其他测试框架 测试开发之路--Spark 之旅 (三):Shuffle 以及性能测试初探
背景
今天我们来讲讲 Spark 比较核心的概念--shuffle,但是在讲 shuffle 之前我们需要先了解一下 key:value 形式的 RDD,因为只有这种 RDD 才会触发 shuffle 操作。上一篇帖子我们知道了 RDD 的概念并做了一些实验。但基础的 RDD 并不具备结构性。所以今天我们来看看 Key:Value 形式的 RDD 是如何操作的。为了方便,我们下面都称做 pair 的 RDD
如何创建一个 Pair 的 RDD
我们有很多种方式创建一个 pair 的 RDD,为了我们演示方便,我们使用在已有的 RDD 中使用 map() 方法来创建一个 RDD 的方式。如下:
rdd4 = sc.parallelize(['age 29', 'count 3', 'age 33', 'count 55'])
D = rdd4.map(lambda x: (x.split(" ")[0], x.split(" ")[1]))
D = rdd4.map(lambda x: (x.split(" ")[0], x.split(" ")[1]))
我们运行代码得到的结果如下

map() 的特点是可以改变返回的类型。例如上面的 demo,我们通过字符串的 split 把每一行进行切分,返回一个元祖。这样 spark 就会把数据处理成 pair 的 RDD 了。
transformation
reduceByKey
pair 的 RDD 拥有所有基础 RDD 的方法的同时,也提供了一些专有与它自己的函数。 例如我们最常用的 reduceByKey(), 没错在这里它是 transformation。不要觉得它带了一个 reduce 就是 action 了。reduceByKey 的作用是按 key 把所有行分类并对相同 key 值的 value 进行聚合计算。看下面这个例子:
rdd5 = sc.parallelize(['book', 'map', 'book', 'map', 'map'])
rdd5.map(lambda x: (x, 1)).reduceByKey(lambda x, y: x + y).foreach(print)
上面的代码是一个统计词频的 demo。分别计算了出现 book 和 map 的次数。首先我们使用 map() 创造一个 pair 的 RDD,key 就是这个单词自己,value 就是 1。 之后使用 reduceByKey 会聚合所有 key 值相同的 value 并做累加计算。结果如下:

mapValues
有些时候我们只想操作 value,key 需要保持不动。 所以 map 这个函数就略显尴尬。 这时候 mapValues 的出现刚好满足我们的需求。
rdd5 = sc.parallelize(['book', 'map', 'book', 'map', 'map'])
rdd5.map(lambda x: (x, 1)).mapValues(lambda x: x+1).foreach(print)
还是上面统计词频的例子,这一次我们注释掉 reduceByKey。使用 mapValues 控制每一个 value 并做 +1 操作。然后我们打印出来就会发现每一个 value 都被加了 1. 结果如下:
groupByKey
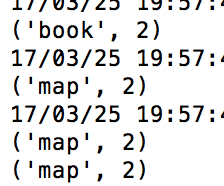
有些时候我们希望把所有 key 相同的行聚合在一起。例如我们想看某一个用户所有的记录。这时候 groupByKey() 是个很好的选择。它会把 key 相同的行聚合在一起组成一个 Iterable 对象。 如下:
rdd6 = sc.parallelize(['book', 'map', 'book', 'map', 'map'])
rdd6.map(lambda x: (x, 1)).groupByKey().foreach(print)
运行结果如下:

可以看到 groupByKey 把所有 key 为 book 和 map 的行聚集在一起,并组成了 Iterable 对象。
join
在我们操作数据库的时候,经常有 join 操作。 如果我们想 jion 两个 RDD 的话也是可以的。如下:
rdd1 = sc.parallelize(['1 A1', '2 A2', '3 A3', '4 A4'])
rdd2 = sc.parallelize(['1 B1', '2 B2', '3 B3', '4 B4'])
A = rdd1.map(lambda x: (x.split(" ")[0], x.split(" ")[1]))
B = rdd2.map(lambda x: (x.split(" ")[0], x.split(" ")[1]))
pairs = A.join(B)
pairs.foreach(print)
我们看看打印的其中一行:

这个例子中我们的 key 就是 1,2,3,4 这些序列。然后我们看到上面的截图我们的 RDD 变成了 A2,B2 这样的行。join 操作已经按 key 把这两个 RDD 拼接到了一起。
action
我们也有一些常见的 action 可以用。例如 countByKey:
rdd7 = sc.parallelize(['book', 'map', 'book', 'map', 'map'])
temp = rdd7.map(lambda x: (x, 1)).countByKey()
print (temp)
运行结果如下:
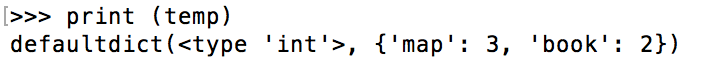
更多的 pair RDD 操作大家去查看官方的 API 文档吧。
partition
我们再来说一说 partition 的概念,RDD 是由众多 paritition 组合而成的,我们第一章曾经介绍过。spark 在读取数据的时候会按一定规则 (例如每个 partition128M) 把数据读取到多个 partition 上去。严格来说 partition 是一个逻辑概念,是 spark 组织数据的方式。我们对 RDD 的操作实际上也是对众多 partition 的操作。
Shuffle
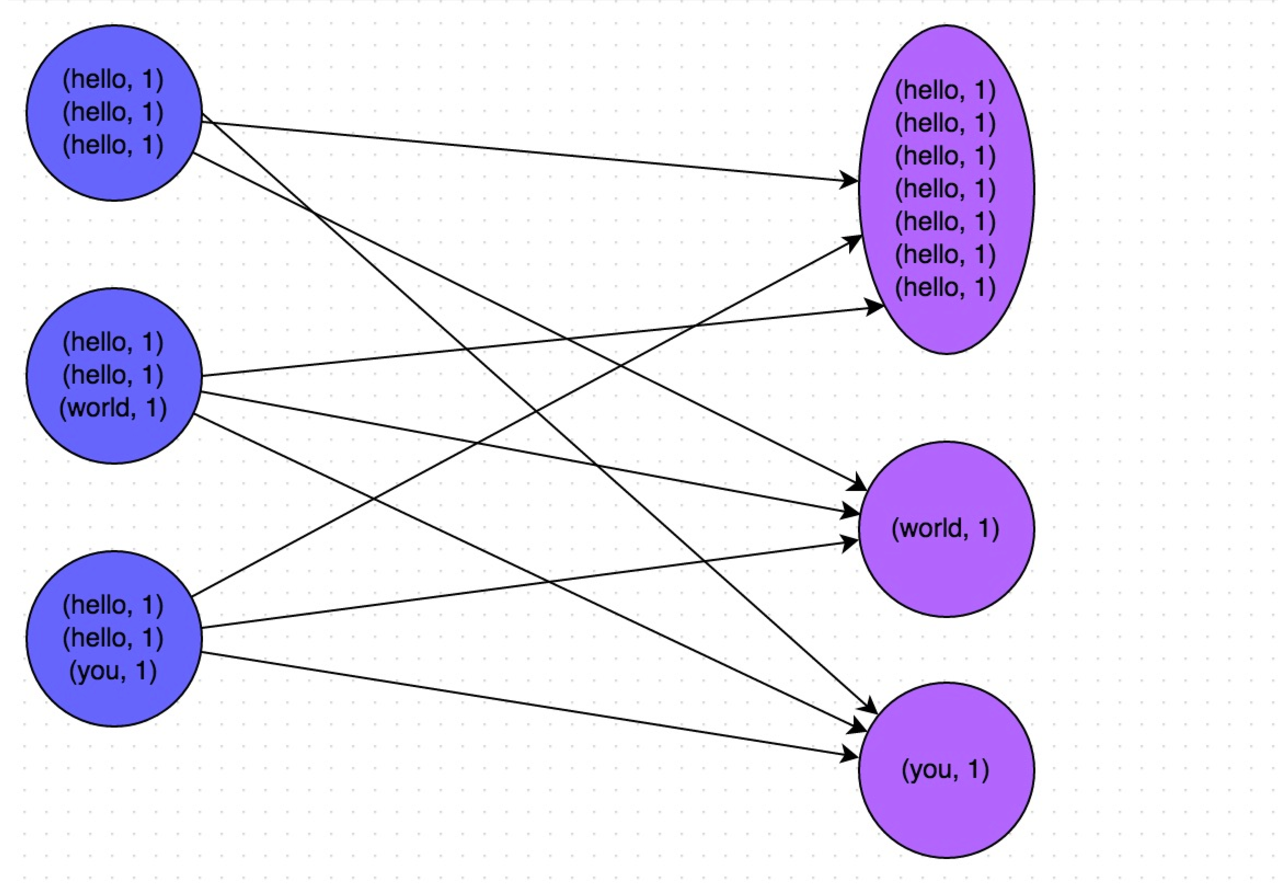
现在我们讲一个很重要的概念--shuffle,这是从 MapReduce 时代就开始的分布式计算独特的设计理念。 理解好 shuffle 的原理对学习 spark 是至关重要的。Shuffle 中文翻译为 “洗牌”,需要 Shuffle 的关键性原因是某种具有共同特征的数据需要最终汇聚到一个 partition 上进行计算。为什么要这么做呢? 因为对于一个分布式计算框架来说,网络通信的开销是十分昂贵的。假设我们有一千个计算节点在并发的执行一个计算任务。它们要聚合,计算,统计。数据在这一千个节点之间流动会造成相当大的网络负担。所以 spark 的设计者们为了减少网络开销而设计了 shuffle。它的原理就是尽量把一个计算任务所要处理的所有数据都聚集在一个 partition 上,这样就节省了很多的网络开销。 例如我们今天学到的 groupByKey() 聚合操作,spark 一旦执行到这一步的时候,会把所有 key 相同的数据分配到同一个 partition 上以供后续操作。例如 key 为 A 的行分配到 X 节点进行计算,key 为 B 的行分配到 Y 节点进行计算,这样在之后的计算中就免去了网络开销。而这个过程就是 shuffle。所谓洗牌就是这个意思了。可以参考下图:
task,stage 和 job
知道了 partition 和 Shuffle 后,我们来聊聊 spark 的运行机制。
job
所谓一个 job,就是由一个 rdd 的 action 触发的动作,可以简单的理解为,当你需要执行一个 rdd 的 action 的时候,会生成一个 job
stage
stage 是一个 job 的组成单位,就是说,一个 job 会被切分成 1 个或 1 个以上的 stage,然后各个 stage 会按照执行顺序依次执行。至于 job 根据什么标准来切分 stage 呢? 简单的说是以 shuffle 和 result 这两种类型来划分。 在 Spark 中有两类 task:
- shuffleMapTask:输出是 shuffle 所需数据, stage 的划分也以此为依据,shuffle 之前的所有变换是一个 stage,shuffle 之后的操作是另一个 stage
- resultTask:输出是 result,比如 rdd.parallize(1 to 10).foreach(println) 这个操作没有 shuffle,直接就输出了,那么只有它的 task 是 resultTask,stage 也只有一个;如果是 rdd.map(x => (x, 1)).reduceByKey(_ + _).foreach(println), 这个 job 因为有 reduceByKey,所以有一个 shuffle 过程,那么 reduceByKey 之前的是一个 stage,执行 shuffleMapTask,输出 shuffle 所需的数据,reduceByKey 到最后是一个 stage,直接就输出结果了。如果 job 中有多次 shuffle,那么每个 shuffle 之前都是一个 stage
- task:task 就是 stage 下的一个任务执行单元,一般来说,一个 rdd 有多少个 partition,就会有多少个 task,因为每一个 task 只是处理一个 partition 上的数据。
如果我们把任务提交到集群上,是可以通过 SparkUI 来观察我们的 job 的。如下图:
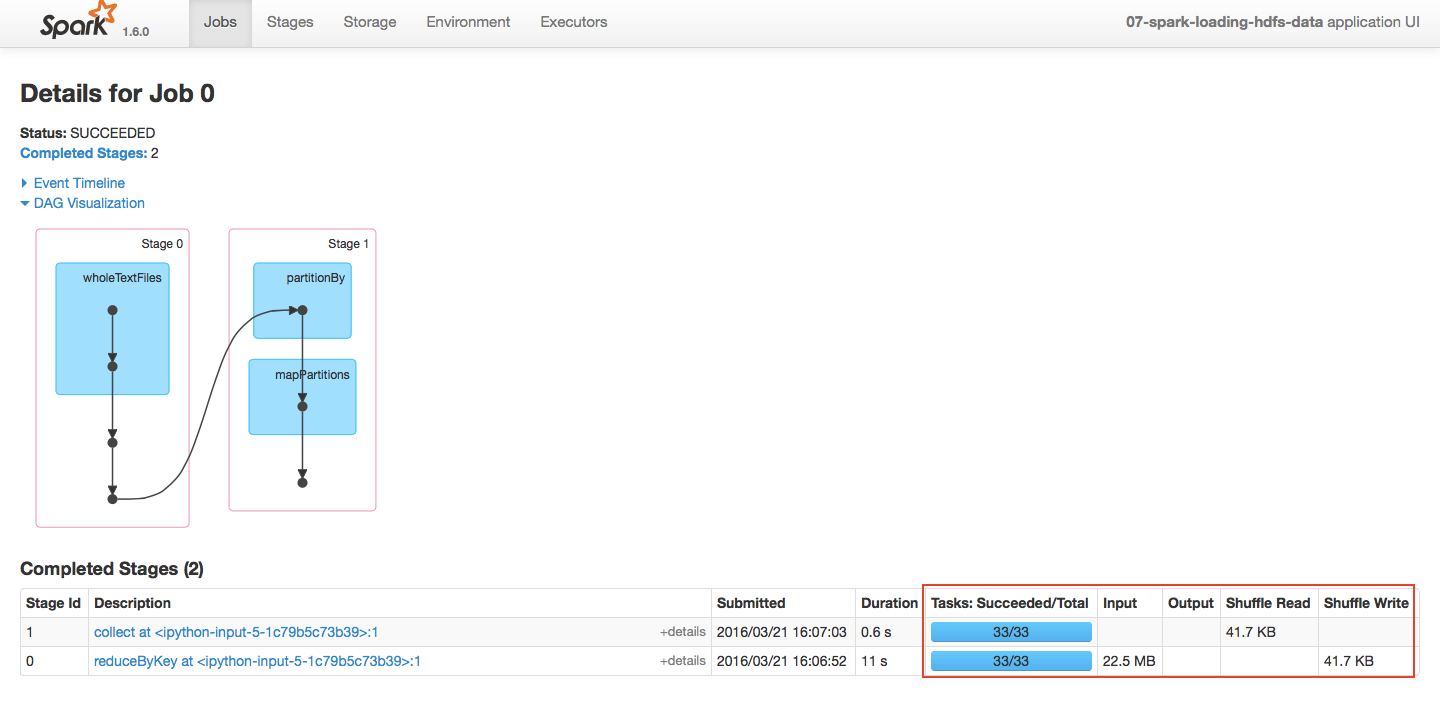
可以看到 reduceBykey 触发了一个 shuffle 所以划分了 stage。
数据倾斜
我们了解了 shuffle 相关的概念和原理后其实可以发现一个问题,那就是 shuffle 比较容易造成数据倾斜的情况。 例如上面我们看到的图,在这批数据中,hello 这个单词的行占据了绝大部分,当我们执行 groupByKey 的时候触发了 shuffle。这时候大部分的数据 (Hello) 都汇集到了一个 partition 上。这种极端的情况就会造成著名的长尾现象,就是说由于大部分数据都汇集到了一个 partition 而造成了这个 partition 的 task 运行的十分慢。而其他的 task 早已完成,整个任务都在等这个大尾巴task 的结束。 这种现象破坏了分布式计算的设计初衷,因为最终大部分的计算任务都在一个单点上执行了。所以极端的数据分布就成为了机器学习和大数据处理这类产品的劲敌,我跟我司的研发人员聊的时候,他们也觉得数据倾斜的情况比较难处理,当然我们可以做 repartition(重新分片) 来重新整合 parition 的数量和分布等操作,以及避免或者减少 shuffle 的成本,各家不同的业务有不同的做法。在做这类产品的性能测试的时候,也跟我们以往的互联网模式不同,产品的压力不在于并发量上,而在于数据量和数据分布上。所以我司才有了造数项目 ---- 专门创造各种不同的数据以满足性能测试的需求。而我当初学习 spark 的初衷,也是为了能参与到这个造数项目中。在这个 spark 系列教程的尾声的时候,我也会介绍一下这个造数工具的基本原理。讲一下它是如何利用 spark 来造出上百亿行的不同分布的数据。
性能测试
就如刚才说的, 测试这种产品就不再是使用 tcp copy, jmeter 等等这种工具去模拟线上用户并发来进行测试了。 而是用造数工具来创造各种不同量级,不同分布的数据进行测试。例如我们做以下的场景假设:模拟 2 月 14 号前两天的购物情况,这几天在网上购物的大部分为男性且购买用户量剧增,购买商品大多为巧克力,鲜花等商品。所以我们假设创造 1 亿行的购买记录,其中男性占 80%,女性占 20%。 鲜花类商品占 60%,巧克力类产品占 30%,其他商品 10%。 我们把这批数据输入到产品中以观察在这种会产生数据倾斜的场景中,产品的性能变化。 其实这个造数工具就相当于我们之前的 Jmeter 这类的模拟工具。 只不过我现在模拟的不再是用户并发量。而是线上数据量和数据分布。当然我们认为直接使用线上真是的数据效果是比较好的,就如我们以前直接将线上流量 copy 到测试环境一样。只是有些时候我们是不被准许接触线上数据,或者线上数据无法满足我们的测试需求 (例如极端数据分布)。所以我们依然还是需要造数工具的。至于性能测试的分析,就可以根据 SparkUI 上对于 Job,stage 和 task 的描述获得很多信息。我们可以了解整个任务划分了多少次 shuffle,分了多少 partition。哪个 task 运行的慢等等。
总结
恩,今天我们得以窥见另一种性能测试的形式。其实说到底并没有特别大的变化。 无非是从模拟并发变成了模拟数据。从 Jmeter 这类的工具变成了造数工具。SparkUI 提供的任务分析功能反而能更好的让我们去分析运行缓慢的 task。这比我们之前的性能测试方便很多。 只不过我们没有造数的开源工具,需要自己写一个。所以才感觉门槛上去了。