能是本身架构设计不好太多共用,牵一发动全身。个人想到的几个解决方向,大方向还是测试要提高代码能力,倒逼和补充开发这个地方的短板:
1、联合开发做好 bad case 收集学习。正文里提到的这些曾经遗漏到线上的问题,都进行复盘,明确直接原因(代码改动点)和根本原因(为何会产生预期外影响但开发 + 测试都评估不到),以及制定落实优化措施(代码本身耦合度高的,提技术优化任务,进行重构优化;新人不清楚的,代码里补充好注释和写好项目代码介绍文档),持续提高这些容易出问题地方的代码质量。
2、经常出问题的部分项目,要求开干前做技术方案设计,测试参与到方案评审中。通过这个来倒逼开发做好设计方案,和评估好此方案的影响范围,思考好再开始写代码,降低风险。这个要去争取开发 leader 的支持,一般他参与评审,开发才会更认真进行设计,而且他把关质量才有保障。
3、提高自己的代码能力,去 review 开发代码,做到每一行改动都明确是在干嘛,和本次需求是否有直接关系,是否有连带影响其它位置。 -
WeTest 自助压测 1 折起,最低 1 分钱参与 Q 币抽奖 at October 15, 2021
压测礼包折扣挺吸引,但没找着对应的专栏文章呀,是还没发布?
-
[求助] 针对 web 端得安全测试 at October 15, 2021
不知道你这个安全测试的目的是啥,可以先说明下?这样才好划定范围给建议。安全的范畴很大的。
大部分专业的 web 端安全测试,大多是在做渗透测试,这块要求的技能比较多,一般得专业安全测试工程师才能做得来。测试工程师一般能做的,也就只是针对最常见的漏洞进行挖掘和测试,以及用一些第三方的安全扫描工具扫描下。比如 https://www.cnblogs.com/fundebug/p/details-about-6-web-security.html 里面提到的各种常见漏洞。
以前安全还有个 OWASP 组织,定期采集高危安全漏洞,并出一些报告和安全标准的,好像最近几年没怎么见到新消息。官网倒是有些可以参考的资料 http://www.owasp.org.cn/OWASP-CHINA/owasp-project/
-
求教【appium 自动化中如图这样的页面该如何定位】 at October 15, 2021
你这个不像是 UI 自动化测试的需求,更像是爬虫。遍历所有数据,并根据条件做不同的操作。
既然目的是遍历数据做操作,建议可以考虑换用爬虫的方式,从接口来抓取数据?效率更高、更稳定。