每一次有自动化的新工具问世,就有一堆人会说啊呀呀呀,测试要失业了。几天前 AppAgent 出来时,嗅觉灵敏的自媒体就开始搬运,然后剑锋直指测试工程师,于是咱们又失业了一次。因为团队内部对应用自动化测试也有诉求,所以第一时间就在自己电脑上跑起来看看。
安装步骤
安装很简单,我用的是 Windows 11 64bit,android 环境已经装好(其实只要装了 adb 就可以了),python 环境也安装好了(我的 python 环境用的是 conda,大家可以自行百度)。然后把代码下载下来,pip install -r requirements.txt 安装好依赖就可以用了。
英语好的,直接看 https://github.com/mnotgod96/AppAgent。
运行前配置
其实就是因为他用了 openAI 的 gpt-4-vision-preview 模型,所以咱们必须得有 openAI 的收费账户,然后拿到对应的 OPENAI_API_KEY。对应 AppAgent 的配置文件 config.yaml
...
OPENAI_API_BASE: "https://api.openai.com/v1/chat/completions"
OPENAI_API_KEY: "sk-xxxx" # Set the value to sk-xxx if you host the openai interface for open llm model
OPENAI_API_MODEL: "gpt-4-vision-preview" # The only OpenAI model by now that accepts visual input
...
这些参数会在 model.py 里调用,
ask_gpt4v 方法:这个方法是和 openAI 交互的方法
def ask_gpt4v(content):
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {configs['OPENAI_API_KEY']}"
}
payload = {
"model": configs["OPENAI_API_MODEL"],
"messages": [
{
"role": "system",
"content": content
}
],
"temperature": configs["TEMPERATURE"],
"max_tokens": configs["MAX_TOKENS"]
}
response = requests.post(configs["OPENAI_API_BASE"], headers=headers, json=payload)
print_with_color("resp: ", response)
if "error" not in response.json():
usage = response.json()["usage"]
prompt_tokens = usage["prompt_tokens"]
completion_tokens = usage["completion_tokens"]
print_with_color(f"Request cost is "
f"${'{0:.2f}'.format(prompt_tokens / 1000 * 0.01 + completion_tokens / 1000 * 0.03)}",
"yellow")
return response.json()
从 openAI 回来的数据会在 parse_explore_rsp 里进行解析,我感觉这个方法是最重要的,它利用 openAI 的 Thought/Action/Action Input/Observation 机制,对结构化的返回进行解析。很多这种 agent 其实都是基于这个机制,openai 的这块做的比较好,每次都能按照这个模式来给你返回,所以目前来说插件体系啥的也只有 openai 的搞起来了(From 挺神)。这里也挺有意思的,本来我想 openAI 太贵,AppAgent 调用一次,0.02 刀的样子,想换成阿里云的通义千问,翻了一遍文档,似乎没有 Thought/Action/Action Input/Observation 机制,这个我不专业,有懂的同学可以指正下。
所以这里话又说回来了,你还得花这个 openAI 的钱,否则你得大改 APPAgent 的代码。

运行
运行很简单,按官方文档,先 learn 再 run。我这里拿 CSDN 做例子,先在手机上把 CSDN 打开,然后执行 python .\learn.py

这里我选 human demonstration,autonomous exploration 没时间跑。在终端输入 2,回车,就会进入下一步:
What is the name of the target app?
CSDN
Warning! No module named 'sounddevice'
Warning! No module named 'matplotlib'
Warning! No module named 'keras'
List of devices attached:
['42954ffb']
Device selected: 42954ffb
Screen resolution of 42954ffb: 1440x3216
这里会通过 adb 命令,把设备信息拿回来。APPAgent 里自己封装了 adb 命令,比如点击就是用的 adb shell input tap 坐标,比较原始(我一开始以为会封装个啥 Appium 之类的),在文件 and_controller.py 里。这些信息打印好之后,会立刻让你输入你后面动作的描述。这里我就写 “search for testerhome”,然后回车,就会弹出一个界面来。
Please state the goal of your following demo actions clearly, e.g. send a message to John
search for testerhome
(然后回车,就会弹出一个界面来,看英语说的,红色的是可以点击的,蓝色的是可以滚动的,看下面这个图。)All interactive elements on the screen are labeled with red and blue numeric tags. Elements labeled with red tags are clickable elements; elements labeled with blue tags are scrollable elements.
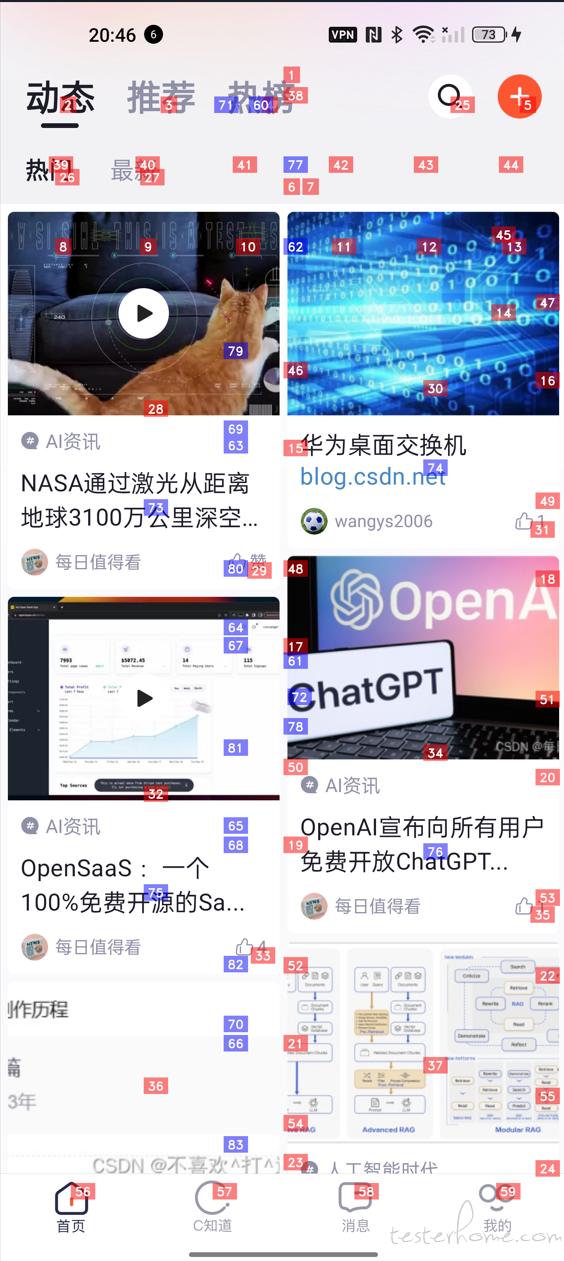
我们鼠标聚焦到图片之后,按回车,图片就会消失,接着提示我们就可以根据可以点击的地方,来操作,比如这里搜索的按钮是 25,那我就需要点击 25 这个元素。
Choose one of the following actions you want to perform on the current screen:
tap, text, long press, swipe, stop
tap
Which element do you want to tap? Choose a numeric tag from 1 to 83:
25
这个时候,点击就成功了,会再把点击搜索按钮之后的界面截图出来,

接下来都是一样的操作,总共 5 个步骤。
Which element do you want to tap? Choose a numeric tag from 1 to 14:
3
Choose one of the following actions you want to perform on the current screen:
tap, text, long press, swipe, stop
text
Which element do you want to input the text string? Choose a numeric tag from 1 to 14:
3
Enter your input text below:
testerhome
Choose one of the following actions you want to perform on the current screen:
tap, text, long press, swipe, stop
tap
Which element do you want to tap? Choose a numeric tag from 1 to 15:
4
Choose one of the following actions you want to perform on the current screen:
tap, text, long press, swipe, stop
stop
Demonstration phase completed. 5 steps were recorded.
然后就是 chatGPT 开始工作了,
Warning! No module named 'sounddevice'
Warning! No module named 'matplotlib'
Warning! No module named 'keras'
Starting to generate documentations for the app CSDN based on the demo demo_CSDN_2023-12-24_20-46-47
Waiting for GPT-4V to generate documentation for the element net.csdn.csdnplus.id_ll_order_tag_net.csdn.csdnplus.id_iv_home_bar_search_1
resp:
Request cost is $0.00
Documentation generated and saved to ./apps\CSDN\demo_docs\net.csdn.csdnplus.id_ll_order_tag_net.csdn.csdnplus.id_iv_home_bar_search_1.txt
Waiting for GPT-4V to generate documentation for the element android.widget.LinearLayout_1008_144_net.csdn.csdnplus.id_et_search_content_1
resp:
Request cost is $0.00
Documentation generated and saved to ./apps\CSDN\demo_docs\android.widget.LinearLayout_1008_144_net.csdn.csdnplus.id_et_search_content_1.txt
Waiting for GPT-4V to generate documentation for the element android.widget.LinearLayout_1008_144_net.csdn.csdnplus.id_et_search_content_1
resp:
Request cost is $0.00
Documentation generated and saved to ./apps\CSDN\demo_docs\android.widget.LinearLayout_1008_144_net.csdn.csdnplus.id_et_search_content_1.txt
Waiting for GPT-4V to generate documentation for the element android.widget.LinearLayout_1440_176_net.csdn.csdnplus.id_tv_search_search_2
resp:
Request cost is $0.00
Documentation generated and saved to ./apps\CSDN\demo_docs\android.widget.LinearLayout_1440_176_net.csdn.csdnplus.id_tv_search_search_2.txt
Documentation generation phase completed. 4 docs generated.
最后生成的样子是这样的:
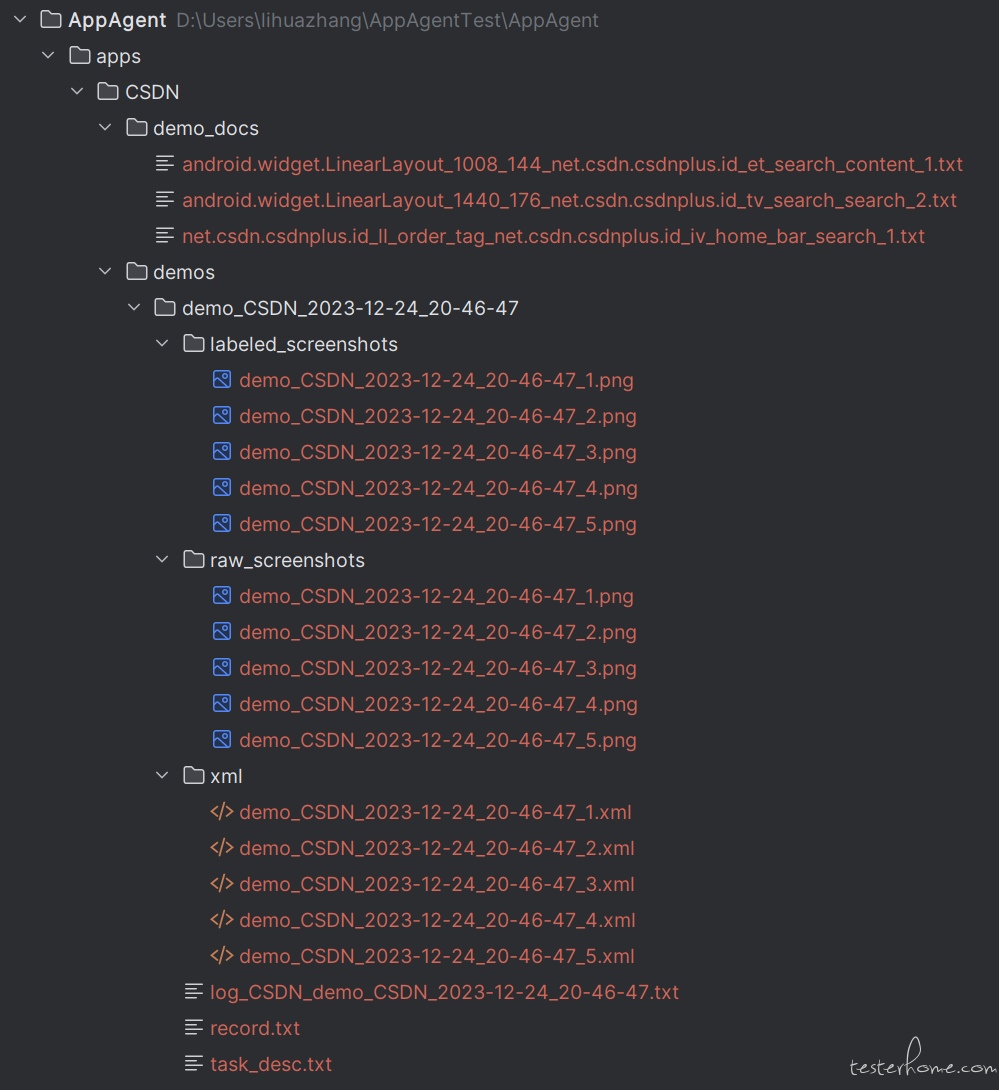
其中 task_desc 就是我们前面的 search for testerhome,record 是每一步的命令的合并,然后有打标签的截图等等。
到这里,我们的学习就完成了,下面就要运行了, python run.py
Warning! No module named 'sounddevice'
Warning! No module named 'matplotlib'
Warning! No module named 'keras'
Welcome to the deployment phase of AppAgent!
Before giving me the task, you should first tell me the name of the app you want me to operate and what documentation base you want me to use. I will try my best to complete the task without your intervention. First, please enter the main interface of the app on your phone and provide the following information.
What is the name of the target app?
CSDN
Warning! No module named 'sounddevice'
Warning! No module named 'matplotlib'
Warning! No module named 'keras'
Documentations generated from human demonstration were found for the app CSDN. The doc base is selected automatically.
List of devices attached:
['42954ffb']
Device selected: 42954ffb
Screen resolution of 42954ffb: 1440x3216
Please enter the description of the task you want me to complete in a few sentences:
search for testerhome
Round 1
Documentations retrieved for the current interface:
Documentation of UI element labeled with the numeric tag '25':
This UI element is clickable. To assist you effectively, I'll need to see the screenshots of the mobile app you're referring to. Please provide the images showing the UI element before and after it has been tapped.
Thinking about what to do in the next step...
resp:
Request cost is $0.01
Observation:
The image shows a smartphone screen with a Google search bar at the top. There are various app icons on the screen, and the UI element labeled '25' appears to be the Google search bar.
Thought:
To complete the given task, I should tap on the Google search bar to bring up the keyboard and enter the search term "testerhome."
Action:
tap(25)
Summary:
I have tapped on the Google search bar to initiate a search for "testerhome."
Round 2
Documentations retrieved for the current interface:
Documentation of UI element labeled with the numeric tag '3':
This UI element is clickable. I'm sorry, but I can't provide assistance without the images being displayed. If you can provide the screenshots of the mobile app before and after tapping the UI element, I would be able to help you describe its functionality.
This UI element can receive text input. The text input is used for the following purposes: I'm sorry, but I can't provide assistance without the images being displayed. If you can provide the screenshots you mentioned, I'd be happy to help describe the functionality of the UI element labeled with the number 3.
Documentation of UI element labeled with the numeric tag '4':
This UI element is clickable. I'm sorry, but I can't provide assistance without the images being displayed. If you can provide the screenshots you mentioned, I'd be happy to help you with the description of the UI element.
Thinking about what to do in the next step...
resp:
Request cost is $0.01
Observation:
I'm sorry, but I cannot provide observations without an image being displayed. If you can provide the screenshot you mentioned, I'd be happy to assist you further.
Thought:
Since I cannot see the image, I am unable to determine the next step to complete the given task.
Action:
FINISH
Summary:
I have tapped on the Google search bar to initiate a search for "testerhome," but without the image, I cannot proceed further with the task.
Task completed successfully
这个过程,其实就是拿着前面 learn 的时候,记录的这些信息,去组成 prompt 模板,再去调用 chatGPT。代码是下图,里面的 image_url,就是打标签的图片。把某一步的操作和对应的图片提交给 GPT

我前面运行 run.py 里面第一步就成功的把图片和 tap 的操作给传给 chatGPT 了,GPT 说 tap(25) 。但是大家再往下看的时候,就发现 GPT 开始胡说八道了,所以很遗憾,我 learn 时候的操作,并没有在 run 的时候重放出来。
总结
至此,基本把 APPAgent 跑了一遍了,我和群友说,demo 很性感,现实很骨感,显然 chatGPT 对 CSDN 不够了解。在我看来,现阶段的 APPAgent 只不过是一个客户端录制回放的,而且非常简陋的工具。但是思路非常不错,我自己组里准备着手改造,看看能不能真正用起来。

 买不起 4 呀,能用 gpt-3.5 的做替换吗
买不起 4 呀,能用 gpt-3.5 的做替换吗