
前言
3 年前的时候写过关于一些大数据入门基础的文章, 当时学习的是 spark。 文章链接如下:
大数据介绍:https://testerhome.com/topics/7988
spark 基础操作:https://testerhome.com/topics/8040
shuffle 和性能测试:https://testerhome.com/topics/8120
离线大数据作业的测试方法:https://testerhome.com/topics/17092
这一篇算是弥补了之前对于流计算的缺失吧。 由于我们产品在今年加入了流计算的能力, 并且 Flink 貌似也有要在流计算领域中一统江山的架势,所以我前段时间借着调研混沌工程方案的契机,也开始学习了 Flink 并了解我们产品对于流计算的应用场景(PS:混沌工程是流计算中一个比较重要的测试手段)。 今天把学习和实践的一些总结分享出来。
什么场景需要流计算
流计算一般都是在一些数据计算的实时性要求很高的场景中出现, 之前在讲 spark 的时候都是基于离线的批处理计算的, 这种计算方式无法满足产品对实时性的要求。 比如如果我们要在大看板上计算 PV 和 UV 的数据, 一般都是希望能够实时的观看到这些数据的变化。 而计算 PV 和 UV 的操作又不好嵌入到业务系统中, 因为对业务侵入性太强并且会影响性能。 所以一般的架构可能是如下的样子:
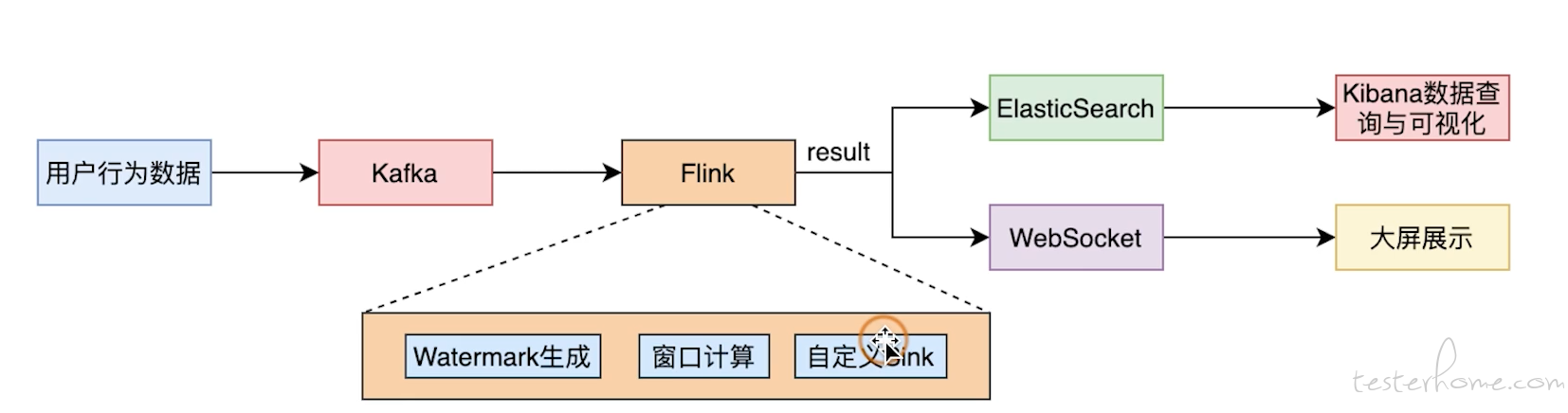
业务系统会将用户行为数据 push 到消息中间件 (kafka) 中, 这样达到了解耦和降低性能开销的目的。 而 flink streaming 服务会订阅 kafka 的 topic 进行流处理, 也就是一旦有数据从 kafka 中发送过来,满足一定条件后就会触发 flink 的一系列算子进行计算, 数据在 flink 中的这些算子中进行传递,聚合,计算等操作后, 将经过处理的数据推送给外部的存储系统或者业务系统, 这些系统会将数据做进一步保存和处理后展示在大屏上 -- 这就是一种计算 PV 和 UV 的简单的场景了。 整个过程之所以叫流,就是因为数据并不是像传统的方式保存到文件系统中,在保存到了一定的量或者利用定时任务触发批处理计算的方式执行。而是数据就像一条 pipeline(流水线) 一样,来一个 (或者一小批,可以规定时间窗口,可以规定数据个数) 就处理一个,并把处理结果传到 pipeline 的下一个算子上继续处理,这种方式是不是有点像 jenkins 的 piepline~ 实际上很多 AI 系统,比如推荐系统,反欺诈系统这些对实时性要求比较高的场景都要利用流计算来实时的进行处理。 如果要展开它的内部处理过程大概是下面这个图:

重点说明一下上图中的 task, 这个 task 就可以理解为 Flink 中的算子了, 也叫 operator。 在 Flink 中可以定义当数据到来的时候, 都经过哪些算子,按照什么顺序进行计算。 比如可以先试用 filter 算子把没用的数据进行过滤, 再使用 map 算子对原始数据做一些转换, 后面再使用 sum 算子进行累加计算出 PV。 当然这些 task 是可以并行计算的,Flink 可以合并计算结果。 要是写代码的话,大概是下面这个样子:

上面是大数据领域经典 demo workcount, 计算文件中的词频。 上面我用红色框起来的部分就是算子, 先是 flatmap 做一些处理, 再使用 keyBy 算子把数据分类, 把有相同的 key 的数据分到一个组里,然后进行 sum 的累加计算, 这样就能计算出每个 key(单词) 的词频了 (这个单词出现多少次)。 PS: 代码里的 keyBy(0) 中的 0 是数据的第几列, 意思是按第几列进行分组。
OK, 上面就是简单讲讲什么是流计算以及什么场景需要流计算。flink 的算子和运行模式跟 spark 是很像的,对 flink 的使用还有疑问的同学可以看看我之前写的 spark 基础。 下面要开始讲测试点了。
从消息中间件说起
好像现在业界主流的能支持流计算的消息中间件也就只有 kafka 了,所以我下面都用 kafka 来举例 (实际上我也只用过 kafka,请原谅我知识上的匮乏),这里我要讲一下 kafka 的精准一次性语义, 之所以讲这个是要开始讲述流计算中最重要最难以验证的一个场景(对,我就是想先讲难的,重要的 )---- 数据一致性。 什么是数据一致性呢,就是不论在任何情况下数据被处理的结果都是一致的。 这里说的任何情况包括但不限于:
)---- 数据一致性。 什么是数据一致性呢,就是不论在任何情况下数据被处理的结果都是一致的。 这里说的任何情况包括但不限于:
- 计算任务异常重启后导致之前已经计算过的数据丢失
- 计算任务异常重启后导致之前已经计算过的数据在本次任务进行重试的时候造成的数据重复计算
- 计算任务不能因为网络延迟,异常等因素导致数据传递给下游系统失败后导致的数据丢失
那么我们看 kafka 是怎么处理这种情况的, 当我们使用 kafka 的 producer 向 broker 推送消息的时候,怎么能保证本次推送的消息不会因为各种异常导致数据丢失呢? 很多小伙伴可能已经想到了重试, 如果因为网络异常等原因导致 push 请求异常的话,那么我们重试几次就好了,毕竟 kafka 开了高可用模式,集群上会有其他的 broker 提供服务,就算当前的 broker 彻底跪了数据也不会丢失的。 但是我们是否想过一个问题,重试请求是可以随便执行的么? 或者说程序怎么能确定本次失败的推送请求就是真的失败了,也就是数据没有保存到 kafka 上。 在 kafka 中确认消息是否推送成功是需要 producer 和 broker 互相交换 ACK 的, 也就是 producer 在把消息推送给 broker 后,broker 在保存成功后要给 producer 回一个 ACK 让 客户端知道消息已经保存成功了。 那么如果我们的异常是发生在 broker 已经保存好数据和把 ACK 发送到客户端之间呢? 也就是数据已经保存好了, 只是没有给客户端返回 ACK,所以客户端认为这个推送消息的请求是失败的。 那么这个时候如果我们执行了 retry 的逻辑,实际上数据就出现了重复的场景。
这么解释大家是不是就明白了 retry 的逻辑不是能随随便便加的,它有一个前提条件, 就是它要 retry 的那个接口必须是幂等的。 这个我再当初讲混沌工程的时候也提过, 一个高可用的系统,它的接口必须是幂等的, 因为高可用的模式说白了就是上游系统 retry,下游系统多副本负载均衡 + 幂等。 只有下游系统有幂等的能力,上游系统才敢执行重试操作, 否则的话就是数据重复写。 那么幂等是什么意思呢, 大白话就是接口自己能判断出当前的请求是不是之前已经发送过的重复数据了,如果是重复数据它是不处理的。 行话就是同样的数据不论计算多少次都不对结果造成影响,此为幂等。
而 kafka 的精准一次性语义中定义了几个级别的模式, 其中有一个叫 exactly once(精准一次性语义,意思是我保证针对一个数据不管你重复发送多少次,服务端都只计算一次) 这种模式就可以解决这个问题。 在 producer 中可以设置幂等和分布式事务相关的参数和代码, 一旦这样设置了,那么就拥有了幂等属性, kafka 内部会根据算法计算出消息的唯一 id,broker 只要查询消息的 id 在之前是否有保存过就可以判断出当前消息是否是重复数据了 (大概是这样,细节没研究过)。 这样客户端就可以肆无忌惮的进行重试而不必担心数据重复计算。
再谈 Flink 的 exactly once
通过讲述 Kafka 的精准一次性语义也就是 exactly once 是为了跟大家讲述什么是数据一致性以及保证数据一致的方法和重要性。 由于 kafka 本身提供了这种特性所以要保证消息传送到 kafka 的数据一致性是比较容易的, 正因为很容易一般不容易出错所以很多团队都忘了去测试这个场景(有时候研发会忘了设置这个参数导致出现 bug,所以最好还是需要测一下)。 当时光保证 kafka 的精准一次性是不行, 我们是一个业务场景, 我们需要的是端到端的一致性, 得是全链路的一致性。 所以现在我们来看看 Flink 这一层怎么做的 exactly once。
Checkpoint
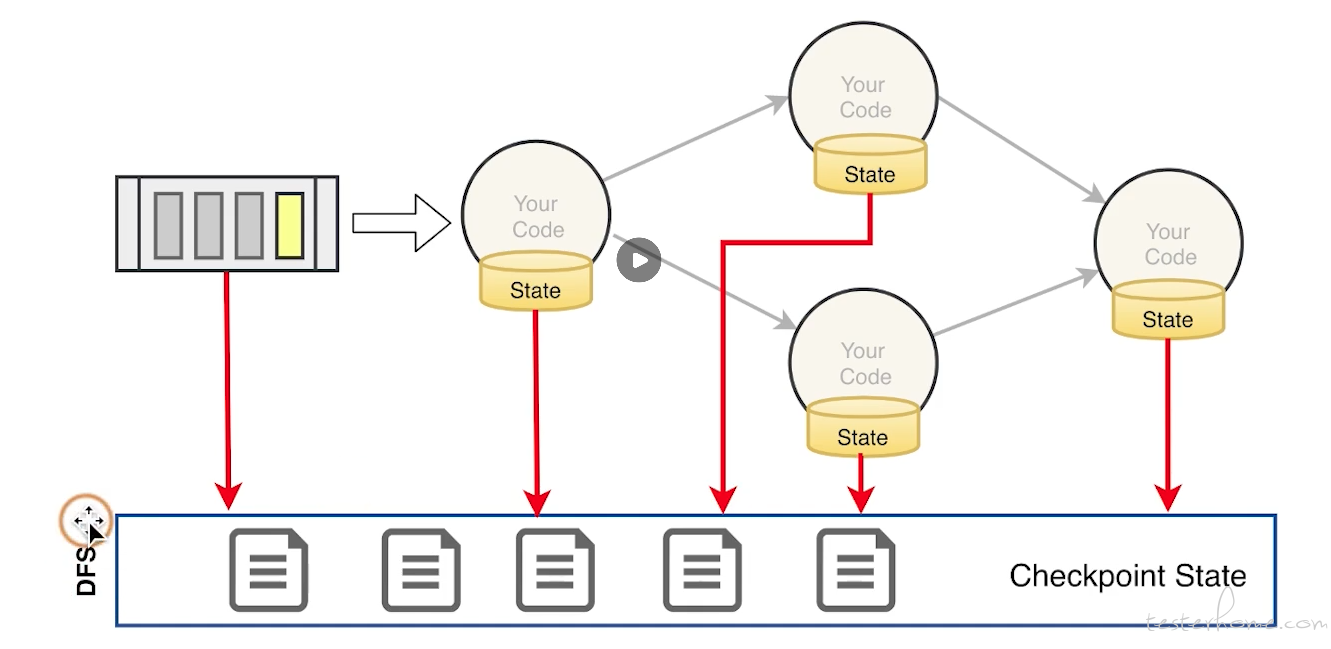
讲到这里就必须要说明一下大名鼎鼎的 checkpoint 了, 基本上 checkpoint 是所有分布式框架都要有的机制,spark 如此 flink 亦如此。checkpoint 就是一种保存我们在计算过程中的数据的方式, 它会根据设置周期性的触发 checkpoint 来保存我们计算的中间结果。 我们还是用 PV 的案例说明:
我们从 Kafka 读取到一条条的消息,从消息中解析出 app_id,然后将统计的结果放到内存中一个 Map 集合,app_id 做为 key,对应的 pv 做为 value,每次只需要将相应 app_id 的 pv 值 +1 后 put 到 Map 中即可。

这里简要说明一下 kafka 的 offset, 这个是消费消息的客户端也就是 consumer 要使用 offset 来记录我已经读取到了消息队列中的哪一条数据, 根据这个 offset 我可以知道下一次我要读取的消息的位置。 即便是程序崩溃了, 只要 offset 能够保存下来就知道恢复后应该从哪个消息开始读取了。 所以在这个机制下,flink 的 Source task 记录了当前消费到 kafka test topic 的所有 partition 的 offset。 所以 flink 会根据策略周期性的触发 checkpoint 事件以流的方式传递给所有的算子, 算子收到 checkpoint 命令后就会把中间状态保存起来, 比如在我们的案例里保存的就是 kafka 的 offset, 比如我们设置每 30s 触发一次 checkpoint, 那么 30s 后 checkpoint 触发,保存的数据为:
chk-100
offset:(0,1000)
pv:(app1,50000)(app2,10000)
该状态信息表示第 100 次 CheckPoint 的时候, partition 0 offset 消费到了 1000,pv 统计结果为(app1,50000)(app2,10000)。 那么如果任务挂了,这时候怎么办?比如:
- 假如我们设置了三分钟进行一次 CheckPoint,保存了上述所说的 chk-100 的 CheckPoint 状态后,过了十秒钟,offset 已经消费到(0,1100),pv 统计结果变成了(app1,50080)(app2,10020),但是突然任务挂了,怎么办?
- flink 只需要从最近一次成功的 CheckPoint 保存的 offset(0,1000)处接着消费即可,当然 pv 值也要按照状态里的 pv 值(app1,50000)(app2,10000)进行累加,不能从(app1,50080)(app2,10020)处进行累加,因为 partition 0 offset 消费到 1000 时,pv 统计结果为(app1,50000)(app2,10000)。
上面讲的并行度为 1 的情况, 那么如果并行度是 N 的情况,checkpoint 会在并行的算子里触发,这个时候 Flink 会选择是保持多个 checkpoint 一起执行完后在统一往后运算 (exactly once), 还是选择不去协调,任意一个算子运行完 checkpoint 后就当前线程就继续往下运算 (at least once),因为 at least once 模式会造成并行的算子的 checkpoint 不是同时触发和结束, 所以他们保存的中间态数据有偏差,也就是数据是会不一致。所以如果业务场景有数据强一致性的需求,那么需要将 checkpoint 模式设置为 exactly once。 这里大家能明白了么? 我们通过把 kafka 的 offset 和我们已经计算好的结果都通过 checkpoint 进行保存来防止数据丢失或重复计算的情况。 代码差不多如下:
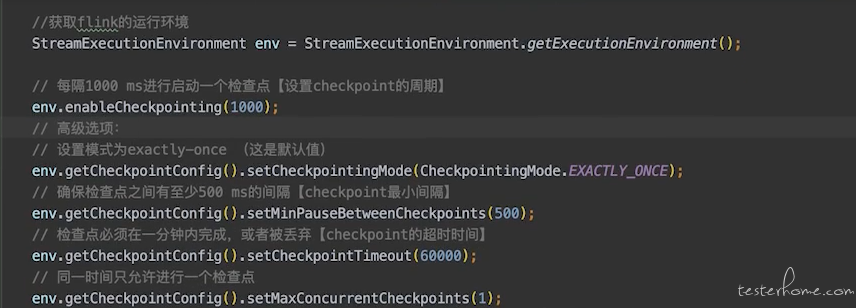
当然上面是 checkpoint 策略, 在实际开发算子任务的时候,要把什么数据通过 checkpoint 保存到 flink 的 state backend 是需要研调用对应的 state 方法来执行的。
贴一个 checkpoint 的图:
说回数据一致性
好了上面说了那么多东西, 但是好像 kafka 和 Flink 都已经把数据一致性保证好了, 那还需要我们测试什么一致性么? 那不是变成了在测试 kafka 或者 flink 么? 我想一定会有同学这么问, 那么我在这里解释下:
- 即便 kafka 和 flink 有 exactly once 语义, 但是开启这些语义需要对应的参数调整, 并且需要编码的时候进行处理, 比如 kafka 里在开启了 exactly once 语义后, 也需要研发在代码里显示调用分布式事务进行数据计算, flink 里对于 kafka 的 offset 和计算结果的保存也需要显示在代码里调用类似 valueState 来进行保存和处理。 也就是你们的产品研发同学是否编码正确决定了数据一致性。
- 在我们的流计算里, flink 上下游都会对接不同的系统, 上游可以是 kafka,也可以是业务系统暴露出来的 socket 服务,也可以其他的源。 所以你在使用非 kafka 也就是没有 exactly once 语义支持的系统的时候,就需要研发去开发相应的方案来解决这个问题。 同理输出放, 流是有数据的源,也有在经过 flink 计算之后输出的系统,这个系统可以是另外一个 kafka,也可以是 mysql, 也可以是业务系统的接口。 那么输出方是否有 exactly once 语义支持呢? 非 kafka 的场景下,基本上也是没有的, 也需要研发来开发对应的方案。 也就是说我程序中 Flink 的 CheckPoint 语义设置了 Exactly Once,但是我在计算的过程中需要实时的把计算结果保存到 mysql 里,那异常出现的时候根据 checkpoint 机制,我们从上一个 checkpoint 记录中保存的 offset 去重新读取并计算消息, 这时候我的 mysql 中看到岂不是看到了数据重复了?比如程序中设置了 1 分钟 1 次 CheckPoint,但是 5 秒向 mysql 写一次数据,并 commit。 所以我们要求的是 Flink 的 end to end 的精确一次都必须实现。如果你的 chk-100 成功了,过了 30 秒,由于 5 秒 commit 一次数据库,所以实际上已经写入了 6 批数据进入 mysql,但是突然程序挂了,从 chk100 处恢复,这样的话,之前提交的 6 批数据就会重复写入,所以出现了重复消费。Flink 的精确一次有两种情况,一个是 Flink 内部的精确一次,一个是端对端的精确一次。 这里面有点绕,我解释的有点啰嗦。
所以根据上面说的,虽然 flink 提供了 exactly once 语义, 但是它的 exactly once 语义只保证 flink 自己的数据计算过程,而不是端到端的。 想要保证数据一致性,还是需要研发同学针对业务场景进行特殊的设计。也就是开发自己产品的 exactly once 语义。 所以我们还是要针对端到端的场景进行测试。
测试的注意事项
- 首先弄清楚产品中流计算的架构,都有哪些数据源,数据又发送到哪些地方。 这一步至关重要, 因为端到端的数据一致性场景,在这一条流式链条里,任何一个点没有做到精准一次性语义都会导致数据不一致,所以我们要测试所有的点。
- 完成第一步后在每一个点进行故障注入,故意让任务失败,让服务挂掉, 属于混沌工程式的测试方法, 就是想尽办法让这个流式的链条中的服务出故障来验证数据一致性。 没有测试工具的同学可以去看一下阿里开源的 chaos blade。 注意: 一个场景的故障注入要反复进行,比如 30 分钟内每隔 3 分钟都随机找到一个 flink task manager 进行 kill 来注入故障, 有些时候只注入一次故障是发现不了 bug 的,因为我们是有状态计算,有状态计算的场景很多是在特殊的状态下发生故障才会出错。 所以要反复注入故障来最大概率的触发 bug。
- 自动化测试中 case 要验证数据一致性的点,比如在 kafka->flink-mysql 的这个场景里,你往数据源 kafka 里灌入了 1000 个消息,如果正确的逻辑是经过计算后要往 mysql 存入 10 条记录, 那么你要去验证这 10 条记录的正确性。 是否有数据丢失或者重复的结算结果出现。
注意: 做这个测试前, 先确定你们是否有数据一致性的强需求。 有些场景真的会觉得数据丢了就丢了。。。。。
结尾
好了写这么多, 今天罗里吧嗦的写了一大堆好像就说了一个数据一致性的测试。 之前在社区跟人讨论的时候,有很多同学其实不赞同这种深入研发架构的测试方式。 而我前两天刷脉脉的时候也在匿名区看到有人发消息, 讨论区里对 qa 是否要测试这种场景有很大的争议。 所以我花了很大的篇幅解释一下做这种测试的必要性。 下次我们将其他的测试方法。

