背景
现在所在公司用上了滴滴出品的 agileTC ,整体上非常好用。但有个功能大家都在呼唤:支持测试任务中修改用例集内容,并同步修改到完整用例集中。所以有了这篇文章。
先说明下具体使用的场景,让大家更理解为什么要做这个功能,目的是什么:
首先,测试集、测试任务这块是本身 agileTC 的已有设计,测试集用于存储测试用例,测试任务用于执行用例。测试任务可以在用例集中筛选/全选用例,进行每个用例的测试结果登记。但测试用例不能修改用例,要修改用例必须到用例集编辑界面(此界面无筛选功能)
在我司的实际项目使用中,常见用法是:
1、项目前期主要是少数 1-2 人参与,他们根据需求及技术方案,完成初版的完整用例,并在里面标记开发自测用例。用例评审用的也是这一版。
2、提测前开发自测时,测试会创建对应的开发自测用例并给开发参照执行、登记结果。
3、提测后,用例会分给多人执行(人数可能不止前期的 1-2 人),会通过自定义标签形式记录这批用例是谁负责。此时会通过测试任务的筛选条件来筛选到只剩下此人负责的用例,单独进行执行和登记。
实际执行中,可能会由于需求变更、部分需求细节需要补充等原因,在 2、3 步经常需要更新用例集。虽然也可以到测试集进行更新,但测试集合计会有过千个用例,而测试任务则只有数百个,因此在测试任务中就进行更新,相对而言会更为方便。
由于总用例集需要用于进行一些数据统计和二轮测试用,所以此时也需要更新。基于此,所以做这个增量保存的功能。
这块功能之前自己其实也有大致想过,但一直没有想得特别透彻,这次做的过程中也是一开始想着直接用现成的 json-patch 直接就可以满足,但自己随机测试一下就出现用例被覆盖且没有任何冲突提示的问题,所以后期干脆彻底梳理了一遍整体设计思路,再重新写代码、加单测。
这块可能其他有做基于百度脑图的 xmind 用例管理平台相关的同学也有遇到,所以在此分享一下,也期望大家有更好的思路,可以下面评论交流下。
全文较长,建议可以先看目录了解大概,再具体看内容
设计方案思考
现有技术方案是这样的:
1、现在用例集和测试任务,涉及 2 个表,test_case 和 exec_record。
2、test_case 表存储每个完整的用例集 json 内容,包括节点、标签、优先级。这个完整的 json 可以直接被脑图组件完整加载和展示。
3、exec_record 表存储每个测试任务的信息,包括筛选条件、各节点的执行结果。其中各节点执行结果存储方式是节点 id+ 测试结果,示例:
{"bv8nxhi3c800":"9","c8tws927cpc0":"9","c8tws7dgbm80":"9"}
4、在前端界面展示的测试任务内容,实际是经过 用例集表 json 根据筛选条件筛选节点->筛选后节点 json 和测试任务的测试结果进行合并 两个步骤得出。这个合并和筛选是实时的,每次刷新加载测试任务的脑图编辑界面,都会做一遍。
5、对于用例集的多人协作,滴滴本身也自带多人同时编辑用例的功能(集成在前端编辑器中,通过 websocket 实时存储 diff 和更新),但因为之前使用时发现会出现用例丢失、用例重复之类的问题,原因猜测和一些网络不稳定导致同步可能不够实时有关。由于前端编辑器没有开源,无法真正寻找到根源及修复,加上一些对脑图编辑器二次调整的需要,所以改用了另一个基于 kityminder + vue 改的脑图组件,也因此无法使用这个自带的多人同时编辑用例功能(这个功能要求编辑器实时上报用户的每一次操作改动,这个功能只有 agileTC 的脑图编辑器组件才具备)。
以前用过的另一个用例管理平台,模型会简单很多:
1、不区分用例和任务,用例本身就带有登记测试结果功能,数据库只需要存用例内容。
2、保存时,会自动根据服务端内容计算出本次保存和打开界面时版本的 diff ,然后把这个 diff 和最新用例内容进行自动合并存储。若合并发现冲突,则反馈冲突内容,让用户在前端界面手动解决冲突后存储。
在实际实践中,会出现合并冲突的情况极少,绝大部分情况都是可以直接自动合并存储的。所以大家的实际用法,也基本都是主测先创建一个简单的 xmind 并分好每个人负责的一级节点,然后各负责人员再去往这个一级下面扩展具体的用例内容。
基于上面的这些历史经验和方案,整体设计方案有两个大方向:
方向一:最小改动原则。用例集每次保存都是增量保存(包括任务中编辑、用例集中编辑),由服务端自动通过 base 版本和保存版本得出 diff ,再应用到最新的用例集中。
方向二:简化整体模型原则。直接去掉测试任务概念,回归之前用过的直接用例集保存测试结果,然后在此基础上,再应用增量保存功能。
考虑到目前大家已经有测试任务的使用习惯,且提出任务可以改用例需求的组,也比较认可测试任务这个工具。因此决定,采用方向一。
整体方案设计

整体方案看起来比较简单,改动点主要有:
1、保存从全量保存变为增量保存
2、保存时可以检测冲突
3、类似 git ,不冲突的部分可以直接保存,冲突部分再单独引导用户手动处理。
但这里面的增量保存、冲突检测、diff 展示,都是一些技术难点。
技术难点及解决
难点一:如何检测生成两个版本 json 的 diff
分析
针对 json 的增量保存,刚好业内也有其他业务场景用到(通过增量同步 json 变更,减少网络带宽占用),目前已有两种官方正式协议:RFC 6902 (JSON Patch) 和 RFC 7396 (JSON Merge Patch)
json-patch 格式说明:https://atbug.com/json-patch/ 、https://datatracker.ietf.org/doc/html/rfc6902(官方协议定义文档)
json-merge-patch 格式说明:https://datatracker.ietf.org/doc/html/rfc7386(官方协议定义文档)
两者对比:https://erosb.github.io/post/json-patch-vs-merge-patch/
相关 java 实现库:
https://github.com/flipkart-incubator/zjsonpatch ——仅支持 json-patch 格式
https://nicedoc.io/java-json-tools/json-patch ——支持 json-patch + json-merge-patch 格式
简单总结下,两者的区别:
- json-patch :生成两个 json 间的变化,并把每个变化点通过操作记录的方式来记录。如:
{ "op": "replace", "path": "/baz/1", "value": "boo" }
{ "op": "move", "from": "/biscuits", "path": "/cookies" }
- op 代表操作。支持 add、remove、replace、copy、move、test 共 6 种操作。其中 test 仅作为校验用,不表达 json 变化。
- 针对 add、replace、test,会带上 path 和 value 字段。示例:
{ "op": "replace", "path": "/baz", "value": "boo" }- 其中 path 内容遵循另一个叫做 json-pointer 的规范。这个规范简单的说,就是所在对象为 object 的用 key 定位,为 array 的用下标定位,父子之间用 / 间隔。举例:"/biscuits" 、"/biscuits/0/name" 、""(代表整个 json )
- value 字段则直接就是对应的 value ,可以是单个值、json object 或者 json array 。
- 针对 remove ,只有 path ,没有 value
针对 copy、move,用 from 指代源位置,path 指代目标位置。示例:
{ "op": "move", "from": "/biscuits", "path": "/cookies" }json-merge-patch:直接指示新的 json 中,各个 key 对应 value 变成的结果。无变化的不出现。如:
// 这个 patch 会把根节点下 key 为 a 的值替换为 z ,再把 c 下面的 f 删掉
{
"a":"z",
"c": {
"f": null
}
}
key 代表要应用的位置。如果有嵌套,则 patch 内也要对应嵌套。
value 代表要改为的新值。其中 null 表示删除,非 null 表示要改的值
如果遇到某个对象是 array ,由于 key 不具备指代 array 中单个元素的能力,所以 patch 中必须完整地把新的 array 完整记录进来,直接进行完整的替换。
解决方案
json-merge-patch
特点一:不会出现冲突,因为指代的就是要改成什么样了
特点二: array 需要完整记录,脑图的 children 节点是 array 类型的,而且很可能很庞大,用这个基本相当于把一级节点外的所有其他节点都全量更新了,不符合场景需要。
json-patch
特点一:原子化,每个改动对应一个 op
特点二:对 array 也可以支持(难点二会提到,实际还是要废掉这个支持,筛选后脑图 json 的下标和原始下标会有很大差异)
因此,最终选择 json-patch ,选用 zjsonpatch 这个库。
关键代码如下:
ObjectMapper mapper = new ObjectMapper();
String convertedBaseContent = convertChildrenArrayToObject(baseContent);
String convertedTargetContent = convertChildrenArrayToObject(targetContent);
JsonNode base = mapper.readTree(convertedBaseContent);
JsonNode result = mapper.readTree(convertedTargetContent);
// OMIT_COPY_OPERATION: 每个节点的 id 都是不一样的,界面上的 copy 到 json-patch 应该是 add ,不应该出现 copy 操作。
// ADD_ORIGINAL_VALUE_ON_REPLACE: replace 中加一个 fromValue 表达原来的值
// 去掉了默认自带的 OMIT_VALUE_ON_REMOVE ,这样所有 remove 会带上原始值,在 value 字段中
EnumSet<DiffFlags> flags = EnumSet.of(OMIT_COPY_OPERATION, ADD_ORIGINAL_VALUE_ON_REPLACE);
JsonNode originPatch = JsonDiff.asJson(base, result, flags);
难点二:如何在应用 diff 时发现冲突,并尽可能应用无冲突的部分
分析
针对难点一使用了 json-patch ,意味着每个改动点都会有一个原子的 patch 进行记录,整体改动会是一个数组模式,每个元素对应一次原子改动
解决方案
那这个方案就变得比较简单了:一次只应用整体 patch 数组中的一次改动,如果出错,则跳过并记录为冲突,不出错,则应用并更新用例内容
关键代码:
/**
* 逐个应用 patch 到目标 json 中,并自动跳过无法应用的 patch 。
* @param patch patch json
* @param baseContent 需要应用到的 json
* @param flags EnumSet,每个元素为 ApplyPatchFlagEnum 枚举值。用于指代应用 patch 过程中一些特殊操作
* @return ApplyPatchResultDto 对象,包含应用后的 json 、应用成功的 patch 和跳过的 patch
* @throws IOException json 解析错误时,抛出此异常
*/
public static ApplyPatchResultDto batchApplyPatch(String patch, String baseContent, EnumSet<ApplyPatchFlagEnum> flags) throws IOException {
baseContent = convertChildrenArrayToObject(baseContent);
ApplyPatchResultDto applyPatchResultDto = new ApplyPatchResultDto();
ObjectMapper mapper = new ObjectMapper();
JsonNode patchJson = mapper.readTree(patch);
JsonNode afterPatchJson = mapper.readTree(baseContent);
List<String> conflictPatch = new ArrayList<>();
List<String> applyPatch = new ArrayList<>();
for (JsonNode onePatchOperation : patchJson) {
try {
if (onePatchOperation.isArray()) {
afterPatchJson = JsonPatch.apply(onePatchOperation, afterPatchJson);
} else { // 外面包一个 array
afterPatchJson = JsonPatch.apply(mapper.createArrayNode().add(onePatchOperation), afterPatchJson);
}
applyPatch.add(mapper.writeValueAsString(onePatchOperation));
} catch (JsonPatchApplicationException e) {
conflictPatch.add(mapper.writeValueAsString(onePatchOperation));
}
}
String afterPatch = mapper.writeValueAsString(afterPatchJson);
afterPatch = convertChildrenObjectToArray(afterPatch);
applyPatchResultDto.setJsonAfterPatch(afterPatch);
applyPatchResultDto.setConflictPatch(conflictPatch);
applyPatchResultDto.setApplyPatch(applyPatch);
return applyPatchResultDto;
}
难点三:怎么保障无冲突的部分应用后正确
分析
某个角度来说,这个才是最难的。冲突的有人工兜底,没冲突就真的纯靠系统识别了,等到人工发现可能已经过了好多个版本,不好追溯和恢复。
需要先尽可能穷举所有可能的改动场景,并一一分析是否有问题。
首先,每次改动,从原子操作角度,可能产生的情况有:
- 增加新节点(包括从零编辑和通过复制粘贴得到的,因 id 值会不一样,从 json object 角度都认为是新增节点)
- 修改已有节点内容(文字、标签、优先级等属性)、
- 删除已有节点
- 移动已有节点(节点的 id 不变,只是位置变了)
四种场景。对应 json-patch 里面的 op :add、replace、remove、move(特别留意,这里也有暗坑,实际实现库有可能用 remove + add 来取代 move 操作,这样 add 就带上了内容的绝对值且无法比对是否和数据库一致)
考虑到多人协作,有可能 base 版本实际非数据库中实际最新版,因此每个原子操作进行分析时,增加 path 或 value 的 base 值,和数据库当前最新版一致/不一致的场景
-
add
- 影响因素:path + value
- path:
- 和数据库不一致:直接提示冲突,没问题。
- 和数据库一致(问题一):object 时 key 都是唯一的,如果被其他人删掉导致无 key 会直接产生冲突,没问题。但 array 时根据下标定位,测试任务筛选条件可能会导致 children 节点在完整用例里有 3 个,任务里只有 1 个(实际对应完整用例第三个),引起下标指向错误。
- value:
- 和数据库不一致:value 只会是此用户修改得出,数据库原来无值,此场景不存在。
- 和数据库一致:只有单人修改,value 属于独占内容,不会缺失或受其他人影响,可直接应用。无问题。
- 影响因素:path + value
-
replace
- 影响因素:path + value
- path(问题一):同 add 中的 path
- value(问题二):
- 和数据库一致:无从知道是否和数据库一致,无原有值记录
- 和数据库不一致:可修改的有 text(文字)、priority(优先级)、resource(自定义标签)等,本质上都是节点 object 下 data 字段的子属性。因为 replace 并不会记录原值,所以可能存在 replace 后的新值覆盖了中途某人修改过的值,且不产生冲突的问题。
- 影响因素:path + value
-
remove
- 影响因素:path + value(原 json-path 不考虑 value ,但为了保障删除内容和删除者意愿一致,需要校验一下)
- path(问题一):同 add 的问题。
- value:
- 和数据库一致:无问题,直接删除即可。
- 和数据库不一致(问题二):可能原因是别人有改动过且先保存,或者处于测试任务筛选条件导致内容和用例全集不一致。此时可能出现错删除了作者见不到,但实际存在的子节点。
- 影响因素:path + value(原 json-path 不考虑 value ,但为了保障删除内容和删除者意愿一致,需要校验一下)
-
move
- 影响因素:from、path。value 因为本身只是想表达移动节点意愿,可以无需校验。
- from(问题一):同 add 的问题。
- path(问题一):同 add 的问题。
- 影响因素:from、path。value 因为本身只是想表达移动节点意愿,可以无需校验。
总结起来,存在两个问题:
问题一:path 描述 array 时,数组下标由于用例可能被筛选过,只是子集,很可能不准
问题二:replace 及 remove 时,并没有记录原来的值,而是直接操作。有可能出现其实作者改动的源值和实际数据库最新值不一致的问题。
补充一个测试 java 库自动生成 patch 的规则时发现的问题:
问题三:自动生成的 patch ,可能会使用 remove + add 取代 move 。此时 add 带有的绝对值,可能会出现类似问题二的直接覆盖导致缺失问题。
解决方案
问题一:path 描述 array 时,数组下标由于用例可能被筛选过,只是子集,很可能不准
生成 patch 时,把 array 改为 object ,object 中每个子元素的 key 都为这个节点本身的 id 属性(脑图中每个节点的 id 属性会保证整个 json 全部节点中绝对的唯一)。生成完 patch 再改回来。
示例:
// 原脑图格式:
{"root": {"data": {"id": "nodeA"}, "children": [{"data": {"id": "nodeAa"}, "children": []}, {"data": {"id": "nodeAb"}, "children": []}]}}
// 把 array 改为 object 后格式:
{"root": {"data": {"id": "nodeA"}, "childrenObject": {"nodeAa": {"data": {"id": "nodeAa"}, "childrenObject": {}, "order": 0}}, {"nodeAb": {"data": {"id": "nodeAb"}, "childrenObject": {}, "order": 1}}}}
关键代码:
/**
* 把 children 从 array 改为 object (array中每个元素外面多加一个 key ,key 的值为元素中的 data.id ),解决 json-pointer 针对数组用下标定位,会不准确问题
* 示例:
* 转换前: {"root": {"data": {"id": "nodeA"}, "children": [{"data": {"id": "nodeAa"}, "children": []}, {"data": {"id": "nodeAb"}, "children": []}]}}
* 转换后: {"root": {"data": {"id": "nodeA"}, "childrenObject": {"nodeAa": {"data": {"id": "nodeAa"}, "childrenObject": {}, "order": 0}}, {"nodeAb": {"data": {"id": "nodeAb"}, "childrenObject": {}, "order": 1}}}}
* @param caseContent 完整用例 json ,需包含 root 节点数据
* @return 转换后 children 都不是 array 的新完整用例 json
*/
public static String convertChildrenArrayToObject(String caseContent) {
return convertChildrenArrayToObject(caseContent, true);
}
private static String convertChildrenArrayToObject(String caseContent, Boolean withOrder) {
JSONObject caseContentJson = JSON.parseObject(caseContent);
JSONObject rootData = caseContentJson.getJSONObject("root");
rootData.put("childrenObject", convertArrayToObject(rootData.getJSONArray("children"), withOrder));
// 把旧数据直接删掉,换成新数据
rootData.remove("children");
return JSON.toJSONString(caseContentJson);
}
// 递归把 array 改为 object ,key 为原来子元素的 id
private static JSONObject convertArrayToObject(JSONArray childrenArray, Boolean withOrder) {
// 把 children 这个 array 换成 Object
JSONObject childrenObject = new JSONObject();
// children 中每个子元素都变为 object
for (int i=0; i<childrenArray.size(); i++) {
JSONObject child = childrenArray.getJSONObject(i);
String childId = child.getJSONObject("data").getString("id");
if (withOrder) {
// 加一个 order 字段,用于转回 array 时保证内部顺序一致。
child.put("order", i);
}
childrenObject.put(childId, child);
// 对 child 进行递归,把它的 children 再变成 object
JSONArray childrenArrayInChild = child.getJSONArray("children");
child.put("childrenObject", convertArrayToObject(childrenArrayInChild, withOrder));
// 删掉已经不需要的 children 字段
child.remove("children");
}
return childrenObject;
}
问题二:replace 及 remove 时,并没有记录原来的值,而是直接操作。有可能出现其实作者改动的源值和实际数据库最新值不一致的问题。
解决思路:
patch 中增加原值校验相关字段。原值一致才允许应用,原值不一致则认为冲突不允许应用。
考虑到改动 json-patch 的实现库比较麻烦且容易埋坑,改为使用 test 这个 op 字段来进行校验,即原来单纯的 replace/remove 变为 test + replace/remove ,test 用于校验原有字段值。至于 test 原字段值,则通过生成的 patch 内容拿
相关代码:
/**
* 给所有 replace 或 remove 的 patch ,能校验原始值的,都加上 test
* @param allPatch ArrayNode 形式的所有 patch 内容
* @return 添加完 test 后的所有 patch 内容
*/
private static ArrayNode addTestToAllReplaceAndRemove(ArrayNode allPatch) {
ObjectMapper mapper = new ObjectMapper();
ArrayNode result = mapper.createArrayNode();
for (JsonNode onePatch : allPatch) {
// 实际应用 patch 时,不会管 replace 本身的 fromValue 字段。得手动前面加一个 test 的校验应用前的原内容是否一致,并在外面再用一个 array 包起来。
// 即 [.., {op: replace, fromValue: .., path: .., value: ..}] 改为 [.., [{op: test, path: .., value: <fromValue>}, {op: replace, path: .., value: <value>}]]
// 如果没有 fromValue 字段,那无法校验,直接按原来样子记录即可
if ("replace".equals(onePatch.get("op").asText()) && onePatch.get("fromValue") != null) {
ArrayNode testAndReplaceArray = mapper.createArrayNode();
ObjectNode testPatch = mapper.createObjectNode();
testPatch.put("op", "test");
testPatch.put("path", onePatch.get("path").asText());
testPatch.set("value", onePatch.get("fromValue"));
testAndReplaceArray.add(testPatch);
testAndReplaceArray.add(onePatch);
result.add(testAndReplaceArray);
continue;
}
// remove 同理,有 value 的前面都加一个 test
if ("remove".equals(onePatch.get("op").asText()) && onePatch.get("value") != null) {
ArrayNode testAndRemoveArray = mapper.createArrayNode();
ObjectNode testPatch = mapper.createObjectNode();
testPatch.put("op", "test");
testPatch.put("path", onePatch.get("path").asText());
testPatch.set("value", onePatch.get("value"));
testAndRemoveArray.add(testPatch);
testAndRemoveArray.add(onePatch);
result.add(testAndRemoveArray);
continue;
}
result.add(onePatch);
}
return result;
}
问题三:自动生成的 patch ,可能会使用 remove + add 取代 move 。此时 add 带有的绝对值,可能会出现类似问题二的直接覆盖导致缺失问题。
经过查看 zjsonpatch 库里 move 的实现,原理还是确认 add 和 remove 的 value 是否有完全一样,如果有,则两者合并成 move 。
之所以会无法合并,原因是前面的 array 转 object 里面加入的 order 字段会变化。
所以,可以做一次不带有 order 字段的转换,先得出 move 字段。然后再把带 order 字段转换中 path 和 move 的 from 或者 path 重合的去掉。
衍生问题:order 位置未被更新(比如原来位置 order 为 5 ,新位置 order 为 3 ,但因为 move 是原版直接挪,所以 move 完内容的 order 还是 5)。放到问题四单独分析解决
相关代码:
// OMIT_COPY_OPERATION: 每个节点的 id 都是不一样的,界面上的 copy 到 json-patch 应该是 add ,不应该出现 copy 操作。
// ADD_ORIGINAL_VALUE_ON_REPLACE: replace 中加一个 fromValue 表达原来的值
// OMIT_MOVE_OPERATION: 所有 move 操作,都还是维持原来 add + remove 的状态,避免一些类似 priority 属性值的一增一减被认为是 move 。
// 去掉了默认自带的 OMIT_VALUE_ON_REMOVE ,这样所有 remove 会在 value 字段中带上原始值
JsonNode originPatch = JsonDiff.asJson(base, result,
EnumSet.of(OMIT_COPY_OPERATION, ADD_ORIGINAL_VALUE_ON_REPLACE, OMIT_MOVE_OPERATION));
// 借助去掉 order 的内容,正确生成 move 操作
JsonNode baseWithoutOrder = mapper.readTree(convertChildrenArrayToObject(baseContent, false));
JsonNode targetWithoutOrder = mapper.readTree(convertChildrenArrayToObject(targetContent, false));
List<String> allFromPath = new ArrayList<>();
List<String> allToPath = new ArrayList<>();
List<JsonNode> allMoveOprations = new ArrayList<>();
// 需要生成 move 操作,去掉原有 flags 里面的忽略 move 标记
JsonNode noOrderPatch = JsonDiff.asJson(baseWithoutOrder, targetWithoutOrder,
EnumSet.of(OMIT_COPY_OPERATION, ADD_ORIGINAL_VALUE_ON_REPLACE));
for (JsonNode oneNoOrderPatch: noOrderPatch) {
if ("move".equals(oneNoOrderPatch.get("op").asText())) {
allFromPath.add(oneNoOrderPatch.get("from").asText());
allToPath.add(oneNoOrderPatch.get("path").asText());
allMoveOprations.add(oneNoOrderPatch);
}
}
ArrayNode finalPatch = mapper.createArrayNode();
// 先把所有 move 加进这个最终的 patch 中
for (JsonNode movePatch : allMoveOprations) {
finalPatch.add(movePatch);
}
for (JsonNode onePatch : originPatch) {
// 和 move 匹配的 add 中,根节点 order 字段需要变为 replace 存下来,避免丢失顺序
if ("add".equals(onePatch.get("op").asText()) && allToPath.contains(onePatch.get("path").asText())) {
// 获取 add 中 value 第一层的 order 值。此时 value 实际是移动的整体 object ,order 就在第一层
int newOrder = onePatch.get("value").get("order").asInt();
ObjectNode replaceOrderPatch = mapper.createObjectNode();
replaceOrderPatch.put("op", "replace");
replaceOrderPatch.put("path", onePatch.get("path").asText() + "/order");
replaceOrderPatch.put("value", newOrder);
// 这种情况下就不用管 replace 的原来值是什么了,所以不设定 fromValue
finalPatch.add(replaceOrderPatch);
// 这个 add 的作用已经被 move + replace 达成了,所以不需要记录这个 add
continue;
}
// move 的源节点删除操作,需要忽略,因为 move 已经起到相应的作用了
if ("remove".equals(onePatch.get("op").asText()) && allFromPath.contains(onePatch.get("path").asText())) {
continue;
}
// 如果 order 没变,那不去除 order 的 patch 有可能也有 move 。这个时候这个 move 需要去掉,避免重复
if ("move".equals(onePatch.get("op").asText()) && allMoveOprations.contains(onePatch)) {
continue;
}
// 其他不需要调整的,直接加进去就可以了
finalPatch.add(onePatch);
}
问题三解决方案的衍生问题四:move 操作的元素,因为是整体内容挪过来的,会导致 order 位置未被更新(比如原来位置 order 为 5 ,新位置 order 为 3 ,但因为 move 是原版直接挪,所以 move 完内容的 order 还是 5)。
如果不用 move 操作,则会出现 add + replace(如果 order 有变更)+ remove 。
所以,解决方法只需要重新应用 replace 操作即可,并且要保障 replace 放在 move 后,避免节点已经被 move 应用失败。
由于生成的 replace 操作有可能作用在原有位置,因此匹配的 path 需要改为新位置。
相关代码:
... 前面是问题三中生成了 move patch 的相关逻辑,其中 allToPath 指代所有 move 中的 path 路径,即移动到的新位置 path
for (JsonNode onePatch : originPatch) {
// 和 move 匹配的 add 中,根节点 order 字段需要变为 replace 存下来,避免丢失顺序
if ("add".equals(onePatch.get("op").asText()) && allToPath.contains(onePatch.get("path").asText())) {
// 获取 add 中 value 第一层的 order 值。此时 value 实际是移动的整体 object ,order 就在第一层
int newOrder = onePatch.get("value").get("order").asInt();
ObjectNode replaceOrderPatch = mapper.createObjectNode();
replaceOrderPatch.put("op", "replace");
replaceOrderPatch.put("path", onePatch.get("path").asText() + "/order");
replaceOrderPatch.put("value", newOrder);
// 这种情况下就不用管 replace 的原来值是什么了,所以不设定 fromValue
finalPatch.add(replaceOrderPatch);
continue;
}
// move 的源节点删除操作,可以忽略
if ("remove".equals(onePatch.get("op").asText()) && allFromPath.contains(onePatch.get("path").asText())) {
continue;
}
// 其他不需要调整的,直接加进去就可以了
finalPatch.add(onePatch);
}
难点四:测试任务带有筛选条件,有可能只是完整用例集的子集。对子集的修改应用到全集时,可能部分内容会对不上引起冲突。
分析
首先,筛选条件目前只有两类:优先级/自定义标签。筛选的的子集和全集相比,在节点 data 内容层面不会有任何不同,只有在节点 children 这个数组层面会减少内容(数量上的减少,子元素内容不会少)。
内容减少,只会引起数组下标的变化,即上一个问题解决方案中 childrenObject 子元素的 order 值不正确,进而引起如果增量改动里有改动 order 会引起冲突(子集的原始值和全集里的原始值不一致)。
举例:
全集:root 节点下一级,依次有 A、B、C 节点。只有 A、C 符合筛选条件
子集:root 节点下一级,只有 A、C 两个节点
操作 1:在 C 后面增加节点。新节点会以 add 操作增加到 root 下面的 children 中,order 会为 3 甚至更大的值。因为是新增的,不会有冲突,但因为 order 可能大于原有 array 的 size ,只需要转换回 array 时只要把没应用上的都在后面补回去即可。
操作 2:在 A、C 之间增加节点。新节点 add 和操作 1,但会引起 C 节点的 replace ,order 从 2 变 3 。由于全集里 C 的 order 其实是 3,这个 replace 会在验证原始值时失败认为冲突。这个冲突其实无关紧要,加一个忽略即可。
解决方案
1、操作 1:在 C 后面增加节点。新节点会以 add 操作增加到 root 下面的 children 中,order 会为 3 甚至更大的值。因为是新增的,不会有冲突,但因为 order 可能大于原有 array 的 size ,只需要转换回 array 时只要把没应用上的都在后面补回去即可。
相关代码:
// 递归把每个 object 改回 array ,去掉 object 中第一层的 key
private static JSONArray convertObjectToArray(JSONObject childrenObject, Boolean withOrder) {
JSONArray childrenArray = new JSONArray();
List<String> keyMoved = new ArrayList<>();
// object 中每个子元素,重新放回到 array 中
for (int i=0; i<childrenObject.keySet().size(); i++) {
for (String key : childrenObject.keySet()) {
JSONObject child = childrenObject.getJSONObject(key);
if (withOrder) {
// 需要根据 order 判定原来的顺序,按顺序加进去,避免顺序错误
if (Integer.valueOf(i).equals(child.getInteger("order"))) {
childrenArray.add(child);
keyMoved.add(key);
} else {
continue;
}
} else {
// 不用管 order ,直接一个一个 key 加进去就是了
childrenArray.add(child);
keyMoved.add(key);
}
// 对添加的 child 进行递归,把它的 childrenObject 再变回 array
JSONObject childrenObjectInChild = child.getJSONObject("childrenObject");
child.put("children", convertObjectToArray(childrenObjectInChild, withOrder));
if (withOrder) {
// 去掉排序用的临时字段
child.remove("order");
}
child.remove("childrenObject");
}
}
// ** 重点:有可能通过 move 过来的 order 值很大,最后要把剩余的 childrenObject 元素继续放到 array 里面
for (String key : childrenObject.keySet()) {
if (!keyMoved.contains(key)) {
childrenArray.add(childrenObject.getJSONObject(key));
}
}
return childrenArray;
}
2、操作 2:在 A、C 之间增加节点。新节点 add 和操作 1,但会引起 C 节点的 replace ,order 从 2 变 3 。由于全集里 C 的 order 其实是 3,这个 replace 会在验证原始值时失败认为冲突。这个冲突其实无关紧要,加一个忽略即可。
相关代码:
for (JsonNode onePatchOperation : patchJson) {
try {
if (onePatchOperation.isArray()) {
afterPatchJson = JsonPatch.apply(onePatchOperation, afterPatchJson);
} else { // 外面包一个 array
afterPatchJson = JsonPatch.apply(mapper.createArrayNode().add(onePatchOperation), afterPatchJson);
}
applyPatch.add(mapper.writeValueAsString(onePatchOperation));
} catch (JsonPatchApplicationException e) {
// 检查是否是对 order 的操作。如果是,那就忽略这个冲突
if (flags.contains(IGNORE_REPLACE_ORDER_CONFLICT) &&
onePatchOperation.isArray() &&
onePatchOperation.get(0).get("path").asText().endsWith("/order")) {
continue;
}
conflictPatch.add(mapper.writeValueAsString(onePatchOperation));
}
}
难点五:如何在出现冲突后进行友好标识,提高解决冲突效率
分析
首先,需要存储存在冲突的变更。从难点二的解决可知,只要从冲突 patch 列表就可以得到。只要备份里增加这个字段即可。
然后,就是怎么根据这个 patch 列表,以及冲突副本完整脑图内容,呈现变更了。
git 标记 diff 的方法,是给增加的内容(+)加上绿色底色,删除的内容(-)加上红色底色,重命名或移动文件则直接通过文件名位置, 以 old -> new 的格式标识。修改内容(replace)从底层上就直接是 删除 + 增加 来表示。
同样的方式放到脑图,增加没问题,删除只要把被删除内容加回来也没问题。没有重命名或移动文件机制,但有修改节点内容及移动节点机制。
由于脑图非纯文本文件,而是以 json 形式记录数据,脑图编辑器呈现数据的形式。diff 内容基本是 path + value 的形式记录,通过 path 不好直观看出改动位置,因此需要直接在冲突副本上通过添加标记的方式进行展示。
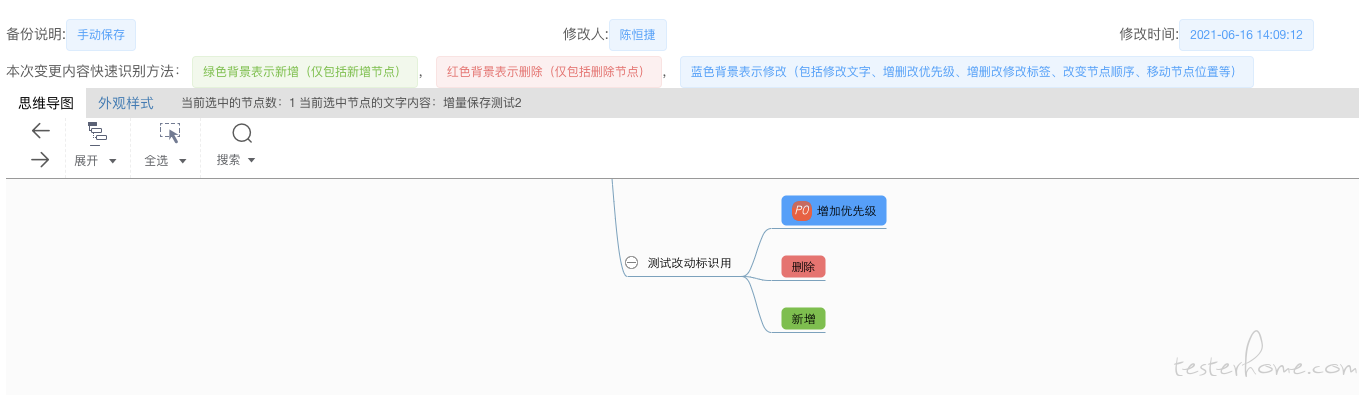
按照相对直觉的方式,设定如下标识:
1、增加的节点:加上绿色底色
2、删除的节点:加上红色底色
3、修改的节点(包括移动节点、修改节点自身的文字、优先级、自定义标签等):加上蓝色底色
解决方案
由于实际 json-patch 的操作,并不会认识 “节点” 这个概念,只知道 json 里的 object 及 array 。
所以,需要先判断 patch 的操作对象,是一个节点还是非节点。判断条件为操作的 path 属性。如果是节点,一定会以类似 /childrenObject/xxx 的形式结尾
相关代码:
/**
* 根据 jsonPatch 内容,在脑图中标记变更。以节点为单位,增加的加绿色背景,删除的加红色背景,修改的加蓝色背景。
* 特别注意,移动节点(move)因为实际节点 id 未有变化,所以也会被标记为修改
*
* @param minderContent
* @param jsonPatch
* @return
*/
public static String markJsonPatchOnMinderContent(String jsonPatch, String minderContent) throws IOException, IllegalArgumentException {
String green = "#67c23a";
String blue = "#409eff";
String red = "#f56c6c";
ObjectMapper objectMapper = new ObjectMapper();
// 因为 jsonPatch 是针对已经把 children 数组变为对象的 json 格式,所以要先转换下
ObjectNode convertedMinderContentJson = objectMapper.readTree(convertChildrenArrayToObject(minderContent)).deepCopy();
ArrayNode jsonPatchArray = (ArrayNode) objectMapper.readTree(jsonPatch);
for (JsonNode onePatch : jsonPatchArray) {
JsonNode operation;
if (onePatch.isArray() && onePatch.size() == 2) {
// 只可能是 replace 或 remove 的。前面多加了 test ,会是一个带有两个子元素的 array 。第二个才是 replace 或 remove
operation = onePatch.get(1);
if (!("replace".equals(operation.get("op").asText()) || "remove".equals(operation.get("op").asText()))) {
throw new IllegalArgumentException(String.format("此单个 patch 格式不正常," +
"正常格式在双元素 array 的第二个,应该是 replace 或 remove 操作" +
"不符合的 patch 内容: %s",
objectMapper.writeValueAsString(onePatch)));
}
} else if (onePatch.isObject()) {
operation = onePatch;
} else {
// 目前不会生成不符合这两种格式的 patch ,抛异常
throw new IllegalArgumentException(String.format("此单个 patch 格式不正常,正常格式应该是双元素array或单个object" +
"请确认 patch 内容是通过此工具类提供的获取 patch 方法生成。不符合的 patch 内容: %s",
objectMapper.writeValueAsString(onePatch)));
}
// 先判定是否为整个节点的内容变更
if (isNodePath(operation.get("path").asText())) {
// 节点级别,只支持 add 、 remove 、move 。因为 replace 只改值不改key,不可能在节点级别产生 replace 操作
switch (operation.get("op").asText()) {
case "add":
addAddNodeMark(convertedMinderContentJson, operation, green);
break;
case "move":
addMoveNodeMark(convertedMinderContentJson, operation, blue);
break;
case "remove":
addRemoveNodeMark(convertedMinderContentJson, operation, red);
break;
default:
throw new IllegalArgumentException(String.format("此单个 patch 格式不正常," +
"正常的节点级别 patch ,op 应该是 add、move、remove 其中一个" +
"不符合的 patch 内容: %s",
objectMapper.writeValueAsString(operation)));
}
} else {
// 非节点级别变更,都将它标记为 修改内容 即可。不应该出现 move 节点属性的动作
switch (operation.get("op").asText()) {
case "add":
addAddAttrMark(convertedMinderContentJson, operation, blue);
break;
case "replace":
addReplaceAttrMark(convertedMinderContentJson, operation, blue);
break;
case "remove":
addRemoveAttrMark(convertedMinderContentJson, operation, blue);
break;
default:
throw new IllegalArgumentException(String.format("此单个 patch 格式不正常," +
"正常的非节点级别 patch ,op 应该是 add、replace、remove 四个其中一个" +
"不符合的 patch 内容: %s",
objectMapper.writeValueAsString(operation)));
}
}
}
return convertChildrenObjectToArray(objectMapper.writeValueAsString(convertedMinderContentJson));
}
总结
由于篇幅所限,其实里面有些小的问题解决并没有列在上面的技术难点里面(比如应用变更时,如果 replace order 操作出错,可以忽略)。整体改动大概花了 4 人天左右,而且中途也写了不少单测代码来保障每次改动都不会影响已有功能(行覆盖率达到 94%,只有少量格式不对抛异常的逻辑没有覆盖)。
此次场景比较复杂,已经尽自己所能,用相对靠谱的分析方法列举出所有可能的场景,并进行对应处理。但是否靠谱还需要靠实践检验,预计节后会上线此功能,届时再看看实际使用的效果。
如果有其它同学也做过类似的功能,有更好的算法或者思路,也欢迎直接评论分享交流下
开源
目前服务端相关的代码改动及配套单测,已提交 PR 给官方。地址:https://github.com/didi/AgileTC/pull/93
增量生成、应用、标记的逻辑全部在 case-server/src/main/java/com/xiaoju/framework/util/MinderJsonPatchUtil.java 这个工具类
配套单测在 case-server/src/test/java/com/xiaoju/framework/util/MinderJsonPatchUtilTest.java
如果有需要的,可以按需自取哈。